Note5:多路复用
1. 读多个文件怎么办
比如我们要写一个程序(要求如下):
1.读GPS的信息;
2.读socket里面的内容控制灯;
3.读串口内容。
while(1)
{
read(gps_fd, buf, sizeof(buf) );
read(socket_fd, buf, sizeof(buf) ); //socket_fd 会阻塞,要等待上一个函数结束
read(serialport_fd, buf, sizeof(buf) ); //serialport 也会阻塞,要等待上一个函数结束
}
为了解决这个阻塞的问题,我们通过线程来解决
// 结构体
struct worker_ctx
{
int fd;
...
} ctx;
// 主线程
pthread_create(&tid, &thread_attr, gps_worker, (void *)&ctx); // &ctx取结构体的地址
pthread_create(&tid, &thread_attr, socket_worker, arg);
pthread_create(&tid, &thread_attr, serialport_worker, arg);
// 子线程
void *gps_worker(void *arg) // 如果有n个东西传送。请用结构体打包
{
struct worker_ctx *ctx=(worker_ctx *)arg;
while(1)
{
read(gps_fd, buf, sizeof(buf) );
}
}
2. 多进程和多线程的理解
多线程:主线程是你爸妈的房间,子线程是你的房间,你们要吃饼干,都只要在客厅里面拿就可以。
多进程:你爸妈的房间在一层楼,你的房间在另外一层楼,两个房间的通信用IPC协议,我们用的socket就是这种协议。
所以多线程比较方便!!!
但是创建线程和进程都会耗费时间。比如我们开一个餐馆,来一个客户我们座位不够,我们就要去买一个凳子给他坐,又来一个客户,我们又要买一个凳子…这样就很慢,我们大量时间都在买凳子上!我们为了改进,我们就创建一个进程(线程)池——process(thread) pool——我们事先准备好凳子!这样就快一点!但是我们创建池不知道客户究竟来多少,我们凳子有可能多,也有可能少!
3. 用多路复用的原因
把三个文件描述符打包进行监听
while(1)
{
some_set_add(set, gps_fd); //把文件描述符加进set集合中
some_set_add(set, socket_fd);
some_set_add(set, serialport_fd);
rv = some_function(set); //监听set集合
if( is(gps_fd) ) //用了if就不会阻塞
{
read(gps_fd, buf, sizeof(buf) );
}
else if( is(socket_fd) )
{
read(socket_fd, buf, sizeof(buf) );
}
else if( is(serialport_fd) )
{
read(serialport_fd, buf, sizeof(buf) );
}
}
4. 五种网络I/O模型
(1)同步阻塞IO(Blocking IO)
即传统的IO模型,在linux中默认情况下所有的socket都是阻塞模式。当用户进程调用了read()这个系统调用,内核就开始了IO的第一个阶段:准备数据。对于网络IO来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候内核就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当内核一直等到数据准备好了,它就会将数据从内核中拷贝到用户内存,然后内核返回结果,用户进程才解除阻塞的状态,重新运行起来;几乎所有的程序员第一次接触到的网络编程都是从listen()、read()、write() 等接口开始的,这些接口都是阻塞型的,一个简单的改进方案是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。

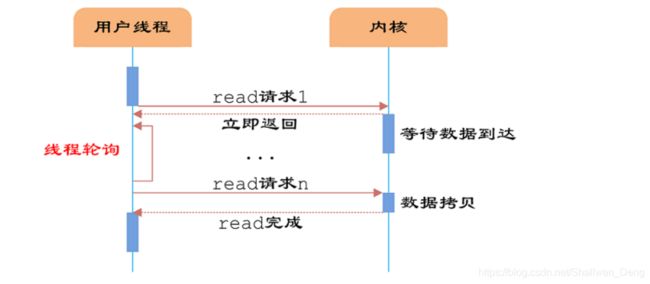
(2)同步非阻塞IO(Non-blocking IO)
默认创建的socket都是阻塞的,同步非阻塞IO是在同步阻塞IO的基础上,将socket设置为NONBLOCK,这个可以使用ioctl()系统调用设置。这样做用户线程可以在发起IO请求后可以立即返回,如果该次读操作并未读取到任何数据,用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。