SQL server 文件占用硬盘过大 日志 读写分离同步文件过大清理 DBCC收缩数据库 分发数据库distribution收缩
一顿操作猛如虎 又省出好几十G硬盘空间 小破站又能蹦跶了
目标:实例库日志压缩清理,分发数据库压缩清理
采用SQL 脚本收缩数据库
-
截断事务日志
backup log [数据库名] with no_log -
收缩数据库
dbcc shrinkdatabase ([数据库名])
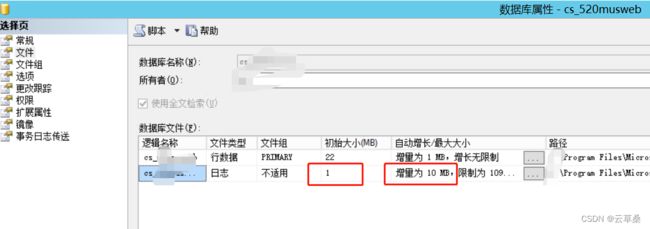
4.以上操作都不行的话,就只能将事务日志设置为:文件增长不受限制,操作完再改回来。
深度用法
----------start---------
DBCC是SQL Server的数据库控制台命令。它可以提供多种命令,用于实现数据库维护、验证、获取信息等功能。
用法一:使用DBCC SHRINKDATABASE语句收缩数据库
使用DBCC SHRINKDATABASE语句可以收缩指定数据库中的数据文件和日志文件的大小,其基本语法结构如下:
基本语法:
DBCC SHRINKDATABASE(数据库名|数据库ID|0,目标百分比,NOTRUNCATE|TRUNCATEONLY)
在DBCC SHRINKDATABASE后面需要指定要收缩的数据库名称或数据库ID。如果使用0,则收缩当前数据库。
参数“目标百分比”,可选,只对收缩数据文件有效。使用此参数后,文件末尾已分配的页移动到文件前面未分配的页。文件末尾的可用空间不会返回给操作系统,文件的物理大小也不会改变。
参数“TRUNCATEONLY”,可选,也只对收缩数据文件有效。使用此参数后,文件末尾的所有可用空间都会释放给操作系统,但不在文件内部执行页移动操作。因此,使用此参数数据文件只能收缩最近分配的区。
例如,收缩数据库db_test,剩余可用空间为10%,代码如下:
DBCC SHRINKDATABASE(db_test,10)
需要注意的是,数据库空间并不是越小越好。因为大多数数据库都需要预留一部分空间,以供日常操作使用。因
此,在收缩数据库时,如果数据库文件的大小不变或者反而变大了,则说明收缩空间是常规操作所需要的,这是
,就不需要收缩数据库了。
用法二:使用DBCC SHRINKDATABASE语句收缩指定的数据库文件
基本语法:
DBCC SHRINKFILE(文件名|文件ID|0,EMPTYFILE,收缩后文件的大小,NOTRUNCATE|TRUNCATEONLY)
参数文件名,必填,指要收缩的数据库文件的逻辑名称。
参数EMPTYFILE,可选,数据库引擎将当前文件的所有数据都迁移到同一文件组中的其他文件,然后可以使用
ALTER DATABASE语句来删除该文件。
参数"收缩后文件的大小"用整数表示,单位为MB。如果未指定此参数,则文件减少到默认的文件大小。
参数“TRUNCATEONLY”,可选,也只对收缩数据文件有效。使用此参数后,文件末尾的所有可用空间都会释放给操作系统,但不在文件内部执行页移动操作。因此,使用此参数数据文件只能收缩最近分配的区。
例如:将数据库db_test中的db_test1文件收缩的20MB,代码如下:
DBCC SHRINKFILE(db_test1,20);
例如:使用EMPTYFILE关键字清空数据库文件。
将数据库db_test中的db_test1文件清空,然后使用ALTER DATABASE语句来删除该文件,代码如下:
DBCC SHRINKFILE(db_test1,EMPTYFILE) GO ALTER DATABASE db_test1 REMOVE FILE dbtest1
例如:有时候日志文件会变得很大,可以使用DBCC SHRINKFILE来收缩日志文件,代码如下:
DBCC SHRINKFILE (db_test_Log, 1);
----------end---------
发布订阅 分发数据库日志 清理
日志

查询分发服务器占用情况的SQL
use distribution;
GO
select top 10 a.tablename,a.SCHEMANAME,sum(a.TotalSpaceMB) TotalSpaceMB,sum(a.RowCounts) RowCounts
from (
SELECT
t.NAME AS TableName,
s.Name AS SchemaName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 AS TotalSpaceKB,
CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
SUM(a.used_pages) * 8 AS UsedSpaceKB,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS UnusedSpaceKB,
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN
sys.schemas s ON t.schema_id = s.schema_id
GROUP BY
t.Name, s.Name, p.Rows) a
GROUP BY a.tablename,a.SCHEMANAME
order by sum(a.TotalSpaceMB) desc接下来就是如何清理了
方案1:执行EXEC dbo.sp_MSdistribution_cleanup @min_distretention = 0, @max_distretention = 72,结果等了2个小时无任何效果(这种情况下就比较数据量少的情况)无奈放弃
方案2:通过Delete Top(500000) MSrepl_commands 与MSrepl_transactions 每次删除50万条数据,这个方案是有效果,数据量大还要多次且时间长 还是比较久 但是分发数据库的日志也会不断增大

USE [distribution]
go
backup log [distribution] with no_log
go
dbcc shrinkdatabase ([distribution])方案3(最终成功的方案):通过TRUNCATE TABLE语句实现数据删除,这个也是最终成功的方案
在执行TRUNCATE TABLE MSrepl_commands 与TRUNCATE TABLE MSrepl_transactions前为了不让其他进程占用分发数据库可以通过”查看日志读取器代理状态“先停止日志往MSrepl_commands 的写入
需要说明的是在MSrepl_transactions有3千万条数据执行时间不到1秒
MSrepl_commands 表因为数据量大太执行的时间达到5分钟之多,强调如果数据量大要耐心等待。
到了此时我以为已经万事大吉了,但是想多了,真正完成还需要继续完成下面的步骤
首先我发现空间没有减少,什么原因呢:分发数据库没有回收, 执行完TRUNCATE后一定要回收一下数据库,通过命令或菜单操作均可。
其次在订阅服务器中发现查看同步状态不能启动代理,会提示:进程无法在“CRM-XXX”上执行“sp_repldone/sp_replcounters”
可以执行 EXEC sp_repldone @xactid =NULL, @xact_segno =NULL, @numtrans = 0, @time =0, @reset =1; EXEC sp_replflush然后重启一下SQL服务
如果发现还会有错误提示,如订阅服务器提示数据不一致查询不到等问题可以重新发布一下,在订阅中重新初始化
具体操作:在本地发布中找到发布的事务,右击选择”重新初始化所有订阅“,完成重新发布订阅
到这里就完成了分发服务器中表MSrepl_commands和表MSrepl_transactions的清理工作。
但是订阅服务器重新初始化后会发现非聚集索引不见了,我是这样解决的,先在分发库中找到所有自定义的索引,然后再订阅数据中执行一遍
查询所有自定义索引的SQL如下,因为我建的索引都是以index开头的,其他有需要可以自己修改一下
SELECT idx.name 索引名称,obj.name 表名,col.name 索引字段名
,'create index '+idx.name +' on '+obj.name +'('+col.name +')'+';' 创建索引语句
FROM sysindexes idx
JOIN sysindexkeys idxkey ON idx.id=idxkey.id AND idx.indid=idxkey.indid
JOIN sysobjects obj ON idxkey.id=obj.id
JOIN syscolumns col ON idxkey.id=col.id AND idxkey.colid=col.colid
WHERE idx.indid NOT IN(0,255) AND idx.name LIKE 'index%' AND obj.xtype='U'
--AND obj.name='sms_saleorder' --查指定表
ORDER BY obj.name,idx.name,col.name