大数据-玩转数据-Oracle系统知识小结
一、说明
Oracle数据库是甲骨文的核心产品,Oracle 的操作都遵循sql标准,所以各个版本在基本操作方面都变化不大。Oracle划分在大型关系数据库范畴,比较Mysql或Nosql数据库来说,还是缺少些扩容的灵活性,但传统金融、通信、电力、航空、保险、大型企业用得比较多。
二、背景知识、数据建模和Linux
1.关系数据库
关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。用户通过查询来检索数据库中的数据,而查询是一个用于限定数据库中某些区域的执行代码。关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。主流的关系数据库有oracle、db2、sqlserver、sybase、mysql等。
关系模型满足的确定约束条件称为范式,关系型数据库的三范式:
根据满足约束条件的级别不同,范式由低到高分为:1NF(第一范式)、2NF(第二范式)、3NF(第三范式)、BNF(BC范式)、4NF(第四范式),不同级别的范式性质不同。
第一范式(1NF)
1NF是最低的规范化要求。如果关系R中所有属性的值域都是简单域,其元素(即属性)不可再分,是属性项而不是属性组,那么关系模型R是满足第一范式的。通俗点也就是说一张关系表中,所有的字段的值都必须是不可再拆分的。例如:表1所示结构就不满足1NF的定义。

第二范式(2NF)
如果一个关系 R 属于 1NF,且所有的非主属性都完全依赖于主属性,则称之为第二范式(也就是除了主键以外的其他字段,都必须完全依赖于主键)。例如表3所示结构就不满足第二范式。

第三范式(3NF)
如果一个关系 R 属于 2NF,且每个非主属性不传递依赖于主属性,这种关系是 3NF。为了理解这种关系,将以表6中的字段作为讲解。

2.数据库设计
关系数据建模设计工具常用有Erwin,PowerDesigner.完成模型设计后将其转化为各种类型的对象和关系。
个人总结了数据库设计对象命名规则:
数据库对象命名规则
2.1 约定
a.数据库对象如表、字段、索引、序列、存储过程等的命名约定;
b.命名使用富有意义的英文词汇,中间以下划线分割;
c.避免使用Oracle的保留字如LEVEL、关键字如TYPE(见Oracle保留字和关键字);
d.各表之间相关列名尽量同名;命名只能使用英文字母,数字和下划线;
e.索引和数据使用单独表空间存放
2.2 表名
报表: RPT_TABLEANME
临时表:TMP_TABLEANME(一次性使用的临时表用完及时清理;非程序使用临时表,表名须包含使用人标识,以便清理;如WANGXF/ZHOUSY/CAOY/…)
系统类型:SYS_TABLEANME
子系统表采用:xxx_TABLEANME(xxx指子系统名称)
共用类的表:PUB_TABLENAME
各业务类型:T_TABLENAME(TABLENAME指业务类型);
程序及系统表名须完善表注释;
例如:
create table TMP_XXXX_01
(
LOAN_NO VARCHAR2(32) NOT NULL,
CUST_NO VARCHAR2(64),
CUST_NAME VARCHAR2(64)
) TABLESPACE PCL;
comment on table TMP_XXXX_01 is '表业务含义';
2.3 存储过程
存储过程采用PROC_TABLENAME
存储过程代码书写全部采用范例PROC_DEMO
2.4 索引
索引采用IDX_TABLENAME_SEQ (SEQ指序号),并指定对应的表空间
例如:
CREATE INDEX IDX_TMP_XXXX_01 ON TMP_XXXX_01(CUST_NO) TABLESPACE PCL_IDX;
2.5 主外键
主键采用PK_TABLENAME
外键采用FK_TABLENAME
例如:
ALTER TABLE TMP_XXXX_01 ADD CONSTRAINT PK_TMP_XXXX_01 PRIMARY KEY (LOAN_NO) USING INDEX TABLESPACE PCL_IDX;
2.6 函数
1、函数采用F_XXXX (XXXX 业务含义)
例如:
CREATE OR REPLACE FUNCTION F_GET_AGE
–该函数获取年龄
2.7 表空间命名
表空间命名:TBS_SCHEMANAME_DATA TBS_SCHEMANAME_IDX
数据文件: tbs_schemaname_dataxx.dbf
tbs_schemaname_idxxx.dbf其中xx代表序号
2.8 字段命名
1、业务含义:对应的英文缩写,切记使用关键字,尽量使用varchar2代替char类型,时间类型不要用字符串,使用NUMBER数据类型时给定长度
2、系统及程序使用表须完善字段注释
Oracle关键字:
ACCESS DECIMAL INITIAL ON START ADD NOT INSERT ONLINE SUCCESSFUL ALL DEFAULT INTEGER OPTION SYNONYM ALTER DELETE INTERSECT OR SYSDATE AND DESC INTO ORDER TABLE ANY DISTINCT IS PCTFREE THEN AS DROP LEVEL PRIOR TO ASC ELSE LIKE PRIVILEGES TRIGGER AUDIT EXCLUSIVE LOCK PUBLIC UID
BETWEEN EXISTS LONG RAW UNION BY FILE MAXEXTENTS RENAME UNIQUE FROM FLOAT MINUS RESOURCE UPDATE CHAR FOR MLSLABEL REVOKE USER CHECK SHARE MODE ROW VALIDATE CLUSTER GRANT MODIFY ROWID VALUES COLUMN GROUP NOAUDIT ROWNUM VARCHAR COMMENT HAVING NOCOMPRESS ROWS VARCHAR2 COMPRESS IDENTIFIED NOWAIT SELECT VIEW CONNECT IMMEDIATE NULL SESSION WHENEVER CREATE IN NUMBER SET WHERE CURRENT INCREMENT OF SIZE WITH DATE INDEX OFFLINE SMALLINT CHAR VARHCAR VARCHAR2 NUMBER DATE LONG CLOB BLOB BFILE INTEGER DECIMAL SUM COUNT GROUPING AVERAGE TYPE
3.Linux
见Linux专题文章。
三、体系结构、模式和事务管理
1. 几个重要的Oracle术语
要学习Oracle的体系结构,先要搞明白几个重要的术语:Oracle服务器、Oracle实例、Oracle数据库。
Oracle服务器:即Oracle server,由Oracle实例和Oracle数据库组成。
Oracle实例:即Oracle instance,是在Oracle启动的第一个阶段根据参数文件,生成的一系列的后台进程和一块共享内存SGA共同组成。
Oracle数据库:即Oracle database,是由Oracle所有的物理文件所组成。其中最关键的有:控制文件、数据文件、redo log文件等。
Oracle实例与Oracle数据库进行交互,Oracle实例来对数据库进行各种操作,从而对外提供数据库的存储和检索服务。
2. Oracle总体结构
Oracle server由Oracle instance和Oracle database组成。而Oracle instance又由后台进程和共享内存组成,所以Oracle的结构又包含了内存结构和进程结构;而Oracle database有物理文件组成,所以Oracle结构也包含了存储结构。
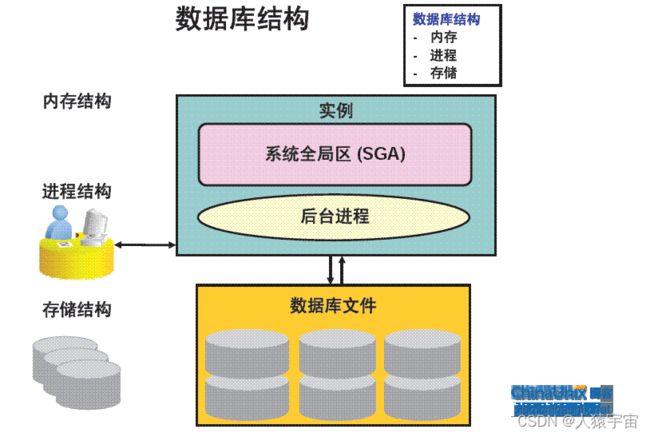
下面分别对Oracle内存结构、Oracle进程结构、Oracle存储结构进行概述,让我们对Oracle有一个对初步的概念。
3. Oracle内存结构
总体而言Oracle的内存由两大部分组成:PGA和SGA,其结构如下图所示:
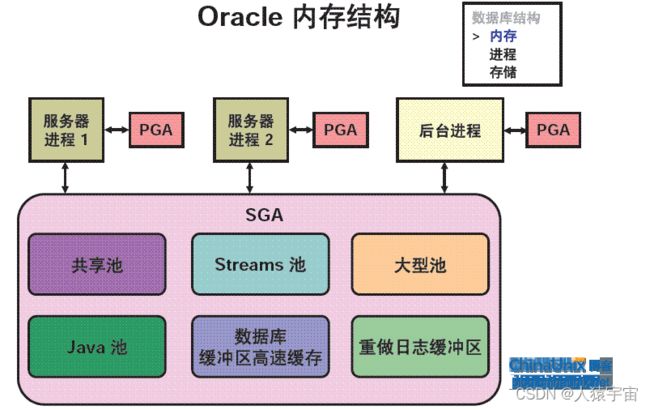
4. Oracle进程结构
Oracle的进程主要有后台进程和Server process(其实按照Linux的严格意义来说,Server process也是属于后台进程)。后台进程主要对Oracle数据库进程各种维护和操作,而Server process主要来处理用户的请求:

用户进程通过监听器来访问Oracle instacne,那么就会触发生成一个Server process进程,来对该用户进程的请求进程处理。后台进程一般有:LGWR, DBWn, ARCn, CKPT, SMON, PMON等等。
1)DBWn(database writer数据库写):
主要作用是将被修改过的buffer cache按照一定的条件写入物理磁盘。
2)LGWR(log writer,日志写):
主要作用是将log buffer中的redo log记录按照一定的条件写入联机的redo log文件。
3)CKPT(checkpoint,检查点进程):
主要作用是将检查点位置(checkpoint position)写入控制文件和数据文件的头部。
4)SMON(system monitor,系统监控进程):
主要作用是在数据库启动时,判断实例上次是否正常关闭,如果是非正常关闭,则进程实例恢复。另外,还会合并相连的可以空间。
5)PMON(process monitor,进程监控):
监控Server process, 如果Server process非正常关闭,则PMON负责清理它占用的各种资源。
5. Oracle存储结构
存储结构即物理文件的组成结构,Oracle涉及的物理文件如下所示:
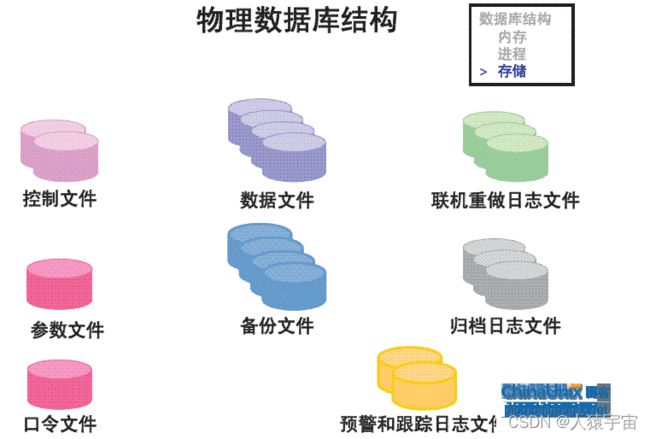
其中的控制文件、数据文件、重做日志文件是不可或缺的关键文件:
1)control file(控制文件):
包含了数据库物理结构的信息,比如各种文件的存放位置,当前数据库的运行状态等。十分重要,丢失则数据库实例不能启动。
2)datafile(数据文件):
存放数据的文件。
3)online redo log file(联机重做日志文件):
存放redo log的文件。维护数据库的一致性,用于数据库恢复。
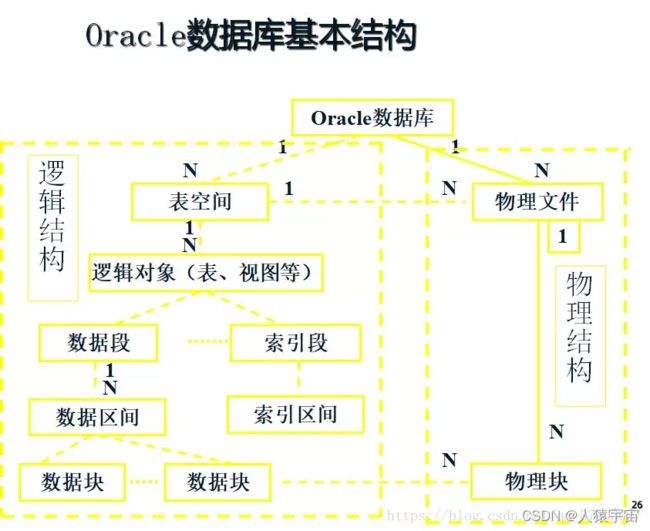
6. Oracle逻辑结构与物理结构关系
四、数据库对象管理
1. Oracle的启动与关闭
启动Oracle
1.#su - oracle 切换到 oracle 用户且切换到它的环境
2.$lsnrctl status 查看监听及数据库状态
3.$lsnrctl start 启动监听
4.$sqlplus / as sysdba 以 DBA 身份进入 sqlplus
5.SQL>startup 启动 db
停止Oracle
1.#su - oracle 切换到 oracle 用户且切换到它的环境
2.$lsnrctl stop 停止监听
3.$sqlplus / as sysdba 以 DBA 身份进入 sqlplus
4.SQL>SHUTDOWN IMMEDIATE 关闭 db
2. 手工创建数据库及用户
参考:
创建数据库文件
CREATE TABLESPACE MyDataBase LOGGING DATAFILE 'D:\Oracle\database\MyDataBase.dbf' SIZE 100M AUTOEXTEND ON NEXT 32M MAXSIZE 500M EXTENT MANAGEMENT LOCAL;
MyDataBase:数据库名称
D:\Oracle\database\MyDataBase.dbf:数据库文件目录
创建数据库临时文件
create temporary TABLESPACE MyDataBase_temp tempfile 'D:\Oracle\database\MyDataBase_temp.dbf' SIZE 100M AUTOEXTEND ON NEXT 32M MAXSIZE 500M EXTENT MANAGEMENT LOCAL;
MyDataBase_temp:数据库临时文件名称
D:\Oracle\database\MyDataBase_temp.dbf:数据库临时文件目录
创建用户与上述两个文件形成映射关系
CREATE USER username IDENTIFIED BY password DEFAULT TABLESPACE MyDataBase TEMPORARY TABLESPACE MyDataBase_temp;
username:用户名
password:密码
MyDataBase:映射的数据库名称
MyDataBase_temp:映射的数据库临时文件名称
添加用户权限
grant connect,resource,dba to username;
grant create session to username;
删除数据库
conn sys/dwh as sysdba;
drop tablespace MyDataBase including contents and datafiles;
drop tablespace MyDataBase_temp including contents and datafiles;
删除用户
drop user username cascade;
改变用户表空间
alter user 用户 quota unlimited on 表空间A;
alter user 用户 quota unlimited on 表空间B;
或者放开所有表空间
grant unlimited tablespace to 用户;
或者索性给所有权限
grant resource,connect,dba to 用户;
查询用户
select * from all_users;
授权
grant connect to XH_Bai_History_WS;
– --是授予最终用户的典型权利,最基本的权力,能够连接到ORACLE数据库中,并在对其他用户的表有访问权限时,做SELECT、UPDATE、INSERTT等操作
grant resource to XH_Bai_History_WS;
–是授予开发人员的,能在自己的方案中创建表、序列、视图等。
grant dba to XH_Bai_History_WS;
–是授予系统管理员的,拥有该角色的用户就能成为系统管理员了,它拥有所有的系统权限
revoke connect,resource from java_user;
–取消权限revoke
grant create view to java_user
–创建视图权限,一般网上找都是说的这句,但是光有这句还是无法创建
grant create view to XH_Bai_History_WS;
–授予查询权限
grant select any table to B;
–授予权限
grant select any dictionary to B;
–以上3项地后就能正常创建视图了。
3. 表空间管理
select distinct tablespace_name from dba_free_space;
SELECT A.TABLESPACE_NAME,
FILENUM,
TOTAL "TOTAL (MB)",
F.FREE "FREE (MB)",
TO_CHAR(ROUND(FREE * 100 / TOTAL, 2), '990.00') "FREE%",
TO_CHAR(ROUND((TOTAL - FREE) * 100 / TOTAL, 2), '990.00') "USED%",
ROUND(MAXSIZES, 2) "MAX (MB)"
FROM (SELECT TABLESPACE_NAME,
COUNT(FILE_ID) FILENUM,
SUM(BYTES / (1024 * 1024)) TOTAL,
SUM(MAXBYTES) / 1024 / 1024 MAXSIZES
FROM DBA_DATA_FILES
GROUP BY TABLESPACE_NAME) A,
(SELECT TABLESPACE_NAME, ROUND(SUM(BYTES / (1024 * 1024))) FREE
FROM DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) F
WHERE A.TABLESPACE_NAME = F.TABLESPACE_NAME
--查询表所涉及对象
select * from dba_source t where upper(t.TEXT) LIKE '%TMP_T_FACEBANK_LOAN_ITEM%'
--清理无用的表
DROP TABLE TMP_T_FACEBANK_LOAN_ITEM PURGE
--处理
10G:
--回收HWM
alter table &table shrink space
--重组该表中现有的行并回收HWM
alter table &table shrink space cascade
4. Oracle原用户
Sys:超级管理员(校长)
System:管理员 修改密码 解锁 授权(老师)(orcl)
system@orcl as sysdba
Alter user scott identified by 新密码
–the accout is locked
解锁:Alter user scott account unlock
Scott:普通用户 (学生)
5. 数据语言PL/SQL
1.数据定义语言(DDL):create drop alter
创建,修改,删除数据库对象(表),操作的是表的结构,不是表的数据
2.数据操作语言(DML):insert delete update ,操作是表中数据
注意:oracle事务需要手动提交
添加数据
Insert into 表名(列名,列名,…)values(值,值,…)
删除数据
Delete from 表名 【where】
更新数据
Update 表名 set 列名=值,列名=值,… 【where】
下面就数据的DML,DDL举例
1.创建表
Create table 表名(
列名 数据类型 【约束】,
列名 数据类型 【约束】,
....
列名 数据类型 【约束】
)
create table stu_b(
stuId int primary key,
stuName varchar2(50) not null,
age int check(age>18)
)
insert into stu_b(stuId,stuname,age) values(1,'小明',19);
insert into stu_b values(2,'张三',20);
select * from stu_b;
create table text_b(
txtId int primary key,
txtName varchar2(20) not null,
txtAge int check(txtAge>18)
)
insert into text_b values(1,'历史',20);
select * from text_b;
数据类型:
字符型:char varchar varchar2
Char:固定长度 char(10):abc 占10
Varchar2:可变(在存空字符时varchar存储的是空字符,varchar2存的是null)
数字型:number(m,n):数字的精度 n:小数点后几位 int float
时间:date
约束:非空(not null)检查(check)默认(default)唯一(unique)
主键(primary key)外键(foreign key)
注意:oracle没有主键自增,需要借助序列(sequence)例:6序列讲解
2.删除表
Drop table 表名 [purge]
Purge:表就会被彻底删除
drop table text_b purge;
3.找回删除的表
Flashback table 表名 to before drop;
flashback table text_b to before drop;
4.重命名
Rename 原来表名 to 新表名
rename stu_b to stu;
5.增加一列(修改表的结构)
Alter table 表名
Add 列名 数据类型 [约束]
alter table stu add phone varchar2(20);
6.删除一列
Alter table 表名
drop column 列名
alter table stu drop column age;
7.修改已有列的数据类型
Alter table 表名 modify 列名 修改类型
alter table stu modify phone varchar2(50);
8.列重命名
Alter table 表名
Rename column 原来列名 to 新名字
alter table stu rename column phone to phones;
9.查询select
Emp:雇员表 dept:部门表
-
基本查询
Select * from 表名
说明:*代表所有的列,直接写列名 -
模糊查询:like
查询条件不精确,通过关键字进行查询
%:0或n个字符
_:1个字符
select * from emp where ename like '%A%' order by empno desc;
select * from emp where ename like '_L%';
select sum(sal) from emp group by deptno;
select * from emp;
select * from dept;
- 分组查询:group by
一般聚合函数(sum,avg,max,min,count),统计
注意:1.聚合函数 2.分组列名
Order by :排序(升序,降序 desc) - 多表联合查询:两张以上表联合查询,主外键关系
注意:避免笛卡尔积,加上主外键约束关系
(1). Where
select empno,ename,sal,dname,loc from emp,dept where emp.deptno=dept.deptno;
(2). 内连接 inner join
select empno,ename,sal,dname,loc from emp inner join dept on emp.deptno=dept.deptno
(3). 外链接 :left join right join full join
主表,附表:主表数据全部显示。,附表匹配主表进行显示
主表有的列附表没有,附表以空格的形式填充
主表没有附表有的列,附表的列就不在显示
5. 子查询
查询语句嵌套了查询语句
注意:子查询必须加上()
相关子查询:子查询不可以脱离父查询而单独执行
先执行父查询,子查询利用父查询的列执行查询,父查询在利用子查询返回的结果作为查询条件
非相关子查询(独立子查询):先执行子查询(内查询),将子查询的结果父查询(外查询)的条件,子查询都可以脱离父查询而单独执行
(1). 单行子查询:子查询返回的结果一个
运算符:>,<,>=,<=,=,<>
(2). 多行子查询:子查询返回的结果又多个值
运算符:in, all, any,not in
/**
查询工资比Allen高的(非相关子查询)
*/
select sal from emp where ename='ALLEN';
select * from emp where sal>(select sal from emp where ename='ALLEN');
--和Allen同部门
select deptno from emp where ename='ALLEN';
select * from emp where deptno=(select deptno from emp where ename='ALLEN');
--比平均工资高的
select avg(sal) from emp;
select * from emp where sal>(select avg(sal) from emp);
--每部门工资最低的员工信息
select min(sal) from emp group by deptno
--多行子查询 in all any notin
select * from emp where sal in (select min(sal) from emp group by deptno);
--查询工资高于所有部门的平均工资
select avg(sal) from emp group by deptno
select * from emp where sal>all(select avg(sal) from emp group by deptno);
--查询工资高于任意部门的平均工资
select * from emp where sal>any(select avg(sal) from emp group by deptno);
--查询工资高于本部门平均工资的所有员工(相关子查询)
select * from emp e where sal>(select avg(sal) from emp where deptno=e.deptno);
--
select count(*),deptno from emp group by deptno
- 分页查询 rownum(伪列)
Rownum从1开始执行
select rownum r,deptno,dname,loc from dept
select * from (select rownum r,deptno,dname,loc from dept) where r>2 and r<5;
6.序列(掌握)
在oracle中sequence就是序号,每次取的时候它会自动增加。sequence与表没有关系
Create sequence 名称(seq_表名)
注意:需要先执行一次nextval,才能执行currval
--简单创建序列
create sequence seq_stu start with 2;
select seq_stu.nextval from dual;
--借助序列实现主键自增
insert into stu values(seq_stu.nextval,'张珊珊','126743453','上海');
操作数据:
delete from stu where stuId=2;
update stu set stuName='丽水',phones='13478564' where stuId=3;
序列字段说明
create sequence SEQ_LOG_ID
minvalue 1 --增长最小值
maxvalue 9999999999 --增长最大值,也可以设置NOMAXvalue – 不设置最大值
start with 101 --从101开始计数
increment by 1 --自增步长为1
cache 50 --设置缓存cache个序列,如果系统down掉了或者其它情况将会导致序列不连续,也可以设置为—NOCACHE防止跳号
cycle; --循环,当达到最大值时,不是从start with设置的值开始循环。而是从1开始循环
使用
insert into 表名(id,name)values(seqtest.Nextval,‘sequence 插入测试’);CurrVal:返回 sequence的当前值 NextVal:增加sequence的值,然后返回 增加后sequence值
注意:第一次NEXTVAL返回的是初始值;随后的NEXTVAL会自动增加你定义的INCREMENT BY值,然后返回增加后的值。
CURRVAL 总是返回当前SEQUENCE的值,但是在第一次NEXTVAL初始化之后才能使用CURRVAL,否则会出错。
一次NEXTVAL会增加一次 SEQUENCE的值,所以如果你在同一个语句里面使用多个NEXTVAL,其值就是不一样的。- 如果指定CACHE值,ORACLE就可以预先在内存里面放置一些sequence,这样存取的快些。cache里面的取完后,oracle自动再取一组 到cache。 使用cache或许会跳号, 比如数据库突然不正常down掉(shutdown abort),cache中的sequence就会丢失. 所以可以在create sequence的时候用nocache防止这种情况。
7.创建视图
create view user_view
as
select stuName 员工姓名,stuAge 员工年龄 from userStu;
select * from user_view
8.函数/过程/触发器
--字符码—返回字符对应十进制
select ASCII('我爱你') from dual;
select chr(52946) from dual;--参数为整数表示unicode码,返回对应的字符
--链接concat—
--concat链接两个字符串
select concat('0371-','4265324532') from dual;
--||连接符
select '0371-'||'3644532' from dual;
select concat('0319-','45836')||'转2465239' 电话码 from dual;
--首字母大写
--initcap返回字符串将其第一个字母大写,其余变小写
select initcap('hello') from dual;
--全大写
--upper返回字符串,并将其所有大写
select upper('hello') from dual;
--全小写
--lower返回字符串,并将其所有小写
select lower('HELLO') from dual;
--查找出现位置
--instr(备查字符串,要查找字符串,查找起始位置,第几次出现)
select instr('411421199603026845','1',1,3) from dual;
--补充
--lpad(原字符串,补充到达个数,补充的字符串)
select lpad('gao',10,'*#') from dual; --lpad在列的左边粘贴字符
select rpad('gao',7,'#@') from dual; --rpad在列的右边粘贴字符
select ltrim(' ltrim') from dual; --删除左边出现的字符 如空格
select rtrim('ltrimr','rm') from dual; --删除右边的字符串
--trim(type ‘字符1’ from ‘字符2’)从字符2两边开始删除字符1,如果前两个参数和from省略从字符2删除两边,type:删除方式(leading:从左边开始删除;trailing:从右边开始删除;both:默认两边删除)
select trim(leading '=' from '=trim=') from dual; --删除字符串leading左边的字符串默认两边
select trim(trailing '=' from '=trim=') from dual;--- trailing右边删除
--截取substr
--substr(字符串,起始位置,截取个数)
select substr('123843564',3,5) from dual;
--替换
select replace('全能就是好','全能','切糕') from dual;
--日期函数
--sysdate系统当前日期
Select sysdate,to_char(sysdate,’dd-mm-yyyy day’) from dual;
select sysdate+14 from dual;
--add_months增加或减去月份
select add_months(sysdate,+1) from dual;
-- month_between(date2,date1)给出date2和date1相差月份
select month_between(sysdate,hiredate),ename from emp;
--
select last_day(sysdate) from dual;
--下一个
--next_day(date,’day’)当前data下个星期的日期
select next_day(sysdate,'星期三') from dual;
--舍取小数
select abs(-10) from dual; --取正
select ceil(3.006) from dual; --ceil向上取值
select floor(3.9999) from dual; --floor向下取值
select round(2.65) from dual; --四舍五入
--trunc 截断
select trunc(3.34523,2) from dual; --截断结果3.34
select trunc(sysdate,'dd') from dual;--截断到dd天
--mod取余
select mod(9,4) from dual;
--求次方power
select power(2,2) from dual;
--开平方 sqrt
select sqrt(4) from dual;
--to_char类型转换
select to_char(sysdate,'yyyy/mm/dd') from dual;
--将数字转换字符串--点可以用D代替
select to_char(123.4,'999.9')+100 from dual; --转换成指定类型999.9
select to_char(1273494,'999,999,999')from dual;
---将字符串转换时间
select to_date('2019-03-20','yyyy-MM-dd') from dual;
--to_number(string,numeric)
--查询奖金不为空的员工数量 count不统计空值
select count(comm) from emp;
-- nvl,nvl2代替空值
--nvl(expr1,expr2)如果expr1为null返回expr2,不为null返回expr1, 注意expr1,expr2两者类型要一致
--nvl2(expr1,expr2,expr3) 如果expr1不为null返回expr2,为null返回expr3,如果expr2和expr3类型不同,expr3会转换为expr2类型。
----员工工资(基本+奖金(有奖金的返回奖金,没有0))
select sal+nvl(comm,0) from emp;
select sal+nvl2(comm,comm,0) from emp;
--nullif
比较 expr1和 expr2 的值,若二者相等,则返回 NULL,否则返回 expr1的值其中 expr1不能为 NULL
select nullif(3000,2000) from dual;
--plsql代码块
--定义变量v_ename varchar2(20);
--定义常量v_pi constant number(6,2):=3.14
declare--定义部分
v_ename varchar2(20);
begin—执行
--通过编号得到用户名
select enam into v_enam from emp where empno=&eno;-- &eno输入符号加载体
exception –异常处理部分
when no_data_fount then
dbms_output.put_line(‘用户名不存在!’);
end;--结束
declare
v_ip constant number(6,2):=3.14;
v_r number(1):=2;
v_area number(6,2);--1.数据类型 2.精度
begin
v_area:=v_pi*v_r*v_r;
dbms_output.put_line(‘面积为:’||v_area);
end;
--自动匹配变量类型
--into字句:在plsql块中查询出的数据必须借助变量输出 into 给v_emp变量
declare
v_emp emp.ename%type;
begin
select ename into v_emp from emp where empno=&eno;
dbms_output.put_line(v_emp);
end;
--rowtype匹配一行
declare--定义部分--rowtype匹配一行
v_emp emp%rowtype;
begin
select * into v_emp from emp where empno=&eon;
dbms_output.put_line(v_emp.ename||v_emp.sal);
end;
----table匹配整表
declare
--定义table类型
type v_emp_type is table of emp%rowtype
index by binary_integer;--通过索引一行行存储
--定义变量
v_emp v_emp_type;
begin
select * into v_emp(0) from emp where empno=7369;
select * into v_emp(1) from emp where empno=7499;
dbms_output.put_line(v_emp(0).ename||v_emp(1).ename);
end;
----record:自定义
declare
type v_emp_recordtype is record(--定义想要的数据
ename emp.ename%type,
total_sal number(6) --不在表里类型也可以自定义
);
v_emp v_emp_recordtype;
begin
select ename,sal+nvl(comm,0) into v_emp from emp where empno=&eno;
dbms_output.put_line('实发工资:'||v_emp.total_sal);
end;
---流程控制语句 (分支)(循环)
--分支if-eals(区间) switch-case
--oracle --if then end if; case when then else end case;
--if then end if;
--plsql块
declare
---输入
v_s number;
begin
v_s:=&s;
if v_s<60 then
dbms_output.put_line('不及格');
else
dbms_output.put_line('及格');
end if;
end;
---if then elseif else end if
declare
v_s number;
begin
v_s:=&s;
if v_s<60 then
dbms_output.put_line('不及格');
elsif v_s>=60 and v_s<70 then
dbms_output.put_line('及格');
elsif v_s>=70 and v_s<90 then
dbms_output.put_line('良好');
elsif v_s>=90 and v_s<=100 then
dbms_output.put_line('优秀');
else
dbms_output.put_line('输入有误!');
end if;
end;
--------------------------------
declare
v_empno emp.empno%type;
v_sal emp.sal%type;
v_comm emp.comm%type;
begin
v_empno:=&eno;
select sal,comm into v_sal,v_comm from emp where empno=v_empno;
if v_comm is null then
update emp set comm=v_sal*0.1 where empno=v_empno;
elsif v_comm<1000 then
update emp set comm=1000 where empno=v_empno;
else
update emp set comm=v_comm+v_comm*0.1 where empno=v_empno;
end if;
end;
select * from dept;
--case when then else end case
declare
v_deptno dept.deptno%type;
begin
v_deptno:=&deo;
case v_deptno
when 10 then dbms_output.put_line('纽约');
when 20 then dbms_output.put_line('达拉斯');
when 30 then dbms_output.put_line('芝加哥');
when 40 then dbms_output.put_line('波士顿');
else dbms_output.put_line('....');
end case;
end;
-------------------case2
declare
v_sal emp.sal%type;
begin
select sal into v_sal from emp where empno=&emo;
case
when v_sal<2000 then dbms_output.put_line('A级别工资');
when v_sal>=2000 and v_sal<3000 then dbms_output.put_line('B级别工资');
else dbms_output.put_line('C级别工资');
end case;
end;
select * from dept;
-----------------
/***循环
1.loop 2.while 3.for
*/
--loop exit when end loop
--loop
循环体
exit 【when】;--退出出口
end loop;
declare
--定义table类型
type v_dept_table is table of dept%rowtype
index by binary_integer;
---定义变量
v_dept v_dept_table;
---定义循环变量
i number:=0;
begin
loop
select * into v_dept(i) from dept where deptno=(i+1)*10;
dbms_output.put_line('编号:'||v_dept(i).deptno||'名称'||v_dept(i).dname||'地址'||v_dept(i).loc);
i:=i+1;
exit when i=4;
end loop;
end;
-----while I loop end loop
--while 表达式 loop 循环体 end loop;
declare
type v_dept_table is table of dept%rowtype
index by binary_integer;
v_dept v_dept_table;
i number:=0;
begin
while i<4 loop
select * into v_dept(i) from dept where deptno=(i+1)*10;
dbms_output.put_line('编号:'||v_dept(i).deptno||'名称'||v_dept(i).dname||'地址'||v_dept(i).loc);
i:=i+1;
end loop;
end;
-------for I in 0..number loop end loop
--for 循环变量 i in 初始表达式..终止表达式 loop 循环体 end loop;
declare
type v_dept_table is table of dept%rowtype
index by binary_integer;
v_dept v_dept_table;
begin
for i in 0..3 loop
select * into v_dept(i) from dept where deptno=(i+1)*10;
dbms_output.put_line('编号:'||v_dept(i).deptno||'名称'||v_dept(i).dname||'地址'||v_dept(i).loc);
end loop;
end;
---异常处理---
begin
insert into dept values(10,'aaa','bbb');
exception
when dup_val_on_index then
dbms_output.put_line('aaaaaa');
dbms_output.put_line('其他');
end;
---自定义异常
declare
my_exception exception;
begin
delete from emp where empno=&eno;
if sql%notfound then
raise my_exception;--raise引发
end if;
exception
when my_exception then
dbms_output.put_line('编号不存在!');
end;
---事务---
create table bankjs(
jsId int primary key,
jsMonny varchar2(20) not null
);
create table bankny(
nyId int primary key,
nyMonny varchar2(20) not null
);
insert into bankjs values(1,'100');
insert into bankny values(1,'100');
select * from bankny;
select * from bankjs;
declare
i number:=1;
begin
update bankjs set jsMonny=jsMonny+100 where jsId=1;
i:=i/0;
update bankny set nyMonny=nyMonny-100 where nyId=1;
commit;--提交
exception
when zero_divide then
rollback;--回滚
end;
---存储过程-----
--1,保存数据库中,针对相同的操作,下次再次使用不用重新编译
--2,预编译:sql--先编译—在执行
/*变量声明块:紧跟着的as (is )关键字,可以理解为pl/sql的declare关键字,用于声明变量。 */
在存储过程(PROCEDURE)和函数(FUNCTION)中没有区别,在视图(VIEW)中只能用 ,在游标(CURSOR)中只能用IS不能用AS。
--不带参
--编译的过程:并没有执行修改的操作,只是对要执行的操作进行一个语法解析等操作
create or replace procedure ifrst_procedure
is---声明
begin
--要执行的参数
update emp set comm=nvl(comm,0)+300;
end;
select * from emp;
--调用执行过程:这个时候才真正的执行
begin
ifrst_procedure;
end;
--带输入参数
--默认不写是in 入参
create or replace procedure text_in(v_empno in number)
is
v_sal emp.sal%type;
begin
select sal into v_sal from emp where empno=v_empno;
dbms_output.put_line(v_sal);
end;
begin
text_in(7369);
end;
--带输入参数输出参数
create or replace procedure text_inout(v_empno in number,v_sal out number)
is
begin
select sal into v_sal from emp where empno=v_empno;
end;
declare
v_salout emp.sal%type;
begin
text_inout(7369,v_salout);
dbms_output.put_line(v_salout);
end;
--入参数输出参数 in out-----
--in out :在执行时先作为输入参数使用,在作为输出参数
create or replace procedure tet_inout(v_inout in out number)
is
begin
select sal into v_inout from emp where empno=v_inout;
end;
-----
create or replace procedure test_inout(in_out in out number)
is
begin
select sal into in_out from emp where empno=in_out;
end;
----执行
declare
a number;
begin
a:=&a;
--test_inout(a);
tet_inout(a);
dbms_output.put_line(a);
end;
---存储过程添加---
create or replace procedure insert_data(v_dempno number,v_dname varchar2,v_loc varchar2)
is
begin
insert into dept values(v_dempno,v_dname,v_loc);
end;
--执行
begin
insert_data(50,'部门','地址');
end;
select * from dept;
----传参关联付=>
--传参方式:位置,名称,组合。
--形参和实参关联。传递参数可以不按顺序-名称传递
begin
insert_data(v_dname=>'部门1',v_loc=>'地址1',v_dempno => 60);
end;
--------函数---------
--函数-先编译:返回特定数据,函数肯定会给我们一个数据
--不带参function return
create or replace function my_func
return number –返回随机数
is
v_num number; --接受产生的随机数并返回
begin
v_num:=floor(dbms_random.value(1,10));--产生随机数
return v_num; --注意:至少有一条return语句
end;
--执行
declare
a number;
begin
a:=my_func;
dbms_output.put_line(a);
end;
--输入输出function in out return var
create or replace function my_funout(v_empno in number,v_dname out varchar2)
return varchar2
is
v_loc dept.loc%type;
begin
select dname,loc into v_loc,v_dname from dept,emp where dept.deptno=emp.deptno and emp.empno=v_empno;
return v_loc;
end;
declare
v_loc dept.loc%type;
v_dname dept.dname%type;
begin
v_loc:=my_funout(7369,v_dname);
dbms_output.put_line(v_loc);
dbms_output.put_line(v_dname);
end;
--包规范-- package
create or replace package my_package
is
pi constant number(10,7):=3.1415926;--定义常量 关键词constant :=赋值符
function getarea(ridus number) return number;--定义函数
procedure print_area;--定义过程
end my_package;
---包体-- package body
create or replace package body my_package
is
v_area number;
--实现函数
function getarea(ridus number)
return number
is
begin
v_area:=pi*ridus*ridus;
return v_area;
end;
--实现过程
procedure print_area
is
begin
dbms_output.put_line(v_area);
end;
end my_package;
------调用包.----
declare
area number;
begin
area:=my_package.getarea(4);
dbms_output.put_line(area);
my_package.print_area;
end;
--序列--
create sequence cc
start with 5
increment by 2;
select cc.currval from dual;
--------过程---------
create or replace procedure v_dept_output(v_empno in out number)
is
begin
select sal into v_empno from emp where empno=v_empno;
end;
declare
empno_sal number;
begin
empno_sal:=&编号;
v_dept_output(empno_sal);
dbms_output.put_line(empno_sal);
end;
----函数 return out—
/**
过程和函数相同点:1,先编译,再执行
2,编译直接保存在数据库中
3,带参数,参数类型相同
不同点:1,语法,函数:function 过程:procedure
3. 函数有返回值,return
什么时候使用:多个值或者不返回值用过程procedure
特定值使用函数function
**/
---通过函数输出两个数据:return 1个 利用out参数
--通过多表联合通过编号 部门 地址
create or replace function my_fun1(v_empno in number,v_loc out varchar2)
return varchar2
is
v_dname dept.dname%type;
begin
select dname,loc into v_dname,v_loc from emp,dept where dept.deptno=emp.deptno and empno=v_empno;
return v_dname;
end;
---
declare
v_dname dept.dname%type;
v_loc dept.loc%type;
begin
v_dname:=my_fun1(7369,v_loc);
dbms_output.put_line(v_loc);
dbms_output.put_line(v_dname);
end;
-----包规范----
----定义一些共有的组件,没有实现体
create or replace package my_packages1
is
ip constant number:=3.1415926;
function getarea(ridus in number) return number;--函数只用定义部分没有实现体
procedure print_area; --过程只有定义部分
end my_packages1;
----包体-----
--包体具体执行部分,是实现包规范
create or replace package body my_packages1
is --is里定义全局变量
v_area number;
---实现包规范
--实现函数
function getarea(ridus in number)
return number
is
begin
v_area:=ip*ridus*ridus;
return v_area;
end;
---实现过程
procedure print_area
is
begin
dbms_output.put_line(v_area);
end;
end my_packages1;
-----调用执行:包名.----
declare
var_arae number;
begin
var_arae:=my_packages1.getarea(5);
dbms_output.put_line(var_arae);
my_packages1.print_area;
end;
select * from emp;
--通过查询字典USER_SOURCE,可显示当前子程序及源码
Select text from user_source where name=’pack_util’;
--删除子程序
Drop procedure proc_name;
--创建索引—create index table on column
create index emp_index on emp(deptno);
select * from emp where emp.deptno='20'
--------------
--创建包规范—游标处理结果集相当java类接口
create or replace package testProduct
is
type cursorType is ref cursor;--定义一个游标变量oracle分配内存处理结果集
end testProduct;
--过程
create or replace procedure testProcedure(userId in number,userList out testProduct.cursorType)
is
begin
if userId=null or userId='' then
open userList for select * from userinfo;
else
open userList for select * from userinfo u where u.userid=userId;
end if;
end;
--申明包结构
create or replace package atii.mypackage as
type mycursor is ref cursor;
procedure queryCount(startDate in date,endDate in date,countList out mycursor);
end mypackage;
--创建包体
create or replace package body atii.mypackage as
procedure queryCount(startDate in date,endDate in date,countList out mycursor)
as
begin
open countList for
select t.createDate,count(t.createDate)
from
(select case when createtime>=(trunc(createtime)+18/24) then trunc(createtime)+1
else trunc(createtime) end createDate
from t_count ) t
where t.createDate>=to_date('2017-08-19','yyyy-MM-dd') and t.createDate<=to_date('2017-08-24','yyyy-MM-dd')
group by t.createDate
order by t.createDate;
end queryCount;
end mypackage;
----
create or replace procedure PRC_STAT_LOGIN
IS
v_username users.username%TYPE;
v_password USERS.PASSWORD%TYPE;
v_userlevel USERS.USER_LEVEL%TYPE;
begin
--声明游标 查询出每个每个用户的信息
declare cursor cursor_login is select * from users ;
--cursor cursor_name is select username from users;
begin
if not cursor_login%isopen then
open cursor_login;
end if;
loop
FETCH cursor_login INTO v_username,v_password,v_userlevel;
EXIT WHEN cursor_login%NOTFOUND;
--正常登录,返回”成功登陆”
DBMS_OUTPUT.PUT_LINE('Login successfully!');
IF v_username is NULL THEN--如用户名不存在,返回”用户名不存在”
DBMS_OUTPUT.put_line('The user is not existed!');
ELSE
IF v_userlevel = 'U' THEN--如用户名、密码都正确,但是级别不够,管理员是A,一般用户是U,那么返回”级别不够”
DBMS_OUTPUT.put_line('Low level!') ;
END IF;
end if;
end loop;
exception
when NO_DATA_FOUND THEN
DBMS_OUTPUT.put_line('No data found!');
when LOGIN_DENIED THEN --如用户名存在,密码错误,返回”密码错误”
DBMS_OUTPUT.PUT_LINE('PASSWORD ERROR');
close cursor_login;
end;
end PRC_STAT_LOGIN;
-------游标使用---------
游标分为两种:1.隐含游标用于处理select into 和DML语句
2.显示游标用于select语句返回多行数据
Begin
Delete from emp where empno=7369;--DML
IF sql%notfound then –被隐含创建了
dbms_output.put_line(‘sql起作用了’);
end if;
end;
使用显示游标语法:
1, 定义游标CURSOR cursor_name IS select_statement;
2, 打开游标OPEN cursor_name;
3, 提取数据 FETCH cursor_name INTO variable1,variable2;
4, 关闭游标 CLOSE cursor_name;
--游标:oracle分配的一块内存,通过指针针对每一行单独处理
--游标一行一行提取数据
declare
type v_cursor is ref cursor;--定义游标
test_cursor v_cursor;
test_table test_user_info%rowtype;
begin
--打开游标
--执行查询,将结果集放在内存中,等待提取,每次提取一行。
open test_cursor for select * from test_user_info;
loop –循环提取
fetch test_cursor into test_table;
exit when test_cursor%notfound;
dbms_output.put_line(test_table.user_id||'-'||test_table.user_name||'-'||test_table.sex);
end loop;
close test_cursor;--关闭游标,释放内存
end;
--------------table-------------一次性提取
declare
cursor emp_cursor is select * from emp;
type test_emp_table is table of emp%rowtype
index by binary_integer;
v_emp test_emp_table;
begin
open emp_cursor;
fetch emp_cursor bulk collect into v_emp; ----一次性全部提取到表结构中
close emp_cursor; --关闭游标
for i in v_emp.first..v_emp.last loop
dbms_output.put_line(v_table(i).user_id||'-'||v_table(i).user_name||'-'||v_table(i).sex);
end loop;
end;
------------------定义参数游标---------------------
declare –部门20员工
cursor emp_cursor(var_deptno number) is
select * from emp where deptno=v_deptno;
v_emp emp%rowtype;
begin
open emp_cursor(20);
loop
fetch emp_cursor into v_emp;
exit when emp_cursor%notfound;
dbms_output.put_line(‘编号’||v_emp.empno||’名称’v_emp.ename);
end loop;
close emp_cursor;
end;
-------------部门信息---------------
--部门编号对应员工信息
declare
--部门游标
cursor dept_cursor is
Select * from dept;
v_dept dept%rowtype;
--emp游标
cursor emp_cursor(v_deptno number) is
select * from emp where deptno=v_deptno;
begin
open dept_cursor;
loop
fetch dept_cursor into v_dept;
exit when dept_cursor%notfound;
dbms_output.put_line(‘部门编号’||v_dept.deptno);
open emp_cursor(v_dept.deptno)
loop
fetch emp_cursor into v_emp;
exit when emp_cursor%notfound;
dbms_output.put_line(‘ 员工编号’||v_emp.empno||’名称’v_emp.ename);
end loop;
close emp_cursor;
end loop;
close dept_cursor;
end;
----简化操作-----
--游标for循环简化游标处理,当使用for循环时,oracle会隐含的打开游标,提取数据,关闭游标
declare
cursor emp_cursor is
select * from emp;
begin
for emp_row in emp_cursor loop
dbms_output.put_line('编号'||emp_row.empno||'名字'||emp_row.ename);
end loop;
end;
---------当时使用游标for循环,可以直接使用子查询-----
begin
for emp_row in (select * from emp) loop –使用子查询当做内容
dbms_output.put_line('编号'||emp_row.empno||'名字'||emp_row.ename);
end loop;
end;
----游标变量-----
Declare
--游标类型
type cursor_type is ref cursor;
--定义变量
cursor_emp cursor_type;
v_emp emp%rowtypw;
begin
--打开游标
Open cursor_emp for select * from emp;
loop
fetch cursor_emp into v_emp;
exit when emp_cursor%notfound;
dbms_output.put_line(‘ 员工编号’||v_emp.empno||’名称’v_emp.ename);
end loop;
end;
--系统动态游标SYS_REFCURSOR的使用---
-- 创建表
create table test_user_info(
user_id integer primary key,--primary key
user_name varchar2(20),
sex varchar2(2)
);
-- 插入测试数据
insert into test_user_info(user_id,user_name,sex) values(1,'小明','M');
insert into test_user_info(user_id,user_name,sex) values(2,'小美','F');
insert into test_user_info(user_id,user_name,sex) values(3,'小美','w');
insert into test_user_info(user_id,user_name,sex) values(4,'小美','q');
commit;
-- 查数
select * from test_user_info;
---- 创建过程取数
create or replace procedure test_SysCursor(p_cursor out sys_refcursor)
is
begin
open p_cursor for select * from test_user_info;
end;
---sys_refcursor入参返结果集
create or replace procedure inout_SysCursor(tname Nvarchar2,out_resultSet out sys_refcursor)
is
begin
open out_resultSet for select * from test_user_info where user_name=tname;
end;
--测试
declare
v_cursor sys_refcursor;
type type_table is table of test_user_info%rowtype
index by binary_integer;
v_table type_table;
--su varchar2(20);
begin
inout_SysCursor('小美',v_cursor);
fetch v_cursor bulk collect into v_table;
for i in v_table.first..v_table.last loop
dbms_output.put_line(v_table(i).user_id||'-'||v_table(i).user_name||'-'||v_table(i).sex);
end loop;
end;
----测试1
declare
v_cursor sys_refcursor;
u test_user_info%rowtype;
begin
test_SysCursor(v_cursor);
--loop fetch v_cursor into u.user_id, u.user_name,u.sex;
loop
fetch v_cursor into u;
exit when v_cursor%notfound;
dbms_output.put_line(u.user_id||'-'||u.user_name||'-'||u.sex);
end loop;
end;
---测试2
declare
v_cursor sys_refcursor;
type test_table is table of test_user_info%rowtype
index by binary_integer;
v_table test_table;
begin
test_SysCursor(v_cursor);
fetch v_cursor bulk collect into v_table;--一次性全部提取
for i in v_table.first..v_table.last loop
dbms_output.put_line(v_table(i).user_id||'-'||v_table(i).user_name||'-'||v_table(i).sex);
end loop;
end;
---普通动态游标的创建
declare
type rc is ref cursor; -- 定义类型
cursor c is
select * from dual; -- 普通静态游标
r_cursor rc; -- 普通动态游标
sr_cursor sys_refcursor; -- 系统动态游标
begin
if (to_char(sysdate, 'mi') >= 40) then
-- ref cursor with dynamic sql
open r_cursor for 'select * from dim_employee';
open sr_cursor for 'select * from dim_org_dept';
elsif (to_char(sysdate, 'mi') <= 20) then
-- ref cursor with static sql
open r_cursor for select * from dim_org_dept;
open sr_cursor for select * from dim_employee;
else
-- ref cursor with static sql
open r_cursor for select * from dual;
open sr_cursor for select * from dual;
end if;
-- the "normal" static cursor
open c;
end;
----触发器---
1.DML触发器—在对数据库DML操作触发,并且可以对每一行或者语句操作上进行触发
2.替代触发器—专门为试图操作的一种触发器
3,系统触发器—对数据库系统事件进行触发,如启动关闭
--触发器组成
1.触发事件—DML或者DDL语句
2.触发时间,是在触发之前(before)还是之后(aftre)
3.触发操作—使用PL/sql
4.触发对象—表,视图,模式,数据库
5.触发频率,定义执行次数
--触发器调用过程,只能包含DML
DML触发器
----事件触发器
-----星期天时不能对emp进行修改操作(insert,delete,update)
Create or replace trigger tri_no_sun
Before insert or update or delete --在修改,添加,删除之前触发
On emp –在哪个表触发
Begin –被触发执行的操作
If to_char(sysdate,’day’) in (‘星期日’) then
--raise_application_error(-20000,‘今天不能修改emp表’);
case
when inserting then –条件谓词使用
raise_application_error(-20000,‘今天不能添加emp表’);
when updateing then
raise_application_error(-20001,‘今天不能修改emp表’);
when deleteing then
raise_application_error(-20002,‘今天不能删除emp表’);
end caes;
End if;
End;
测试
Delete from emp where empno=7369;
-----失效触发器
Alter trigger tri_on_sun disable;
--启动
Aletr tigger tri_on_sun enable;
--删除
Drop trigger tri_on_sun;
-----行级触发器-fo reach row-----
--当降低部门30工资触发
Create trigger no_sql
Before update of sal,comm or delete
On emp
for each row –行级触发器
when(old.deptno=30)
begin
caes
when updateing(‘sal’) then
if :new.sal<:old.sal then
raise_application_error(-20002,‘这个部门工资不能降低’);
end if;
when updateing(‘comm) then
if :new.comm<:old.comm then
raise_application_error(-20000,‘这个部门奖金不能降低’);
end if;
when deleteing then
raise_application_error(-20001,‘这个部门不能删除’);
end;
-----after触发器执行DML之后触发----
---级联更新after触发---
Create trigger case_update
After update of deptno –修改emp表之后触发
On dept
For each row
Begin
Update emp set deptno=:new.deptno where deptno=:lod.deptno;
End;
Update dept set deptno=50 where deptno=20;
------数据的备份-----
--删除一个表时,将被删除的数据通过过程添加到一个回收表,回收表在删除时被触发调用
--1.创建一个回收表,和被删除的表一样
Create table deldept(
Deptno number(7),
Dname varchar2(30),
Loc varchar2(40)
);
--2,创建过程
Create or replace procedore add_deldept(v_deptno number,v_dname varchar2,v_loc varchar2)
Is
Begin
Insert into deldept values(v_deptno,v_dname,v_loc);
End;
--触发器调用过程
create or replace trigger beifen_dept
after delete –在删除dept行之后触发
on dept
for each row –行级触发
begin
add_deldept(:old,deptno,:old,bname,:old.loc);--存储旧参数
endl
delete from dept where deptno=40;
替代触发器
--不能在复杂视图上执行DML操作,必须基于视图创建instead of 触发器
注意:只能适用于视图,不能指定before和after,必须指定for each row,只能视图上创建
Create or replace view emp_view
As
Selet deptno,count(*) total_employeer,sun(sql) total_sal from emp group by deptnol
--删除不成功
Delete from emp_view where deptno=20;
Create or replace trigger view_tri
Instead of delete
On emp_view
For each row
Begin
dbms_output.put_line(‘替代触发器创建成功’);
End;
五、数据装载、备份与恢复
1. Oracle的备份与恢复三种标准的模式
大致分为两 大类,备份恢复(物理上的)以及导入导出(逻辑上的),而备份恢复又可以根据数据库的工作模式分为非归档模式(Nonarchivelog-style) 和归档模式(Archivelog-style),通常,我们把非归档模式称为冷备份,而相应的把归档模式称为热备份,他们的关系如下所示
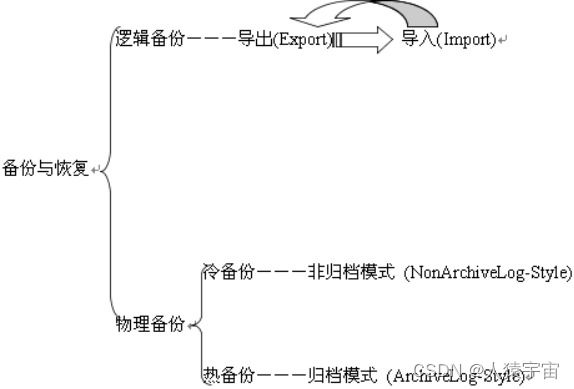
三种方式各有优点,我们做个比较(这个是用Fireworks画的,有点糙):
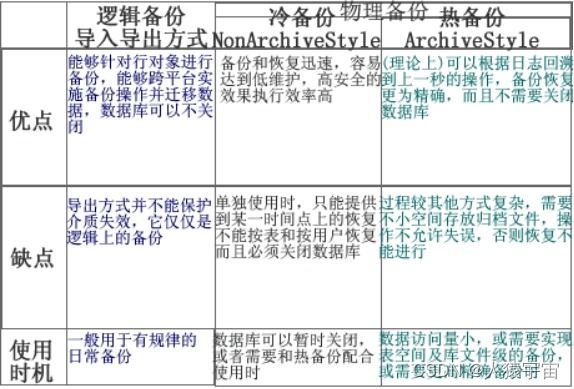
热备份和冷备份优缺点
热备份的优点是:
1.可在表空间或数据文件级备份,备份时间短。
2.备份时数据库仍可使用。
3.可达到秒级恢复(恢复到某一时间点上)。
4.可对几乎所有数据库实体作恢复。
5.恢复是快速的,在大多数情况下在数据库仍工作时恢复。
热备份的不足是:
1.不能出错,否则后果严重。
2.若热备份不成功,所得结果不可用于时间点的恢复。
3.因难维护,所以要特别仔细小心,不允许“以失败而告终”。
冷备份的优点是:
1.是非常快速的备份方法(只需拷贝文件)
2.容易归档(简单拷贝即可)
3.容易恢复到某个时间点上(只需将文件再拷贝回去)
4.能与归档方法相结合,作数据库“最新状态”的恢复。
5.低度维护,高度安全。
冷备份不足是:
1.单独使用时,只能提供到“某一时间点上”的恢复。
2.在实施备份的全过程中,数据库必须要作备份而不能作其它工作。也就是说,数据库必须是关闭状态。
3.若磁盘空间有限,只能拷贝到磁带等其它外部存储设备上,速度会很慢。
4.不能按表或按用户恢复。
2. 逻辑备份方式的方法
利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中 去。理论基础:Oracle提供的Export和Import具有三种不同的操作方式(就是备份的数据输出(入)类型):
- 1,表方式(T) 可以将指定的表导出备份;
- 2,全库方式(Full) 将数据库中的所有对象导出;
- 3,用户方式(U) 可以将指定的用户相应的所有数据对象导出;
在导入导出备份方式中,提供了很强大的一种方法,就是增量导出/导入,但是它必须作为System来完成增量的导入导出,而且只能是对整个数据库进行实施。增量导出又可以分为三种类别:
- 1,完全增量导出(Complete Export) 这种方式将把整个数据库文件导出备份;
exp system/manager inctype=complete file=20041125.dmp
(为了方便检索和事后的查询,通常我们将备份文件以日期或者其他有明确含义的字符命名)
- 2,增量型增量导出(Incremental Export) 这种方式将只会备份上一次备份后改变的结果;
exp system/manager inctype=incremental file=20041125.dmp
- 3,累积型增量导出(Cumulate Export) 这种方式的话,是导出自上次完全增量导出后数据库变化的信息。
exp system/manager inctype=cumulative file=20041125.dmp
通常情况下,DBA们所要做的,就是按照企业指定或者是自己习惯的标准(如果是自己指定的标准,建议写好计划说明),一般,我们采用普遍认可的下面的方式进行每天的增量备份:
- Mon: 完全备份(A)
- Tue: 增量导出(B)
- Wed:增量导出(C)
- Thu: 增量导出(D)
- Fri: 累计导出(E)
- Sat: 增量导出(F)
- Sun: 增量导出(G)
这样,我们可以保证每周数据的完整性,以及恢复时的快捷和最大限度的数据损失。恢复的时候,假设事故发生在周末,DBA可按这样的步骤来恢复数据库:
- 第一步:用命令CREATE DATABASE重新生成数据库结构;
- 第二步:创建一个足够大的附加回滚。
- 第三步:完全增量导入A:
imp system/manager inctype=RESTORE FULL=y FILE=A
- 第四步:累计增量导入E:
imp system/manager inctype=RESTORE FULL=Y FILE=E
- 第五步:最近增量导入F:
imp system/manager inctype=RESTORE FULL=Y FILE=F
通常情况下,DBA所要做的导入导出备份就算完成,只要科学的按照规律作出备份,就可以将数据的损失降低到最小,提供更可靠的服务。另外,DBA最好对每次的备份做一个比较详细的说明文档,使得数据库的恢复更加可靠。
3. 物理备份之冷备份(条件-NonArchiveLog):
当数据库可以暂时处于关闭状态时,我们需要将它在这一稳定时刻的数据相关文件转移到安全的区域,当数据库遭到破坏,再从安全区域将备份的数据库相关文件拷 贝回原来的位置,这样,就完成了一次快捷安全等数据转移。由于是在数据库不提供服务的关闭状态,所以称为冷备份。冷备份具有很多优良特性,比如上面图中我 们提到的,快速,方便,以及高效。一次完整的冷备份步骤应该是:
-
1,首先关闭数据库(shutdown normal)
-
2,拷贝相关文件到安全区域(利用操作系统命令拷贝数据库的所有的数据文件、日志文件、控制文件、参数文件、口令文件等(包括路径))
-
3,重新启动数据库(startup)
以上的步骤我们可以用一个脚本来完成操作:
su – oracle < sqlplus /nolog
connect / as sysdba
shutdown immediate;
!cp 文件 备份位置(所有的日志、数据、控制及参数文件);
startup;
exit;
这样,我们就完成了一次冷备份,请确定你对这些相应的目录(包括写入的目标文件夹)有相应的权限。
恢复的时候,相对比较简单了,我们停掉数据库,将文件拷贝回相应位置,重启数据库就可以了,当然也可以用脚本来完成。
4. 物理备份之热备份:(条件-ArchiveLog)
当我们需要做一个精度比较高的备份,而且我们的数据库不可能停掉(少许访问量)时,这个情况下,我们就需要归档方式下的备份,就是下面讨论的热备份。热备 份可以非常精确的备份表空间级和用户级的数据,由于它是根据归档日志的时间轴来备份恢复的,理论上可以恢复到前一个操作,甚至就是前一秒的操作。具体步骤 如下:
1,通过视图v$database,查看数据库是否在Archive模式下:
SQL> select log_mode from v$database;
如果不是Archive模式
则设定数据库运行于归档模式下:
SQL>shutdown immediate
SQL>startup mount
SQL> alter database archivelog;
SQL> alter database open;
如果Automaticarchival显示为“Enabled”,则数据库归档方式为自动归档。否则需要手工归档,或者将归档方式修改为自动归档,如:
正常shutdown数据库,在参数文件中init.ora中加入如下参数
SQL>shutdown immediate
修改init.ora:
LOG_ARCHIVE_START=TRUE LOG_ARCHIVE_DEST1=ORACLE_HOME/admin/o816/arch(归档日值存放位置可以自己定义)
SQL>startup
然后,重新启动数据库,此时Oracle数据库将以自动归档的方式工作在Archive模式下。其中参数LOG_ARCHIVE_DEST1是指定的归 档日志文件的路径,建议与Oracle数据库文件存在不同的硬盘,一方面减少磁盘I/O竞争,另外一方面也可以避免数据库文件所在硬盘毁坏之后的文件丢 失。归档路径也可以直接指定为磁带等其它物理存储设备,但可能要考虑读写速度、可写条件和性能等因素。
注意: 当数据库处在ARCHIVE模式下时,一定要保证指定的归档路径可写,否则数据库就会挂起,直到能够归档所有归档信息后才可以使用。另外,为创建一个有效 的备份,当数据库在创建时,必须履行一个全数据库的冷备份,就是说数据库需要运行在归档方式,然后正常关闭数据库,备份所有的数据库组成文件。这一备份是 整个备份的基础,因为该备份提供了一个所有数据库文件的拷贝。(体现了冷备份与热备份的合作关系,以及强大的能力)
2. 备份表空间文件:
- a,首先,修改表空间文件为备份模式
ALTER TABLESPACE tablespace_name BEGIN BACKUP;
- b,然后,拷贝表空间文件到安全区域
!CP tablespace_name D_PATH;
- c,最后,将表空间的备份模式关闭
ALTER TABLESPACE tablespace_name END BACKUP;
3,对归档日志文件的备份:
停止归档进程-->备份归档日志文件-->启动归档进程
如果日志文档比较多,我们将它们写入一个文件成为一个恢复的参考:
$ files `ls <归档文件路径>/arch*.dbf`;export files
4,备份控制文件:
SQL> alter database backup controlfile to 'controlfile_back_name(一般用2004-11-20的方式)' reuse;
当然,我们也可以将上面的东东写为一个脚本,在需要的时候执行就可以了:
脚本范例:
su – oracle < sqlplus /nolog
connect / as sysdba
ALTER TABLESPACE tablespace_name BEGIN BACKUP
!CP tablespace_name D_PATH
ALTER TABLESPACE tablespace_name END BACKUP
alter database backup controlfile to 'controlfile_back_name(一般用2004-11-20的方式)' reuse;
!files `ls <归档文件路径>/arch*.dbf`;export files
热备份的恢复,对于归档方式数据库的恢复要求不但有有效的日志备份还要求有一个在归档方式下作的有效的全库备份。归档备份在理论上可以无数据丢失,但 是对于硬件以及操作人员的要求都比较高。在我们使用归档方式备份的时候,全库物理备份也是非常重要的。归档方式下数据库的恢复要求从全备份到失败点所有的 日志都要完好无缺。
恢复步骤:LOG_ARCHIVE_DEST_1
- shutdown数据库。
- 将全备份的数据文件放到原来系统的目录中。
- 将全备份到失败点的所有归档日志放到参数LOG_ARCHIVE_DEST_1所指定的位置。
- 利用sqlplus登陆到空实例。(connect / as sysdba) 然后
startup mount
set autorecovery on
recover database;
alter database open;
这样,我们的热恢复就算完工了。
六、管理运行中的数据库
linux系统的系统日志一般位于/var/log目录下。linux的系统日志由一个叫syslog的进程管理的,如下日志都是由syslog服务驱动的。
- /var/log/ messages:记录linux系统常见的系统和服务错误。
- /var/log/lastlog:记录最后一次用户登录的时间,登录IP等信息。
- /var/log/secure:linux系统安全日志,记录用户和工作组变化情况,用户登录认证信息。
- /var/log/btmp:记录linux登录失败的用户,时间以及远程ip地址。
- /var/log/cron:记录crond计划任务服务的执行情况。
上面的日志都可以用linux系统的vi和cat命令查看。
$vi 日志名、 $cat 日志名
- oracle数据库中最重要的日志是警告日志,警告日志alert_sid.log一般位于$ORACLE_HOME/admin/ORACLE_SID/bdump目录下面。如果不知道oracle11g数据库警告日志的具体位置,可以通过以下代码查找:
SQL>show parameter background_dump_dest
打开alert_sid.log日志,主要产看ora-或者是errers关键词的,这一般是数据库发生错误的信息。
- 检查linux磁盘空间情况:$df -lh
- 检查数据库表空间使用率:
oracle的dba权限登录pl/sql development,在sql窗口输入如下内容:
SQL> select a.tablespace_name,
round((a.maxbytes / 1024 / 1024), 2) "sum MB",
round((a.bytes / 1024 / 1024), 2) "datafile MB",
round(((a.bytes - b.bytes) / 1024 / 1024), 2) "used MB",
round(((a.maxbytes - a.bytes + b.bytes) / 1024 / 1024), 2) "free MB",
round(((a.bytes - b.bytes) / a.maxbytes) * 100, 2) "percent_used"
from (select tablespace_name, sum(bytes) bytes, sum(maxbytes) maxbytes
from dba_data_files
where maxbytes != 0
group by tablespace_name) a,
(select tablespace_name, sum(bytes) bytes, max(bytes) largest
from dba_free_space
group by tablespace_name) b
where a.tablespace_name = b.tablespace_name
order by ((a.bytes - b.bytes) / a.maxbytes) desc
执行即可产看结果.
- 检查数据库文件是否为自动扩展:
在pl/sql developer的sql窗口输入下面语句:
SQL>select file_id,file_name,tablespace_name,autoextensible from dba_data_files;
- 检查RMAN备份是否出错:
$crontab -l
回车可以看到rman备份情况及对应的日志,可以打开日志进行查看。如果日志中包含RMAN-的则表示可能不成功。
- 实时监控linux操作系统:
$top
回车即可监控linux系统的cpu,内存,交换空间,IO的使用情况。
如果想停止实时监控,可以同时按ctrl+C组合键来终止。
- 查看oracle数据库进程:
$ps -ef|grep ora_
回车即可查看oracle11g所有进程情况。
- 查看oracle数据库的监听程序:
$lsnrctl status
- 查看等待事件
selectevent,sum (decode(wait_Time,0,0,1))"Prev", sum(decode(wait_Time,0,1,0)) "Curr",count(*)"Tot" from v$session_Wait group by event order by 4;
- 在线回滚段名字描述
selectname, waits, gets, waits/gets "Ratio" fromv$rollstat C, v$rollname D where C.usn= D.usn;
- 监控表空间的 I/O 比例
selectB.tablespace_name nam,
A.phyblkrd pbr,
A.phywrts pyw,
B.file_name "file",
A.phyrds pyr,
A.PHYBLKWRTpbw
fromv$filestat A, dba_data_files B
whereA.file# = B.file_id order byB.tablespace_name;
- 数据库使用的数据文件信息显示的信息是来自控制文件的
selectsubstr(C.file#,1,2) "#",substr(C.name,1,30) "Name",C.bytes, D.phyrds, D.PHYWRTS, C.status from v$datafile C, v$filestat D
whereC.file# = D.file#;
- 监控 SGA 的命中率
selecta.value + b.value"logical_reads", c. value"phys_reads", round(100 * ((a.value+b.value)-c.value) / (a.value+b.value))"BUFFER HIT RATIO"
fromv$sysstat a, v$sysstat b, v$sysstat c
wherea.statistic# = 38 and b.statistic# = 39and c.statistic# = 40;
- 监控 SGA 中字典缓冲区的命中率
selectparameter, gets,Getmisses , getmisses/(gets+getmisses)*100 "missratio",
(1-(sum(getmisses)/(sum(getmisses)+sum(getmisses))))*100 "Hit ratio"
fromv$rowcache
wheregets+getmisses <>0
groupby parameter, gets, getmisses;
- 监控 SGA 中共享缓存区的命中率,应该小于1%
selectsum(pins) "Total Pins", sum(reloads) "Total Reloads",
sum(reloads)/sum(pins)*100 libcache
fromv$librarycache;
selectsum(pinhits-reloads)/sum(pins) "hit radio",sum(reloads)/sum(pins)"reload percent" from v$librarycache;
- 监控 SGA 中重做日志缓存区的命中率,应该小于1%
SELECTname, gets, misses, immediate_gets, immediate_misses, Decode(gets,0,0, misses/gets*100) ratio1,
Decode(immediate_gets+immediate_misses,0,0,immediate_misses/(immediate_gets+immediate_misses)*100) ratio2
FROMv$latch WHERE name IN ('redo allocation ','redo copy');
- 数据库运行了一段时间后,由于不断的在表空间上创建和删除对象,会在表空间上产生大量的碎片,DBA应该及时了解表空间的碎片和可用空间情况,以决定是否要对碎片进行整理或为表空间增加数据文件。以下为引用的内容:
select tablespace_name,
count(*)chunks ,
max(bytes/1024/1024)max_chunk
fromdba_free_space
groupby tablespace_name;
上面的SQL列出了数据库中每个表空间的空闲块情况,如下所示:
以下为引用的内容:
TABLESPACE_NAME CHUNKS MAX_CHUNK
INDX 1 57.9921875
RBS 3 490.992188
RMAN_TS 1 16.515625
SYSTEM 1 207.296875
TEMP 20 70.8046875
TOOLS 1 11.8359375
USERS 67 71.3671875
其中,CHUNKS列表示表空间中有多少可用的空闲块(每个空闲块是由一些连续的Oracle数据块组成),如果这样的空闲块过多,比如平均到每个数据文件上超过了100个,那么该表空间的碎片状况就比较严重了,可以尝试用以下的SQL命令进行表空间相邻碎片的接合:
alter tablespace 表空间名coalesce;
然后再执行查看表空间碎片的SQL语句,看表空间的碎片有没有减少。如果没有效果,并且表空间的碎片已经严重影响到了数据库的运行,则考虑对该表空间进行重建。
MAX_CHUNK列的结果是表空间上最大的可用块大小,如果该表空间上的对象所需分配的空间(NEXT值)大于可用块的大小的话,就会提示ORA-1652、ORA-1653、ORA-1654的错误信息,DBA应该及时对表空间的空间进行扩充,以避免这些错误发生。
DBA要定时对数据库的连接情况进行检查,看与数据库建立的会话数目是不是正常,如果建立了过多的连接,会消耗数据库的资源。同时,对一些“挂死”的连接,可能会需要DBA手工进行清理。
- 以下的SQL语句列出当前数据库建立的会话情况:以下为引用的内容:
selectsid,serial#,username,program,machine,status
fromv$session;
输出结果为:以下为引用的内容:
SID SERIAL# USERNAME PROGRAM MACHINE STATUS
1 1 ORACLE.EXE WORK3 ACTIVE
2 1 ORACLE.EXE WORK3 ACTIVE
3 1 ORACLE.EXE WORK3 ACTIVE
4 1 ORACLE.EXE WORK3 ACTIVE
5 3 ORACLE.EXE WORK3 ACTIVE
6 1 ORACLE.EXE WORK3 ACTIVE
7 1 ORACLE.EXE WORK3 ACTIVE
8 27 SYS SQLPLUS.EXE WORKGROUP\WORK3 ACTIVE
11 5 DBSNMP dbsnmp.exe WORKGROUP\WORK3 INACTIVE
注:
SID会话(session)的ID号;
SERIAL#会话的序列号,和SID一起用来唯一标识一个会话;
USERNAME建立该会话的用户名;
PROGRAM这个会话是用什么工具连接到数据库的;
STATUS当前这个会话的状态,ACTIVE表示会话正在执行某些任务,INACTIVE表示当前会话没有执行任何操作。
如果DBA要手工断开某个会话,则执行:
altersystem kill session 'SID,SERIAL#';
注意,上例中SID为1到7(USERNAME列为空)的会话,是Oracle的后台进程,不要对这些会话进行任何操作。
- 查看undo回滚率
SELECT NAME, VALUE
FROM v$sysstat WHERE NAME IN ('user commits', 'transaction rollbacks');
七、性能调整
Oralce 性能调优(基础)可以从以下几个方面入手
1. 外部的性能问题
我们应该记住 Oracle 并不是单独运行的。因此我们将查看一下通过调整 Oracle 服务器以得到高的性能
首先从调整 Oracle 外部的环境开始。如果内存和 CPU 的资源不足的话,任何的 Oracle 调整都是没有帮助的。Oracle 并不是单独运行的。 Oracle 数据库的性能和外部的环境有很大的关系。
这些外部的条件包括有:
-
CPU :CPU 资源的不足令查询变慢。当查询超过了 Oracle 服务器的 CPU 性能时,你的数据库性能就受到 CPU 的限制。
-
内存 :可用于 Oralce 的内存数量也会影响 SQL 的性能,特别是在数据缓冲和内存排序方面。
-
网络 :大量的 Net 通信令 SQL 的性能变慢。 许多新手都错误的认为应该首先调整 Oracle
数据库,而不是先确认外部资源是否足够。实际上,如果外部环境出现瓶颈,再多的 Oracle 调整都是没有帮助的。
在检查 Oracle 的外部环境时,有两个方面是需要注意的:
-
1 、当运行队列的数目超过服务器的 CPU 数量时,服务器的性能就会受到 CPU 的限制。补救的方法是为服务器增加额外的 CPU
或者关闭需要很多处理资源的组件,例如 Oracle Parallel Query 。 -
2 、内存分页。当内存分页时,内存容量已经不足,而内存页是与磁盘上的交换区进行交互的。补救的方法是增加更多的内存,减少 Oracle
SGA 的大小,或者关闭 Oracle 的多线程服务器。
可以使用各种标准的服务器工具来得到服务器的统计数据,例如 vmstat,glance,top 和 sar 。 DBA 的目标是确保数据库服务器拥有足够的 CPU 和内存资源来处理 Oracle 的请求。
2. row-resequencing (行的重新排序)
当 Oracle 由磁盘上的一个数据文件得到一个数据块时,读的进程就必须等待物理 I/O 操作完成。磁盘操作要比数据缓冲慢 10,000 倍。因此,如果可以令 I/O 最小化,或者减少由于磁盘上的文件竞争而带来的瓶颈,就可以大大地改善 Oracle 数据库的性能。
如果系统响应很慢,通过减少磁盘 I/O 就可以有一个很快的改善。如果在一个事务中通过按一定的范围搜索 primary-key 索引来访问表,那么重新以 CTAS 的方法组织表将是你减少 I/O 的首要策略。通过在物理上将行排序为和 primary-key 索引一样的顺序,就可以加快获得数据的速度。
就象磁盘的负载平衡一样,行的重新排序也是很简单的,而且也很快。通过与其它的 DBA 管理技巧一起使用,就可以在高 I/O 的系统中大大地减少响应的时间。
在高容量的在线事务处理环境中( online transaction processing , OLTP ),数据是由一个 primary 索引得到的,重新排序表格的行就可以令连续块的顺序和它们的 primary 索引一样,这样就可以在索引驱动的表格查询中,减少物理 I/O 并且改善响应时间。这个技巧仅在应用选择多行的时候有用,或者在使用索引范围搜索和应用发出多个查询来得到连续的 key 时有效。对于随机的唯一 primary-key (主键)的访问将不会由行重新排序中得到好处。
考虑以下的一个 SQL 的查询,它使用一个索引来得到 100 行:
select salary from employee where last_name like 'B%';
这个查询将会使用 last_name_index ,搜索其中的每一行来得到目标行。这个查询将会至少使用 100 次物理磁盘的读取,因为 employee 的行存放在不同的数据块中。不过,如果表中的行已经重新排序为和 last_name_index 的一样,同样的查询又会怎样处理呢?我们可以看到这个查询只需要三次的磁盘 I/O 就读完全部 100 个员工的资料(一次用作索引的读取,两次用作数据块的读取),减少了 97 次的块读取。
重新排序带来的性能改善的程度在于在你开始的时候行的乱序性如何,以及你需要由序列中访问多少行。至于一个表中的行与索引的排序键的匹配程度,可以查看数据字典中的 dba_indexes 和 dba_tables 视图得到。
在 dba_indexes 的视图中,查看 clustering_factor 列。如果 clustering_factor 的值和表中的块数目大致一样,那么你的表和索引的顺序是一样的。不过,如果 clustering_factor 的值接近表中的行数目,那就表明表格中的行和索引的顺序是不一样的。
行重新排序的作用是不可以小看的。在需要进行大范围的索引搜索的大表中,行重新排序可以令查询的性能提高三倍。一旦你已经决定重新排序表中的行,你可以使用以下的工具之一来重新组织表格。
使用 Oracle 的 Create Table As Select (CTAS) 语法来拷贝表格
Oracle9i 自带的表格重新组织工具
3. SQL 调优
- 3.1 消除不必要的大表全表搜索:
不必要的全表搜索导致大量不必要的 I/O ,从而拖慢整个数据库的性能。调优专家首先会根据查询返回的行数目来评价 SQL 。在一个有序的表中,如果查询返回少于 40% 的行,或者在一个无序的表中,返回少于 7% 的行,那么这个查询都可以调整为使用一个索引来代替全表搜索。对于不必要的全表搜索来说,最常见的调优方法是增加索引。可以在表中加入标准的 B 树索引,也可以加入 bitmap 和基于函数的索引。要决定是否消除一个全表搜索,你可以仔细检查索引搜索的 I/O 开销和全表搜索的开销,它们的开销和数据块的读取和可能的并行执行有关,并将两者作对比。在一些情况下,一些不必要的全表搜索的消除可以通过强制使用一个 index 来达到,只需要在 SQL 语句中加入一个索引的提示就可以了。
在全表搜索是一个最快的访问方法时,将小表的全表搜索放到缓存中,调优专家应该确保有一个专门的数据缓冲用作行缓冲。在 Oracle7 中,你可以使用 alter table xxx cache 语句,在 Oracle8 或以上,小表可以被强制为放到 KEEP 池中缓冲。
- 3.2 确保最优的索引使用 :
对于改善查询的速度,这是特别重要的。有时 Oracle 可以选择多个索引来进行查询,调优专家必须检查每个索引并且确保 Oracle 使用正确的索引。它还包括 bitmap 和基于函数的索引的使用。
-
3.3 确保最优的 JOIN 操作
有些查询使用 NESTED LOOP join 快一些,有些则是 HASH join 快一些,另外一些则是 sort-merge join 更快。 -
3.4 基础SQL优化写法
1、查询时候不要写SELECT * 需要什么字段就放什么字段,select * 非常耗费性能
2、尽量少用distinct ,建议用group by
3、in 或 not in 推荐用 exists /not exist 代替
有时候如果in 中出现的为连续数值 可以用BETWEEN AND 代替
4、IS NULL 或IS NOT NULL操作,建议用替代方法
判断字段是否为空一般是不会应用索引的,因为索引是不索引空值的。
推荐方法:用其它相同功能的操作运算代替,如:a is not null 改为 a>0 或a>’’等。不允许字段为空,而用一个缺省值代替空值,如字段不允许为空。
5、> 及 < 操作符(大于或小于操作符)
大于或小于操作符一般情况下是不用调整的,因为它有索引就会采用索引查找,但有的情况下可以对它进行优化,如一个表有100万记录,一个数值型字段A,30万记录的A=0,30万记录的A=1,39万记录的A=2,1万记录的A=3。那么执行A>2与A>=3的效果就有很大的区别了,因为A>2时ORACLE会先找出为2的记录索引再进行比较,而A>=3时ORACLE则直接找到=3的记录索引。
6、LIKE操作符
LIKE操作符可以应用通配符查询,里面的通配符组合可能达到几乎是任意的查询,但是如果用得不好则会产生性能上的问题,如LIKE ‘%5400%’ 这种查询不会引用索引,而LIKE ‘X5400%’则会引用范围索引。
7、OR 操作符
建议使用union all 连接两段查询结果
8、where 字段
比如 substr(a,1,4)=‘abcd’ 可改为 a like ‘abcd%’ 使其走范围索引
a+2>3 可改为 a>1
9、写法问题
同一sql 建议写法一致,比如 select * from table;
不同人可能喜欢全部大写 SELECT * FROM TABLE
加个空格 SELECT * FROM TABLE;
大小写混合 select * from TABLE
以上为整理的一些常见的
4. 调整 Oracle 排序
排序是 SQL 语法中一个小的方面,但很重要,在 Oracle 的调整中,它常常被忽略。当用 create index 、 ORDER BY或者 GROUP BY 的语句时, Oracle 数据库将会自动执行排序的操作。通常,在以下的情况下 Oracle 会进行排序的操作:
使用 Order by 的 SQL 语句
使用 Group by 的 SQL 语句
在创建索引的时候
进行 table join 时,由于现有索引的不足而导致 SQL 优化器调用 MERGE SORT
当与 Oracle 建立起一个 session 时,在内存中就会为该 session 分配一个私有的排序区域。如果该连接是一个专用的连接 (dedicated connection) ,那么就会根据 init.ora 中 sort_area_size 参数的大小在内存中分配一个 Program Global Area (PGA) 。如果连接是通过多线程服务器建立的,那么排序的空间就在 large_pool 中分配。不幸的是,对于所有的 session ,用做排序的内存量都必须是一样的,我们不能为需要更大排序的操作分配额外的排序区域。因此,设计者必须作出一个平衡,在分配足够的排序区域以避免发生大的排序任务时出现磁盘排序( disk sorts )的同时,对于那些并不需要进行很大排序的任务,就会出现一些浪费。当然,当排序的空间需求超出了 sort_area_size 的大小时,这时将会在 TEMP 表空间中分页进行磁盘排序。磁盘排序要比内存排序大概慢 14,000 倍。
上面我们已经提到,私有排序区域的大小是有 init.ora 中的 sort_area_size 参数决定的。每个排序所占用的大小由 init.ora 中的 sort_area_retained_size 参数决定。当排序不能在分配的空间中完成时,就会使用磁盘排序的方式,即在 Oracle 实例中的临时表空间中进行。
磁盘排序的开销是很大的,有几个方面的原因。首先,和内存排序相比较,它们特别慢;而且磁盘排序会消耗临时表空间中的资源。 Oracle 还必须分配缓冲池块来保持临时表空间中的块。无论什么时候,内存排序都比磁盘排序好,磁盘排序将会令任务变慢,并且会影响 Oracle 实例的当前任务的执行。还有,过多的磁盘排序将会令 free buffer waits 的值变高,从而令其它任务的数据块由缓冲中移走。
5. 调整 Oracle 的竞争
Oracle 的其中一个优点时它可以管理每个表空间中的自由空间。 Oracle 负责处理表和索引的空间管理,这样就可以让我们无需懂得 Oracle 的表和索引的内部运作。不过,对于有经验的 Oracle 调优专家来说,他需要懂得 Oracle 是如何管理表的 extent 和空闲的数据块。对于调整拥有高的 insert 或者 update 的系统来说,这是非常重要的。
要精通对象的调整,你需要懂得 freelists 和 freelist 组的行为,它们和 pctfree 及 pctused 参数的值有关。这些知识对于企业资源计划( ERP )的应用是特别重要的,因为在这些应用中,不正确的表设置通常是 DML 语句执行慢的原因。
对于初学者来说,最常见的错误是认为默认的 Oracle 参数对于所有的对象都是最佳的。除非磁盘的消耗不是一个问题,否则在设置表的 pctfree 和 pctused 参数时,就必须考虑平均的行长和数据库的块大小,这样空的块才会被有效地放到 freelists 中。当这些设置不正确时,那些得到的 freelists 也是 “dead” 块,因为它们没有足够的空间来存储一行,这样将会导致明显的处理延迟。
Freelists 对于有效地重新使用 Oracle 表空间中的空间是很重要的,它和 pctfree 及 pctused 这两个存储参数的设置直接相关。通过将 pctused 设置为一个高的值,这时数据库就会尽快地重新使用块。不过,高性能和有效地重新使用表的块是对立的。在调整 Oracle 的表格和索引时,需要认真考虑究竟需要高性能还是有效的空间重用,并且据此来设置表的参数。以下我们来看一下这些 freelists 是如何影响 Oracle 的性能的。
当有一个请求需要插入一行到表格中时, Oracle 就会到 freelist 中寻找一个有足够的空间来容纳一行的块。你也许知道, freelist 串是放在表格或者索引的第一个块中,这个块也被称为段头( segment header )。 pctfree 和 pctused 参数的唯一目的就是为了控制块如何在 freelists 中进出。虽然 freelist link 和 unlink 是简单的 Oracle 功能,不过设置 freelist link (pctused) 和 unlink (pctfree) 对 Oracle 的性能确实有影响。
由 DBA 的基本知识知道, pctfree 参数是控制 freelist un-links 的(即将块由 freelists 中移除)。设置 pctfree=10 意味着每个块都保留 10% 的空间用作行扩展。 pctused 参数是控制 freelist re-links 的。设置 pctused=40 意味着只有在块的使用低于 40% 时才会回到表格的 freelists 中。
许多新手对于一个块重新回到 freelists 后的处理都有些误解。其实,一旦由于一个删除的操作而令块被重新加入到 freelist 中,它将会一直保留在 freelist 中即使空间的使用超过了 60% ,只有在到达 pctfree 时才会将数据块由 freelist 中移走。
表格和索引存储参数设置的要求总结
以下的一些规则是用来设置 freelists, freelist groups, pctfree 和 pctused 存储参数的。你也知道, pctused 和 pctfree 的值是可以很容易地通过 alter table 命令修改的,一个好的 DBA 应该知道如何设置这些参数的最佳值。
有效地使用空间和高性能之间是有矛盾的,而表格的存储参数就是控制这个方面的矛盾:
对于需要有效地重新使用空间,可以设置一个高的 pctused 值,不过副作用是需要额外的 I/O 。一个高的 pctused 值意味着相对满的块都会放到 freelist 中。因此,这些块在再次满之前只可以接受几行记录,从而导致更多的 I/O 。
追求高性能的话,可以将 pctused 设置为一个低的值,这意味着 Oracle 不会将数据块放到 freelists 中直到它几乎是空的。那么块将可以在满之前接收更多的行,因此可以减少插入操作的 I/O 。要记住 Oracle 扩展新块的性能要比重新使用现有的块高。对于 Oracle 来说,扩展一个表比管理 freelists 消耗更少的资源。
设置对象存储参数的一些常见规则:
经常将 pctused 设置为可以接收一条新行。对于不能接受一行的 free blocks 对于我们来说是没有用的。如果这样做,将会令 Oracle 的性能变慢,因为 Oracle 将在扩展表来得到一个空的块之前,企图读取 5 个 “dead” 的 free block 。
表格中 chained rows 的出现意味着 pctfree 太低或者是 db_block_size 太少。在很多情况下, RAW 和 LONG RAW 列都很巨大,以至超过了 Oracle 的最大块的大小,这时 chained rows 是不可以避免的。
如果一个表有同时插入的 SQL 语句,那么它需要有同时删除的语句。运行单一个一个清除的工作将会把全部的空闲块放到一个 freelist 中,而没有其它包含有任何空闲块的 freelists 出现。
freelist 参数应该设置为表格同时更新的最大值。例如,如果在任何时候,某个表最多有 20 个用户执行插入的操作,那么该表的参数应该设置为 freelists=20
应记住的是 freelist groups 参数的值只是对于 Oracle Parallel Server 和 Real Application Clusters 才是有用的。对于这类 Oracle , freelist groups 应该设置为访问该表格的 Oracle Parallel Server 实例的数目。
八、数据字典、动态视图
dictionary and dynamic view
Oracle 字典和动态视图
oracle服务显示全部的系统统计信息在v$sysstat 视图中,也用很多视图展现oracle性能和问题快照信息。
你能够通过查询这些视图发现被启动的实例总体信息。
oracle服务在DBA_xxx 视图中显示数据存储统计信息,可以用来查找存储故障(表,簇,索引)
utlbstat and utlestat 工具
你可能需要收集在制定业务时间内的性能特征, 可以用utlbstata.sql 和utlbstat.sql脚本 ,有经验的人通常用这两个工具去获取数据来调优项目
Oracle 等待事件
如果你正排出数据库系统的故障,那么需要知道有那些等待的进程
oracle 提供了一个等待事件列表,一些字典视图也提供了哪些session 在等待
oracle 诊断和调优包
在调优时可以使用oracle提供的图形界面工具来诊断和调优。例如图形监控、分析、自动调优。
字典和专用视图
在运行分析命令后,字典和专用视图回提供有用的统计信息。例如:
dba_tables dba_tab_columns dba_clusters dba_indexs ,dba_index_stats, index_histogram, dba_histogams.
下面是动态快照和性能试图
v v i e w v view v viewvfixed_table
x$tables
下面分类列出了可用到的一些统计视图
数据库实例信息
v$database
v$instance
v$option
v$parameter
v$backup
v$process
v$waritstat
v$system_event
磁盘信息
v$datafile
v$filestat
v$log
v$log_history
v$dbfile
V$tempfile
v$tempstat
用户和会话信息
v$lock
v$oper_cursor
v$process
v$sort_usage
v$session
v$sessstat
v$transaction
v$session_event
v$session_wait
v$px_sesstat
v$px_session
v$session_object_cache
内存信息
v$buffer_pool_statistics
v$db_object_cache
v$librarycache
v$rowcache
v$systat
v$sgastat
竞争信息
v$lock
v$rollname
v$rollstat
v$waitstat
v$latch