开源大模型发展汇总
1. 大模型发展&概况
a. 发展线路图

其中基础模型如下:

- 大部分不开源,而OPT、BLOOM、LLaMA 三个模型是主要面向开源促进研究,聊天机器人场景开源的Open Assistant(huggingface)
- 中文有一些GLM,百川,MOSS,伶荔 (Linly)等
指令微调模型如下:
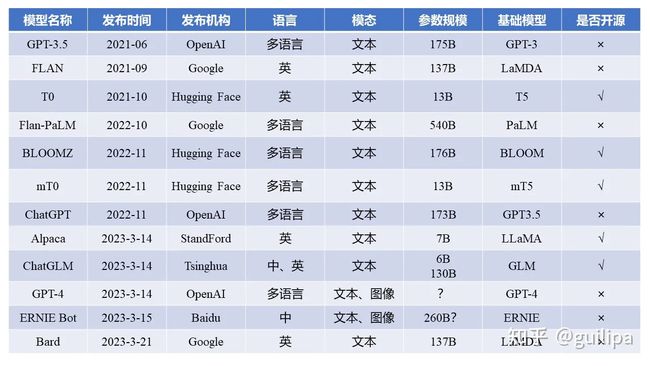
微调模型依赖关系:

b. 中文相关大模型
6月 SuperCLUE 中文大模型总排行榜
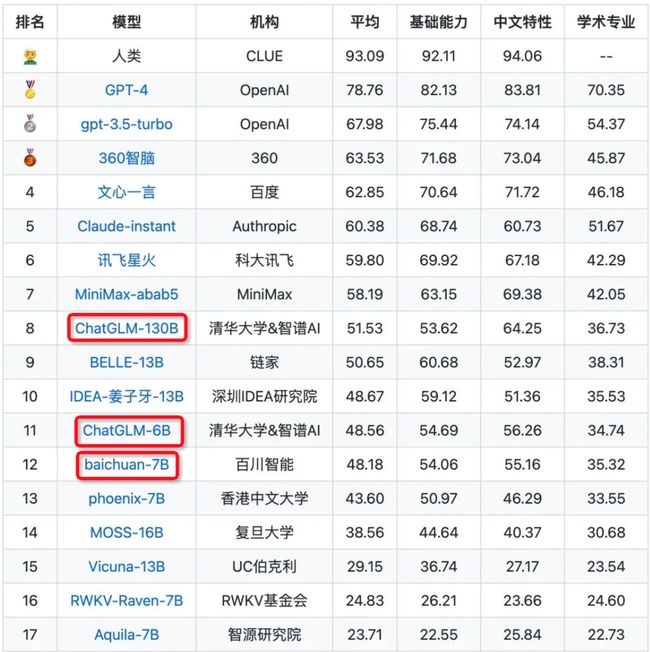
6月SuperCLUE基础能力榜单

6月SuperCLUE-70亿参数量级榜单

ps:
7.11 百川发布13B模型,超过ChatGLM 130B非开源模型
7.11 Claude2发布,个人通过app和pc免费提供,商用 API 收费。超过chatgpt3.5-turbo。与gpt4比各有优势。价格远低于ChatGPT
c. 支持中文的通用大模型概况
LLaMA
meta 开源
作者在20个benchmarks上验证了Zero-shot和Few-shot的效果。从效果上看上是非常不错的,似乎证明了训练数据的规模可以弥补模型规模的不足。
基于公开数据集
小参数媲美大参数模型
130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过参数量达 1750 亿的 GPT-3,而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B
- 训练:?
- 运行:1*V100
ChatGLM(清华+智普ai)6B开源
对话模型,ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
- 训练:100*A100
- 运行:1*3090(10G显存)
百川(王小川)
baichuan-inc/Baichuan-13B-Chat · Hugging Face
基于LLaMA 源码重头训练的基座模型
目前最大中文开源模型(40层,GPT4 120层)13B模型中文数据集上已超过大部分国外开源
训练:100*A100
运行:1*3090 (16G显存)

MOSS(复旦)
对话机器人,体验地址:MOSS 类ChatGPT的开源项目。《流浪地球》
MOSS 是一个支持中英双语和多种插件的开源对话语言模型, moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100/A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。
MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力
支持:使用搜索引擎、文生图、计算器、解方程。支持插件
- 训练:?
- 运行:1*A100 、2*3090(1w),单卡A100占用显存30G
利玲(Linly)
- 公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
- 项目具有高兼容性和易用性,提供可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式。
目前公开可用的模型有:
- Linly-Chinese-LLaMA:中文基础模型,基于 LLaMA 在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B 正在训练中。
- Linly-ChatFlow:中文对话模型,在 400 万指令数据集合上对中文基础模型指令精调,现已开放 7B、13B 对话模型。
- Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
进行中的项目:
Linly-Chinese-BLOOM:基于 BLOOM 中文增量训练的中文基础模型,包含 7B 和 175B 模型量级,可用于商业场景。
- 训练:32*A100
- 运行:?
- CPM-Bee —— 中英文双语大语言模型
体验地址:CPM-Bee | OpenBMB
基座模型。工程院院士牵头。北大、北航、百度等参与的开放社区
基础任务,包括:文字填空、文本生成、翻译、问答、评分预测、文本选择题等等
开源可商用
- Chinese-Vicuna —— 基于 LLaMA 的中文大语言模型
Chinese-Vicuna 是一个中文低资源的 LLaMA+Lora 方案。
项目包括
- finetune 模型的代码
- 推理的代码
- 仅使用 CPU 推理的代码 (使用 C++)
- 下载 / 转换 / 量化 Facebook llama.ckpt 的工具
- 其他应用
- Chinese-LLaMA-Alpaca —— 中文 LLaMA & Alpaca 大模型
Chinese-LLaMA-Alpaca 包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型。
这些模型在原始 LLaMA 的基础上,扩展了中文词汇表并使用中文数据进行二次预训练,从而进一步提高了对中文基本语义理解的能力。同时,中文 Alpaca 模型还进一步利用中文指令数据进行微调,明显提高了模型对指令理解和执行的能力。
- ChatYuan —— 对话语言大模型
ChatYuan 是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2 使用了和 v1 版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatYuan-large-v2 是 ChatYuan 系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC 甚至手机上进行推理(INT4 最低只需 400M )
- 训练:?
- 运行:消费级显卡、pc、手机。只需400M
d. 支持中文的行业/场景大模型概况
LaWGPT 是一系列基于中文法律知识的开源大语言模型
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力
本草(BenTsao)【原名:华驼 (HuaTuo)】是基于中文医学知识的 LLaMA 微调模型
此项目开源了经过中文医学指令精调 / 指令微调 (Instruct-tuning) 的 LLaMA-7B 模型。通过医学知识图谱和 GPT3.5 API 构建了中文医学指令数据集,并在此基础上对 LLaMA 进行了指令微调,提高了 LLaMA 在医疗领域的问答效果
-
轩辕: 金融领域大模型
度小满在 BLOOM-176B 的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调。
-
ProtTrans
是国内最大的蛋白质预训练模型,参数总量达到 30 亿
FYI:
1.大语言模型调研汇总
2.开源大语言模型完整列表 全网最全 - 科技 - 糯米糕资讯网
2. 主流开源基座模型对比
LLaMA、ChatGLM 和 BLOOM。(百川新发布基于LLaMA源码从新制作中英数据集训练的基座模型)
| 模型 |
训练数据 |
训练数据量 |
模型参数量 |
词表大小 |
| LLaMA |
以英语为主的拉丁语系,不包含中日韩文 |
1T/1.4T tokens |
7B、13B、33B、65B |
32000 |
| ChatGLM-6B |
中英双语,中英文比例为 1:1 |
1T tokens |
6B |
130528 |
| Bloom |
46 种自然语言和 13 种编程语言,包含中文 |
350B tokens |
560M、1.1B、1.7B、3B、7.1B、176B |
250880 |
| 百川-13B |
中英文 |
1.4T tokens |
13B |
64,000 |
| 模型 |
模型结构 |
位置编码 |
激活函数 |
layer norm |
| LLaMA |
Casual decoder |
RoPE |
SwiGLU |
Pre RMS Norm |
| ChatGLM-6B |
Prefix decoder |
RoPE |
GeGLU |
Post Deep Norm |
| Bloom |
Casual decoder |
ALiBi |
GeLU |
Pre Layer Norm |
| 百川-13B |
ALiBi |
LLaMA模型及微调模型
运行要求:1*V100
- Alpaca:斯坦福大学在 52k 条英文指令遵循数据集上微调了 7B 规模的 LLaMA。
- Vicuna:加州大学伯克利分校在 ShareGPT 收集的用户共享对话数据上,微调了 13B 规模的 LLaMA。
- baize:在 100k 条 ChatGPT 产生的数据上,对 LLaMA 通过 LoRA 微调得到的模型。
- StableLM:Stability AI 在 LLaMA 基础上微调得到的模型。
- BELLE:链家仅使用由 ChatGPT 生产的数据,对 LLaMA 进行了指令微调,并针对中文进行了优化。
ChatGLM模型及微调
ChatGLM2-6B发布:
运行要求:消费级显卡
- langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答。可基于本地知识库构建。可离线运行,私有化部署,有docker镜像
- 闻达:大型语言模型调用平台,也是知识库问答,支持多种基座模型,推荐 ChatGLM-6B 实现了类 ChatPDF 功能。闻达对资源的评估
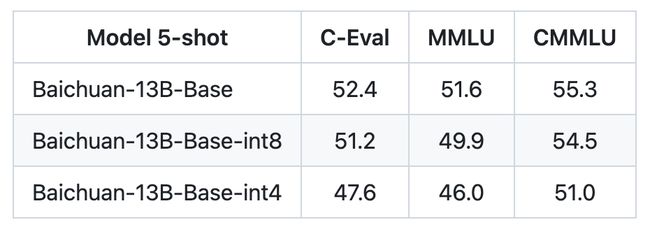
百川-13B模型及微调
百川发布时间较短,有知名度的微调模型还未出现。百川-13B的运行资源要求参考如下

3. 微调finetune中文大模型
说明:
自训练模型的初衷起源于,上面3个问题。如果在业务中确实有价值,则值得测试自训练行业匹配的模型,风险可控,性能可控,成本可控。自主可控,且可以考虑对外服务
训练成本:
不同模型,不同的finetune方法对原模型的影响不同,实际训练后才能确定。
以百川-13B为例
运行资源参考:
- 租用,阿里云服务P100(16G显存):月费3k-4k+。或12元/小时
- 自购消费级显卡1*3090(24G),9K,2手16G大概7K。另需单独服务器
finetune资源参考:
依参数量,数据量、数据构成不同等差异较大,参考网友信息
Alpaca 7B
Alpaca 7B是斯坦福大学在LLaMA 7B模型上经过52K个指令跟踪示范进行微调的模型,其性能比肩GPT-3.5(text-davinci-003),但是整个训练成本不到600美元。
在8*A100(80G)上训练了3个小时,不到100美元;使用OpenAI的API自动生成指令集,不到500美元
- 博客《Alpaca: A Strong, Replicable Instruction-Following Model》、 stanford alpaca
- 论文《Self-Instruct: Aligning Language Models with Self-Generated Instructions》、知乎-论文解读贴
gpt2_chinese
- 15G的中文语料
- 31亿个tokens
- 一张3090显卡
- 训练60多个小时
最终训练出一个中文版本的gpt2,如果有想了解如何训练中文gpt2的,可以查看这个教程
https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chinese_gpt2
chinese-chat-30m
模型参数:vocab_size=12829,num_hidden_layers=8,num_attention_heads=8,intermediate_size=1024,
max_position_embeddings=512,hidden_size=512 语言模型数据:10G数据 finetune:alpaca 51K条数据
https://huggingface.co/MLRush/chinese-chat-30m
网友测试
训练配置:4*V100,训练时长约70-80小时。33G中文数据,0.8B参数
https://github.com/enze5088/Chatterbox/blob/main/docs/model/llama-zh-base.md
4.其它相关
1.上层构建
AI agent
定位为独立的智能体,除模型微调外,目前各前沿公司重点关注方向之一。目的是在模型之上构建一个能分解处理人类需求为多重promopt的代理层。改层有望部分取代现有程序功能
2. 算力方面
量子计算发展迅速
- 华为云开发内部测试量子编程,提供开发包,小规模组织量子开发竞赛
- 谷歌最新突破。新量子计算机可以在短短几秒内完成传统超级计算机47年的计算量。
华为HiQ:HiQ量子计算
本源量子云平台:量子云-本源量子
算力提升,对未来带来无限想象空间