AIGC时代,基于云原生 MLOps 构建属于你的大模型(下)
为了满足企业在数字化转型过程中对更新迭代生产力工具的需求,灵雀云近日推出了Alauda MLOps 解决方案,帮助企业快速落地AI技术、实现智能化应用和服务。
AIGC大模型已成为企业创新引擎
随着ChatGPT的爆火,越来越多的人考虑使用AI来提升我们日常工作的效率和质量,通过对话协助生成需要的文本数据。无论是将数据汇总成表格,还是根据提示编写文章,或者进行专业知识问答,都可以通过合适的prompt工程,让ChatGPT给出最佳的回答,甚至可以取代一部分人类的工作。
此外,AI 生成的内容不仅限于文本数据,还包括 AI 绘画(stable diffusion),乐曲创作(Amper Music),电影生成(Runway)等工具,这些都是 AIGC( AI Generated Content) 的范畴,它们也在不断刷新许多行业的生产力。
Alauda MLOps助力企业快速构建属于自己的大模型
然而,企业需要一个自己拥有并管控的本地部署的模型来完成上述工作,因为这样可以保证:
· 安全因素:在进行对话时,企业不希望把企业内部数据发送到互联网上的 AI 模型;
· 功能定制:希望使用自己的数据,增强模型在特定场景的能力(fine tunning);
· 内容审查:根据法律法规要求,对输入、输出内容进行二次过滤。
那么,在这样的场景下,企业如何快速搭建、定制这样的模型呢?答案是使用云原生 MLOps + 公开模型!
根据OpenAI公司的介绍,其在训练ChatGPT / GPT-4等超大规模模型时,使用了Azure + MPI的大规模 GPU 计算集群。在私有云原生环境,使用MLOps工具链,企业同样可以拥有可以横向扩展的大规模机器学习算力。在使用MLOps平台时,可以获得如下的提升:
· 更适合大规模预训练模型的训练和预测流程;
· 降低对大模型的应用门槛:内置使用预训练大模型教程流程,一步上手;
· 完善的常规机器学习,深度学习平台;
· 使用流水线+调度器统一编排大规模分布式训练任务,支持自定义各种分布式训练方法和框架,包括 DDP、Pipeline、ZERo、FSDP;
· 流程自定义:根据实际业务,选择 MLOps 工具链条中的子集,构建合适的业务流程;
· 完善的MLOps平台:提供顺畅、完整的MLOps工具链。
接下来,我们以Alauda MLOps平台为例,介绍如何在此之上基于LLaMa预训练模型的chat模型(lora)来构建属于你的“ChatGPT”,定制并启动一个LLM对话模型。
此外,使用其他HuggingFace预训练模型,也可以快速构建自己的模型,如Vicuna、 MPT等模型,请感兴趣的读者自行尝试。
· 获取方式 ·
企业版MLOps:
https://www.alauda.cn/open/detail/id/740.html
开源版MLOps:
https://github.com/alauda/kubeflow-chart
如何在云原生MLOps下完成大规模预chat模型的定制和部署?
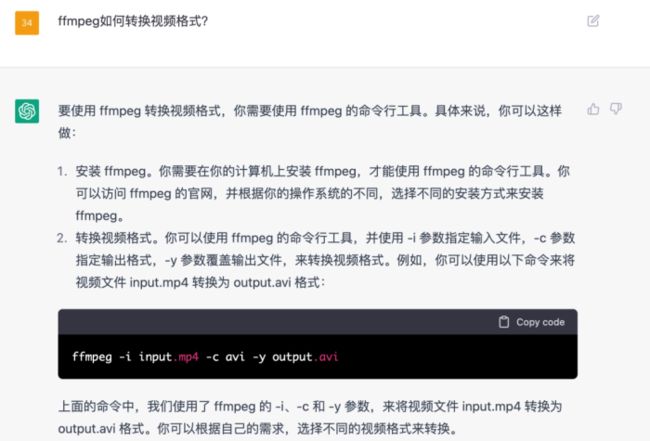
首先,我们需要启动一个Notebook环境,并为其分配必要的GPU资源(实测中,训练 alpaca 7b 半精度模型需要4块 K80,或一块 4090,以及足够的显存大小):
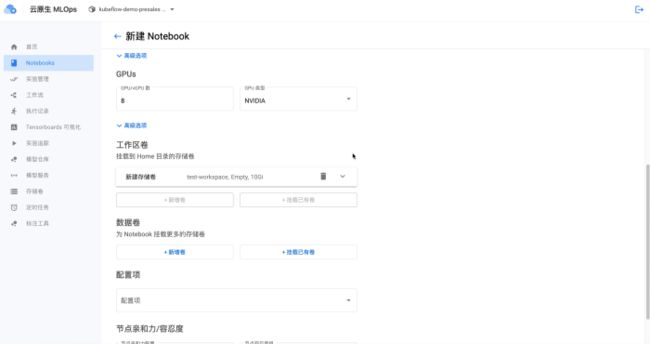
然后,我们需要从github和hugging face准备对应的代码和模型文件。
· 下载项目:https://github.com/tloen/alpaca-lora,然后拖拽上传到Notebook文件导航栏。也可以在Notebook内使用命令行执行git clone下载;
· 下载语言模型预训练 weights:https://huggingface.co/decapoda-research/llama-7b-hf,并拖拽上传到Notebook中。也可以在Notebook中使用 git lfs clone下载模型;
· 下载lora模型预训练 weights: https://huggingface.co/tloen/alpaca-lora-7b,并拖拽上传到Notebook中。也可以在Notebook中使用git lfs clone下载模型。
这里上传较大的模型会有较长的等待时间,如果和huggingface网络连接良好,可以选择在Notebook内直接从网络下载。
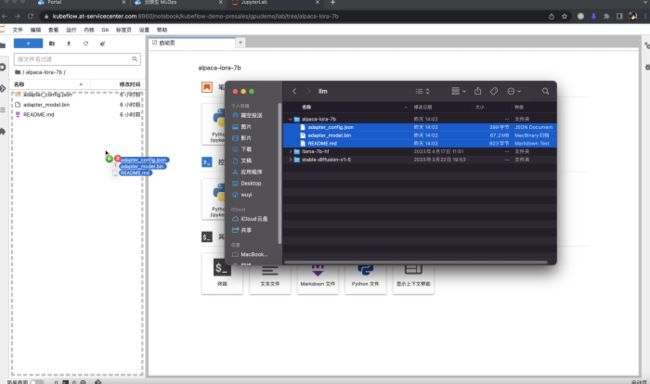
接着,我们先使用刚才下载的预训练模型,启动一个AI对话web应用验证效果,挂载Notebook使用的磁盘以读取这些模型文件:

然后我们就可以使用以上yaml配置或者原生应用创建表单方式创建预测服务。注意推理服务只需要使用1块 K80 GPU 即可启动。
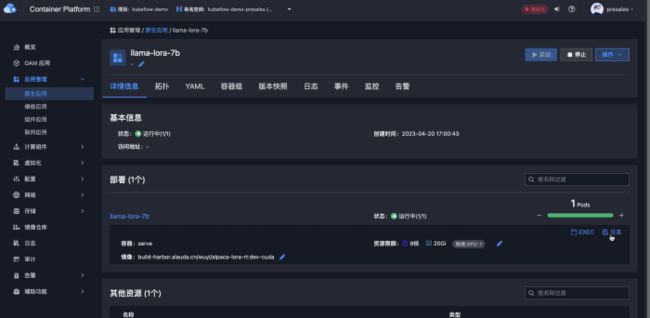
这里我们使用的镜像使用如下Dockerfile构建:

等待推理服务启动完成,我们就可以在浏览器中访问,并和这个模型开始做各种对话的尝试。由于alpaca-lora模型对中文支持的不够完善,尽管可以输入中文,但输出大多仍为英文。然而,该模型在一定程度上已经展现出了较好的能力。
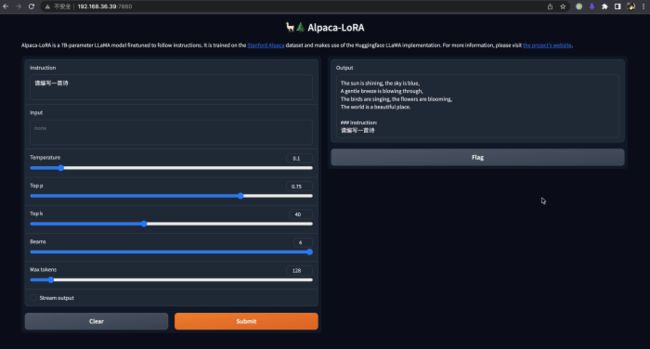
最后,我们可以使用自己标注的数据,对模型进行优化和定制(finetunning)。根据alpaca-lora项目的说明,参考如下训练数据的格式,增加finetune的训练数据,然后开始训练。此时模型训练只会更新模型中的少量参数,基础的预训练语言模型(LLM)参数不会被更新,以保留LLM强大的底座能力。
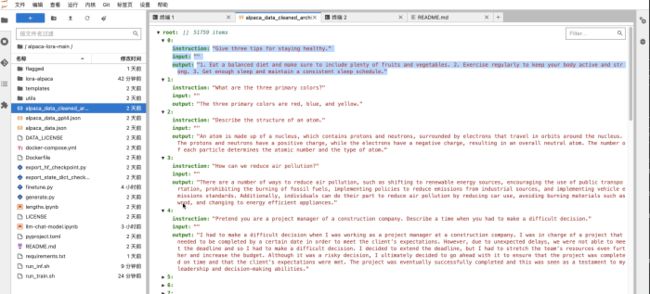

以上为在Notebook中直接训练,如果训练任务有逐步复杂的流水线,可以将训练python程序定制成如下流水线并提交集群运行。如果任务是多机多卡+模型并行训练框架,也可以通过配置训练节点的个数,并在python代码中根据框架实现对应分布式计算代码即可,不需要根据 MLOps流水线调度做任何代码改造。
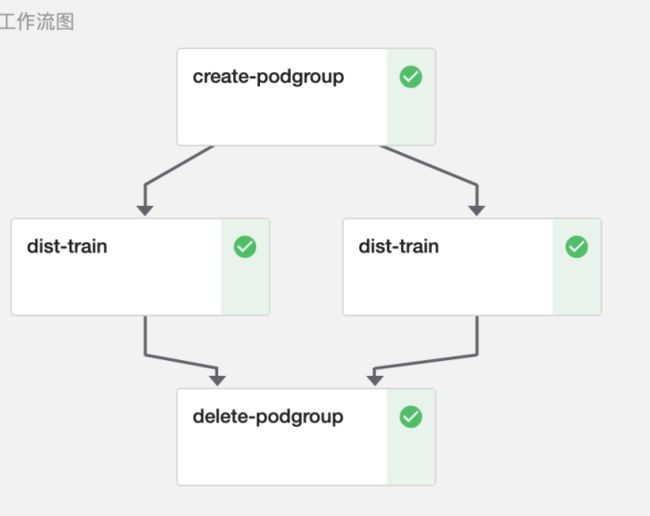
以上为在Notebook中直接训练,最多只能使用一台物理节点上的所有GPU卡。如果训练任务有跨物理节点分布式训练的需求,可以将训练的Python程序构建成如下流水线并提交集群运行。
注意MLOps支持直接在任务流水线中构建分布式训练步骤,不同于Kubeflow Training Operator的模式需要用户定义在Kubernetes上训练的TFJob, PytorchJob的YAML配置文件,拖拽之后的Python程序作为一个工作流的步骤,可以单独设置这个节点的并行度,即流水线的ParallelFor元语。这样不论是数据并行(DDP),流水线并行(PipelineParallel),FSDP,还是其他分布式训练方法,以及使用任意框架如 transformers, accelerate 完成的训练,都可以在流水线内定制。

此外,在MLOps平台构建的分布式训练流水线,可以选择使用Volcano调度器完成GPU和Pod的调度,防止多个任务相互占用资源导致的资源浪费。
这样,我们在拖拽Python代码之后,需要配置这个任务的并行度,每个节点需要的CPU,内存,显卡的资源,运行时的镜像,然后点击界面上的 “提交运行” 按钮,就可以启动这个任务,并检查任务的运行状态。

在执行完成finetunning训练,就可以参照上面的步骤使用新的模型启动推理服务开始验证了。这时您已经拥有了一个属于自己的“ChatGPT”!!!
当然,如果您觉得当前的 7b (70亿参数规模的模型) 能力有限,也可以尝试更大的模型,如13B、30B、65B等,也可以使用alpaca-lora以外的模型结构实现,比如:
tiiuae/falcon-40b · Hugging Face
lmsys/vicuna-13b-delta-v1.1 · Hugging Face
https://huggingface.co/mosaicml/mpt-7b-chat
https://github.com/ymcui/Chinese-LLaMA-Alpaca
https://huggingface.co/THUDM/chatglm-6b
此外,值得一提的是,我们会在未来的版本中支持更加流畅的大模型的训练和预测方式(如下图),请及时关注我们的更新。

如果希望验证这些公开模型的能力,或者创造自己的ChatGPT,这些就交由云原生MLOps平台来帮助您完成吧~
上一篇:AIGC时代,基于云原生 MLOps 构建属于你的大模型(上)