gen1-视频生成论文阅读
文章目录
- 摘要
- 贡献
- 算法
-
- 3.1 LDM
- 3.2 时空隐空间扩散
- 3.3表征内容及结构
-
- 内容表征
- 结构表征
- 条件机制
- 采样
- 3.4优化过程
- 实验结果
- 结论
论文: 《Structure and Content-Guided Video Synthesis with Diffusion Models》
官网: https://research.runwayml.com/gen1
github:未开源
摘要
现有编辑视频内容方法在保留结构的同时编辑视频内容需要重新训练,或者跨帧图像编辑传播过程易出错。
本文提出一种结构和内容导向的视频扩散模型,可基于视觉、文本描述编辑视频。结构表征与用户提供内容编辑之间冲突是由于两者不充分解耦导致。对此,作者基于包含各种信息的单个深度估计进行训练,用于保证结构及内容完整度。gen1基于视频及图片联合训练,用于控制时间一致性。作者实验证明在多个方面取得成功:细粒度控制、基于参考图定制生成、用户对模型结果的偏好。
贡献
作者提出的gen1,可控制结构,关注内容的视频扩散模型,由大量无标注视频及成对文本图像数据数据构成。使用单目深度估计优化表征结构,使用预训练模型embedding表征内容。
本文贡献:
1、扩展LDM至视频生成;
2、提出一个关注结构及内容模型,通过参考图或文本引导视频生成;
3、展示对视频时间、内容、结构一致性控制;
4、该模型通过在小数据集finetune,可生成特定目标视频。
算法
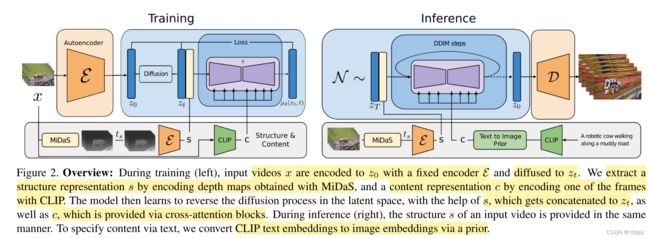
基于纹理结构表征 s s s,文本内容表征 c c c,作者训练生成模型 p ( x ∣ s , c ) p(x|s, c) p(x∣s,c),生成视频 x x x。整体架构如图2。
3.1 LDM
前向扩散过程如式1, x t − 1 x_{t-1} xt−1通过增加正态分布噪声获得 x t x_t xt;
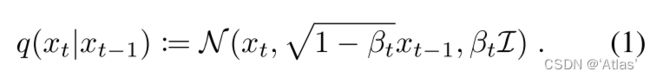
学习去噪过程如式2,3,4,其中方差固定,
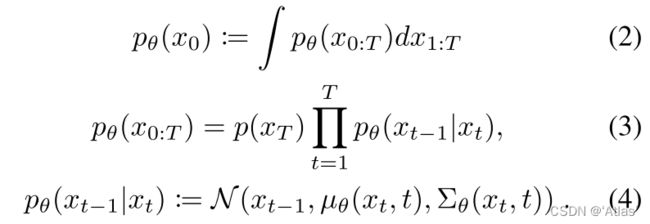
µ θ ( x t , t ) µ_θ(x_t, t) µθ(xt,t)为UNet预测均值,损失函数如式5, µ t ( x t , x 0 ) µ_t(x_t, x_0) µt(xt,x0)为前向后验函数 q ( x t − 1 ∣ x t , x 0 ) q(x_{t−1}|x_t, x_0) q(xt−1∣xt,x0)的均值。
LDM将扩散过程迁移进隐空间。
3.2 时空隐空间扩散
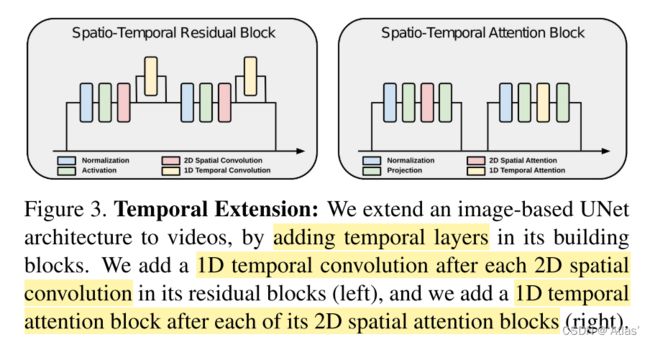
UNet主要有两个block:Residual blocks及transformer blocks,如图3,作者增加1D跨时间卷积,在时间轴学习空间中对应目标,在transformer block中引入基于帧号的位置编码;
对于 b × n × c × h × w b ×n× c × h ×w b×n×c×h×w的数据,重排为 ( b ⋅ n ) × c × h × w (b·n) × c × h × w (b⋅n)×c×h×w,用于空间层, ( b ⋅ h ⋅ w ) × c × n (b·h·w) × c × n (b⋅h⋅w)×c×n用于时间卷积, ( b ⋅ h ⋅ w ) × n × c (b · h · w) × n × c (b⋅h⋅w)×n×c用于时间self-attention
3.3表征内容及结构
受限于无视频-文本对数据,因此需要从训练视频x提取结构及内容表征;因此每个样本损失函数如式6,
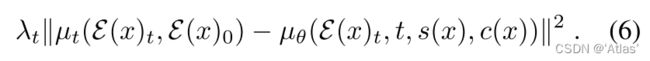
推理时,结构 s s s及内容 c c c通过输入视频 y y y及文本prompt t t t提取,如式7,x为生成结果。
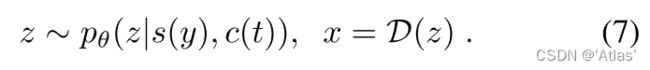
内容表征
使用CLIP的image embedding表征内容,训练先验模型,可通过text embedding采样image embedding,使得可通过image输入进行编辑视频。
解码器可视化证明CLIP embedding增加对语义及风格敏感度,同时保持目标大小、位置等几何属性不变。
结构表征
语义先验可能会影响视频中目标形状。但是可以选择合适的表征引导模型降低语义与结构之间相关性。作者发现输入视频帧深度估计提供所需结构信息。
为了保留更多结构信息,作者基于结构表征训练模型,作者通过模糊算子进行扩散与其他增加噪声方法相比,增加稳定性。
条件机制
结构表征视频各帧空间信息,作者使用concat进行使用此信息;
对于内容信息与特定位置无关,因此使用cross-attention,可将此信息传递至各位置。
作者首先基于MiDaS DPT-Large模型对所有输入帧估计深度图,然后使用 t s t_s ts轮模糊及下采样操作,训练过程 t s t_s ts随机采样 0 − T s 0-T_s 0−Ts,控制结构保留度,如图10,将扰动深度图重采样至RGB帧分辨率并使用 ϵ \epsilon ϵ进行编码,得到特征与输入 z t z_t zt进行concat输入UNet。

采样
作者使用DDIM,使用无分类器扩散引导提升采样质量;依据下式进行,
![]()
作者训练两个共享参数模型:视频模型以及图像模型,利用式8控制视频帧时间一致性,效果如图4所示。
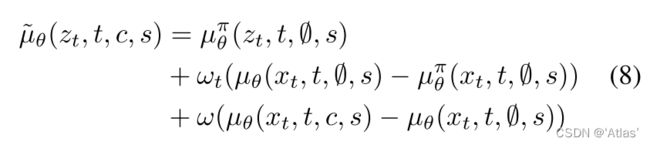
3.4优化过程
1、使用预训练LDM初始化模型;
2、基于CLIP image embeddings finetune模型;
3、引入时间联系,联合训练图像及视频;
4、引入结构信息 s s s, t s t_s ts设置为0,训练模型;
5、 t s t_s ts随机采样0-7,训练模型
实验结果
为自动生成prompt,作者使用blip获取视频description,使用GPT-3生成prompt
对于各种输入结果如图5所示,拥有多种可编辑能力,比如风格变化、环境变化、场景特性。
图8证明mask视频编辑任务;

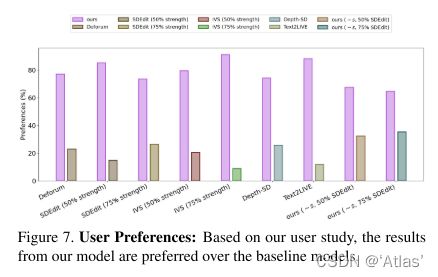
用户评判结果如图7,
帧一致性评估:计算输出视频各帧CLIP image embeddings,计算连续帧之间平均余弦相似度;
Prompt一致性评估:计算输出视频各帧CLIP image embeddings与text embeddings之间平均余弦相似度。
图6展示实验结果,日益增加的时间尺度 w s w_s ws,导致更高帧一致性但是第prompt一致性,结构尺度 t s t_s ts越大,导致更高prompt一致性,内容与输入结构一致性越低。

基于小数据集finetune方法DreamBooth,作者在15-30张图片上finetune模型,图10展示可视化结果。
结论
作者提出基于扩散模型视频生成方法。基于深度估计确保结构一致性,同时利用文本或图片进行内容控制;通过在模型中引入时间连接以及联合图像视频训练确保时间稳定性,通过控制轮次 t s t_s ts控制结构保留度。