2020-06-05-pytorch调参
1. 学习率
非常重要,设得太大,模型会发散,直接崩了;过小,则一直震荡,无法跳出局部最优解。
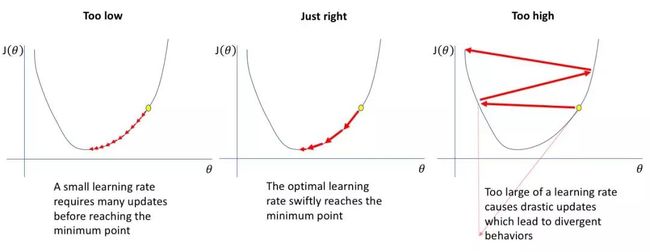
看这里来通过一定的手段学习最佳学习率。
def find_lr(init_value = 1e-8, final_value=10., beta = 0.98):
num = len(trn_loader)-1
mult = (final_value / init_value) ** (1/num)
lr = init_value
optimizer.param_groups[0]['lr'] = lr
avg_loss = 0.
best_loss = 0.
batch_num = 0
losses = []
log_lrs = []
for data in trn_loader:
batch_num += 1
#As before, get the loss for this mini-batch of inputs/outputs
inputs,labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
#Compute the smoothed loss
avg_loss = beta * avg_loss + (1-beta) *loss.data[0]
smoothed_loss = avg_loss / (1 - beta**batch_num)
#Stop if the loss is exploding
if batch_num > 1 and smoothed_loss > 4 * best_loss:
return log_lrs, losses
#Record the best loss
if smoothed_loss < best_loss or batch_num==1:
best_loss = smoothed_loss
#Store the values
losses.append(smoothed_loss)
log_lrs.append(math.log10(lr))
#Do the SGD step
loss.backward()
optimizer.step()
#Update the lr for the next step
lr *= mult
optimizer.param_groups[0]['lr'] = lr
return log_lrs, losses
net = SimpleNeuralNet(28*28,100,10)
optimizer = optim.SGD(net.parameters(),lr=1e-1)
criterion = F.nll_loss
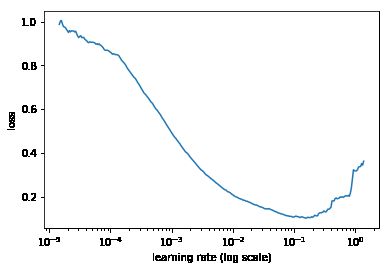
logs,losses = find_lr()
plt.plot(logs[10:-5],losses[10:-5])
# 绘制下面类似的图片来发现最佳学习率
⚠️
注意batch_size与lr的影响,一般来说,越大的batch-size使用越大的学习率。原理很简单,越大的
batch-size意味着我们学习的时候,收敛方向的confidence越大,我们前进的方向更加坚定,而小的batch-size则显得比较杂乱,毫无规律性,因为相比批次大的时候,批次小的情况下无法照顾到更多的情况,所以需要小的学习率来保证不至于出错。人工经验这么判断可能不太准确,所以上面的自动话方法可能好一点。
2. 权重初始化
常用的权重初始化算法是「kaiming_normal」或者「xavier_normal」。
- Xavier初始法,适用于普通激活函数(tanh, sigmoid)
- He初始化,适用于ReLU
- svd初始化:对RNN有比较好的效果
3. 迁移学习和差分学习率
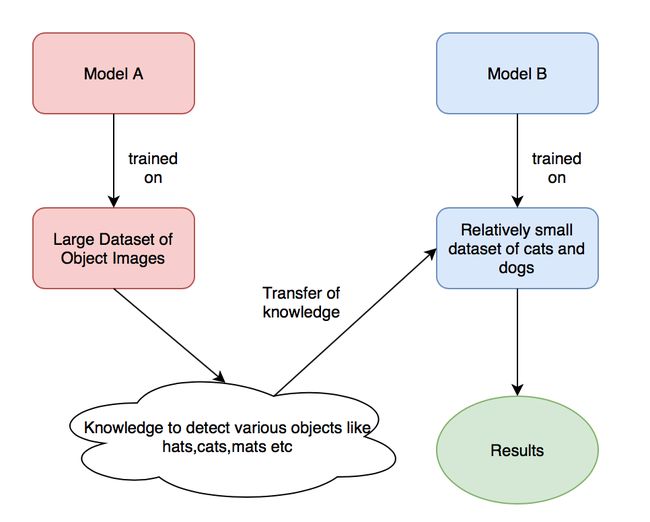
迁移学习在CV领域非常普遍,它是将在一个过程/活动中所学到的知识,应用到不同的任务中的过程,实现形式就是用pre-trained的模型参数去初始化我们自己的模型。
训练技巧就是首先冻结除分类层以外的所有层,然后训练模型到一个比较好的点,然后放开参数训练所有的层。
差分学习率则意味着在网络的不同部分使用不同的学习率。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-97f2SlQt-1632883613273)(https://miro.medium.com/max/1302/1*4zrt6IeIhv55mUskGhXR7Q.png)]
其背后思想是底层的红色的层学习边缘、形状等通用特征,这些特征的泛化能力很好,我们不希望有大的变动,而中间的蓝色层则学习与训练它的数据集有关的具体细节,为了能更贴合我们的数据,所以希望其学习率更大一些,绿色部分同理。
4. 余弦退火(cosine annealing)和热重启的随机梯度下降
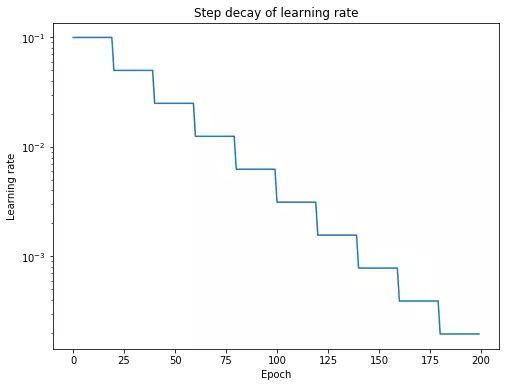
退火即先从一个比较高的学习速率开始然后慢慢地在训练中降低学习速率。这个方法背后的思想是我们喜欢快速地从初始参数移动到一个参数值「好」的范围,但这之后我们又想要一个学习速率小到我们可以发掘「损失函数上更深且窄的地方」。
学习速率退火的最流行方式是「步衰减」(Step Decay),其中学习率经过一定数量的训练 epochs 后下降了一定的百分比。
# pytorch 实现的余弦退火
optimizer_CosineLR = torch.optim.SGD(net.parameters(), lr=0.1)
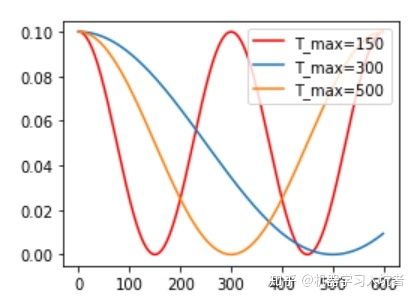
CosineLR = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_CosineLR, T_max=150, eta_min=0)
其包含的参数和余弦知识一致,参数T_max表示余弦函数周期;eta_min表示学习率的最小值,默认它是0表示学习率至少为正值。确定一个余弦函数需要知道最值和周期,其中周期就是T_max,最值是初试学习率。下图展示了不同周期下的余弦学习率更新曲线:
带有热重启的**随机梯度下降(SGDR)**与周期性方法很相似,其中一个积极的退火表与周期性「再启动」融合到原始的初始学习率之中。

查看这里了解一些新的策略。
通常可以利用Cyclical LR,SGDR或者AdamW。到目前为止,Adam 等自适应优化方法仍然是训练深度神经网络的最快方法。然而,各种基准测试的许多最优解决方案或在 Kaggle 中获胜的解决方案仍然选用 SGD,因为他们认为,Adam 获得的局部最小值会导致不良的泛化。
SGDR 将两者结合在一起,迅速「热」重启到较大的学习率,然后利用积极的退火策略帮助模型与 Adam 一样快速(甚至更快)学习,同时保留普通 SGD 的泛化能力。可以先用Adam系列算法训练到一定程度,再用SGD微调。
#pytorch官方还没有实现热重启的余弦退火算法,下面是一个实现,该实现也可以作为SGDR的实现。
class CosineAnnealingWithRestartsLR(_LRScheduler):
r"""Set the learning rate of each parameter group using a cosine annealing
schedule, where :math:`\eta_{max}` is set to the initial lr and
:math:`T_{cur}` is the number of epochs since the last restart in SGDR:
.. math::
\eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})(1 +
\cos(\frac{T_{cur}}{T_{max}}\pi))
When last_epoch=-1, sets initial lr as lr.
It has been proposed in
`SGDR: Stochastic Gradient Descent with Warm Restarts`_. This implements
the cosine annealing part of SGDR, the restarts and number of iterations multiplier.
Args:
optimizer (Optimizer): Wrapped optimizer.
T_max (int): Maximum number of iterations.
T_mult (float): Multiply T_max by this number after each restart. Default: 1.
eta_min (float): Minimum learning rate. Default: 0.
last_epoch (int): The index of last epoch. Default: -1.
.. _SGDR\: Stochastic Gradient Descent with Warm Restarts:
https://arxiv.org/abs/1608.03983
"""
def __init__(self, optimizer, T_max, eta_min=0, last_epoch=-1, T_mult=1):
self.T_max = T_max
self.T_mult = T_mult
self.restart_every = T_max
self.eta_min = eta_min
self.restarts = 0
self.restarted_at = 0
super().__init__(optimizer, last_epoch)
def restart(self):
self.restart_every *= self.T_mult
self.restarted_at = self.last_epoch
def cosine(self, base_lr):
return self.eta_min + (base_lr - self.eta_min) * (1 + math.cos(math.pi * self.step_n / self.restart_every)) / 2
@property
def step_n(self):
return self.last_epoch - self.restarted_at
def get_lr(self):
if self.step_n >= self.restart_every:
self.restart()
return [self.cosine(base_lr) for base_lr in self.base_lrs]
5. 尝试拟合一个小数据集
在我们实现自己的模型的时候,有很多时候写完了,训练完了发现结果不尽如人意,这时候的原因可能是多方面的,比如超参数,比如模型的结构等等,无论哪一种,都是对于我们时间的浪费,这个时候,合理的做法是构造一个很小的数据集,测试在这个小数据集上模型的效果,小数据集很快就跑完了,所以对于我们调试超参数,调试模型结构都大有裨益。
这里有个小细节,因为通常我们使用的都是已有数据集,再去构造一个小的数据集有点麻烦,这时候可以从已有数据集中取一些样本来拟合。
first_batch = next(iter(train_loader))
for batch_idx, (data, target) in enumerate([first_batch] * 50):
# training code here
6. 多尺度训练
一系列算法,CV领域普遍,使用多个resolution的图片训练模型。
7.混合精度训练
大多数模型使用32bit精度数字进行训练。然而,最近的研究发现,16bit模型也可以工作得很好。混合精度意味着对某些内容使用16bit,但将权重等内容保持在32bit。16bit精度可以大大降低内存占用。
# pytorch中使用混合精度非常简单
from apex import amp
#O0:纯FP32训练,可以作为accuracy的baseline;
#O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。
#O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算。
#O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
loss = model(input_ids, labels=lm_labels)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
8. 训练小策略
- 梯度归一化
loss /= batch_size
- 梯度裁剪
torch.nn.utils.clip_grap_norm_(params, clip_value)
- Dropout
一般为0.5,还有个位置的问题,不过目前来说,基本都是复用模型,不用太关心
后续持续更新…