Spark性能调优指南来了!
1、什么是Spark
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
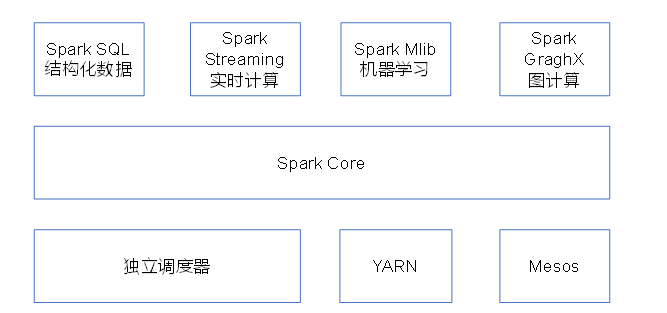
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的 API 定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL或者Apache Hive版本的 HQL 来查询数据。Spark SQL支持多种数据源,比如 Hive 表、Parquet以及JSON等。
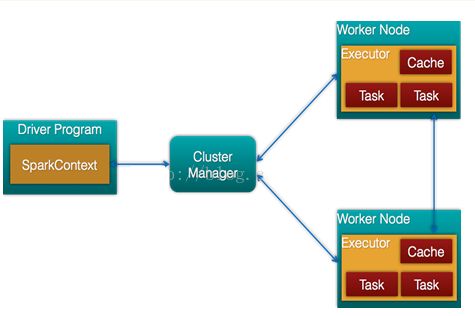
2、Spark Shuffle解析
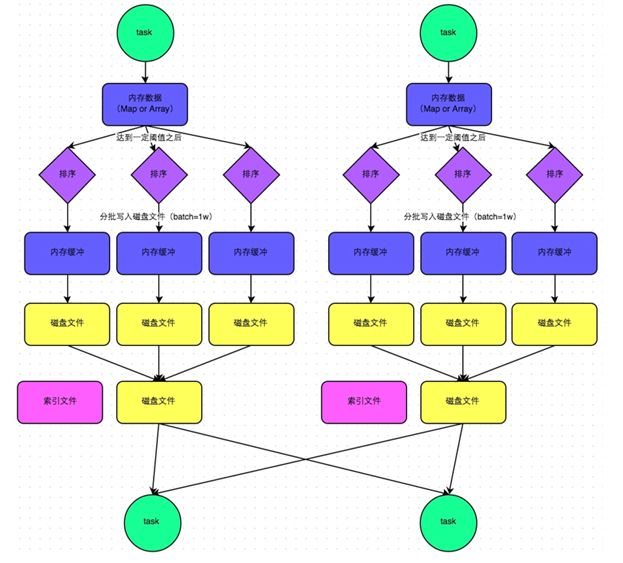
2.1 HashShuffle
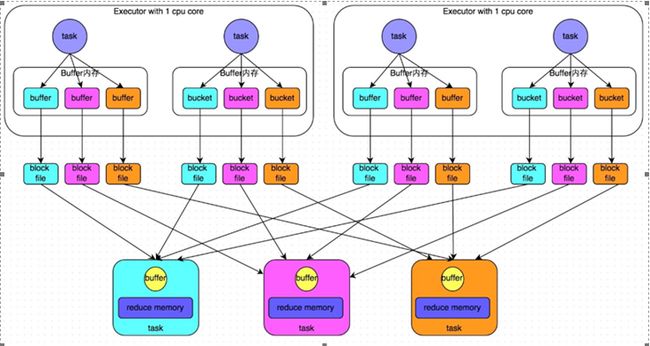
- 未经优化的
HashShuffleManager
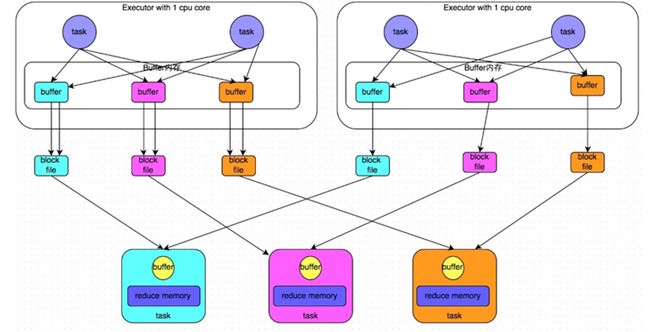
- 优化后的
HashShuffleManager
2.2 SortShuffle
3、执行计划处理流程
先看下从一个 sql 转化成 Rdd 的过程:
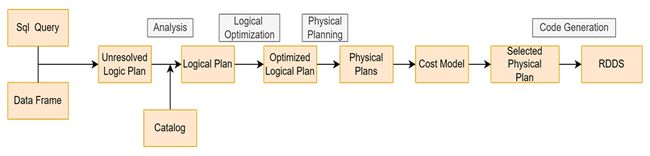
核心的执行过程一共有 5 个步骤:

这些操作和计划都是 Spark SQL 自动处理的,会生成以下计划:
➢ Unresolved 逻辑执行计划:Parsed Logical Plan
Parser 组件检查 SQL 语法上是否有问题,比如少写个逗号,少写个FROM,然后生成 Unresolved(未决断)的逻辑计划, 不检查表名、不检查列名。
➢ Resolved 逻辑执行计划:Analyzed Logical Plan
通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等,就是说验证表名列名到底在不在。
➢ 优化后的逻辑执行计划:Optimized Logical Plan
Catalyst 优化器根据各种规则进行优化,比如谓词下推。
➢ 物理执行计划:Physical Plan
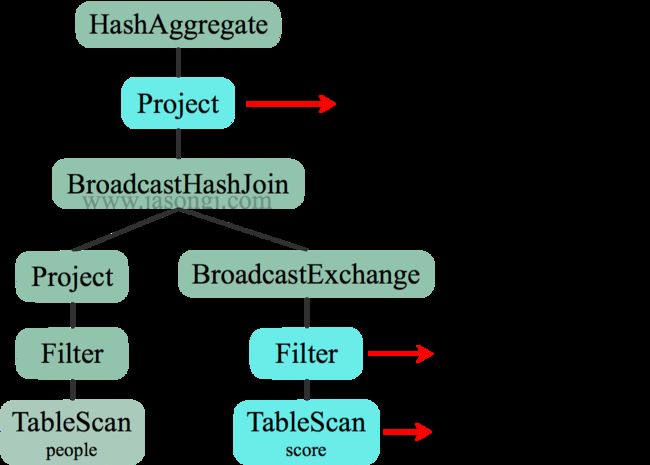
1)HashAggregate 运算符表示数据聚合,一般 HashAggregate 是成对出现,第一个 HashAggregate 是将执行节点本地的数据进行局部聚合,另一个 HashAggregate 是 将各个分区的数据进一步进行聚合计算。
2)Exchange 运算符其实就是 shuffle,表示需要在集群上移动数据。很多时候 HashAggregate 会以 Exchange 分隔开来。
3)Project 运算符是 SQL 中的投影操作,就是选择列(例如:select name, age…)。
4)BroadcastHashJoin 运算符表示通过基于广播方式进行 HashJoin。
5)LocalTableScan 运算符就是全表扫描本地的表
➢ CBO代价选择:选择最优的执行计划
4、SparkSQL 语法优化
4.1 大小表join
如果当一张小表足够小并且可以先缓存到内存中,那么可以使用 Broadcast Hash Join,其原理就是先将小表聚合到 driver 端,再广播到各个大表分区中,那么 再次进行 join 的时候,就相当于大表的各自分区的数据与小表进行本地 join,从而规避了 shuffle。
1)通过参数指定自动广播 广播 join 默认值为 10MB,
由 spark.sql.autoBroadcastJoinThreshold 参数控制。
2)强行广播join
语法: SELECT /*+ broadcast(a) */ FROM a JOIN b ON
4.2 大表和大表join
SMB JOIN 是 sort merge bucket 操作,需要进行分桶,首先会进行排序,然后根据 key 值合并,把相同 key 的数据放到同一个 bucket 中(按照 key 进行 hash)。分桶的目的其实 就是把大表化成小表。相同 key 的数据都在同一个桶中之后,再进行 join 操作,那么在联 合的时候就会大幅度的减小无关项的扫描。
使用条件:
(1)两表进行分桶,桶的个数必须相等
(2)两边进行 join 时,join 列=排序列=分桶列
5、基于 RBO 的优化
5.1 谓词下推(Predicate Pushdown)
将 过 滤 条 件 的 谓 词 逻 辑 都 尽 可 能 提 前 执 行 , 减 少 下 游 处 理 的 数 据 量 。下推的谓词能够大幅减少数据扫描量,降低磁盘 I/O 开销。
5.2 列剪裁(Column Pruning)
列剪裁就是扫描数据源的时候,只读取那些与查询相关的字段。
5.3 常量替换(Constant Folding)
我们在 select 语句中,掺杂了一些 常量表达式,Catalyst 也会自动地用表达式的结果进行替换。
6、基于 CBO 的优化
上文介绍的 RBO 属于逻辑计划的优化,只考虑查询,未考虑数据本身的特点。下面将介绍 CBO 如何利用数据本身的特点优化物理执行计划。
CBO 优化主要在物理计划层面,原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划。
6.1 官方实验
CBO优化前:

CBO优化后:

物理执行计划是一个树状结构,其代价等于每个执行节点的代价总合,如下图所示。

而每个执行节点的代价,分为两个部分
该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
- 每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
- 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;
- 中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
所以,最终主要需要解决两个问题
- 如何获取原始数据集的统计信息
- 如何根据输入数据集估算特定算子的输出数据集
6.2 CBO如何优化
1 Statistics 收集(相关信息提前收集好)
需要先执行特定的 SQL 语句来收集所需的表和列的统计信息。
➢ 生成表级别统计信息(扫表):
ANALYZE TABLE 表名 COMPUTE STATISTICS
生成 sizeInBytes (这张表的大小)和 rowCount(这张表多少行)。
从如下示例中,Statistics 一行可见, customer 表数据总大小为 37026233 字节,即 35.3MB,总记录数为 28万。
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS;
Time taken: 12.888 seconds
spark-sql> desc extended customer;
c_customer_sk bigint NULL
c_customer_id string NULL
c_current_cdemo_sk bigint NULL
c_current_hdemo_sk bigint NULL
c_current_addr_sk bigint NULL
c_first_shipto_date_sk bigint NULL
c_first_sales_date_sk bigint NULL
c_salutation string NULL
c_first_name string NULL
c_last_name string NULL
c_preferred_cust_flag string NULL
c_birth_day int NULL
c_birth_month int NULL
c_birth_year int NULL
c_birth_country string NULL
c_login string NULL
c_email_address string NULL
c_last_review_date string NULL
# Detailed Table Information
Database jason_tpc_ds
Table customer
Owner jason
Created Time Sat Sep 15 14:00:40 CST 2018
Last Access Thu Jan 01 08:00:00 CST 1970
Created By Spark 2.3.2
Type EXTERNAL
Provider hive
Table Properties [transient_lastDdlTime=1536997324]
Statistics 37026233 bytes, 280000 rows
Location hdfs://dw/tpc_ds/customer
Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat org.apache.hadoop.mapred.TextInputFormat
OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Storage Properties [field.delim=|, serialization.format=|]
Partition Provider Catalog
Time taken: 1.691 seconds, Fetched 36 row(s)
➢ 生成列级别统计信息
ANALYZE TABLE 表名 COMPUTE STATISTICS FOR COLUMNS 列 1,列 2,列 3
从如下示例可见,customer 表的 c_customer_sk 列最小值为 1, 最大值为 280000,null 值个数为 0,不同值个数为 274368,平均列长度为 8,最大列长度为 8。
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS FOR COLUMNS c_customer_sk, c_customer_id, c_current_cdemo_sk;
Time taken: 9.139 seconds
spark-sql> desc extended customer c_customer_sk;
col_name c_customer_sk
data_type bigint
comment NULL
min 1
max 280000
num_nulls 0
distinct_count 274368
avg_col_len 8
max_col_len 8
histogram NULL
2 算子对数据集影响估计
对于中间算子,可以根据输入数据集的统计信息以及算子的特性,可以估算出输出数据集的统计结果。
本节以 Filter 为例说明算子对数据集的影响。
对于常见的 Column A < value B Filter,可通过如下方式估算输出中间结果的统计信息
- 若
A.min > B,则无数据被选中,输出结果为空 - 若
A.max < B,则全部数据被选中,输出结果与A相同,且统计信息不变 - 若
A.min < B < A.max,则被选中的数据占比为(B.value - A.min) / (A.max - A.min),A.min不变,A.max更新为B.value
3 算子代价估计
SQL 中常见的操作有 Selection(由 select 语句表示),Filter(由 where 语句表示)以及笛卡尔乘积(由 join 语句表示)。其中代价最高的是 join。
Spark SQL 的 CBO 通过如下方法估算 join 的代价
Cost = rows * weight + size * (1 - weight)
Cost = CostCPU * weight + CostIO * (1 - weight)
其中 rows 即记录行数代表了 CPU 代价,size 代表了 IO 代价。weight 由 spark.sql.cbo.joinReorder.card.weight 决定,其默认值为 0.7。
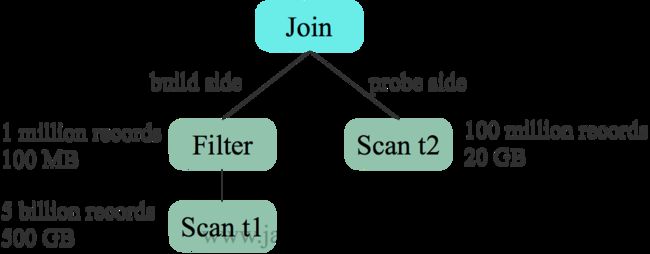
6.3 CBO优化Build侧选择
对于两表Hash Join,一般选择小表作为build size,构建哈希表,另一边作为 probe side。未开启 CBO 时,根据表原始数据大小选择 t2 作为build side
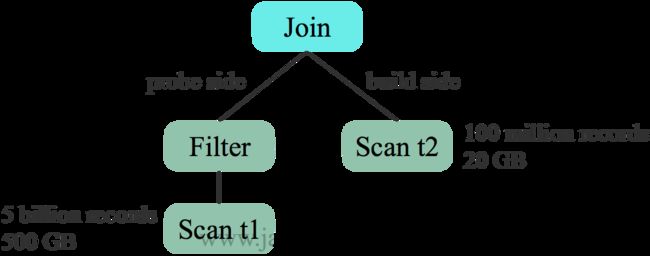
开启 CBO 后,基于估计的代价选择 t1 作为 build side。更适合本例
6.4 优化 Join 类型
在 Spark SQL 中,Join 可分为 Shuffle based Join 和 BroadcastJoin。Shuffle based Join 需要引入 Shuffle,代价相对较高。BroadcastJoin 无须 Join,但要求至少有一张表足够小,能通过 Spark 的 Broadcast 机制广播到每个 Executor 中。
在不开启 CBO 中,Spark SQL 通过 spark.sql.autoBroadcastJoinThreshold 判断是否启用 BroadcastJoin。其默认值为 10485760 即 10 MB。并且该判断基于参与 Join 的表的原始大小。
在下图示例中,Table 1 大小为 1 TB,Table 2 大小为 20 GB,因此在对二者进行 join 时,由于二者都远大于自动 BroatcastJoin 的阈值,因此 Spark SQL 在未开启 CBO 时选用 SortMergeJoin 对二者进行 Join。
而开启 CBO 后,由于 Table 1 经过 Filter 1 后结果集大小为 500 GB,Table 2 经过 Filter 2 后结果集大小为 10 MB 低于自动 BroatcastJoin 阈值,因此 Spark SQL 选用 BroadcastJoin。

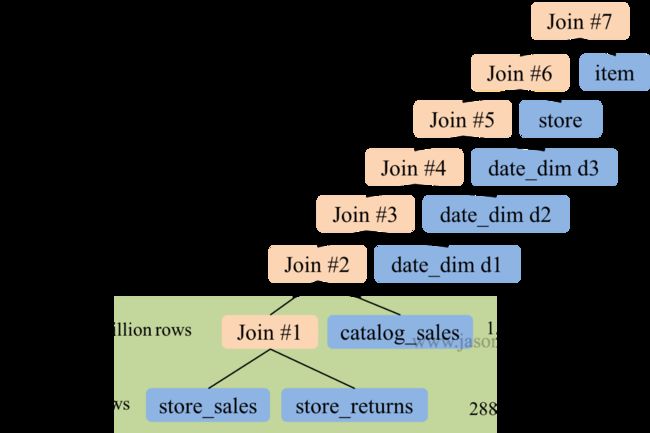
6.5 优化多表 Join 顺序
未开启 CBO 时,Spark SQL 按 SQL 中 join 顺序进行 Join。极端情况下,整个 Join 可能是 left-deep tree。在下图所示 TPC-DS Q25 中,多路 Join 存在如下问题。
left-deep tree,因此所有后续Join都依赖于前面的Join结果,各Join间无法并行进行。- 前面的两次
Join输入输出数据量均非常大,属于大Join,执行时间较长。
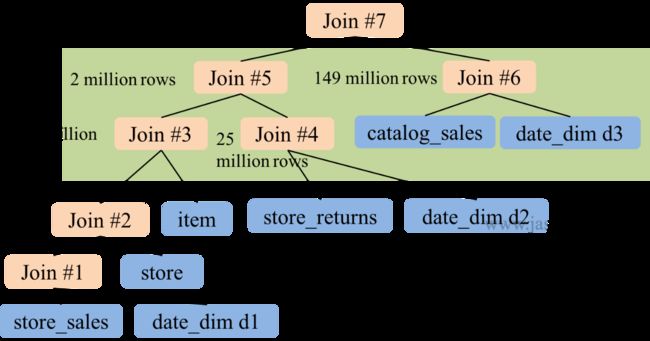
开启 CBO 后, Spark SQL 将执行计划优化如下:
6.6 使用 CBO
通过 “spark.sql.cbo.enabled” 来开启,默认是 false。配置开启 CBO 后,CBO 优化器可以 基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build 侧 选择、优化 Join 类型、优化多表 Join 顺序等。
下面是相关参数的说明:

总结
本文首先讲解了 Spark 的底层的 Shuffle 的调优以及从 SQL 到 RDD的生成执行计划的整个处理流程,其次是 Spark SQL 语法优化,最后梳理了 Spark SQL 是如何基于 RBO 和 CBO 的进行优化的!