客户端ack模块的实现
文章目录
- 背景
- 第一版设计
- 第二版设计
- 第三、四版设计
- 写在最后
背景
所谓客户端ack模块是在我们推送服务中一个技术需求,本文主要介绍其迭代过程。
首先简单介绍下推送服务的架构,如下图。用户请求ws服务,建立ws长连接,并通过login和subscribe请求建立订阅关系。使用uid代表用户,topic代表用户订阅的数据类型。业务服务使用connector sdk通过grpc stream同ws服务建立双向通信,将业务数据推送至ws服务。

为了减少connector和ws服务间的冗余通信,在connector中维护了用户的订阅状态以做前置的过滤。当用户有上下线以及订阅取消订阅行为时,ws服务会将用户状态同步至connector。为了保证ws同connector间状态的最终一致性,需要在ws服务增加客户端ack模块来确保connector收到状态同步消息。
第一版设计
拿到这个技术需求后,首先去了解了当前状态同步的协议,发现其为增量同步。当某个用户状态发生变化时,ws会将变化的部分发送至connector sdk。示意如下。
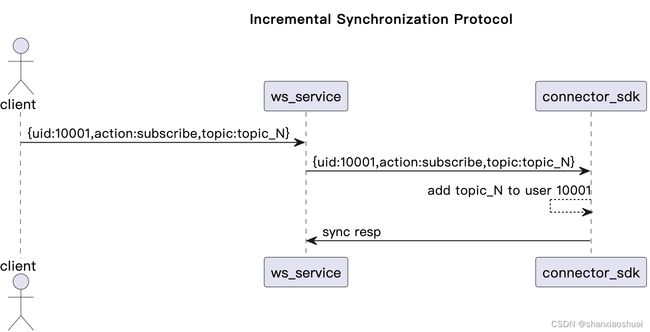
针对增量同步的方式,我们的ack模块需要面对两个问题:
- 需要为每个消息增加唯一的标识;
- ack模块需要实现exactly one;
第一个问题很容易解决,使用全局递增的request id就足够解决。
第二个问题是ack中常见的问题,因为涉及到重试。
单纯的客户端ack机制只能保证at least once,需要协同服务端的消息幂等性保证才能实现exactly one。在增量同步的协议,通常需要依赖唯一的request id来实现服务端的幂等,收到消息检验request id是否已经收到过,然后保存request id。kafka的exactly once就采用了这种方式,但是在我们的场景下需要在server端(connector)维护额外的消息状态,会引入过多的复杂度,这是我不想要的。
针对以上的问题,我选择调整状态同步的协议,将增量同步的方式更改为uid维度的全量同步。每当用户的订阅状态发生变化时,ws会将uid的当前状态全量同步至connector sdk。示意如下。
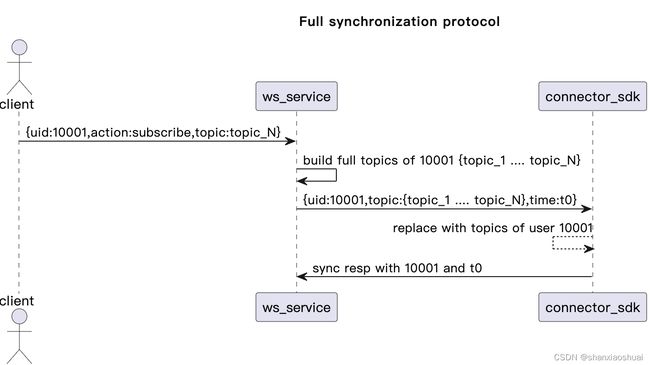
更改协议后,我们可以使用uid作为消息的标识,因为消息本身就具有uid维度的幂等性,所以上面的两个问题就解决了。
同时,因为同一uid的消息是具备覆盖特性的,对于同一uid的消息,我们只需要关注最近发生的一条是否到达connector sdk即可。所以在消息中增加了timestamp标识消息的新旧,同时纳秒级的timestamp也可以帮助我们在server端解决ABA的问题。
实现参见ack_v1.0.0,实现比较简单,就不贴代码了。在1.0.0中,基于上述描述实现了基本的功能。能够记录最新的消息,删除收到响应的消息,给出duration(duration不建议太小,5-10s是比较好的选择)时间内没有收到响应的消息。另外,还有一些小的优化点:
- 提供方法对map进行重新分配以防止大map的内存泄漏;
- 封装了分段的结构,以减少锁的粒度,提高并发度;
第二版设计
上述第一版的设计,在常见的client\server架构下是没有问题的。所谓常见的client\server架构是指client和server之间为单向通信,client发出请求,server给出响应。
但是在我们的推送服务中,connector作为server不仅给出状态同步请求的响应,同时会推送大量的业务数据。并且在目前的设计上,响应和业务数据是共享同一条grpc stream以及同一个loop receiver的goroutine。如果在收到状态同步请求的响应去ack时出现锁的阻塞,会阻塞整个推送服务。
在一次新业务接入的切流过程中,就出现了因为ack时锁的阻塞导致进程假死的现象。当然个人觉得不是ack模块的设计问题,主要原因有两个:
- 切流时根本没有进行评估,cpu被打满(个人觉得是主要原因);
- 在对ack消息进行重发时,会重复记录消息(会造成写放大);
虽然导致阻塞假死的原因是其他因素造成的,但是还是希望通过一些代码设计上的优化能够尽量兼容这些边界情况。提出的解决方案有两个:
- 在业务层,将状态同步消息的处理和业务消息的处理进行隔离,拆分到不同的grpc stream,由不同的goroutine处理;
- ack模块提供异步处理的能力;
我其实更倾向于第一种方案,隔离地更加彻底。但是站在ack模块的角度,针对这种大流量双向通信的场景,提供异步操作的模式是更完善的能力。所以在ack_v1.0.1中,提供了异步处理的模式,可以通过参数控制。

需要注意的是,当异步处理的buffer满时,会将消息丢弃掉,此时会造成可能的状态不一致。针对这种情况,我的建议是:
- 根据场景合理的选择分段锁的粒度,增加并发度;
- 根据场景合理的设置buffer的大小;
- 通过可观测性的手段(比如metrics)将丢弃的消息告警出来,通过人工补偿的手段去处理;
第三、四版设计
在ack_v1.0.1中,除了异步的设计,还引入了msg的概念,以适应更通用的场景,并在ack_v1.1.0中升级为泛型版本。


其中value用来保存实际的业务消息。flag用来在ack时确认是否能够ack,比如我们上述业务场景下flag是时间戳。只有时间戳大于等于当前保存的时间戳才能被ack,否则忽略,保证只有消息不会被更久的响应ack。
写在最后
整个ack模块的设计比较简单,但是当我真正想把代码做得通用、好用、简单用时,发现并不是那么简单,所以写篇博客记录一下,代码也放到github上,欢迎大家提出宝贵建议。