《cuda c编程权威指南》02 - 内存管理和线程管理
一个典型的CUDA编程结构包括5个主要步骤。
- 分配GPU内存。
- 从CPU内存中拷贝数据到GPU内存。
- 调用CUDA内核函数来完成程序指定的运算。
- 将数据从GPU拷回CPU内存。
- 释放GPU内存空间。
这里先理一理如何分配gpu内存。
目录
1. 内存管理函数
1.1 分别内存
1.2 数据拷贝
2. gpu内存结构
3. 小栗子
3.1 纯c编写(只在cpu上相加)
3.2 cuda编写(在gpu上相加)
3.2.1 线程层次结构
3.2.2 定义
3.2.3 同步问题
3.2.4 核函数
3.2.5 调试错误
3.2.6 完整cuda程序
1. 内存管理函数
4种内存管理函数,用途和标准的c语言可以一一对应。区别就是一个在cpu上管理分配和释放,一个是在gpu上操作。

1.1 分别内存
cudaError_t cudaMalloc (void** devPtr, size_t size)设备端(gpu)分配size字节的线性内存。
1.2 数据拷贝
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)这里的数据拷贝,用来在主机端和设备端之间传输count字节数据。传输方向由kind指定,kind有以下4种。
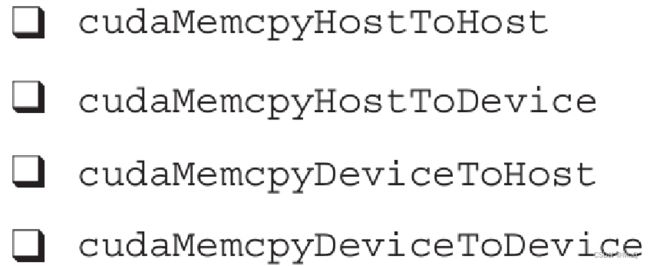
这个函数以同步方式执行,因为在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。
其中,可以将上面返回的cudaError_t解释成可读的错误信息。
char* cudaGetErrorString(cudaError_t e)该功能和c语言的strerror类似。
2. gpu内存结构
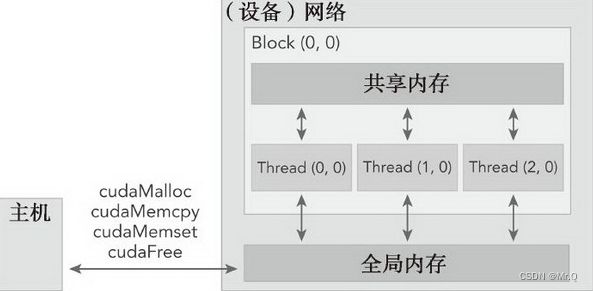
gpu中最主要的两种内存是全局内存和共享内存。全局内存类似于cpu中的系统内存,而共享内存类似于cpu缓存。
3. 小栗子
功能:数组a中数字和数组b相加,存放到数组c
3.1 纯c编写(只在cpu上相加)
#include
#include // srand
// cpu
void sumArraysOnHost(float* a, float* b, float* c, const int N)
{
for (int i = 0; i < N; i++)
{
c[i] = a[i] + b[i];
}
}
void initialData(float* p, const int N)
{
//generate different seed from random number
time_t t;
srand((unsigned int)time(&t)); // 生成种子
for (int i = 0; i < N; i++)
{
p[i] = (float)(rand() & 0xFF) / 10.0f; // 随机数
}
}
int main(void)
{
// 1 分配内存
int nElem = 1024;
size_t nBytes = nElem * sizeof(nElem);
float* h_a, * h_b, * h_c;
h_a = (float*)malloc(nBytes);
h_b = (float*)malloc(nBytes);
h_c = (float*)malloc(nBytes);
// 初始化
initialData(h_a, nElem);
initialData(h_b, nElem);
// 2 直接在cpu上相加
sumArraysOnHost(h_a, h_b, h_c, nElem);
// 3 释放内存
free(h_a);
free(h_b);
free(h_c);
return 0;
} 3.2 cuda编写(在gpu上相加)
将相加操作放到gpu上操作。下面将给出完整典型的cuda编程结构。
3.2.1 线程层次结构
线程层次结构。一个grid包含很多块Block,一个Block包含很多Thread.
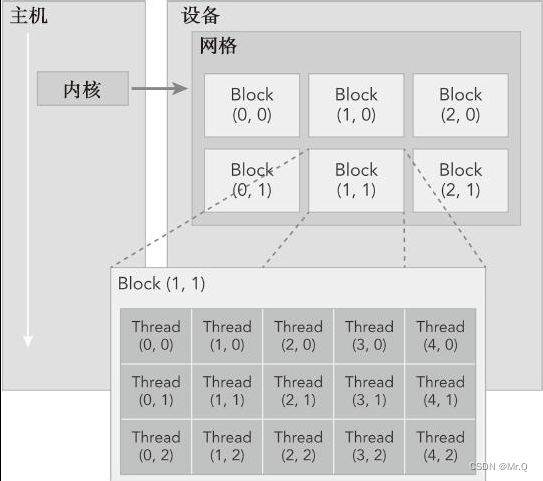
由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间(相当于系统内存)。blockIdx(线程块在线程格内的索引),threadIdx(块内的线程索引)。
当执行一个核函数时,CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx(自动生成的变量)。
3.2.2 定义
定义块的尺寸,并基于块和数据的大小计算网格尺寸。比如有6个数据
int nElem = 6;
// 定义一维数组线程块
dim3 block(3); // 块内有3个线程组
// 定义一维数组网格. 有3个块。即网格大小3是块大小3的倍数。
dim3 grid((nElem + block.x - 1) / block.x); // 为了保证倍数关系。(6+3-1)/3 = 3
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
__global__ void checkIndex(void) {
printf("blockIdx: (%d, %d, %d) threadIdx: (%d, %d, %d) \n"
"gridDim: (%d, %d, %d) blockDim: (%d, %d, %d) \n",
blockIdx.x, blockIdx.y, blockIdx.z,
threadIdx.x, threadIdx.y, threadIdx.z,
gridDim.x, gridDim.y, gridDim.z,
blockDim.x, blockDim.y, blockDim.z
);
}
int main(void)
{
int nElem = 6;
// 定义一维数组线程块
dim3 block(3); // 块内有3个线程组
// 定义一维数组网格. 有3个块。即网格大小3是块大小3的倍数。
dim3 grid((nElem + block.x - 1) / block.x); // (6+3-1)/3 = 3
// check grid and block dimension from the host side.
printf("host gridIdx: (%d, %d, %d) \n", grid.x, grid.y, grid.z);
printf("host blockIdx: (%d, %d, %d) \n", block.x, block.y, block.z);
// check grid and block dimension from the device side.
checkIndex << > > (); // <<>>
// reset device before you leavec
cudaDeviceReset();
return 0;
} 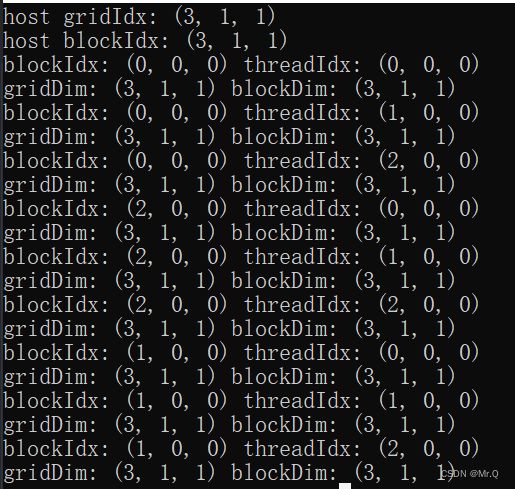
可以看到当执行一个核函数checkIndex时,CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx,
其中,
(1)blockDim和gridDim都是(3,1,1).
(2)blockIdx从(0,0,0) -> (2,0,0) -> (1,0,0).block顺序是随机的;
(3)不同block内的threadIdx则一直是从(0,0,0) ->(1,0,0) -> (2,0,0).
3.2.3 同步问题
(1)所有的核函数调用和主机线程是异步的。调用核函数后会继续往下执行,不用等核函数执行完。
(2)有时需要同步,则显示的强制主机等待所有的核函数执行结束,设置:
cudaError_t cudaDeviceSynchronize(void);(3)而一些cuda API在主机和设备之间是隐式同步的。 比如cudaMemcpy,主机端需要等待拷贝完才能继续执行。
3.2.4 核函数
核函数是在设备端执行的代码。 当核函数被调用时,许多不同的CUDA线程并行执行同一个计算任务。
__global__ void kernel_name(argument list);注意:
(1)核函数必须是void返回类型;
(2)函数类型限定符(修饰符)决定在哪里执行,也决定被谁调用;

__device__和__host__限定符可以一齐使用,这样函数可以同时在主机和设备端进行编译。
(3)CUDA核函数的限制
以下限制适用于所有核函数:
·只能访问设备内存
·必须具有void返回类型
·不支持可变数量的参数
·不支持静态变量
·显示异步行为
// 主机端:纯c语言
void sumArraysOnHost(float* a, float* b, float* c, const int N)
{
for (int i = 0; i < N; i++)
c[i] = a[i] + b[i];
}
// 设备端:去掉了循环。内置的线程坐标变量替换了数组索引
__global__ void sumArraysOnDevice(float* a, float* b, float* c)
{
int i = threadIdx.x; // sumArraysOnDevice << <1, 32 >> > (a, b, c);
//int i = blockIdx.x; // sumArraysOnDevice << <32, 1>> > (a, b, c);
c[i] = a[i] + b[i];
}
// 调用方式:只有一个块,块内有32个线程。并发执行
sumArraysOnDevice << <1, 32 >> > (a, b, c);
// 强制用一个块和一个线程执行核函数,这模拟了串行执行程序。有助于调试和验证结果
sumArraysOnDevice << <1, 1 >> > (a, b, c);网格内有只有一个块,块内有32个线程,则可以使用threadIdx.x作为索引;
如果网格内有32个块,每个块内有1个线程,则可以使用blockIdx.x作为索引。
3.2.5 调试错误
#define CHECK(call)
{
const cudaError_t error = call;
if (error != cudaSuccess)
{
printf("Error: %s: %d, ", __FILE__, __LINE__);
printf("code: %d, reason: %s\n", error, cudaGetErrorString(error));
exit(1);
}
}
CHECK(cudaMemCpy(d_c, gpuRef, nBytes, cudaMemcpyHostToDevice));3.2.6 完整cuda程序
#include "cuda_runtime.h"
#include "device_launch_parameters.h" // threadIdx
#include // io
#include // time_t
#include // rand
#include //memset
#define CHECK(call) \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
}
void checkResult(float* hostRef, float* deviceRef, const int N)
{
double eps = 1.0E-8;
for (int i = 0; i < N; i++)
{
if (hostRef[i] - deviceRef[i] > eps)
{
printf("Arrays do not match\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], deviceRef[i], i);
break;
}
}
printf("Arrays match!\n");
}
void initialData(float* p, const int N)
{
//generate different seed from random number
time_t t;
srand((unsigned int)time(&t)); // 生成种子
for (int i = 0; i < N; i++)
{
p[i] = (float)(rand() & 0xFF) / 10.0f; // 随机数
}
}
__global__ void checkIndex(void) {
printf("blockIdx: (%d, %d, %d) threadIdx: (%d, %d, %d) \n"
"gridDim: (%d, %d, %d) blockDim: (%d, %d, %d) \n",
blockIdx.x, blockIdx.y, blockIdx.z,
threadIdx.x, threadIdx.y, threadIdx.z,
gridDim.x, gridDim.y, gridDim.z,
blockDim.x, blockDim.y, blockDim.z
);
}
// cpu
void sumArraysOnHost(float* a, float* b, float* c, const int N)
{
for (int i = 0; i < N; i++)
{
c[i] = a[i] + b[i];
}
}
// 设备端:去掉了循环
__global__ void sumArraysOnDevice(float* a, float* b, float* c, const int N)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main(void)
{
int device = 0;
cudaSetDevice(device); // 设置显卡号
// 1 分配内存
// host memory
int nElem = 32;
size_t nBytes = nElem * sizeof(nElem);
float* h_a, * h_b, * hostRef, *gpuRef;
h_a = (float*)malloc(nBytes);
h_b = (float*)malloc(nBytes);
hostRef = (float*)malloc(nBytes); // 主机端求得的结果
gpuRef = (float*)malloc(nBytes); // 设备端拷回的数据
// 初始化
initialData(h_a, nElem);
initialData(h_b, nElem);
memset(hostRef, 0, nBytes);
memset(hostRef, 0, nBytes);
// device memory
float* d_a, * d_b, * d_c;
cudaMalloc((float**)&d_a, nBytes);
cudaMalloc((float**)&d_b, nBytes);
cudaMalloc((float**)&d_c, nBytes);
// 2 transfer data from host to device
cudaMemcpy(d_a, h_a, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, nBytes, cudaMemcpyHostToDevice);
// 3 在主机端调用设备端核函数
dim3 block(nElem);
dim3 grid(nElem / block.x);
sumArraysOnDevice<<>>(d_a, d_b, d_c, nElem);
// 4 transfer data from device to host
cudaMemcpy(gpuRef, d_c, nBytes, cudaMemcpyDeviceToHost);
//确认下结果
sumArraysOnHost(h_a, h_b, hostRef, nElem);
checkResult(hostRef, gpuRef, nElem);
// 5 释放内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
free(h_a);
free(h_b);
free(hostRef);
free(gpuRef);
return 0;
}