大数据学习笔记-Yarn(二)
Yarn WebUI服务
1.1 yarn wenUI
服务,http://RMHOST:8088
打开页面,以列表的形式展示处于各种状态的各种程序
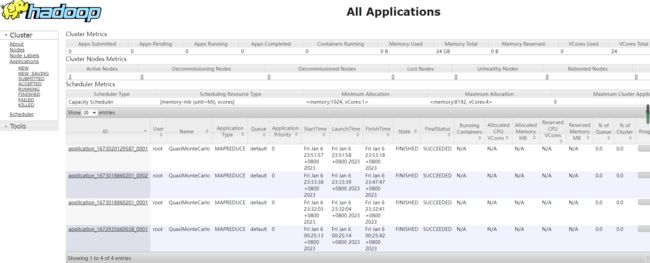
以下参数指定UI地址
UI 页面的参数介绍(图片来源黑马程序员教程)

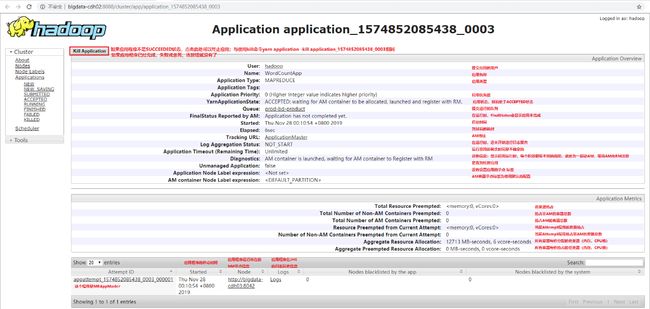
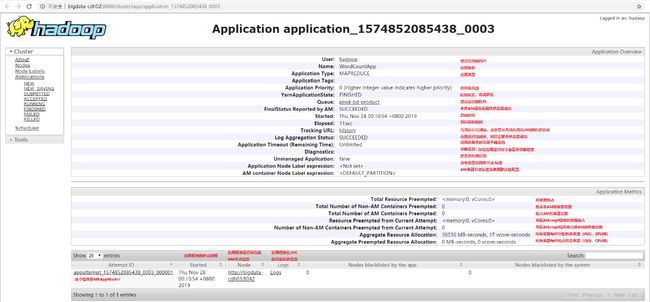
1.2 Job HistoryServer服务
仅存储已经完成的Mapredyce应用程序的作业历史信息,当启用JHS服务时,建议开启日志聚合功能。
配置
mapreduce.jobhistory.address
node1.itcast.cn:10020
mapreduce.jobhistory.webapp.address
node1.itcast.cn:19888
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/app-logs
yarn.log.server.url
http://node1.itcast.cn:19888/jobhistory/logs
服务启动
mapred --daemon start historyserver历史服务页面

1.3TimeLineServer
:由于Job History Server仅对MapReduce应用程序提供历史信息服务,其他程序的历史信息自己提供,如Spark自己提供的org.apache.spark.deploy.history.HistoryServer来解决应用历史信息。
为了解决这个问题Yarn新增了Timeline Server组件,以通用的方式存储和检索应用程序当前和历史信息.
到目前,有V1、V1.5和V2共三个版本,V1仅限于写入器/读取器和存储的单个实例,无法很好地扩展到小型群集之外;V2还处于alpha状态,所以在本章以V1.5
配置
yarn.timeline-service.enabled
true
yarn.resourcemanager.system-metrics-publisher.enabled
true
yarn.timeline-service.generic-application-history.enabled
true
yarn.timeline-service.hostname
node1.itcast.cn
yarn.timeline-service.http-cross-origin.enabled
true
启动服务
yarn --daemon start timelineserver
访问地址
http://node1:8188
YARN操作维护命令
Yarn给用户提供了一个脚本命令,位置${HADOOP_HOME}/bin/yarn
不带任何参数的yarn命令,会给出提示
官网指导地址https://hadoop.apache.org/docs/r3.1.4/hadoop-yarn/hadoop-yarn-site/YarnCommands.html
2.1 User用户命令
application使用方式
yarn application [option]相关操作
# 仅显示状态为SUBMITTED、ACCEPTED、RUNNING应用
yarn application -list
# 查看状态为all 的application列表
yarn application -list -appStates ALL
# 杀死某一个Application
yarn application -kill [application_id]
# 移动一个Application到default队列
yarn application -movetoqueue application_1573364048641_0004 -queue defaultjar使用方式
yarn jar xxx.jar [mainClass] args相关操作
# 执行jar包到yarn上
yarn jar hadoop-mapreduce-examples-3.1.4.jar pi 2 2applicationtempt使用方式
# attempt理解为尝试,一个app应用内部的一次尝试执行过程(AM Task)
yarn applicationattempt[option]相关操作
# 查看某个应用所有的attempt
yarn applicationattempt -list application_1614179148030_0001
# 标记applicationattempt失败
yarn applicationattempt -fail appattempt_1573364048641_0004_000001
#查看具体某一个applicationattemp的报告
yarn applicationattempt -status appattempt_1614179148030_0001_000001container使用方式
yarn container [options]相关操作
# 查看某一个applicationattempt下所有的container
yarn container -list appattempt_1614179148030_0001_000001
#logs使用方式
yarn logs -applicationId [options] queue使用方式
# 查看队列状态
yarn queue [options]node使用方式
yarn node [options]version使用方式
yarn version2.2 Admin管理员命令
管理员命令
daemonlog
nodemanager
proxyserver
resourcemanager
rmadmin
schedulerconf
scmadmin
sharedcachemanager
timelineserver
registrydns
resourcemanager|nodemanager使用方式
# 针对RM的操作命令
yarn resourcemanager [options]相关操作
#启动某个节点的resourcemanager
yarn resourcemanager
#启动某个节点的nodemanager
yarn nodemanager
# 格式化resourcemanager的RMStateStore
yarn resourcemanager -format-state-store
#删除RMStateStore中的Application
yarn resourcemanager -remove-application-from-state-store proxyserver使用方式
#启动某个节点的proxyserver,使用代理的原因是为了减少通过YARN进行基于Web的攻击的可能性。
yarn proxyserver需要在yarn-site中提前配置
yarn.web-proxy.address
node3.btks.cn:8089
daemonlog使用方式
yarn daemonlog -getlevel
yarn daemonlog -setlevel
具体操作
#查看帮助
yarn daemonlog --help
#查看RMAppImpl的日志级别
yarn daemonlog -getlevel \
node1.btks.cn:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl
#设置RMAppImpl的日志级别
yarn daemonlog -setlevel \
node1.btks.cn:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl DEBUG
rmadmin使用方式
yarn rmadmin [options]具体操作
#重新加载mapred-queues配置文件
yarn rmadmin -refreshQueues
#刷新ResourceManager的主机信息
yarn rmadmin -refreshNodes
#在ResourceManager上刷新NodeManager的资源
yarn rmadmin -refreshNodesResources
#刷新超级用户代理组映射
yarn rmadmin -refreshSuperUserGroupsConfiguration
#刷新ACL以管理ResourceManager:
yarn rmadmin -refreshAdminAcls
#获取ResourceManager服务的Active/Standby状态
yarn rmadmin -getAllServiceState
#ResourceManager服务执行健康检查,如果检查失败,RMAdmin工具将使用非零退出码退出。
yarn rmadmin -checkHealth rm1
yarn rmadmin -checkHealth rm2timelineserver使用方式
yarn timelineserver
#启动时间轴服务 通常使用下面的命令启动
yarn-daemon.sh start timelineserver
# 更常用
yarn --daemon start timelineserverYARN资源管理与隔离
管理两种资源memory和cpu资源,资源管理由Resourcemanager和NodeManager共同完成。
资源调度分配:Resourcenamager
资源隔离:NodeManager
3.1Memory资源
Yarn允许用户配置每个节点上可用的物理内存资源;
核心配置参数
#参数一:yarn.nodemanager.resource.memory-mb
该节点上YARN可使用的物理内存总量,默认是8192(MB);
如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities为true时,将会自动计算操作系统内存进行设置。
#参数二:yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2:1
#参数三:yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
#参数四:yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
#参数五:yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
#参数六:yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
YARN采用了线程监控的方法判断任务是否超量使用内存,一旦超过,则之间将其杀死。Yarn未提供Cgroups内存隔离机制。
3.2CPU资源
CPU资源的组织方式仍在探索中,当前只是非常粗粒度的实现方式
CPU被划分成虚拟CPU(CPU virtual Core),此处的虚拟CPU是YARN引入的概念
核心参数配置
#参数一:yarn.nodemanager.resource.cpu-vcores
该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值。
如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities为true时,将会自动计算操作系统CPU核数进行设置。
#参数二:yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
#参数三:yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是4。
YARN资源调度器Scheduler
资源是有限的,并且在繁忙的集群上,应用程序通常需要等待某些请求的到满足。
YARN调度程序的工作就是定义一些策略为应用程序分配资源
YARN负责应用资源分配的就是Scheduler,它是RseourceManager的核心组件之一
没有最佳,只有适合的
三种调度器
FIFOScheduler(先进先出调度器)、
Capacity Scheduler(容量调度器)、
Fair Scheduler(公平调度器)。
Apache版本YARN默认使用 Capacity Scheduler
如果需要使用其他调度器,可以在yarn-site中的yarn.resourcemanager.scheduler.class配置。
工作队列是从不同客户端收到的各种任务的集合
Yarn默认只有一个可用于提交任务的队列,队列树的结构。
在YARN中,层级有队列组织方法,它们构成一个树结构,且根队列叫做root
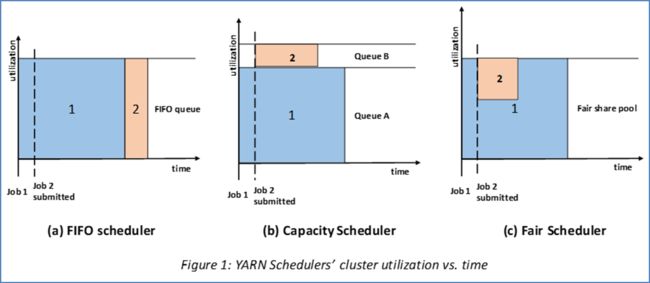
FIFOScheduler(先进先出调度器)
Hadoop1.x中的JobTracher原有的调度器实现
先提交的应用先运行,不考虑优先级和范围,适用于负载较低的小规模集群
拥有宇哥控制全局的队列queue,默认queue名称为default
优势:无需配置、先到先得、易于执行
劣势:任务优先级不会变高,大任务阻塞
配置
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler
Capacity Scheduler容量调度
允许多个组织共享整个集群资源,是Apache Hadoop3.x默认调度策略
通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源
队列内部采用先进先出
一个个队列有独立的资源,队列的结构和资源是可以配置,在队列的基础上可以划分子队列,子队列在父队列的基础上再分配资源。
特性优势
层次化的队列设计:更容易合理分配和限制资源使用
容量保证:每个队列设定容量占比,每个队列不会占用整个集群资源
安全:每个队列有严格的访问控制
弹性分配:空闲的资源可以分配
多租户使用:多个用户可以共享同一个集群
操作性:动态修改队列容量
基于用户、组的队列映射
默认配置
Hadoop3.x默认调度策略就是Capacity,官方自带默认配置HADOOP_CONF/capacity-scheduler.xml
默认全局只有一个队列default,占集群整体容量的100%
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
相关配置参数
核心就是队列的分配和使用,修改HADOOP_CONF/capacity_scheduler.xml文件可以配置队列
示例(树形结构)
yarn.scheduler.capacity.root.queues
a,b,c
yarn.scheduler.capacity.root.a.queues
a1,a2
yarn.scheduler.capacity.root.b.queues
b1,b2
队列属性
官方自带的配置
yarn.scheduler.capacity.maximum-applications
10000
Maximum number of applications that can be pending and running.
yarn.scheduler.capacity.maximum-am-resource-percent
0.1
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
yarn.scheduler.capacity.resource-calculator
org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
yarn.scheduler.capacity.root.queues
default
The queues at the this level (root is the root queue).
yarn.scheduler.capacity.root.default.capacity
100
Default queue target capacity.
yarn.scheduler.capacity.root.default.user-limit-factor
1
Default queue user limit a percentage from 0.0 to 1.0.
yarn.scheduler.capacity.root.default.maximum-capacity
100
The maximum capacity of the default queue.
yarn.scheduler.capacity.root.default.state
RUNNING
The state of the default queue. State can be one of RUNNING or STOPPED.
yarn.scheduler.capacity.root.default.acl_submit_applications
*
The ACL of who can submit jobs to the default queue.
yarn.scheduler.capacity.root.default.acl_administer_queue
*
The ACL of who can administer jobs on the default queue.
yarn.scheduler.capacity.root.default.acl_application_max_priority
*
The ACL of who can submit applications with configured priority.
For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]
yarn.scheduler.capacity.root.default.maximum-application-lifetime
-1
Maximum lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
This will be a hard time limit for all applications in this
queue. If positive value is configured then any application submitted
to this queue will be killed after exceeds the configured lifetime.
User can also specify lifetime per application basis in
application submission context. But user lifetime will be
overridden if it exceeds queue maximum lifetime. It is point-in-time
configuration.
Note : Configuring too low value will result in killing application
sooner. This feature is applicable only for leaf queue.
yarn.scheduler.capacity.root.default.default-application-lifetime
-1
Default lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
If the user has not submitted application with lifetime value then this
value will be taken. It is point-in-time configuration.
Note : Default lifetime can't exceed maximum lifetime. This feature is
applicable only for leaf queue.
yarn.scheduler.capacity.node-locality-delay
40
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
When setting this parameter, the size of the cluster should be taken into account.
We use 40 as the default value, which is approximately the number of nodes in one rack.
Note, if this value is -1, the locality constraint in the container request
will be ignored, which disables the delay scheduling.
yarn.scheduler.capacity.rack-locality-additional-delay
-1
Number of additional missed scheduling opportunities over the node-locality-delay
ones, after which the CapacityScheduler attempts to schedule off-switch containers,
instead of rack-local ones.
Example: with node-locality-delay=40 and rack-locality-delay=20, the scheduler will
attempt rack-local assignments after 40 missed opportunities, and off-switch assignments
after 40+20=60 missed opportunities.
When setting this parameter, the size of the cluster should be taken into account.
We use -1 as the default value, which disables this feature. In this case, the number
of missed opportunities for assigning off-switch containers is calculated based on
the number of containers and unique locations specified in the resource request,
as well as the size of the cluster.
yarn.scheduler.capacity.queue-mappings
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
yarn.scheduler.capacity.queue-mappings-override.enable
false
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments
1
Controls the number of OFF_SWITCH assignments allowed
during a node's heartbeat. Increasing this value can improve
scheduling rate for OFF_SWITCH containers. Lower values reduce
"clumping" of applications on particular nodes. The default is 1.
Legal values are 1-MAX_INT. This config is refreshable.
yarn.scheduler.capacity.application.fail-fast
false
Whether RM should fail during recovery if previous applications'
queue is no longer valid.
yarn.scheduler.capacity.workflow-priority-mappings
A list of mappings that will be used to override application priority.
The syntax for this list is
[workflowId]:[full_queue_name]:[priority][,next mapping]*
where an application submitted (or mapped to) queue "full_queue_name"
and workflowId "workflowId" (as specified in application submission
context) will be given priority "priority".
yarn.scheduler.capacity.workflow-priority-mappings-override.enable
false
If a priority mapping is present, will it override the value specified
by the user? This can be used by administrators to give applications a
priority that is different than the one specified by the user.
The default is false.
案例配置
yarn.scheduler.capacity.root.queues
prod,dev
yarn.scheduler.capacity.root.dev.queues
eng,science
yarn.scheduler.capacity.root.prod.capacity
40
yarn.scheduler.capacity.root.dev.capacity
60
yarn.scheduler.capacity.root.dev.maximum-capacity
75
yarn.scheduler.capacity.root.dev.eng.capacity
50
yarn.scheduler.capacity.root.dev.science.capacity
50
同步配置文件到其他节点
[root@node1 hadoop]# pwd
/export/server/hadoop-3.1.4/etc/hadoop
[root@node1 hadoop]# scp capacity-scheduler.xml root@node2:$PWD
capacity-scheduler.xml 100% 1105 1.1MB/s 00:00
[root@node1 hadoop]# scp capacity-scheduler.xml root@node3:$PWD重启yarn
stop-yarn.sh
start-yarn.sh
提交作业,指定队列
yarn jar hadoop-mapreduce-examples-3.1.4.jar pi -Dmapreduce.job.queuename=prod 2 2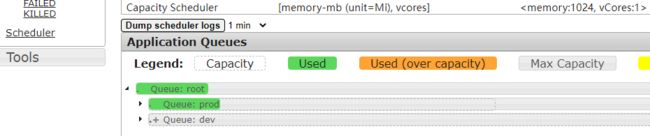
不指定队列,直接提交程序(报错)
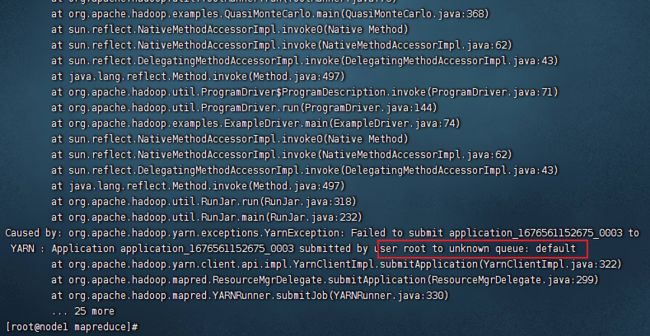
Fair Scheduler
Fair Scheduler 叫做公平调度器,提供了yarn应用程序公平的共享大型集群中资源的一种方式。为所有的应用分配公平的资源。
多个队列之间允许资源共享和抢占,用户之间公平的共享,根据任务动态调整
所有用户可以共享一个名为default的队列,可以提交指定队列

优势:
分层队列,队列可以按层次结构排列划分资源,并可以配置权重以按特定比例共享集群
基于用户或组的队列映射:可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务
资源抢占:根据应用的配置,抢占和分配资源可以是友好的或是强制的。默认不启用资源抢占
保证最小配额
允许资源共享
不限制运行数量
开启设置
yarn-site.xml 添加配置
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.scheduler.fair.allocation.file
/export/server/hadoop-3.1.4/etc/hadoop/fair-scheduler.xml
yarn.scheduler.fair.preemption
true
yarn.scheduler.fair.preemption.cluster-utilization-threshold
0.8f
yarn.scheduler.fair.user-as-default-queue
true
yarn.scheduler.fair.allow-undeclared-pools
false
fair-scheduler.xml,每隔10s加载一次,动态加载,官方参考链接
https://hadoop.apache.org/docs/r3.1.4/hadoop-yarn/hadoop-yarn-site/FairScheduler.html#Properties_that_can_be_placed_in_yarn-site.xml
官网参考翻译
10000 mb,0vcores
90000 mb,0vcores
50
0.1
2.0
fair
charlie
5000 mb,0vcores
0.5
40000 mb,0vcores
3.0
4096 mb,4vcores
30
5
案例-多租户隔离
第一步编辑yarn-site.xml
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.scheduler.fair.allocation.file
/export/server/hadoop-3.1.4/etc/hadoop/fair-scheduler.xml
yarn.scheduler.fair.preemption
true
yarn.scheduler.fair.preemption.cluster-utilization-threshold
0.8f
yarn.scheduler.fair.user-as-default-queue
true
yarn.scheduler.fair.allow-undeclared-pools
false
第二步,配置fair-scheduler
30
512mb,4vcores
20480mb,20vcores
100
fair
2.0
hadoop hadoop
hadoop hadoop
512mb,4vcores
20480mb,20vcores
100
fair
1.0
spark spark
spark spark
512mb,4vcores
20480mb,20vcores
100
fifo
1.5
hadoop,develop,spark
hadoop,develop,spark
512mb,4vcores
30720mb,30vcores
100
fair
1.0
*
第三步:配置资源同步到其他机器
scp yarn-site.xml fair-scheduler.xml root@node2:$PWD
scp yarn-site.xml fair-scheduler.xml root@node3:$PWD第四步:重启yarn
stop-yarn.sh
start-yarn.sh查看
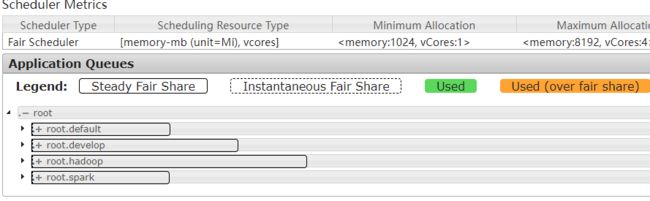
验证
准备工作
#创建一个普通用户
useradd hadoop
passwd hadoop
#创建supergroup用户组
groupadd supergroup
#将用户添加到用户组
usermod -a -G supergroup hadoop
#将用户信息同步到hadoop上面
hdfs dfsadmin -refreshUserToGroupsMappings用hadoop用户提交程序
cd /export/server/hadoop-3.1.4/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-3.1.4.jar pi 2 2
提示:实验完毕之后删除以上设置
YARN核心配置参数
给定了很多默认参数,官方
https://hadoop.apache.org/docs/r3.1.4/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
注意版本
5.1 RM核心参数
调度器类型及请求线程数据量。
# 设置YARN使用调度器,默认值:(不同版本YARN,值不一样)
yarn.resourcemanager.scheduler.class
#Apache 版本 YARN ,默认值为容量调度器;
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
#CDH 版本 YARN ,默认值为公平调度器;
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler#ResourceManager
处理调度器请求的线程数量,默认50,如果YARN运行任务Job比较多,可以将值调整大一下。
yarn.resourcemanager.scheduler.client.thread-count
5.2 NM核心参数
yarn.nodemanager.resource.detect-hardware-capabilities
#是否让yarn自己检测硬件进行配置,默认false,如果设置为true,那么就会自动探测NodeManager所在主机的内存和CPU。
yarn.nodemanager.resource.count-logical-processors-as-cores
#是否将虚拟核数当作CPU核数,默认false。
yarn.nodemanager.resource.pcores-vcores-multiplier
#确定如何将physcal核心转换为vcore的乘数。vcore的数量将计算为CPU数量*乘数。
yarn.nodemanager.resource.memory-mb
#NodeManager可以使用内存,默认8192M
yarn.nodemanager.resource.system-reserved-memory-mb
保留给非YARN进程的物理内存量(以MB为单位)。
yarn.nodemanager.resource.cpu-vcores
#NodeManager使用CPU核数,默认8个。
参数:yarn.nodemanager.pmem-check-enabled,是否开启container物理内存检查限制,默认打开;
参数:yarn.nodemanager.vmem-check-enabled,是否开启container虚拟内存检查限制,默认打开;
参数:yarn.nodemanager.vmem-pmem-ratio,虚拟内存物理内存比例,默认2.1;
5.3 Container核心参数
参数一:yarn.scheduler.minimum-allocation-mb
#可申请容器的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
参数二:yarn.scheduler.maximum-allocation-mb
#可申请的最多物理内存量,默认是8192(MB)。高于此值的内存请求将引发InvalidResourceRequestException。
参数三:yarn.scheduler.minimum-allocation-vcores
#可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
参数四:yarn.scheduler.maximum-allocation-vcores
#单个任务可申请的最多虚拟CPU个数,默认是4。高于此值的请求将引发InvalidResourceRequestException。
6、YARN Resource资源配置
6.1什么叫做资源配置
管理CPU和内存,支持可扩展的资源模型,YARN跟踪所有节点,通过定义可以包含任意可扩展的countable资源(运行时消耗,运行完回收),yarn支持使用“资源配置文件”
6.2 跟资源配置相关的参数
相关的配置参数放在三个文件中yarn-site.xml,resource-type.xml,node-resource.xml,推荐分开放,也可都放在yarn-site.xml中
资源文件配置yarn-site.xml
yarn.resource-types
resource1,resource2
The resources to be used for scheduling.
Use resource-types.xml to specify details about the individual resource types.
ResourceManager 配置resource-type
yarn.resource-types
resource1, resource2
yarn.resource-types.resource1.units
G
yarn.resource-types.resource2.minimum-allocation
1
yarn.resource-types.resource2.maximum-allocation
1024
NodeManager配置node-resource
yarn.nodemanager.resource-type.resource1
5G
yarn.nodemanager.resource-type.resource2
2m
6.3配置模板 YARN资源模型
mapreduce使用redource mapreduce像yarn申请AM容器,MapTask容器,ReduceTask容器
对每一种容器类型,都够一组对应的属性可用于设置请求的资源
yarn.app.mapreduce.am.resource.memory-mb
#将应用程序主容器请求的内存设置为以MB为单位的值。默认为1536。
yarn.app.mapreduce.am.resource.vcores
#将应用程序 master container 请求的CPU设置为该值。默认为1。
yarn.app.mapreduce.am.resource.
#将应用程序 master container 的请求的数量设置为该值。
mapreduce.map.resource.memory-mb
#将所有 map master container 请求的内存设置为以MB为单位的值。默认为1024。
mapreduce.map.resource.vcores
#将所有映射 map master container 请求的CPU设置为该值。默认为1。
mapreduce.map.resource.
#将所有 map master container 的请求的数量设置为该值。
mapreduce.reduce.resource.memory-mb
#将所有educe task container请求的内存设置为以MB为单位的值。默认为1024。
mapreduce.reduce.resource.
#将所有educe task container 的请求的数量设置为该值。