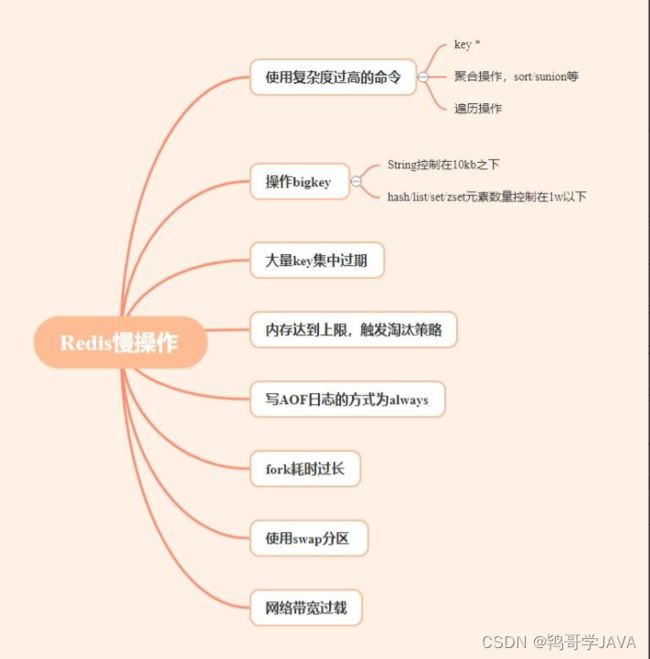
Redis有哪些慢操作?
Redis是否变慢了?
从业务服务器到Redis服务器这条调用链路中变慢的原因可能有2个
- 业务服务器到Redis服务器之间出现了网络问题,例如网络丢包,延迟比较严重
- Redis本身的执行出现问题,此时我们就需要排查Redis的问题
但是大多数情况下都是Redis服务的问题。但是应该如何衡量Redis变慢了呢?命令执行时间大于1s,大于2s?这其实并没有一个固定的标准。
例如在一个配置较高的服务器中,0.5毫秒就认为Redis变慢了,在一个配置较低的服务器中,3毫秒才认为Redis变慢了。所以我们要针对自己的机器做基准测试,看平常情况下Redis处理命令的时间是多长?
我们可以使用如下命令来监测和统计测试期间的最大延迟(以微秒为单位)
redis-cli --latency -h `host` -p `port`
比如执行如下命令
[root@VM-0-14-centos src]# ./redis-cli -h 127.0.0.1 -p 6379 --intrinsic-latency 60
Max latency so far: 1 microseconds.
Max latency so far: 12 microseconds.
Max latency so far: 55 microseconds.
Max latency so far: 124 microseconds.
Max latency so far: 133 microseconds.
Max latency so far: 142 microseconds.
Max latency so far: 982 microseconds.
Max latency so far: 1049 microseconds.
Max latency so far: 2366 microseconds.
Max latency so far: 3725 microseconds.
52881684 total runs (avg latency: 1.1346 microseconds / 1134.61 nanoseconds per run).
Worst run took 3283x longer than the average latency.
参数中的60是测试执行的秒数,可以看到最大延迟为3725微秒(3毫秒左右),如果命令的执行远超3毫秒,此时Redis就有可能很慢了!
那么Redis有哪些慢操作呢?
Redis有哪些慢操作?
Redis的各种命令是在一个线程中依次执行的,如果一个命令在Redis中执行的时间过长,就会影响整体的性能,因为后面的请求要等到前面的请求被处理完才能被处理,这些耗时的操作有如下几个部分
Redis可以通过日志记录那些耗时长的命令,使用如下配置即可
# 命令执行耗时超过 5 毫秒,记录慢日志
CONFIG SET slowlog-log-slower-than 5000
# 只保留最近 500 条慢日志
CONFIG SET slowlog-max-len 500
执行如下命令,就可以查询到最近记录的慢日志
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 32693 # 慢日志ID
2) (integer) 1593763337 # 执行时间戳
3) (integer) 5299 # 执行耗时(微秒)
4) 1) "LRANGE" # 具体执行的命令和参数
2) "user_list:2000"
3) "0"
4) "-1"
2) 1) (integer) 32692
2) (integer) 1593763337
3) (integer) 5044
4) 1) "GET"
2) "user_info:1000"
...
使用复杂度过高的命令
之前的文章我们已经介绍了Redis的底层数据结构,它们的时间复杂度如下表所示
名称 时间复杂度 dict(字典) O(1) ziplist (压缩列表) O(n) zskiplist (跳表) O(logN) quicklist(快速列表) O(n) intset(整数集合) O(n)
「单元素操作」:对集合中的元素进行增删改查操作和底层数据结构相关,如对字典进行增删改查时间复杂度为O(1),对跳表进行增删查时间复杂为O(logN)
「范围操作」:对集合进行遍历操作,比如Hash类型的HGETALL,Set类型的SMEMBERS,List类型的LRANGE,ZSet类型的ZRANGE,时间复杂度为O(n),避免使用,用SCAN系列命令代替。(hash用hscan,set用sscan,zset用zscan)
「聚合操作」:这类操作的时间复杂度通常大于O(n),比如SORT、SUNION、ZUNIONSTORE
「统计操作」:当想获取集合中的元素个数时,如LLEN或者SCARD,时间复杂度为O(1),因为它们的底层数据结构如quicklist,dict,intset保存了元素的个数
「边界操作」:list底层是用quicklist实现的,quicklist保存了链表的头尾节点,因此对链表的头尾节点进行操作,时间复杂度为O(1),如LPOP、RPOP、LPUSH、RPUSH
「当想获取Redis中的key时,避免使用keys *」 ,Redis中保存的键值对是保存在一个字典中的(和Java中的HashMap类似,也是通过数组+链表的方式实现的),key的类型都是string,value的类型可以是string,set,list等
例如当我们执行如下命令后,redis的字典结构如下
set bookName redis;
rpush fruits banana apple;
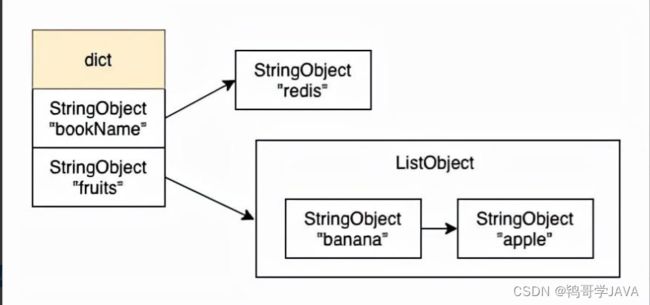
我们可以用keys命令来查询Redis中特定的key,如下所示
# 查询所有的key
keys *
# 查询以book为前缀的key
keys book*
keys命令的复杂度是O(n),它会遍历这个dict中的所有key,如果Redis中存的key非常多,所有读写Redis的指令都会被延迟等待,所以千万不用在生产环境用这个命令(如果你已经准备离职的话,祝你玩的开心)。
「既然不让你用keys,肯定有替代品,那就是scan」
scan是通过游标逐步遍历的,因此不会长时间阻塞Redis
「用用zscan遍历zset,hscan遍历hash,sscan遍历set的原理和scan命令类似,因为hash,set,zset的底层实现的数据结构中都有dict。」
操作bigkey
「如果一个key对应的value非常大,那么这个key就被称为bigkey。写入bigkey在分配内存时需要消耗更长的时间。同样,删除bigkey释放内存也需要消耗更长的时间」
如果在慢日志中发现了SET/DEL这种复杂度不高的命令,此时你就应该排查一下是否是由于写入bigkey导致的。
「如何定位bigkey?」
Redis提供了扫描bigkey的命令
$ redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01
...
-------- summary -------
Sampled 829675 keys in the keyspace!
Total key length in bytes is 10059825 (avg len 12.13)
Biggest string found 'key:291880' has 10 bytes
Biggest list found 'mylist:004' has 40 items
Biggest set found 'myset:2386' has 38 members
Biggest hash found 'myhash:3574' has 37 fields
Biggest zset found 'myzset:2704' has 42 members
36313 strings with 363130 bytes (04.38% of keys, avg size 10.00)
787393 lists with 896540 items (94.90% of keys, avg size 1.14)
1994 sets with 40052 members (00.24% of keys, avg size 20.09)
1990 hashs with 39632 fields (00.24% of keys, avg size 19.92)
1985 zsets with 39750 members (00.24% of keys, avg size 20.03)
可以看到命令的输入有如下3个部分
- 内存中key的数量,已经占用的总内存,每个key占用的平均内存
- 每种类型占用的最大内存,已经key的名字
- 每种数据类型的占比,以及平均大小
这个命令的原理就是redis在内部执行了scan命令,遍历实例中所有的key,然后正对key的类型,分别执行strlen,llen,hlen,scard,zcard命令,来获取string类型的长度,容器类型(list,hash,set,zset)的元素个数
使用这个命令需要注意如下两个问题
- 对线上实例进行bigkey扫描时,为避免ops(operation per second 每秒操作次数)突增,可以通过-i增加一个休眠参数,上面的含义为,每隔100条scan指令就会休眠0.01s
- 对于容器类型(list,hash,set,zset),扫描出的是元素最多的key,但一个key的元素数量多,不一定代表占用的内存多
「如何解决bigkey带来的性能问题?」
- 尽量避免写入bigkey
- 如果使用的是redis4.0以上版本,可以用unlink命令代替del,此命令可以把释放key内存的操作,放到后台线程中去执行
- 如果使用的是redis6.0以上版本,可以开启lazy-free机制(lazyfree-lazy-user-del yes),执行del命令的时候,也会放到后台线程中去执行
大量key集中过期
我们可以给Redis中的key设置过期时间,那么当key过期了,它在什么时候会被删除呢?
「如果让我们写Redis过期策略,我们会想到如下三种方案」
- 定时删除,在设置键的过期时间的同时,创建一个定时器。当键的过期时间来临时,立即执行对键的删除操作
- 惰性删除,每次获取键的时候,判断键是否过期,如果过期的话,就删除该键,如果没有过期,则返回该键
- 定期删除,每隔一段时间,对键进行一次检查,删除里面的过期键 定时删除策略对CPU不友好,当过期键比较多的时候,Redis线程用来删除过期键,会影响正常请求的响应
定时删除策略对CPU不友好,当过期键比较多的时候,Redis线程用来删除过期键,会影响正常请求的响应
惰性删除读CPU是比较有好的,但是会浪费大量的内存。如果一个key设置过期时间放到内存中,但是没有被访问到,那么它会一直存在内存中
定期删除策略则对CPU和内存都比较友好
redis过期key的删除策略选择了如下两种
- 惰性删除
- 定期删除
「惰性删除」 客户端在访问key的时候,对key的过期时间进行校验,如果过期了就立即删除
「定期删除」 Redis会将设置了过期时间的key放在一个独立的字典中,定时遍历这个字典来删除过期的key,遍历策略如下
- 每秒进行10次过期扫描,每次从过期字典中随机选出20个key
- 删除20个key中已经过期的key
- 如果过期key的比例超过1/4,则进行步骤一
- 每次扫描时间的上限默认不超过25ms,避免线程卡死
「因为Redis中过期的key是由主线程删除的,为了不阻塞用户的请求,所以删除过期key的时候是少量多次」。源码可以参考expire.c中的activeExpireCycle方法
为了避免主线程一直在删除key,我们可以采用如下两种方案
- 给同时过期的key增加一个随机数,打散过期时间,降低清除key的压力
- 如果你使用的是redis4.0版本以上的redis,可以开启lazy-free机制(lazyfree-lazy-expire yes),当删除过期key时,把释放内存的操作放到后台线程中执行
内存达到上限,触发淘汰策略
Redis是一个内存数据库,当Redis使用的内存超过物理内存的限制后,内存数据会和磁盘产生频繁的交换,交换会导致Redis性能急剧下降。所以在生产环境中我们通过配置参数maxmemoey来限制使用的内存大小。
当实际使用的内存超过maxmemoey后,Redis提供了如下几种可选策略。
「Redis的淘汰策略也是在主线程中执行的。但内存超过Redis上限后,每次写入都需要淘汰一些key,导致请求时间变长」
可以通过如下几个方式进行改善
- 增加内存或者将数据放到多个实例中
- 淘汰策略改为随机淘汰,一般来说随机淘汰比lru快很多
- 避免存储bigkey,降低释放内存的耗时
写AOF日志的方式为always
Redis的持久化机制有RDB快照和AOF日志,每次写命令之后后,Redis提供了如下三种刷盘机制
「当aof的刷盘机制为always,redis每处理一次写命令,都会把写命令刷到磁盘中才返回,整个过程是在Redis主线程中进行的,势必会拖慢redis的性能」
当aof的刷盘机制为everysec,redis写完内存后就返回,刷盘操作是放到后台线程中去执行的,后台线程每隔1秒把内存中的数据刷到磁盘中
当aof的刷盘机制为no,宕机后可能会造成部分数据丢失,一般不采用。
「一般情况下,aof刷盘机制配置为everysec即可」
fork耗时过长
在持久化一节中,我们已经提到「Redis生成rdb文件和aof日志重写,都是通过主线程fork子进程的方式,让子进程来执行的,主线程的内存越大,阻塞时间越长。」
可以通过如下方式优化
- 控制Redis实例的内存大小,尽量控制到10g以内,因为内存越大,阻塞时间越长
- 配置合理的持久化策略,如在slave节点生成rdb快照
使用swap分区
当机器的内存不够时,操作系统会将部分内存的数据置换到磁盘上,这块磁盘区域就是Swap分区,当应用程序再次访问这些数据的时候,就需要从磁盘上读取,导致性能严重下降
「当Redis性能急剧下降时就有可能是数据被换到Swap分区,我们该如何排查Redis数据是否被换到Swap分区呢?」
# 先找到redis-server的进程id
ps -ef | grep redis-server
# 查看redis swap的使用情况
cat /proc/$pid/smaps | egrep '^(Swap|Size)'
[root@VM-0-14-centos ~]# cat /proc/2370/smaps | egrep '^(Swap|Size)'
Size: 1568 kB
Swap: 0 kB
Size: 8 kB
Swap: 0 kB
Size: 24 kB
Swap: 0 kB
Size: 2200 kB
Swap: 0 kB
每一行Size表示Redis所用的一块内存大小,Size下面的Swap表示这块大小的内存,有多少已经被换到磁盘上了,如果这2个值相等,说明这块内存的数据都已经被换到磁盘上了
我们可以通过如下方式来解决
- 增加机器内存
- 整理内存碎片
最后我们总结一下Redis的慢操作