34. 实战:基于某api实现歌曲检索与下载(附完整源代码)
目录
前言 (相关链接在评论区)
目的 (相关链接在评论区)
思路 (相关链接在评论区)
代码实现
1. 访问某音乐平台(链接放在评论区了),抓包搜索接口
2. 抓取音乐id信息
3. 解析音乐id,获取下载直链
4. 保存到本地
5. 实现用户交互逻辑
完整代码
运行效果
总结
前言
本节将介绍基于Python和某api实现的歌曲检索与批量下载功能的实现。
(相关链接在评论区)
目的
实现搜索任意关键词,选择任意序号歌曲下载或下载当页全部歌曲。
思路
1. 访问某音乐平台(链接放在评论区了),抓包搜索接口
2. 抓取音乐id信息
3. 解析音乐id,获取下载直链
4. 保存到本地
5. 实现用户交互逻辑
代码实现
1. 访问某音乐平台(链接放在评论区了),抓包搜索接口
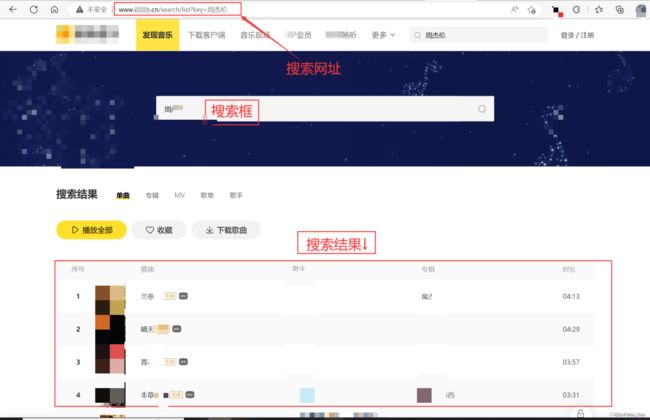
查看源代码,发现没有数据,所以抓包。
F12 --> Network --> Fetch/XHR --> 刷新网页

拿到请求搜索列表的URL,以及两个关键参数:
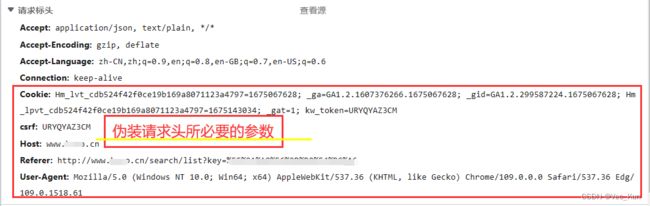

headers = {
'Cookie': '_ga=GA1.2.1574857442.1641026894; _gid=GA1.2.607461508.1641026894; kw_token=WRFKXNRRLBB',
'csrf': 'WRFKXNRRLBB',
'Host': '见评论区',
'Referer': '见评论区',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}# 输入关键参数
key = input('请输入搜索关键词:')
pn = input('请输入查看页序号:')
# 搜索接口,key为关键词,pn为页码
url = '见评论区'.format(key, pn)
resp = requests.get(url, headers=headers)
# pprint(resp.json())因为返回结果是json形式的数据,用json库解析,拿出必要的信息,给歌曲编号(没有编号键)
# 输出搜索结果
cnt = 1
data_list = resp.json()['data']['list']
for i in data_list:
name = i['name'].replace(' ', ' ')
i['name'] = name
artist = i['artist'].replace(' ', ' ')
i['artist'] = artist
i['seq'] = cnt
cnt += 1
print('序号:', i['seq'], '歌曲:', i['name'], '歌手:', i['artist'], '\n')2. 抓取音乐id信息
# 拿到歌曲id便于解析
rid = request_dic['rid']rid是我们必要的信息。
我们在某直链网站可以用rid来提取它所对应的直链下载地址(相关链接在评论区)
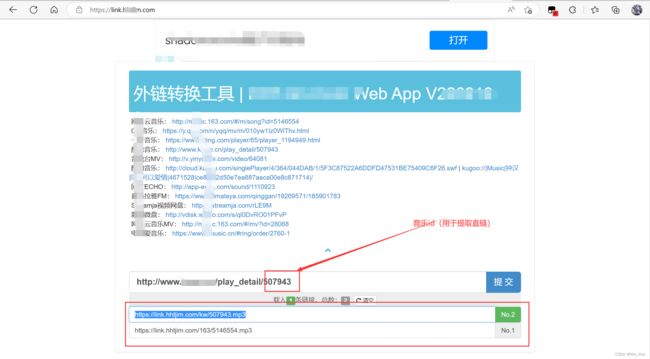
3. 解析音乐id,获取下载直链
for data in download_list:
# 把字符串转换为十进制整数用于选择列表数据
if flag:
data = int(data, 10)
# 逐个拿选中歌曲的字典
request_dic = data_list[data-1]
# 拿到歌曲id便于解析
rid = request_dic['rid']
# print(rid)
# 稍微处理一下曲名
name = request_dic['name'].split('-')[0]
# print(name)
new_url = '见评论区'.format(rid)
response = requests.get(new_url)如果没有全部下载的话,我们就需要把输入的字符串转为数字便于选择歌曲序号,拿到rid并且处理一下曲名,因为有些曲名会在“-”后面加上一些来源,比如xxx片头曲之类,我们是不需要的,所以直接split分割取第一个。
new_url就是直接把rid塞进去,就是对应的直链地址了。
4. 保存到本地
if not os.path.exists('./3_Music_Crawler'):
os.mkdir('./3_Music_Crawler')
with open('3_Music_Crawler/%s.mp3' % name, 'wb') as f:
f.write(response.content)
print(name, '下载成功')
如果没有某路径,便创建它,这是基于os库实现的,导包即可。
将直链中的数据二进制写入本地文件,用歌曲名命名,后缀为MP3格式。
5. 实现用户交互逻辑
首先就是要先输入关键参数:输入关键词与查询页码,每页中的数据量不必改变,默认是20条。
# 输入关键参数
key = input('请输入搜索关键词:')
pn = input('请输入查看页序号:')向用户输出搜索结果,并打印歌曲序号和详细信息,供用户选择是否进行下载。
# 输出搜索结果
cnt = 1
data_list = resp.json()['data']['list']
for i in data_list:
name = i['name'].replace(' ', ' ')
i['name'] = name
artist = i['artist'].replace(' ', ' ')
i['artist'] = artist
i['seq'] = cnt
cnt += 1
print('序号:', i['seq'], '歌曲:', i['name'], '歌手:', i['artist'], '\n')用户输入0时,下载当前页所有歌曲,也可以输入以空格分隔的序号来下载对应序号的歌曲。
# 选择歌曲下载
download_list = input('请输入你想下载歌曲的序号(用空格分隔序号,输入0下载本页全部):').split(' ')
flag = True
if download_list == ['0']:
flag = False
download_list = []
for it in range(1, len(resp.json()['data']['list']) + 1):
download_list.append(it)
print('开始下载...')这样我们就完整顺下来整个过程了,最后我们梳理一下逻辑,奉上完整代码:
(相关链接在评论区)
完整代码
import requests
from pprint import pprint
import os
# 伪装请求头
headers = {
'Cookie': '_ga=GA1.2.1574857442.1641026894; _gid=GA1.2.607461508.1641026894; kw_token=WRFKXNRRLBB',
'csrf': 'WRFKXNRRLBB',
'Host': '见评论区',
'Referer': '见评论区',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
# 输入关键参数
key = input('请输入搜索关键词:')
pn = input('请输入查看页序号:')
# 搜索接口,key为关键词,pn为页码
url = '见评论区'.format(key, pn)
resp = requests.get(url, headers=headers)
# pprint(resp.json())
# 输出搜索结果
cnt = 1
data_list = resp.json()['data']['list']
for i in data_list:
name = i['name'].replace(' ', ' ')
i['name'] = name
artist = i['artist'].replace(' ', ' ')
i['artist'] = artist
i['seq'] = cnt
cnt += 1
print('序号:', i['seq'], '歌曲:', i['name'], '歌手:', i['artist'], '\n')
# 选择歌曲下载
download_list = input('请输入你想下载歌曲的序号(用空格分隔序号,输入0下载本页全部):').split(' ')
flag = True
if download_list == ['0']:
flag = False
download_list = []
for it in range(1, len(resp.json()['data']['list']) + 1):
download_list.append(it)
print('开始下载...')
# 下载歌曲
for data in download_list:
# 把字符串转换为十进制整数用于选择列表数据
if flag:
data = int(data, 10)
# 逐个拿选中歌曲的字典
request_dic = data_list[data-1]
# 拿到歌曲id便于解析
rid = request_dic['rid']
# print(rid)
# 稍微处理一下曲名
name = request_dic['name'].split('-')[0]
# print(name)
new_url = '见评论区'.format(rid)
response = requests.get(new_url)
if not os.path.exists('./3_Music_Crawler'):
os.mkdir('./3_Music_Crawler')
with open('3_Music_Crawler/%s.mp3' % name, 'wb') as f:
f.write(response.content)
print(name, '下载成功')
运行效果
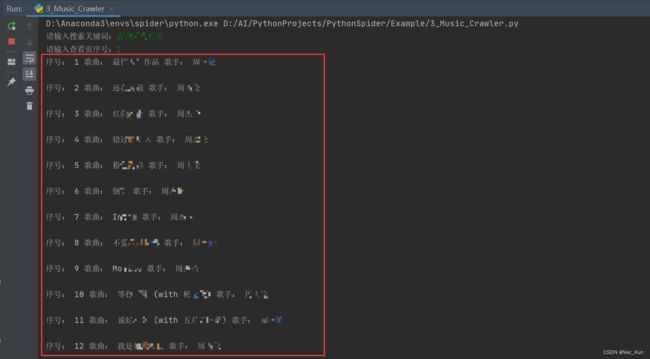
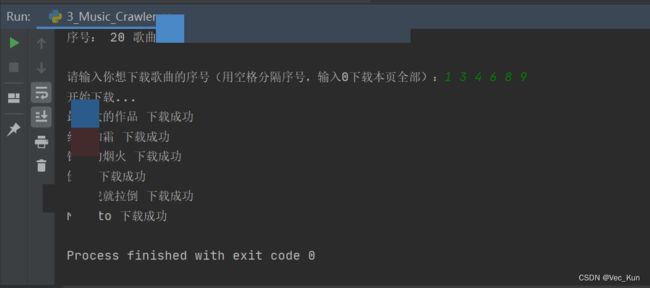
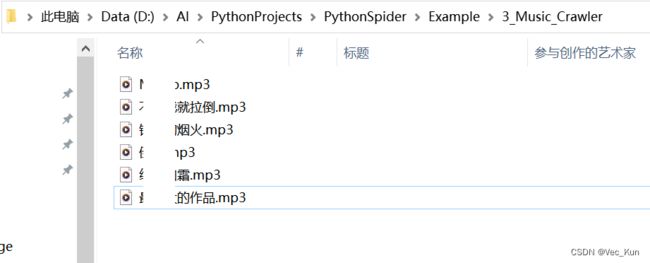
总结
本节基于某api获取直链,在某音乐平台获取搜索列表,从而拿到音乐唯一的rid,替换直链从而访问到歌曲的直接下载链接。整个过程比较经典,适合小白练手。