spark入门
PySpark入门
- 1.Spark介绍
-
- 1.1spark的应用及使用
- 1.2Spark的计算流程设计
- 1.3Spark的单机模式及测试
-
- 1.3.1Spark在Linux上Anaconda部署Python
- 1.3.2Spark本地模式部署
- 1.3.3Spark Python Shell单机部署
- 1.3.4.Map算子实现分布式转换
- 1.3.5WordCount需求及分析
- 1.3.6WordCount开发及实现
- 1.3.7圆周率计算
- 1.4Sparkalone集群
-
- 1.4.1Sparkalone集群架构
- 1.4.2Standalone集群部署
- 1.4.3Standalone集群启动
- 1.4.4standalone集群测试
- 1.4.5Standalone集群高可用HA
- 1.4.6Pysapk本地开发环境搭建
-
- 1.4.6.1Windows安装Anaconda
- 1.4.6.2windows安装jdk和hadoop
- 1.4.6.3Anaconda中安装Pyspark
- 1.4.6.4开发环境:Pycharm中创建工程
- 1.4.6.5工程结构规范说明
- 1.4.6.6pyspark调用环境配置
- 1.4.6.7sparkcontext的功能及构建
- 1.4.6.8PySpark代码模板的构建
- 1.4.6.9WordCount代码开发测试
- 1.4.6.10本地开发-正则处理
- 1.4.6.11本地开发-文件系统
- 1.4.6.12本地开发-动态传参
- 1.4.6.13Spark程序监控
- 1.5PySpark集群的提交方式
-
- 1.5.1.远程提交测试
- 1.5.2.spark_submit脚本
- 1.5.3.提交WordCount
- 1.5.4.Spark程序核心概念
- 1.5.5.集群提交:deploy mode
- 1.5.6.Spark on yarn的实现
- 1.5.7.spark on yarn配置测试
- 1.5.8.Yarn程序的运行流程
- 1.5.9.spark onyarn-面试核心
- 1.5.10.分布式程序开发基本思想
- 1.6RDD的算子分类及常用基础算子
-
- 1.6.1.RDD的设计及定义
- 1.6.2.RDD的五大特性
- 1.6.3.wordcount程序中的rdd
- 1.6.4.RDD的两种创建方式
- 1.6.5.RDD读取小文件处理
- 1.6.6高阶函数Lambda表达式
- 1.6.7RDD算子分类
- 1.6.8常用转换算子filter/map/flatmap
- 1.6.9常见触发算子count/foreach/saveTextFile
- 1.6.10其他触发算子:first/take/collect/reduce
- 1.6.11RDD常用的分析算子-uninon/distinct
- 1.6.12分组聚合算子-groupByKey/reduceByKey
- 1.6.13排序算子-sortBy/sortBy'Key/takeOrdered
- 1.6.14重分区算子-repartiton/coalesce
- 1.6.15RDD的算子使用案例
- 1.6.16网站分析案例-数据加载
- 1.6.17pv统计
- 1.6.18uv统计
- 1.7RDD其他算子
-
- 1.7.1reduce算子的实现原理
- 1.7.2其他聚合算子
- 1.7.3其他kv类型算子
- 1.7.4join关联算子
- 1.7.5分区处理算子
- 1.7.6搜狗日志分析案例
- 1.7.7jieba中文分词器
- 1.7.8数据加载清洗
- 1.7.9搜索关键词TopN统计
- 1.7.10用户搜索点击统计
- 1.7.11搜索时间段TopN统计
- 1.8Spark容错机制
-
- 1.8.1数据容错方案
- 1.8.2RDD容错机制:persist
- 1.8.3RDD容错机制:checkpoint
- 1.8.4spark共享变量-数据共享
- 1.8.5Broadcast Variables广播变量
- 1.8.6分布式计算问题
- 1.8.7Accumulators累加器
- 1.8.8Spark内核调度
- 1.8.9spark应用执行流程
- 1.8.10Spark中的宽窄依赖
- 1.8.11spark的shuffle设计
- 1.9SparkSQl设计及入门
-
- 1.9.1sparkCore重点
- 1.9.2Spark的优化思路
- 1.9.3SparkCore的缺点
- 1.9.4SparkSQL的介绍
- 1.9.5SparkSQL的介绍
- 1.9.6SQL与Core的对比
- 1.9.7SparkSQL的编程规则
- 1.9.8SparkSQL实现WordCount
- 1.9.10DataFrame的设计
-
- 1.9.10.1DataFrame的设计与发展
- 1.9.10.2Row和Schema的概念及使用
- 1.9.10.3自动推断类型转换Dataframe
- 1.9.10.4自定义Schema转换DataFrame
- 1.9.10.5指定列名称转换DataFrame
- 1.9.11电影评分top10
-
- 1.9.11.1电影数据及需求分析
- 1.9.11.2读取数据并封装DF
- 1.9.11.3基于SQL实现TopN
- 1.9.11.4关联数据构建结果
- 1.9.11.5SQL和DSL的使用
- 1.9.11.6DSL开发使用API函数
- 1.9.11.7DSL开发使用SQL函数
- 1.9.11.8Catalyst优化器
- 1.9.12 SparkSQL外部数据源
-
- 1.9.12.1SparkSQL读写数据的方式
- 1.9.12.2读写Text文件使用
- 1.9.12.3读写Json文件使用
- 1.9.12.4 读写Parquet文件使用
- 1.9.12.5读写CSV文件使用
- 1.9.12.6读写JDBC使用
- 1.9.12.7 读写Hive使用
- 1.9.13 SparkSQL的UDF
-
- 1.9.13.1 UDF函数的设计
- 1.9.13.2 register方式定义UDF函数
- 1.9.13.3 udf注册方式定义UDF函数
- 1.9.14 零售数据分析案例
-
- 1.9.14.1 案例数据及需求分析
- 1.9.14.2 案例数据加载及数据清洗
- 1.9.14.3 每个省份总销售额统计
- 1.9.14.4 销售额Top3省份数据过滤
- 1.9.14.5 销售额Top3省份的店铺个数
- 1.9.14.6 销售额Top3省份的平均订单金额
- 1.9.14.7 销售额Top3省份的支付类型占比
- 1.9.15 SparkSQL使用方式及优化
-
- 1.9.15.1 spark-sql脚本的使用
- 1.9.15.2 ThriftServer的使用
- 1.9.15.3 工作中不同场景下的使用方式
- 1.9.15.4 Spark总结优化及数据倾斜
1.Spark介绍
1.Spark官网:https://spark.apache.org/
定义:基于内存式计算的分布式统一化的数据分析引擎
功能:数据分析引擎工具栈
- 实现离线数据批处理,类似于MapReduce,写代码做处理
- 实现交互式即时数据查询:类似于Hive、Presto、Impala,使用SQL做即席查询分析
- 实现实时数据处理:类似于Storm、Flink实现分布式的实时计算
- 实现机器学习的开发:代替传统一些机器学习工具
2.场景:所有需要对数据进行分布式的查询、计算、机器学习都可以使用Spark来完成
- 工作中Spark目前主要的应用场景:SparkSQL做离线计算,实时计算使用Flink来实现
3.SparkSQL、Presto、Impala:都是基于SQL的内存式计算引擎
-
SparkSQL:性能垫底,功能最全面,使用成本最低
-
Presto:性能其次,支持多数据源接口:Hive、ES、Kafka
-
Impala:性能最高,语法兼容性很差,用于对Hive和Hbase数据查询统计
SparkCore:最底层核心的模块,所有上层计算底层都是SparkCore,面试中核心
SparkSQL:功能最强大的模块,既能做离线也能做实时,既能写SQL也能写代码,底层环视SparkCore,使用Spark的核心
Spark Streaming:准时计算的模块,底层也是SparkCore,使用离线来模拟实时
Spark MLib:机器学习的算法库,主要用于实现推荐系统等应用的算法库
Spark GreaphX:图计算,基于图数据结构实现一些计算
开发语言:Python,SQL,Scala,Java,R -
SQL:简单但不灵活,不能满足复杂开发任务
-
编程语言:灵活但不简单,不适合做简单的统计分析
Batch/Streaming data:统一化离线计算和实时计算开发方式,支持多种开发语言
SQL analytics:通用的SQL分析快速构建分析报表,运行速度快于大多数数仓计算引擎
Data science at scale:大规模的数据科学引擎,支持PB级别的数据进行探索性数据分析,不需要使用采样
Machine learning:可以支持在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到数千台机器的集群上
1.1spark的应用及使用
应用场景:
1.离线场景:实现离线数据仓库中的ETL、数据分析、即时查询等应用,非常成熟,工作中主要的应用场景
2.实时场景:实现实时数据流的数据处理,但功能相对不够完善,工作中建议使用Flink来代替
运行模式:
1.Local:程序运行在本地,只启动一个进程来运行所有Task任务,没有集群架构
2.Standalone:Spark自带的分布式资源管理平台的集群,可以将Spark运行在自带的Standalone集群
3.YARN:Spark on YARN,将Spark程序提交到YARN中运行,由YARN提供分布式资源
4.Messos:类似于YARN,国外用的比较多,国内基本没有
5.K8s:基于容器化的平台
1.2Spark的计算流程设计
MR的计算流程
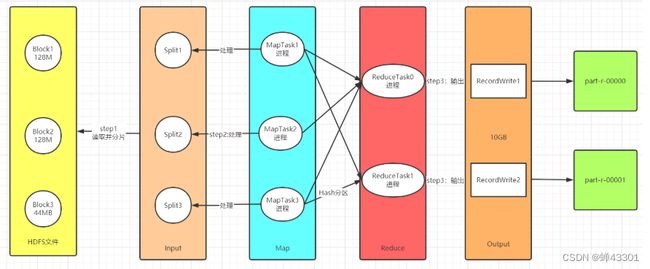
1.step1读取数据:Input
- 功能一:实现分片,将读取到的数据进行划分,将不同的数据才能分给不同的task
- 功能二::转换kv
2.step2处理数据:Map,Shuffle,Reduce
Map:负责数据处理:一对一的转换,多对一的过滤
- 功能一:构建分布式并行Task,每个分片对应一个MapTask
- 功能二:每个MapTask负责自己处理的分片的数据的转换,转换逻辑由map方法来决定
shuffle:负责数据处理
- Map输出写入数据:磁盘
- 功能:实现全局的分区,排序,分组
- Reduce读取Map输出的数据:读取磁盘
Reduce:负责数据处理:多对一的聚合
- 功能:默认由一个ReduceTask进程来实现数据的聚合处理
3.step3保存结果:Output
- 功能:将上一步的结果写入外部系统
spark的计算流程
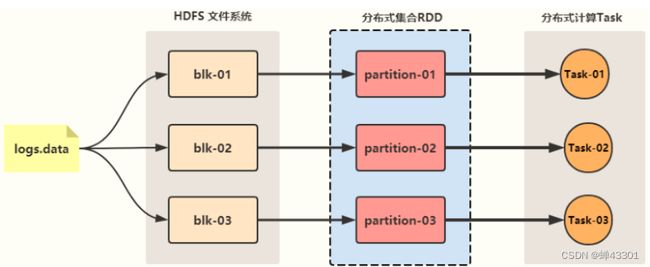
1.step1:读取数据
-
根据分片规则,将数据源进行分片,每个分片作为一个数据分区
-
整个数据的所有分区从逻辑上合并为一个整体,Spark中称之为RDD
-
一个RDD就代表读取到的数据这个数据由多个分区组成,每个分区数据存储在不同的机器内存中
-
RDD可以理解为一个分布式的列表集合:list
-
将所有数据读取放入一个分布式列表:RDD(一个RDD中包含多个分区)
2.处理数据 -
对RDD调用函数进行处理,Spark底层就会启动多个Task(线程)对这个RDD的每个分区来进行并行处理
-
处理流程由代码中的函数决定,可以有 多个Map和多个Reduce阶段
-
如果不经过Shuffle,上一步处理的结果可以存储在内存中,直接供下一步进行计算
-
RDD.map.reduce.map.reduce.map.map:对分布式列表通过代码定义处理逻辑,底层这个RDD每个分区会用一个Task来实现转换
3.保存结果
- 将每个Task计算的结果进行输出保存
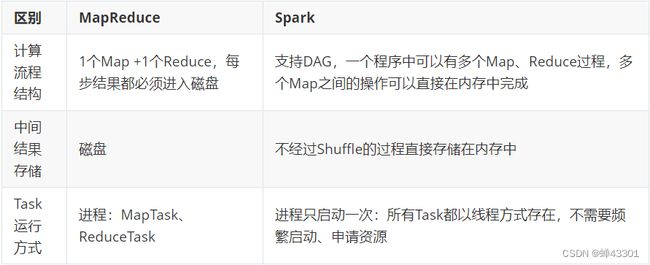
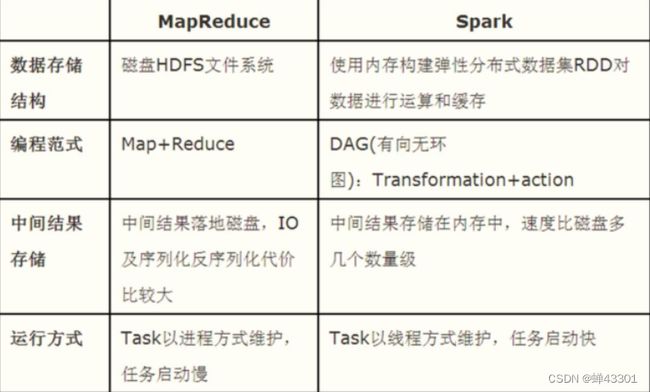
4为什么比MR要快
1.3Spark的单机模式及测试
1.3.1Spark在Linux上Anaconda部署Python
目标:实现Linu机器上使用Anaconda部署Python
安装:
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
第一次:【直接回车,然后按q】
Please, press ENTER to continue
>>>
第二次:【输入yes】
Do you accept the license terms? [yes|no]
[no] >>> yes
第三次:【输入解压路径:/export/server/anaconda3】
[/root/anaconda3] >>> /export/server/anaconda3
第四次:【输入yes,是否在用户的.bashrc文件中初始化Anaconda3的相关内容】
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes
激活
# 刷新环境变量
source /root/.bashrc
# 激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate
验证
python3
配置
# 编辑环境变量
vim /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/export/server/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin
# 刷新环境变量
source /etc/profile
# 创建软连接
ln -s /export/server/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME
python3
1.3.2Spark本地模式部署
安装
# 解压安装
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server
# 重命名
cd /export/server
mv spark-3.1.2-bin-hadoop3.2 spark-local
# 创建软连接
ln -s spark-local spark
配置
# 编辑环境变量
vim /etc/profile
# 添加以下内容
# Spark Home
export SPARK_HOME=/export/server/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# 刷新环境变量:这是命令,不能放在文件中
source /etc/profile
1.3.3Spark Python Shell单机部署
目标:掌握Spark Shell的基本使用
实施功能:
- 提供一个交互式的命令行,用于测试开发Spark的程序代码
- spark-shell:基于Scala语言开发Spark的测试命令行
- spark-sql:基于SQL语言开发Spark的测试命令行
- pypark:基于Python语言开发Spark的测试命令行
- 注意:本质上是运行了一个Spark程序
启动
pyspark --master local[2]
1.3.4.Map算子实现分布式转换
目标:实现使用map算子分布式转换
- SparkCore中的函数叫做算子
- map:用于将列表中的每个元素取出来,调用参数中的函数进行处理,将每个元素的处理结果放入一个新的列表中
- 构建一个普通列表
- 对列表进行转换
list1 = [1,2,3,4,5,6,7,8,9,10]
list2 = map(lambda x : x ** 2, list1) - lambda x:x**2:匿名函数表达式
- x:代表这个函数的参数
- x**2:这个函数的返回值
- 结构:lambda参数名:处理逻辑/返回值
转换输出的结果
print(*list2)
Spark实现分布式转换
- step1:将普通列表转换为分布式集合:RDD
- step2:对RDD进行分布式处理转换
- step3:分布式的输出结果
代码示例:
# 定义一个列表
list1 = [1,2,3,4,5,6,7,8,9,10]
# 将列表通过SparkContext将数据转换为一个分布式集合RDD
inputRdd = sc.parallelize(list1)
# 将RDD中每个分区的数据进行处理
rsRdd = inputRdd.map(lambda x : x**2)
# 将结果RDD的每个元素进行输出
rsRdd.foreach(lambda x : print(x))
1.3.5WordCount需求及分析
目标:掌握WordCount需求及实现思路的分析
对word.txt文本实现词频统计,统计每个单词出现的次数
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
实现思路:
step1:读取文件将文件的数据变成为分布式结合数据
RDD1
1.part0:
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
hive hadoop spark spark
2.part1:
hue hbase hbase hue hue
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
step2:先过滤,将空行过滤掉
RDD2
part0:
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
hive hadoop spark spark
part1:
hue hbase hbase hue hue
hadoop spark
hive hadoop spark spark
hue hbase hbase hue hue
hadoop spark
step3:将每一行多个单词转换为一行一个单词
RDD3
part0:
hadoop
spark
hive
hadoop
spark
spark
hue
hbase
hbase
hue
hue
hadoop
spark
hive
hadoop
spark
spark
part1:
hue
hbase
hbase
hue
hue
hadoop
spark
hive
hadoop
spark
spark
hue
hbase
hbase
hue
hue
hadoop
spark
step4:将每个单词转换为KeyValue的二元组(word,1)
RDD4
part0:
hadoop 1
spark 1
hive 1
hadoop 1
spark 1
spark 1
hue 1
hbase 1
hbase 1
hue 1
hue 1
hadoop 1
spark 1
hive 1
hadoop 1
spark 1
spark 1
part1:
hue 1
hbase 1
hbase 1
hue 1
hue 1
hadoop 1
spark 1
hive 1
hadoop 1
spark 1
spark 1
hue 1
hbase 1
hbase 1
hue 1
hue 1
hadoop 1
spark 1
step5:按照单词分组聚合
分组
part0:
('hadoop', [1,1,1,1,1,1])
('hive', [1,1,1])
('hue', [1,1,1,1,1,1,1,1,1])
part1:
('spark', '[1,1,1,1,1,1,1,1,1,1,1])
('hbase', [1,1,1,1,1,1])
聚合
part0:
('hadoop', 7)
('hive', 3)
('hue', 9)
part1:
('spark', 10)
('hbase', 6)
step6:输出结果保存到文件中
1.3.6WordCount开发及实现
目标:实现WordCount程序的开发
step0:上传word.txt文件到Linux本地:node1
cd /export/data/
rz
step1:读取文件,将文件的数据变成分布式集合数据
# 将这个文件读取到Spark中,变成一个分布式列表对象
fileRdd = sc.textFile("file:///export/data/word.txt")
# 输出这个数据一共有多少行
fileRdd.count()
# 输出这个数据前3行的内容
fileRdd.take(3)
step2:先过滤,将空行过滤掉
# 对RDD中的数据进行过滤,取每个元素进行判断,符合条件的留下来,放入一个新的RDD中
filterRdd = fileRdd.filter(lambda line : len(line.strip()) > 0)
filterRdd.count()
filterRdd.take(3)
step3:将每一行多个单词转换为一行一个单词
# 将每条数据中一行多个单词,变成一行一个单词
wordRdd = filterRdd.flatMap(lambda line : line.strip().split(r" "))
wordRdd.count()
wordRdd.take(10)
step4:将每个单词转换为keyvalue的二元组(word,1)
tupleRdd = wordRdd.map(lambda word : (word,1))
tupleRdd.take(10)
step5:按照单词分组聚合
# 按照Key进行分组并且进行聚合
rsRdd = tupleRdd.reduceByKey(lambda tmp,item : tmp+item)
rsRdd.foreach(lambda kv : print(kv))
输出结果保存到文件中
rsRdd.saveAsTextFile("file:///export/data/wcoutput1")
合并开发
# 读取数据
inputRdd = sc.textFile("file:///export/data/word.txt")
# 转换数据
rsRdd = inputRdd \
.filter(lambda line : len(line.strip()) > 0) \
.flatMap(lambda line : line.strip().split(r" ")) \
.map(lambda word : (word,1)) \
.reduceByKey(lambda tmp,item : tmp+item)
# 保存结果
rsRdd.saveAsTextFile("file:///export/data/wcoutput2")
1.3.7圆周率计算
目标:实现官方圆周率计算的案例
测试:
/export/server/spark/bin/spark-submit \
--master local[2] \
/export/server/spark/examples/src/main/python/pi.py \
100
1.4Sparkalone集群
1.4.1Sparkalone集群架构
目标l理解standalone集群架构
分布式主从架构:整体的功能及架构高度类似于YARN
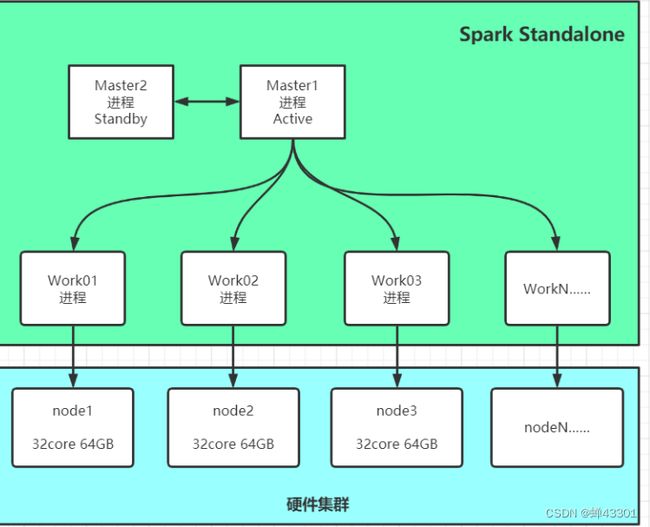
主:Master:管理节点
- 接收客户端请求
- 管理从节点
- 资源管理和任务调度
从:worker:计算节点
- 使用自己所在节点的资源运行计算进程Executor:给每个计算进程分配一定的资源
- 假设每台机器机器:32Core - 64GB
- 那么Worker的资源由配置决定,例如16Core - 32GB
- 表示Worker最多能使用这台机器的16Core32GB的资源用于计算
1.4.2Standalone集群部署
目标:实现Spark Standalone集群的部署
安装Spark:第一台机器
# 解压安装
cd /export/software/
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server
# 重命名
cd /export/server
mv spark-3.1.2-bin-hadoop3.2 spark-standalone
# 重新构建软连接
rm -rf spark
ln -s spark-standalone spark
配置集群节点
spark-env.sh
cd /export/server/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
# 22行
export JAVA_HOME=/export/server/jdk
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
# 60行
SPARK_MASTER_HOST=node1.itcast.cn
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_DAEMON_MEMORY=1g
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1.itcast.cn:8020/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
在HDFS上创建程序日志存储目录
start-dfs.sh
hdfs dfs -mkdir -p /spark/eventLogs/
spark-defaults.conf:Spark属性配置文件
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
# 末尾
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1.itcast.cn:8020/spark/eventLogs
spark.eventLog.compress true
workers:从节点地址配置文件
mv workers.template workers
vim workers
# 删掉localhost,添加以下内容
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
log4j.properties:日志配置文件
mv log4j.properties.template log4j.properties
vim log4j.properties
# 19行:修改日志级别为WARN
log4j.rootCategory=WARN, console
分发同步
cd /export/server/
scp -r spark-standalone node2:$PWD
scp -r spark-standalone node3:$PWD
第二台和第三台创建软链接
cd /export/server/
ln -s spark-standalone spark
配置环境变量:第二和第三台机器
# 编辑环境变量
vim /etc/profile
# 添加以下内容
# Spark Home
export SPARK_HOME=/export/server/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# 刷新环境变量
source /etc/profile
1.4.3Standalone集群启动
目标:掌握spark standalone集群的启动管理
实施启动:
- 启动master:
- 启动worker
- 启动historyserver
代码示例:
start-master.sh
start-workers.sh
start-history-server.sh
关闭
- 关闭master
- 关闭worker
- 关闭historyserver
代码示例:
stop-master.sh
stop-worker.sh
stop-history-server.sh
监控:启动以后才能访问
Master监控服务
historyserver历史监控服务
http://node1:8080/
http://node1:18080/
1.4.4standalone集群测试
目标实现spark程序在standalone集群上的测试
实施-圆周率测试:
/export/server/spark/bin/spark-submit \
--master spark://node1.itcast.cn:7077 \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3" \
/export/server/spark/examples/src/main/python/pi.py \
100
WordCountt测试
将word.txt文件上传到hdfs上
hdfs dfs -mkdir -p /spark/wordcount/input
hdfs dfs -put /export/data/word.txt /spark/wordcount/input/
启动sparkshell
/export/server/spark/bin/pyspark \
--master spark://node1.itcast.cn:7077 \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3"
测试WorkCount
# 读取数据
inputRdd = sc.textFile("/spark/wordcount/input")
# 转换数据
rsRdd = inputRdd \
.filter(lambda line : len(line.strip()) > 0) \
.flatMap(lambda line : line.strip().split(r" ")) \
.map(lambda word : (word,1)) \
.reduceByKey(lambda tmp,item : tmp+item)
# 保存结果
rsRdd.saveAsTextFile("/spark/wordcount/output1")
1.4.5Standalone集群高可用HA
目标:了解Spark Standalone集群的Master HA的搭建测试
关闭所有Spark进程
export/server/spark/sbin/stop-workers.sh
/export/server/spark/sbin/stop-master.sh
/export/server/spark/sbin/stop-history-server.sh
修改配置文件
cd /export/server/spark/conf/
vim spark-env.sh
#注释以下内容
#SPARK_MASTER_HOST=node1
#添加
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
分发
cd /export/server/spark/conf
scp -r spark-env.sh node2:$PWD
scp -r spark-env.sh node3:$PWD
启动ZK
zookeeper-daemons.sh start
zookeeper-daemons.sh status
启动Master
第一台:
/export/server/spark/sbin/start-master.sh
第二台
/export/server/spark/sbin/start-master.sh
启动worker
/export/server/spark/sbin/start-workers.sh
测试
/export/server/spark/bin/spark-submit \
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077 \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3" \
/export/server/spark/examples/src/main/python/pi.py \
100
1.4.6Pysapk本地开发环境搭建
1.4.6.1Windows安装Anaconda
目标:实现Windows本地Anaconda的安装
方式一:直接安装原生的Python解析器:https://www.python.org/
方式二:通过Anaconda来辅助安装管理:https://www.anaconda.com/products/individual-d
为什么选择Anaconda进行安装
原因:
- 强大的库包管理机制,自动安装全面的python库
- conda list:列举所有的包
- conda install包名:安装库包
- conda remove包名:移除库名
base:Anaconda自带的基础环境
# 切换
conda activate base
# 关闭
conda deactivate
1.4.6.2windows安装jdk和hadoop
目标:实现windows本地jdk和hadoop的安装
windows安装jdk
将提供的jdk.zip文件解压在没有中文符的路径下
windows安装hadoop
将hadoop解压爱没有中文的路径下
记住这个路径
1.4.6.3Anaconda中安装Pyspark
目标:实现windows中基于Anaconda环境安装PySpark
step1:进入cmd命令:
conda config --set show_channel_urls yes
step2:安装Pyspark
CMD中切换到base虚拟镜像环境
conda activate base
CMD中安装pyspark
conda install pyspark=3.1.2
或
pip install pyspark==3.1.2
step3:检查是否安装成功
1.4.6.4开发环境:Pycharm中创建工程
目标:实现pycharm中创建spark本地开发项目工程
实施:
新建工程:
选择python解析器
指定Anaconda中刚刚安装完pyspark的base虚拟环境
如果没有则手动启动

验证解释器
1.4.6.5工程结构规范说明
目标:理解项目代码开发的工程结构
main:用于存放每天开发的一些代码文件
resources:用于存放程序中需要用到的配置文件
datas:用于存放每天用到的一些数据文件
test:用于存放测试的一些代码文件
1.4.6.6pyspark调用环境配置
目标:掌握pyspark代码中依赖环境的配置
配置:
# 导包
import os
if __name__ == "__main__":
# 配置JDK的路径,就是前面解压的那个路径
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
1.4.6.7sparkcontext的功能及构建
目标:掌握sparkcontext的功能及代码构建
功能:
- 负责启动,监控整个程序组件
- 负责管理当前程序的所有配置信息
- 负责读取外部数据,将数据构建为RDD
- 负责解析同步提交job等
构建-代码示例:
# 导包
import os
from pyspark import SparkContext, SparkConf
# 程序入口
if __name__ == "__main__":
# todo:0-声明所有环境:Python解析器地址、JDK地址、Hadoop的地址
# 配置JDK的路径,就是前面解压的那个路径
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkContext对象
# 构建一个程序的配置对象:程序名字[setAppName],运行模式[setMaster],其他参数配置.set("spark.io.compression.codec","snappy")
conf = SparkConf().setAppName("AppName").setMaster("local[2]")
# 构建一个SparkContext对象
sc = SparkContext(conf=conf)
# todo:2-读取数据、处理数据、保存结果
# step1: 读取数据
# step2: 处理数据
# step3: 保存结果
print(sc)
# todo:3-关闭SparkContext
sc.stop()
1.4.6.8PySpark代码模板的构建
目标:基于PySpark程序开发的固定逻辑PySpark代码模板
创建项目模板:

添加代码:
代码示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
"""
-------------------------------------------------
Description : TODO:
SourceFile : ${NAME}
Author : ${USER}
Date : ${DATE}
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("App Name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# step2: 处理数据
# step3: 保存结果
# todo:3-关闭SparkContext
sc.stop()
测试:

1.4.6.9WordCount代码开发测试
目标:基于windows本地环境实现WordCount代码的开发测试
代码示例:
- **开发**
```python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
"""
-------------------------------------------------
Description : TODO:用于实现词频统计
SourceFile : 01.pyspark_core_wordcount
Author : Frank
Date : 2022/5/20
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("App Name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据:SparkContext对象负责读取文件
input_rdd = sc.textFile("../datas/wordcount/word.txt")
# 输出第一行
# print(input_rdd.first())
# 打印总行数
# print(input_rdd.count())
# step2: 处理数据
rs_rdd = input_rdd\
.filter(lambda line: len(line.strip()) > 0)\
.flatMap(lambda line: line.strip().split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda tmp,item: tmp+item)
# step3: 保存结果
# 打印结果
rs_rdd.foreach(lambda x: print(x))
# 结果保存到文件中:路径不能提前存在
rs_rdd.saveAsTextFile("../datas/output/wcoutput1")
# todo:3-关闭SparkContext
sc.stop()
1.4.6.10本地开发-正则处理
导包:import re
语法:re.split(分隔符,需要分割的字符串)
实现:\s+:代表空白符,第一个\是转义
rs_rdd = (input_rdd
.filter(lambda line: len(line.strip()) > 0)
# .flatMap(lambda line: line.strip().split(" ")) #按照空格分割的
.flatMap(lambda line: re.split("\\s+", line)) #\s+表示空白符,按照空白符进行分割
.map(lambda word: (word, 1))
.reduceByKey(lambda tmp,item: tmp+item)
)
1.4.6.11本地开发-文件系统
目标:实现windows本地开发读写hdfs文件系统
Linux集群:会自动加载hadoop中的core-site.xml
fs.defaultFS=hdfs://node1.itcast.cn:8020
所以默认地址为hdfs
解决方法:在代码中指定hdfs地址
input_rdd = sc.textFile(r"hdfs://node1:8020/spark/wordcount/input")
rs_rdd.saveAsTextFile(r"hdfs://node1:8020/spark/wordcount/output2")
解决当前windows用户没有写hdfs文件的权限
# 申明当前以root用户的身份来执行操作
os.environ['HADOOP_USER_NAME'] = 'root'
完整代码示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
"""
-------------------------------------------------
Description : TODO:用于实现词频统计
SourceFile : 03.pyspark_core_wordcount_hdfs
Author : Frank
Date : 2022/5/20
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['HADOOP_USER_NAME'] = 'root'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("App Name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据:SparkContext对象负责读取文件
input_rdd = sc.textFile("hdfs://node1.itcast.cn:8020/spark/wordcount/input")
# 输出第一行
# print(input_rdd.first())
# 打印总行数
# print(input_rdd.count())
# step2: 处理数据
rs_rdd = input_rdd\
.filter(lambda line: len(line.strip()) > 0)\
.flatMap(lambda line: line.strip().split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda tmp,item: tmp+item)
# step3: 保存结果
# 打印结果
rs_rdd.foreach(lambda x: print(x))
# 结果保存到文件中:路径不能提前存在
rs_rdd.saveAsTextFile("hdfs://node1.itcast.cn:8020/spark/wordcount/output2")
# todo:3-关闭SparkContext
sc.stop()
1.4.6.12本地开发-动态传参
目标:掌握如何在代码中实现动态传参
导包:
import sys
方法
argv:用于接收运行程序时传递的参数
实现:
# 导包
import sys
# 将程序中传递的第一个参数作为输入地址
input_rdd = sc.textFile(sys.argv[1])
# 将程序中传递的第二个参数作为输出地址
rs_rdd.saveAsTextFile(sys.argv[2])
Pycharm配置参数
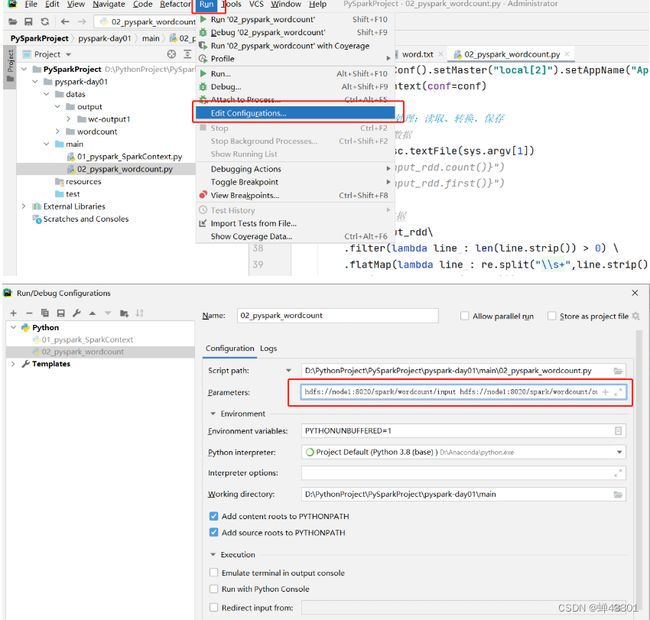
1.4.6.13Spark程序监控
目标:掌握spark程序监控的基本使用
测试:
import time
time.sleep(100000)

job:显示当前这个程序的所有job,一个程序可以有多个job
- spark中不是所有的代码都会触发job的产生和运行
- 所有rdd的转换是不会立即产生job,运行Task任务的,这种模式称为lazy模式:避免在内存中构建RDD,但时不用
- 只有遇到了需要使用数据的代码操作才会产生job,触发Task任务的运行

Stages:显示当前这个程序的所有Stage,一个job可以有多个Stage
- 当一个job被触发运行的时候,Spark底层会根据回溯算法构建这个job的执行计划图,即DAG图
- 每个job都会有1个DAG图,在构建的时候会根据计算构成中是否要产生shuffle来划分Stage
- 不产生shuffle的操作就再同一个Stage中执行,产生shuffle的操作,会传递到另外一个stage中执行
-最终每个stage中的操作会转换为对应的Task来执行

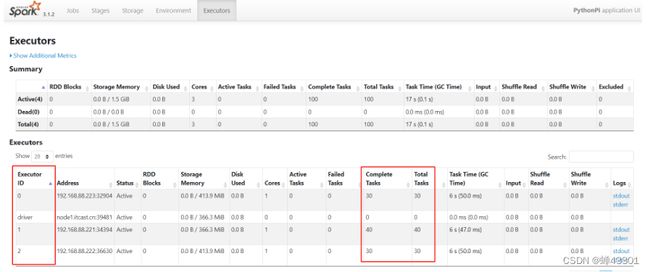
Executors:显示当前这个程序的运行进程信息 - 每个Spark程序都由两种进程组成,一个Driver和多个Executors
- Driver进程:负责解析程序,构建DAG图,构建Stage,构建,调度,监控Task任务的运行
- Executor进程:负责运行程序中的所有Task任务
1.5PySpark集群的提交方式
1.5.1.远程提交测试
目标:实现本地代码提交到远程集群测试运行
方式一:每次手动上传代码文件到Linux命令中能够
方式二:直接在Pycharm来实现远程运行
step1:在某一台Linux的Python环境中安装Pyspark
配置镜像源:
conda config --set show_channel_urls yes
vim /root/.condarc
安装pyspark:遇到y or n就输入y
conda install pyspark=3.1.2
验证:
conda list | grep pyspark
stop2:启动spark集群并创建同步目录
#启动集群:第一台机器
start-dfs.sh
start-master.sh
start-workers.sh
start-history-server.sh
#创建同步目录
mkdir -p /root/pyspark_code
step3:指定远程解析器
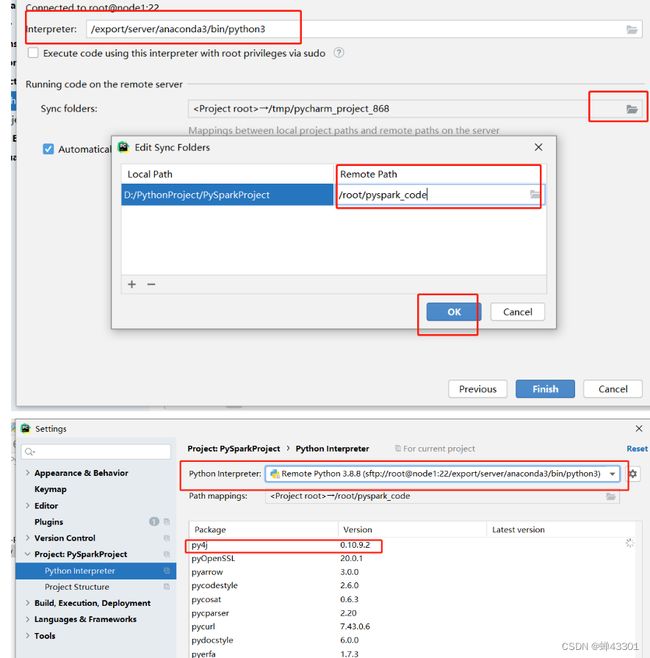
step4:上传,有的Pyharm需要手动上传
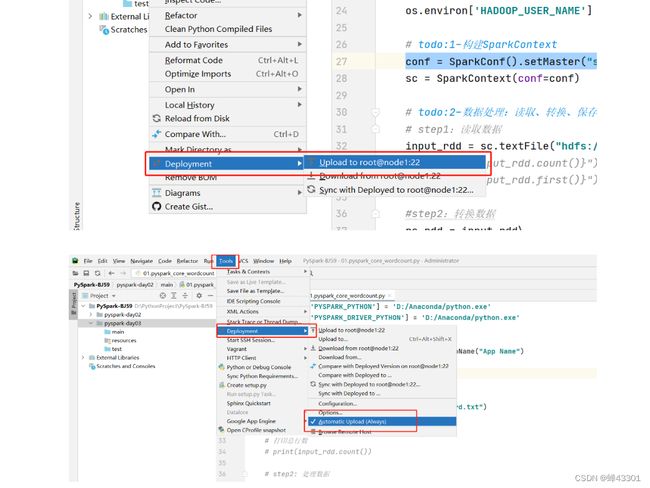
step5:修改代码,提交运行
修改集群模式
# 修改所有集群环境变量
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
代码示例:
- **==一定要记得将修改后的代码确保同步成功了==**
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ACEdLJov-1653637543141)(Day03_SparkCore核心设计:RDD.assets/image-20220522114901937.png)]
- 运行
```python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
import re
import sys
import time
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("spark://node1.itcast.cn:7077").setAppName("RemoteTest")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1:读取数据
input_rdd = sc.textFile("hdfs://node1:8020/spark/wordcount/input")
# print(f"{input_rdd.count()}")
# print(f"{input_rdd.first()}")
#step2:转换数据
rs_rdd = input_rdd\
.filter(lambda line : len(line.strip()) > 0) \
.flatMap(lambda line : re.split("\\s+",line.strip()))\
.map(lambda word : (word,1))\
.reduceByKey(lambda tmp,item : tmp+item)
#step3:输出结果
rs_rdd.foreach(lambda item : print(item))
rs_rdd.saveAsTextFile("hdfs://node1:8020/spark/wordcount/output3")
# todo:3-关闭SparkContext
time.sleep(100000)
sc.stop()

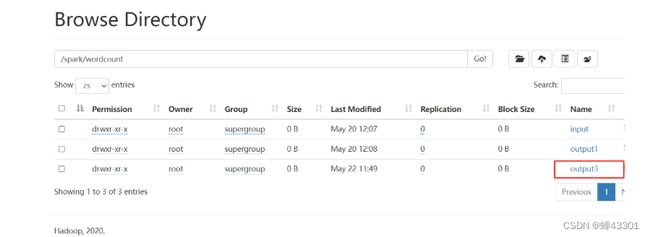
基于远程提交的解析器封装一个远程的代码模板
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
"""
-------------------------------------------------
Description : TODO:
SourceFile : 02.pyspark_core_remote_template
Author : Frank
Date : 2022/5/22
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量:全部换成Linux地址
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("Remote Test APP")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据:SparkContext对象负责读取文件
# step2: 处理数据
# step3: 保存结果
# todo:3-关闭SparkContext
sc.stop()
1.5.2.spark_submit脚本
目标:掌握sprk_submit脚本的使用
官网:https://spark.apache.org/docs/latest/submitting-applications.html
注释:
# 语法
spark-submit \
可选参数【程序名字、运行模式、资源配置、配置信息】 \
Python文件 \
代码中argV参数
# 示例
spark-submit [可选参数] pyspark_core_word_args.py /spark/wordcount/input /spark/wordcount/output
# 圆周率
/export/server/spark/bin/spark-submit \
# 参数要根据需求给定参数
--master local[2] \
# 文件是Pycharm中开发好的
/export/server/spark/examples/src/main/python/pi.py \
# 参数由Python文件代码决定
1000
基础选项:优先级
–master:用于指定当前程序提交运行在哪一种运行模式中
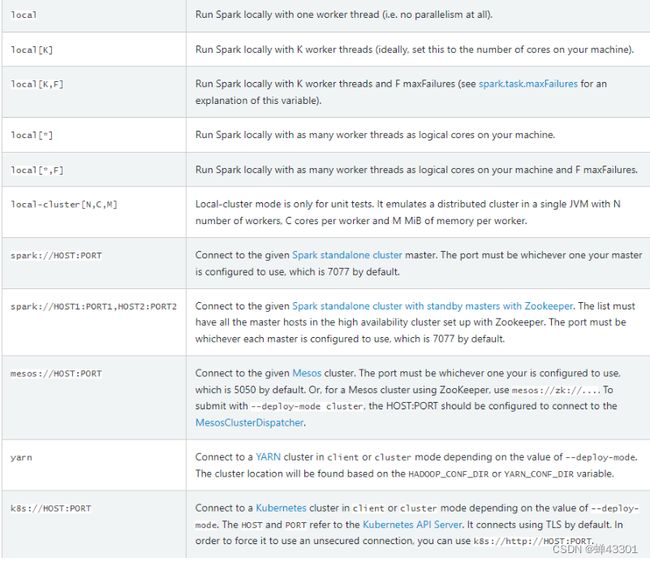
本地测试:local[K],k表示给定k核cpu来运行当前程序
standlone集群:spark://master:7077
Yarn集群:yarn
--deploy-mode:用于指定Driver进程运行的位置,默认为client,可以修改为cluster
--class:指定运行类,Python中不用管
--name:指定程序的名字,等同于代码中setAppName
--jars:指定额外用到的第三方的java库包
--conf:指定一些额外的配置,等同于代码中的set方法
spark程序集群模式运行时会启动两种进程:Driver驱动进程+Executor计算进程,每种进程运行时都需要资源
Driver资源选项:一般情况下,给默认的即可
Driver资源选项:一般情况下,给默认的即可
--driver-memory:Driver进程能用多少内存,默认Diver进程会使用1G内存
--driver-cores:Driver进程能用多少cpu,默认使用1corecpu
--supervise:Driver故障以后自动重启,避免Driver进程故障,影响程序的运行
Executor资源选项:基本每个spark程序都需要调节
--executor-memory:指定每个Executor进程都使用多少内存,默认是1G
--executor-cores:指定每个Executor能使用多少核cpu,yarn中默认为1,standlone中默认所有可用的
--total-executors:指定yarn集群中,这个程序总共启动几个Executor
--queue:指定运行的队列名称
1.5.3.提交WordCount
目标:实现开发的wordcount程序使用spark-submit提交
上传
cd /export/data
rz
测试本地运行
spark-submit \
--master local[2] \
/export/data/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output4
测试standalone集群
# 不指定资源:Standalone集群中会给定所有资源
spark-submit \
--master spark://node1.itcast.cn:7077 \
/export/data/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output5
# 指定资源:工作中每个程序在提交运行时,都需要根据数据量来合理指定每个程序使用的资源
spark-submit \
--master spark://node1.itcast.cn:7077 \
--driver-memory 512M \
--driver-cores 1 \
--supervise \
--executor-memory 1G \
--executor-cores 1 \
--total-executor-cores 2 \
/export/data/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output6

1.5.4.Spark程序核心概念
目标:理解spark程序核心概念
架构组成
- 主:Master管理节点
- 接受客户端请求,管理从节点worker节点,资源管理和任务调度
- 从:worker计算节点
- 使用自己所在节点的资源运行Executor进程,给每个Executor分配一定的资源
程序组成:任何一个spark程序都由两种进程构成
程序提交后会先启动Driver进程
Driver进程:驱动进程
- 想主节点申请Executor资源,让主节点从节点上根据需求配置启动对应的Executor
- 解析代码逻辑:将代码中的逻辑转换为task线程
- 将task分配给executor去运行
- 监控每个executor运行的task状态
Execitor进程:执行进程(运行task)
- 运行在worker上,使用worker分配的资源等待运行task
- 所有Executor启动成功以后会向Driver进行注册
- Executor收到Driver分配Task任务,运行Task
架构与程序关系
- Driver进程的启动由Master负责
- Master负责管理所有Worker资源,Driver会向Master请求启动Executor
- Worker上负责运行Executor进程
- Driver负责解析、分配、监控所有Task线程在Executor中运行

1.5.5.集群提交:deploy mode
目标:掌握集群模式中的deploy mode的功能及应用
将代码上传到hdfs上
hdfs dfs -mkdir -p /spark/app/py
hdfs dfs -put /export/data/pyspark_core_word_args.py /spark/app/py/
client模式:不加选项默认就是client模式
# 第三台机器提交
spark-submit \
--master spark://node1.itcast.cn:7077 \
--deploy-mode client \
--driver-memory 512M \
--driver-cores 1 \
--supervise \
--executor-memory 1G \
--executor-cores 1 \
--total-executor-cores 2 \
hdfs://node1:8020/spark/app/py/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output7
cluster模式
spark-submit \
--master spark://node1.itcast.cn:7077 \
--deploy-mode cluster \
--driver-memory 512M \
--driver-cores 1 \
--supervise \
--executor-memory 1G \
--executor-cores 1 \
--total-executor-cores 2 \
hdfs://node1:8020/spark/app/py/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output8
1.5.6.Spark on yarn的实现
目标:掌握spark on yarn的设计
关闭原来的standalone集群
cd /export/server/spark-standalone/
sbin/stop-master.sh
sbin/stop-worker.sh
sbin/stop-history-server.sh
1.5.7.spark on yarn配置测试
目标:实现spark on yarn的配置及测试
搭建:
cd /export/software/
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server
cd /export/server
mv spark-3.1.2-bin-hadoop3.2 spark-yarn
rm -rf /export/server/spark
ln -s /export/server/spark-yarn /export/server/spark
修改配置:spark-env.sh
cd /export/server/spark-yarn/conf
mv spark-env.sh.template spark-env.sh
vim /export/server/spark-yarn/conf/spark-env.sh
## 22行左右设置JAVA安装目录、HADOOP和YARN配置文件目录
export JAVA_HOME=/export/server/jdk
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
export YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 历史日志服务器
SPARK_DAEMON_MEMORY=1g
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1.itcast.cn:8020/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
spark-defaults.conf
cd /export/server/spark-yarn/conf
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
## 添加内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1.itcast.cn:8020/spark/eventLogs
spark.eventLog.compress true
spark.yarn.historyServer.address node1.itcast.cn:18080
spark.yarn.jars hdfs://node1.itcast.cn:8020/spark/jars/*
上传spark jar包
#因为YARN中运行Spark,需要用到Spark的一些类和方法
#如果不上传到HDFS,每次运行YARN都要上传一次,比较慢
#所以自己手动上传一次,以后每次YARN直接读取即可
hdfs dfs -mkdir -p /spark/jars/
hdfs dfs -put /export/server/spark-yarn/jars/* /spark/jars/
修改yarn-site.xml
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
## 添加如下内容
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
yarn.log.server.url
http://node1.itcast.cn:19888/jobhistory/logs
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
分发yarn-site.xml
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml [email protected]:$PWD
scp -r yarn-site.xml [email protected]:$PWD
分发:将第一台机器的spark-yarn分发到第二台和第三台
分发:第一台机器操作
cd /export/server/
scp -r spark-yarn node2:$PWD
scp -r spark-yarn node3:$PWD
修改第二台和第三台软连接
rm -rf /export/server/spark
ln -s /export/server/spark-yarn /export/server/spark
启动:第一台机器
启动Yarn
start-yarn.sh
启动MR的JobHistoryServer:19888
mapred --daemon start historyserver
启动Spark的HistoryServer:18080
start-history-server.sh
官方圆周率计算
spark-submit \
--master yarn \
/export/server/spark-yarn/examples/src/main/python/pi.py \
10
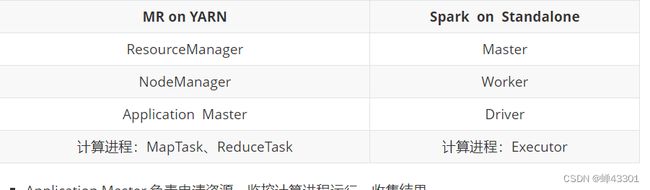
1.5.8.Yarn程序的运行流程
目标:回顾yarn程序的流程
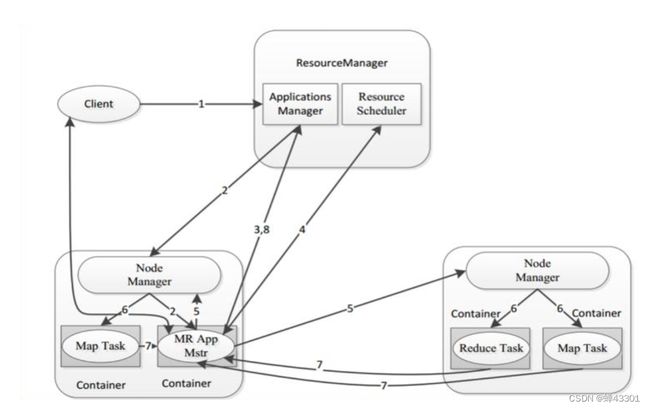
step1:客户端申请提交运行MR程序
step2:ResourceManager验证是否合法,如果合法,随机选择一台NodeManager启动AppMaster
step3:AppMaster根据任务分配向ResourceManager申请Task运行的Container资源
step4:ResourceManager根据资源情况分配对应的Container信息返回给AppMaster
step5:AppMaster根据ResourceManager分配的Container信息,将Container信息分发给对应的NodeManager
step6:NodeManager收到Container信息,启动MapTask和ReduceTask运行
step7:每个Task将自己运行的信息汇报给AppMaster,AppMaster监控每个Task的状态,直到Task结束
step8:AppMaster等到所有Task结束返回运行结果
1.5.9.spark onyarn-面试核心
目标:掌握spark on Yarn的重要面试题
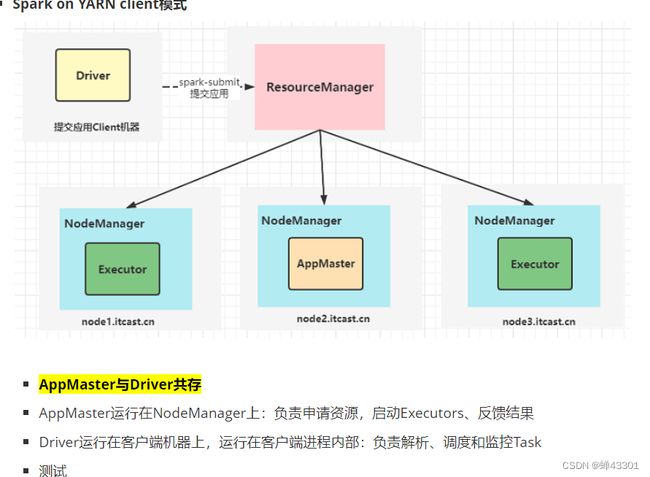
AppMaster与Driver共存
AppMaster运行在NodeManager上:负责申请资源,启动Executor,反馈结果
Driver运行在客户端机器是哪个,运行在客户端进程内部:负责解析,调度和监控task
测试
spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512M \
--driver-cores 1 \
--supervise \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 1 \
hdfs://node1:8020/spark/app/py/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output10
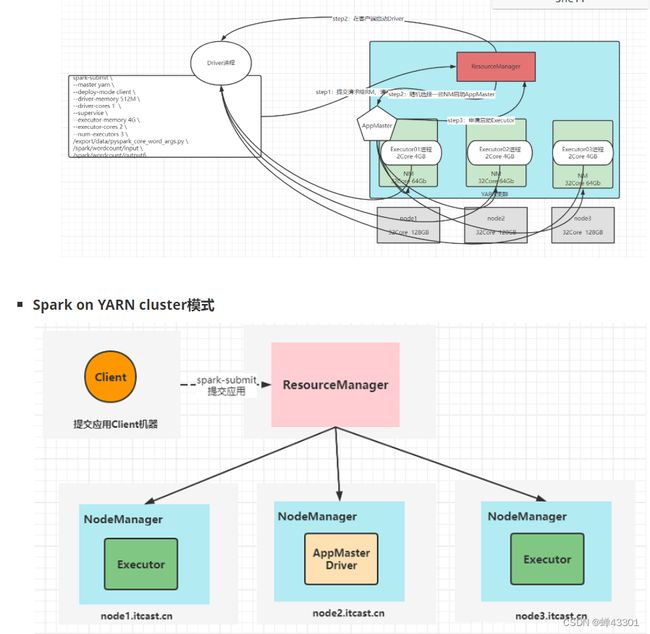
AppMaster和Dirver合并
spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--driver-cores 1 \
--supervise \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 1 \
hdfs://node1:8020/spark/app/py/pyspark_core_word_args.py \
/spark/wordcount/input \
/spark/wordcount/output11
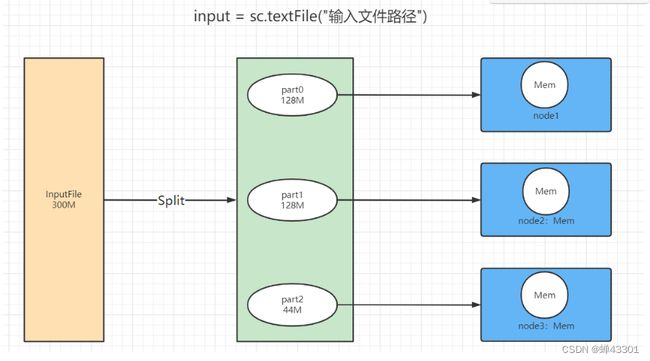
1.5.10.分布式程序开发基本思想
step1:读取数据input
- 代码中,要指定读取数据文件的位置,然后返回一个代表输入数据的变量
- 将要处理的数据拆分成N份,每一份数据放在不同机器上
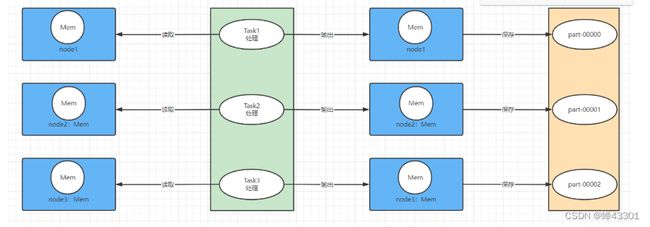
step2:处理数据Transform
- 代码中,定义input的数据变量怎么进行转换,返回一个代表结果数据的变量
- 启动N个计算任务Task,每个计算任务Task根据处理逻辑去处理每一份数据
step3:保存结果Save
- 代码中:将代表结果数据的变量进行输出或者保存到外部系统中
- 启动Task将每台机器的数据进行输出或者写入外部系统
实现
代码示例
# step1:读取数据
input = sc.textFile("输入路径")
# step2:处理数据
result = input.具体的处理逻辑【map、flatMap、filter、reduceByKey等】
# step3:保存结果
result.saveAsTextFile("输出路径")
1.6RDD的算子分类及常用基础算子
1.6.1.RDD的设计及定义
目标:掌握RDD的设计及定义
实现:
step1:SparkCore中所有的数据读取到程序中以后都会存储在一个RDD中
step2:所有的数据转换处理,都直接在代码中对RDD进行处理
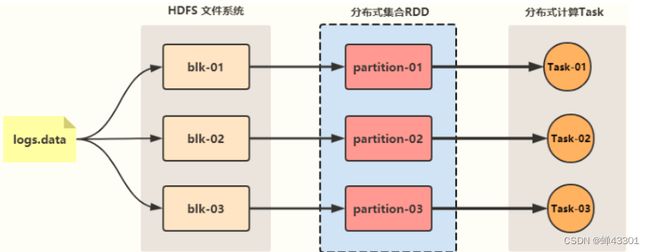
1.6.2.RDD的五大特性
目标掌握RDD的五大特性
特性一:每个RDD都又一系列的分区构成
特性二:RDD的计算操作本质上是对RDD每个分区的计算
特性三:每个RDD都会保存与其他RDD之间的依赖关系:血脉或者学血链
特性四:可选的,如果是二元组[kv]类型rdd,在shuffle过过程中可以自定义分区器
特性五:可选的,spark程序运行时,task的分配可以指定实现最优路径解:最优计算位置
1.6.3.wordcount程序中的rdd
目标:理解wordcount程序中的rdd设计
代码示例:
# step1:读取数据
input_rdd = sc.textFile("hdfs://node1:8020/spark/wordcount/input")
# step2:转换数据
rs_rdd = input_rdd\
.filter(lambda line : len(line.strip()) > 0) \
.flatMap(lambda line : re.split("\\s+",line.strip()))\
.map(lambda word : (word,1))\
.reduceByKey(lambda tmp,item : tmp+item)
# step3:输出结果
rs_rdd.saveAsTextFile("hdfs://node1:8020/spark/wordcount/output")
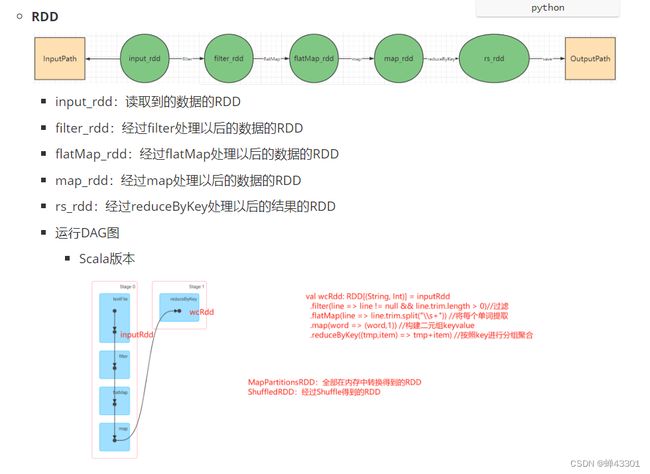
1.6.4.RDD的两种创建方式
方式一:并行化一个已存在的集合
方法:parallelize
功能:将一个集合转换为RDD
测试:
# 创建一个Python的集合,比如列表、字典等
data = [1,2,3,4,5,6,7,8,9,10]
# 将集合转换为RDD
list_rdd = sc.parallelize(data)
# 输出RDD的内容
list_rdd.foreach(lambda member:print(member))
方式二:读取外部共享存储系统
方法:textFile,wholeTextFile,newAPIHadoopRdd等
功能:读取外部存储系统的数据转换为RDD
测试:
# 读取文件数据变为RDD
file_rdd = sc.textFile("../datas/wordcount/word.txt")
# 输出RDD的内容
file_rdd.foreach(lambda line : print(line))
1.6.5.RDD读取小文件处理
目标:了解RDD读取小文件的处理
# 读取数据
file1_rdd = sc.textFile("../datas/ratings100",minPartitions=2)
# 打印分区数
print(f"{file1_rdd.getNumPartitions()}")
每个小文件对应一个人去,每个分区会使用1个Task来处理
每个Task需要1Core CPU来计算,导致浪费大量的CPU处理很小的数据
解决wholeTextFiles
功能:将每个文件作为一条kv存储在rdd中
- k:文件名的绝对路径
- v:文件的内容
场景:用于解决小文件的问题,可以将多个小文件变成多个kv,自由指定分区个数
测试:
# 读取数据
file2_rdd = sc.wholeTextFiles("../datas/ratings100",minPartitions=2)
# 打印分区数
print(f"{file2_rdd.getNumPartitions()}")
# 取出数据:每个文件
file2_rdd.foreach(lambda file : print(file))
print("===========================================")
# 取出每个文件的每一行
line_rdd = file2_rdd.flatMap(lambda content: content[1].split("\n"))
# 输出前5行
for item in line_rdd.take(5):
print(item)
1.6.6高阶函数Lambda表达式
目标:掌握Lambda表达式的使用
现在有一个列表,里面有1-10共10个元素,现在需要提供一个函数,能实现平方和次方等不同的操作
方案一:在函数中定义不同的计算逻辑
# 定义一个列表
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(*list1)
# 定义一个函数
def comp(data, com_type):
# 返回结果的列表
rs = []
# 取出列表中的每个元素
for i in data:
# 如果等于2,就计算每个元素的平方
if com_type == 2:
# 计算当前这个元素的平方
i = i ** 2
# 放入结果列表
rs.append(i)
else:
# 如果不等于2,就计算立方
i = i ** 3
# 将立方的结果放入结果列表
rs.append(i)
# 返回整个结果列表
return rs
高阶函数来实现
# 调用函数
result = comp(list1, 3)
# 输出结果
print(*result)
### 1.4.17
# 定义一个列表
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(*list1)
# 调用高阶函数map(计算逻辑,处理的列表):取出列表中的每个元素按照计算逻辑进行处理
result = map(lambda x: x + 3, list1)
# 输出结果
print(*result)
1.6.7RDD算子分类
目标:掌握RDD算子分类
设计:
- spark为了避免资源浪费,将RDD的读取,转换设计为lazy模式
- 不会触发job,也就不会产生Task,不会构建RDD的数据
- RDD的定义,转换都不是立即执行的
- 需要等待真正使用到对应RDD的数据返回给用户时,才真正的执行所有RDD的构建和转换
- 根据血缘机制一层一层通过Task来构建每个RDD的数据,最终输出结果
实现:
Tranformation算子:转换算子
功能:用于对RDD中的数据进行转换
特点:lazy模式,不会理解执行所以不会触发job的运行,函数返回值固定为RDD类型
常见:map/filter/flatMap/reduceByKey/groupByKey/join等
Action算子:触发算子
功能:用户对RDD的数据进行输出或者保存
特点:会触发job的运行,返回值为非RDD类型
1.6.8常用转换算子filter/map/flatmap
目标:掌握RDD的常用转换算子filter/map/flatmap
1.map算子:
功能:对RDD中每个元素调用一次参数中的函数,并将每次调用的返回值放入一个新的RDD中
分类:转换算子
场景:一对一转换,需要返回值
计算每个元素的立方
实现:
# map算子:一对一转换算子,有返回值
list1 = [1, 2, 3, 4, 5, 6]
input_rdd = sc.parallelize(list1)
input_rdd.foreach(lambda x: print(x))
print("======================")
map_rdd = input_rdd.map(lambda x: x**3) # 计算每个元素的结果,将所有结果放入一个新的RDD
map_rdd.foreach(lambda x: print(x))
2.flatMap算子
功能:将两层嵌套集合中的每个元素取出,扁平化处理,放入一层集合中返回,类似于SQL中explode函数
分类:转换算子
场景:多层集合元素展开,一个集合对应多个元素
语法:
def flatMap(self , f : T -> Iterable[U]) -> RDD[U]
代码示例:
# flatMap算子:类似于explode函数,将两层列表List[List[A]],转换成一层列表List[A]
list2 = ['夜曲/发如雪/东风破/七里香', '十年/爱情转移/你的背包', '日不落/舞娘/倒带', '鼓楼/成都/吉姆餐厅/无法长大', '月亮之上/荷塘月色']
input_rdd = sc.parallelize(list2)
flatmap_rdd = input_rdd.flatMap(lambda line: re.split("/", line))
flatmap_rdd.foreach(lambda x: print(x))
3.filter算子
功能:对RDD集合中的每个元素调用一次参数中的表达式对数据进行过滤,符合条件就保留,不符合就过滤
分类:转换算子
场景:类似sql中where或者having
语法:
def filter(self, f: T -> bool ) -> RDD[T]
实现:
# filter算子:类似于SQL中where操作,给定一个条件,符合就保留
input_rdd = sc.textFile("../datas/function_data/filter.txt")
input_rdd.foreach(lambda line: print(line))
print("=======================")
# 过滤掉字段缺失和性别为-1的
filter_rdd = input_rdd.filter(lambda line: len(re.split("\\s+", line)) == 4 and re.split(" ", line)[2] != '-1')
filter_rdd.foreach(lambda line: print(line))
1.6.9常见触发算子count/foreach/saveTextFile
目标:掌握常用的触发算子
1.count算子
功能:统计RDD集合中元素的个数,返回一个int值
分类:触发算子
场景:统计RDD的数据量,计算行数
语法:
def count(self) -> int
实现:
list1 = ['夜曲/发如雪/东风破/七里香','十年/爱情转移/你的背包','日不落/舞娘/倒带','鼓楼/成都/吉姆餐厅/无法长大','月亮之上/荷塘月色']
inputRdd = sc.parallelize(list1)
print(f"初始RDD的元素个数为: {inputRdd.count()}")
flatMapRdd = inputRdd.flatMap(lambda line : re.split("/",line))
print(f"结果RDD的元素个数为: {flatMapRdd.count()}")
2.foreach算子
功能:对RDD中每个元素调用一次参数中的函数,没有返回值
分类:触发算子
场景:对RDD中的每个元素进行输出或者保存,一般用于测试打印或者保存数据到第三方系统
语法:
def foreach(self , f : T -> None) -> None
实现:
list1 = [1, 2, 3, 4, 5, 6]
inputRdd = sc.parallelize(list1)
inputRdd.foreach(lambda x : print(x**3))
3.saveAsTextFile算子
功能:用于将RDD的数据保存到外部文件系统中
分类:触发算子
场景:保存RDD的计算的结果,一般用于将结果保存到HDFS
文件个数=Task个数=分区个数
语法:
def saveAsTextFile(self , path ) -> None
实现:
list1 = [1, 2, 3, 4, 5, 6]
inputRdd = sc.parallelize(list1)
mapRdd = inputRdd.map(lambda x : x**3)
mapRdd.saveAsTextFile("../datas/output/output1")
1.6.10其他触发算子:first/take/collect/reduce
目标:掌握其他常用触发算子
1.first算子
功能:返回RDD集合中的第一个元素
分类:触发算子
注意:take返回的结果放入Driver内存中的,take数据量不能过大
语法:
def take(self , num:int ) -> List[T]
2.collect算子
功能:将RDD转化成一个列表返回
分类:触发算子
注意:这个RDD的数据一定不能过大,如果RDD数据量很大,导致Driver内存溢出
语法:
def collect(self) -> List[T]
3.reduce算子
功能:将RDD中的每个元素按照给定的聚合函数进行聚合,返回聚合的结果
分类:触发算子
语法:
# tmp用于存储每次计算临时结果,item就是RDD中的每个元素
def reduce(self,f : (T,T) -> T) -> T
示例代码:
list1 = [1,2,3,4,5,6,7,8,9,10]
inputRdd = sc.parallelize(list1)
# first
firstElem = inputRdd.first()
print(f"第一个元素是:{firstElem}")
# take
takeElem = inputRdd.take(5)
print(f"前五个元素是:{takeElem}")
# collect
collectAsList = inputRdd.collect()
print(f"所有元素的内容是:{collectAsList}")
# reduce
reduceRS = inputRdd.reduce(lambda tmp,item : tmp + item)
print(f"累加的结果为:{reduceRS}")
1.6.11RDD常用的分析算子-uninon/distinct
目标:掌握其他转换算子union/distinct
1.union算子
功能:实现两个RDD中数据的合并
分类:转换算子
语法:
def union(self,other:RDD[U]) -> RDD[T/U]
2.distinct算子
功能:实现对RDD数据的去重
分类:转换算子
语法:
def distinct(self) -> RDD[T]
示例代码:
list1 = [1,2,3,4,5,6,7,8]
list2 = [5,6,7,8,9,10]
inputRdd1 = sc.parallelize(list1)
print(inputRdd1.collect())
inputRdd2 = sc.parallelize(list2)
print(inputRdd2.collect())
# union
unionRdd = inputRdd1.union(inputRdd2)
print(unionRdd.collect())
# distinct
distinctRdd = unionRdd.distinct()
print(distinctRdd.collect())
1.6.12分组聚合算子-groupByKey/reduceByKey
目标:掌握分组聚合算子groupByKey/reduceByKey
1.groupByKey算子
功能:对kv类型的RDD按照key进行分组,相同k的value让如一个集合列表中
要求:只有kv类型的rdd才能调用
分类:转换算子
场景:需要对数据进行分组的场景
特点:必须经过shuffle,可以指定新的RDD分区个数,可以指定分区规则
语法:
def groupByKey(self,numpartitions,partitionFunction) -> RDD[Tuple[K,Iterable[V]]]
需求:计算每个单词出现次数
原始数据:
('hue', 1)
('hbase', 1)
('hbase', 1)
('hue', 1)
('hue', 1)
('hadoop', 1)
('spark', 1)
('hive', 1)
('hadoop', 1)
('spark', 1)
('spark', 1)
('hue', 1)
('hbase', 1)
('hbase', 1)
('hue', 1)
('hue', 1)
('hadoop', 1)
('spark', 1)
('hadoop', 1)
('spark', 1)
('hive', 1)
('hadoop', 1)
('spark', 1)
('spark', 1)
('hue', 1)
('hbase', 1)
('hbase', 1)
('hue', 1)
('hue', 1)
('hadoop', 1)
('spark', 1)
('hive', 1)
('hadoop', 1)
('spark', 1)
('spark', 1)
目标结果
spark ------> 1 1 1 1 1 1 1 1 1 1
hbase ------> 1 1 1 1 1 1
hadoop ------> 1 1 1 1 1 1 1
hive ------> 1 1 1
hue ------> 1 1 1 1 1 1 1 1 1
实现:
inputRdd = sc.textFile("../datas/wordcount/word.txt")
# print(f"{inputRdd.first()}")
# 将每个单词,转换成KV格式
wordRdd = inputRdd.filter(lambda line: len(line.strip()) > 0) \
.flatMap(lambda line : line.strip().split(" ")) \
.map(lambda word : (word,1))
# 输出数据
wordRdd.foreach(lambda x : print(x))
# groupByKey分组测试
groupRdd = wordRdd.groupByKey()
groupRdd.foreach(lambda x : print(x[0],"------>",*x[1]))
# 计算个数
rsRdd = groupRdd.map(lambda x:(x[0],sum(x[1])))
rsRdd.foreach(lambda x:print(x))
2.reduceByKey算子
功能:对kv类型的RDD按照key进行分组,并对相同key的所有value进行聚合
要求;只有kv类型的RDD才能调用
分类:转换算子
场景:需要对数据进行分组并且聚合的场景
特点:必须经过shuffle,可以执行新的RDD分区个数,可以指定分区规则
语法:
def reduceByKey(self,f: (T,T) -> T,numPartitions,partitionFunction) -> RDD[Tuple[K,V]]
原始数据:
('hue', 1)
('hbase', 1)
('hbase', 1)
('hue', 1)
('hue', 1)
('hadoop', 1)
('spark', 1)
('hive', 1)
('hadoop', 1)
('spark', 1)
('spark', 1)
('hue', 1)
('hbase', 1)
('hbase', 1)
('hue', 1)
('hue', 1)
('hadoop', 1)
('spark', 1)
('hadoop', 1)
('spark', 1)
('hive', 1)
('hadoop', 1)
('spark', 1)
('spark', 1)
('hue', 1)
('hbase', 1)
('hbase', 1)
('hue', 1)
('hue', 1)
('hadoop', 1)
('spark', 1)
('hive', 1)
('hadoop', 1)
('spark', 1)
('spark', 1)
目标结果:
('spark', 10)
('hbase', 6)
('hadoop', 7)
('hive', 3)
('hue', 9)
实现:
inputRdd = sc.textFile("../datas/wordcount/word.txt")
# 将每个单词,转换成KV格式
wordRdd = inputRdd.filter(lambda line: len(line.strip()) > 0) \
.flatMap(lambda line : line.strip().split(" ")) \
.map(lambda word : (word,1))
# reduceByKey直接分组对Value聚合
rsRdd = wordRdd.reduceByKey(func=lambda tmp,item : tmp+item)
rsRdd.foreach(lambda x:print(x))
1.6.13排序算子-sortBy/sortBy’Key/takeOrdered
目标:掌握排序算子
1.sortBy算子
功能:对RDD中的所有元素进行整体排序,可以指定排序规则
分类:转换算子
场景:适用于所有对数据排序的场景,一般用于对大数据量非kv类型的rdd的数据排序
特点:经过shuffle,可以指定排序后新rdd的分区个数
语法:
def sortBy(self,keyFunc:(T) -> 0, asc, numPartitions) -> RDD
原始数据:
laoda,20,male
laoer,22,female
laoliu,28,middle
laosan,24,male
laosi,30,male
laowu,26,female
目标结果:
laosi,30,male
laoliu,28,middle
laowu,26,female
laosan,24,male
laoer,22,female
laoda,20,male
实现:
import time
inputRdd = sc.textFile("../datas/function_data/sort.txt")
def split_line(line):
arr = line.strip().split(",")
return (arr[0],arr[1],arr[2])
mapRdd = inputRdd.map(lambda line: split_line(line))
sortByRdd = mapRdd.sortBy(keyfunc=lambda x: x[1],ascending=False)
sortByRdd.saveAsTextFile("../datas/output/sort-"+str(time.time()))
2.sortByKey算子
功能:对RDD中的所有元素按照key进行整体排序,可以指定排序规则
要求:只有kv类型的rdd才能调用
分类:转换算子
场景:适用于大数据量的kv类型的rdd按照key排序的场景
特点:经过shuffle,可以指定排序后新rdd的分区个数
语法:
def sortByKey(self, asc, numPartitions) -> RR[Tuple[K,V]]
原始数据:
laoda,20,male
laoer,22,female
laoliu,28,middle
laosan,24,male
laosi,30,male
laowu,26,female
目标结果:
laosi,30,male
laoliu,28,middle
laowu,26,female
laosan,24,male
laoer,22,female
laoda,20,male
实现:
inputRdd = sc.textFile("../datas/function_data/sort.txt")
def split_line(line):
arr = line.strip().split(",")
return (arr[0],arr[1],arr[2])
mapRdd = inputRdd.map(lambda line: split_line(line))
sortByKeyRdd = (mapRdd
.map(lambda x: (x[1], (x[0], x[2])))
.sortByKey(ascending=False)
)
sortByKeyRdd.saveAsTextFile("../datas/output/sort-"+str(time.time()))
3.top算子
功能:对RDD中的所有元素降序排序,并返回前N个元素,即返回RDD中最大的前N个元数据
分类:触发算子
场景:去RDD数据中的最大TopN个元素
特点:不经过Shuffle,将所有元素放入Driver内存中排序,只能适合处理小数据量
语法:
def top(self,num) -> List[0]
实现:
print("=============")
take_ordered_list = numRdd.takeOrdered(5)
print(*take_ordered_list)
1.6.14重分区算子-repartiton/coalesce
目标:掌握重分区算子
1.repartiton算子
功能:调整rdd的分区个数
分类:转换算子
场景:一般用于调大分区个数
特点:必须经过shuffle过程
语法:
def repartition(self,numPartitions) -> RDD[T]
2.coalesce算子
功能:调整rdd的分区个数
分类:转换算子
场景:一般用于降低分区个数
特点:可以选择是否经过shuffle
语法:
def coalesce(self, numPartitions, shuffle) -> RDD[T]
示例代码:
numRdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
print(f"numRdd的分区个数是:{numRdd.getNumPartitions()}")
numRdd.foreach(lambda x:print(x))
upRdd = numRdd.repartition(4)
print(f"upRdd的分区个数是:{upRdd.getNumPartitions()}")
upRdd.foreach(lambda x: print(x))
downRdd = upRdd.coalesce(1)
print(f"downRdd的分区个数是:{downRdd.getNumPartitions()}")
downRdd.foreach(lambda x: print(x))
1.6.15RDD的算子使用案例
目标:理解网站分析案例的需求
指标讲解:
pv:页面访问量
uv:唯一用户数
1.6.16网站分析案例-数据加载
需求:
step1:读取数据编程rdd
step2:对字段个数不合法的数据进行过滤
step3:将每条数据的每一列拆分出来,并且构建日期字段
实现:
# step1: 读取数据
inputRdd = sc.textFile("../datas/function_data/tianchi_user.csv")
print({inputRdd.first()})
# ETL:过滤不完整数据,将每条数据转换成元组
def to_list(line):
arr = line.strip().split(",")
return (arr[0],arr[1],arr[2],arr[3],arr[4],arr[5],arr[5][0:10])
etlRdd = (inputRdd
.filter(lambda line: len(line.strip().split(",")) == 6)
.map(lambda line : to_list(line))
)
print(etlRdd.first())
1.6.17pv统计
目标:实现网站分析的pv统计
需求:
step1:构建kv,每条数据作为1个pv,以日期作为k,v恒为1
step2:按照key进行分组聚合
step3:按照key进行升序排序
实现:
step2: 计算PV
pvRdd = (etlRdd
.map(lambda line: (line[6],1))
.reduceByKey(lambda tmp,item: tmp+item)
.coalesce(1)
.sortByKey()
)
pvRdd.foreach(lambda x: print(x))
1.6.18uv统计
目标:实现网站分析案例的uv统计
需求
step1:将日期和用户id过滤出来
step2:按照日期对用户id去重
step3:统计每天每个用户id个数
step4:按照个数降序排序
实现:
step3: 计算UV
uvRdd = (etlRdd
.map(lambda line: (line[6],line[0]))
.distinct()
.map(lambda tuple: (tuple[0],1))
.reduceByKey(lambda tmp,item: tmp+item)
.coalesce(1)
.sortBy(keyfunc=lambda tuple: tuple[1],ascending=False)
)
uvRdd.foreach(lambda x: print(x))
1.7RDD其他算子
1.7.1reduce算子的实现原理
目标:掌握reduce算子的实现原理
reduce是rdd的一个触发算子,功能是实现rdd中元素聚合操作
def reduce(self, f : (T,T) -> T) -> T
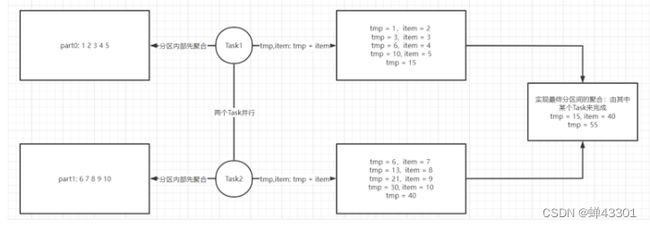
- 这种思想等同于MR中Combiner的思想,先并行实现每个分区内部的计算,最后只要将每个分区的结果进行计算即可
- 这种算子在spark中称为:带有map端聚合算子
面试题:groupByKey+map和reduceByKey都能实现分布式分组聚合,性能层面有什么区别?
- 能用reduceByKey就不用groupByKey
- reduceByKey的性能要高于groupByKey
- reduceByKey是带有Map聚合的算子,现在每个分区内部分组聚合,然后最后将所有分区的结果再分组聚合
- groupByKey经过shuffle将所有数据放在一起以后再重新分组
实现:
# step1 : 读取数据
inputRdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], numSlices=2)
# inputRdd.foreach(lambda x : print(f'part{TaskContext().partitionId()} x={x}'))
# step2 : 处理数据
def computeSum(tmp,item):
print(f'part={TaskContext().partitionId()},tmp={tmp},item={item}')
return tmp+item
reduceRs = inputRdd.reduce(lambda tmp, item: computeSum(tmp, item))
# step3 : 保存结果
print(reduceRs)
# 分区内先聚合
part=1,tmp=6,item=7
part=1,tmp=13,item=8
part=1,tmp=21,item=9
part=1,tmp=30,item=10
tmp=40
# 分区内先聚合
part=0,tmp=1,item=2
part=0,tmp=3,item=3
part=0,tmp=6,item=4
part=0,tmp=10,item=5
tmp=15
# 分区间先聚合
part=None,tmp=15,item=40
#输出结果
55
1.7.2其他聚合算子
掌握其他聚合算子的使用及区别
1.fold算子
功能:将RDD中的每个元素按照给定的聚合函数进行聚合,返回聚合的结果
分类:触发算子,转换算子叫做foldByKey
特点:有初始值,每个分区在计算时都会计算上初始值,分区间计算时也会计算1次初始值,初始值一共被聚合N+1次,N代表分区数
语法:zeroValue就是tmp第一次的值
def fold(self, zeroValue: T, f:(T,T) -> T) -> T
示例:
foldRs = inputRdd.fold(1,computeSum)
结果:
# 分区内聚合
part=1,tmp=1,item=6
part=1,tmp=7,item=7
part=1,tmp=14,item=8
part=1,tmp=22,item=9
part=1,tmp=31,item=10
tmp = 41
# 分区内聚合
part=0,tmp=1,item=1
part=0,tmp=2,item=2
part=0,tmp=4,item=3
part=0,tmp=7,item=4
part=0,tmp=11,item=5
tmp = 16
# # 分区间聚合
part=None,tmp=1,item=16
part=None,tmp=17,item=41
58
2.aggregate算子
功能:将RDD中的每个元素进行聚合,返回聚合的结果
分类:触发算子,转换算子叫做aggregateByKey
特点:有初始值,并且可以单独指定分区内聚合逻辑和分区间聚合逻辑
语法:
def aggregate(self, zeroValue: T, f1:(T,T) -> T, f2:(T,T) -> T) -> T
f1:每个分区内部怎么计算
f2:分区间怎么计算
区别:
reduce:不支持初始值,分区内聚合逻辑与分区间聚合逻辑一致
fold:支持初始值,分区内聚合逻辑与分区间聚合逻辑一致
aggregate:支持初始值,分区内聚合逻辑与分区间聚合逻辑可以不一致
1.7.3其他kv类型算子
目标:掌握其他kv类型算子的使用
1.keys:
功能:针对二元组kv类型的rdd,返回rdd中所有的key,放入一个新的rdd中
分类:转换算子
语法:
def keys( self: RDD[Tuple[K,V]] ) -> RDD[K]
示例:
rdd_kv = sc.parallelize([('laoda',11),('laoer',22),('laosan',33),('laosi',44)], numSlices=2)
rdd_keys = rdd_kv.keys()
rdd_keys.foreach(lambda x: print(x))
2.values
功能:针对二元组KV类型的RDD,返回RDD中所有的Value,放入一个新的RDD中
分类:转换算子
语法:
def values( self: RDD[Tuple[K,V]] ) -> RDD[V]
示例:
rdd_values = rdd_kv.values()
rdd_values.foreach(lambda x: print(x))
3.mapvalues
功能:针对二元组KV类型的RDD,对RDD中每个元素的Value进行map处理,结果放入一个新的RDD中
分类:转换算子
语法:
def mapValues(self: RDD[Tuple[K,V]], f: (V) -> U) -> RDD[Tuple[K,U]]
示例:
rdd_kv_map_values = rdd_kv.mapValues(lambda x: x ** 2)
rdd_kv_map_values.foreach(lambda x: print(x))
4.collectAsMap
功能:将二元组类型的RDD转换成一个Map字典
分类:触发算子
特点:类似于collect,将RDD中元素的结果放入Driver内存中的一个字典中,数据量必须比较小
语法:
def collectAsMap(self: RDD[Tuple[K,V]]) -> Dict[K,V]
示例:
rdd_kv_collect_as_map = rdd_kv.collectAsMap()
print(rdd_kv_collect_as_map)
1.7.4join关联算子
目标:掌握join关联算子的使用
算子**:join / fullOuterJoin / leftOuterJoin / rightOuterJoin
功能:实现两个KV类型的RDD之间按照K实现关联,将两个RDD的关联结果放入一个新的RDD中
语法:
def join(self: RDD[Tuple[K,V]], otherRdd: RDD[Tuple[K,W]]) -> RDD[Tuple[K,(V,W)]]
示例:
rdd_singer_age = sc.parallelize([("周杰伦", 43), ("陈奕迅", 47), ("蔡依林", 41), ("林子祥", 74), ("陈升", 63)], numSlices= 2)
rdd_singer_music = sc.parallelize([("周杰伦", "青花瓷"), ("陈奕迅", "孤勇者"), ("蔡依林", "日不落"), ("林子祥", "男儿当自强"), ("动力火车", "当")], numSlices=2)
rdd_join = rdd_singer_age.join(rdd_singer_music)
rdd_join.foreach(lambda x: print(x))
print("=====================================================")
rdd_full_join = rdd_singer_age.fullOuterJoin(rdd_singer_music)
rdd_full_join.foreach(lambda x: print(x))
print("=====================================================")
rdd_left_join = rdd_singer_age.leftOuterJoin(rdd_singer_music)
rdd_left_join.foreach(lambda x: print(x))
print("=====================================================")
rdd_right_join = rdd_singer_age.rightOuterJoin(rdd_singer_music)
rdd_right_join.foreach(lambda x: print(x))
1.7.5分区处理算子
目标:掌握分区处理算子使用
代码示例:
# 构建RDD
input_rdd = sc.parallelize((1, 2, 3, 4, 5, 6, 7, 8, 9, 10), numSlices=2)
# 使用map进行转换:对每个元素进行处理
map_rdd = input_rdd.map(lambda x: x*2)
# 定义方法,用于将数据写入MySQL
def saveToMySQL(x):
# 构建一个MySQL连接,获取一个游标,执行SQL语句
print(x)
# 将RDD中每个元素写入MySQL
map_rdd.foreach(lambda x: saveToMySQL(x))
1.mapPartitions
功能:对RDD每个分区的数据进行操作,将每个分区的数据进行map转换,将转换的结果放入新的RDD中
分类:转换算子
语法:
def mapPartitions(self: RDD[T], f: Iterable[T] -> Iterable[U] ) -> RDD[U]
对比map:map对每个元素进行操作
def map(self: RDD[T], f: T -> U ) -> RDD[U]
2.foreachPartition
功能:对RDD每个分区的数据进行操作,将整个分区的数据加载到内存进行foreach处理,没有返回值
分类:触发算子
语法:
def foreachParition(self: RDD[T] , f: Iterable[T] -> None) -> None
对比foreach:对每个元素进行操作
def foreach(self: RDD[T] , f: T -> None) -> None
代码示例:
# 使用mapPartitions:对每个分区进行处理
def map_partition(part):
rs = [i * 2 for i in part]
return rs
# 每个分区会调用一次:将这个分区的数据放入内存,性能比map更好,优化型算子,注意更容易出现内存溢出
map_part_rdd = input_rdd.mapPartitions(lambda part: map_partition(part))
# 使用foreachPartiion:对每个分区进行处理写入MySQL
def save_part_to_mysql(part):
# 构建MySQL连接
for i in part:
# 利用MySQL连接将结果写入MySQL
print(i)
# 将每个分区的数据直接写入MySQL,一个分区就构建一个连接
map_part_rdd.foreachPartition(lambda part: save_part_to_mysql(part))
1.7.6搜狗日志分析案例
目标:实现搜狗日志案例的需求分析
分析需求一::统计热门搜索
sql实现:
select
word,
count(1) as cnt
from table
group by word
order by cnt desc
limit 10
需求二:统计所有用户搜索中最大搜索次数,最小搜索次数,平均搜索次数
sql实现:
-- 计算每个用户对每个搜索词的搜索次数
-- 从搜索次数中取最大值,最小值,平均值
with tmp as (
select
userid,
word,
count(1) as cnt
from table
group by userid,word
)
select
max(cnt),
min(cnt),
avg(cnt)
from tmp;
需求三:统计一天每小时搜索量并按照搜索量降序排序
sql实现:
select
substr(time,1,2) as hour,
count(1) as cnt
from table
group by substr(time,1,2)
order by cnt desc
1.7.7jieba中文分词器
目标:实现jieba中文分词器的使用
安装:
conda activate base
安装jieba分词器
pip install jieba
全模式:将句子中所有可以组成词的词语都扫描出来,速度非常快,但可能会出现歧义
jieba.cut(“语句”,cut_all=True)
精确模式:将句子最精明地按照语义切开,适合文本分析,提取语义中存才的每个词
jieba.cut(“语句”, cut_all=False)
搜索引擎模式:在精确模式的基础上,对长词再次切开,适合用于搜索引擎粉刺
jieba.cut_for_search(“语句”)
测试:
import jieba
if __name__ == '__main__':
"""
Jieba中文分词使用
"""
# 定义一个字符串
line = '我来到北京清华大学'
# TODO:全模式分词
seg_list = jieba.cut(line, cut_all=True)
print(",".join(seg_list))
# TODO: 精确模式
seg_list_2 = jieba.cut(line, cut_all=False)
print(",".join(seg_list_2))
# TODO: 搜索引擎模式
seg_list_3 = jieba.cut_for_search(line)
print(",".join(seg_list_3))
1.7.8数据加载清洗
目标实现搜狗案例数据加载清洗
数据示例:
00:00:04 6943214457930995 [秦始皇陵墓] 1 16 www.vekee.com/b51126/
00:00:04 0554004435565833 [青海湖水怪] 3 2 www.mifang.org/do/bs/p55.html
00:00:04 9975666857142764 [电脑创业] 3 3 yahoo.com/question/140704190210.html
读取数据:
# step1: 读取数据
input_rdd = sc.textFile("/spark/sogou")
print(f"{input_rdd.first()}")
print(f"{input_rdd.count()}")
清洗数据:
etl_rdd = ( input_rdd
# 先分割出来,将一个字符串分割为一个列表
.map(lambda line: re.split("\\s+", line))
# 过滤,元素个数不为6的不要
.filter(lambda item: len(item) == 6)
# 将列表转换为元素,并且去掉中括号
.map(lambda item: (item[0], item[1], str(item[2])[1:-1], int(item[3]), int(item[4]), item[5], ))
)
print(etl_rdd.take(5))
print(etl_rdd.count())
1.7.9搜索关键词TopN统计
目标:实现搜索关键词TopN的统计
统计搜索词出现的次数,按照次数降序排序,取次数最多前10个搜索词
代码示例:
# b.需求一:统计每个搜索词出现的次数,求搜索词出现次数最多的前10个
rs1 = ( etl_rdd
# 先用分词器进行分词,一行中的多个词编程一行一个词
.flatMap(lambda tuple: jieba.cut(tuple[2], cut_all=False))
# 构建每个词就出现1次
.map(lambda word: (word, 1))
# 按照每个词进行分组聚合
.reduceByKey(lambda tmp,item: tmp+item)
# 按照出现的次数进行降序排序
.sortBy(lambda tuple: tuple[1], ascending=False)
# 取前10名
.take(10)
)
print(*rs1)
1.7.10用户搜索点击统计
目标:实现用户搜索点击统计
需求:统计所有搜索中,用户在搜索时,最多,最少,平均搜索次数
代码示例:
# c.需求二:统计分析用户搜索的最多,最少,平均次数
rs2 = ( etl_rdd
# 每个用户每个搜索构建一个二元组,表示这个用户对这个搜索词搜索了一次((用户id,搜索词),1)
.map(lambda item: ((item[1], item[2]), 1))
# 按照用户和搜索词进行分组聚合,每个用户搜索每个搜索词一共搜了多少次((用户id,搜索词),搜索次数)
.reduceByKey(lambda tmp,item: tmp+item)
# 获取所有用户搜索所有词的次数
.values()
)
print(f"最大次数={rs2.max()}")
print(f"最小次数={rs2.min()}")
print(f"平均次数={rs2.mean()}")
1.7.11搜索时间段TopN统计
目标:实现搜索时间段TopN统计
需求:统计每个小时的搜索量,按照搜索量降序排序
代码:
# d.统计每个小时的搜索量,按照搜索量降序排序
rs3 = ( etl_rdd
# 每一条数据中都有小时,就表示这个小时出现了一条搜索,就计算1
.map(lambda item: (item[0][0:2], 1))
# 按照小时分组,统计每个小时的搜索量
.reduceByKey(lambda tmp,item: tmp+item)
# 降低分区,结果最多只有24条
.coalesce(1)
# 将KV位置互换,可以用top对搜索量先排序
.map(lambda tuple: (tuple[1], tuple[0]))
# 排序:按照搜索量降序排序
.top(24)
)
完整代码示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
import re
import jieba
"""
-------------------------------------------------
Description : TODO:
SourceFile : 01.pyspark_core_sogou_case
Author : Frank
Date : 2022/5/26
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['HADOOP_USER_NAME'] = 'root'
os.environ['YARN_CONF_DIR'] = '/export/server/hadoop/etc/hadoop'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("yarn")\
.setAppName("Remote Test APP")\
.set("spark.yarn.jars","hdfs://node1.itcast.cn:8020/spark/jars/*")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
input_rdd = sc.textFile("/spark/sogou")
# print(input_rdd.first())
# print(input_rdd.count())
# step2: 处理数据
# a.数据清洗:字段合法性判断,一行解析为一个六元组,去掉搜索词两边的中括号
etl_rdd = ( input_rdd
# 先分割出来,将一个字符串分割为一个列表
.map(lambda line: re.split("\\s+", line))
# 过滤,元素个数不为6的不要
.filter(lambda item: len(item) == 6)
# 将列表转换为元素,并且去掉中括号:0-时间,1-用户id,2-搜索词
.map(lambda item: (item[0], item[1], str(item[2])[1:-1], int(item[3]), int(item[4]), item[5], ))
)
# print(etl_rdd.take(5))
# print(etl_rdd.count())
# b.需求一:统计每个搜索词出现的次数,求搜索词出现次数最多的前10个
# rs1 = ( etl_rdd
# # 先用分词器进行分词,一行中的多个词编程一行一个词
# .flatMap(lambda tuple: jieba.cut(tuple[2], cut_all=False))
# # 构建每个词就出现1次
# .map(lambda word: (word, 1))
# # 按照每个词进行分组聚合
# .reduceByKey(lambda tmp,item: tmp+item)
# # 按照出现的次数进行降序排序
# .sortBy(lambda tuple: tuple[1], ascending=False)
# # 取前10名
# .take(10)
# )
# print(*rs1)
# c.需求二:统计分析用户搜索的最多,最少,平均次数
rs2 = ( etl_rdd
# 每个用户每个搜索构建一个二元组,表示这个用户对这个搜索词搜索了一次((用户id,搜索词),1)
.map(lambda item: ((item[1], item[2]), 1))
# 按照用户和搜索词进行分组聚合,每个用户搜索每个搜索词一共搜了多少次((用户id,搜索词),搜索次数)
.reduceByKey(lambda tmp,item: tmp+item)
# 获取所有用户搜索所有词的次数
.values()
)
# print(f"最大次数={rs2.max()}")
# print(f"最小次数={rs2.min()}")
# print(f"平均次数={rs2.mean()}")
# d.统计每个小时的搜索量,按照搜索量降序排序
rs3 = ( etl_rdd
# 每一条数据中都有小时,就表示这个小时出现了一条搜索,就计算1
.map(lambda item: (item[0][0:2], 1))
# 按照小时分组,统计每个小时的搜索量
.reduceByKey(lambda tmp,item: tmp+item)
# 降低分区,结果最多只有24条
.coalesce(1)
# 将KV位置互换,可以用top对搜索量先排序
.map(lambda tuple: (tuple[1], tuple[0]))
# 排序:按照搜索量降序排序
.top(24)
)
print(*rs3)
# step3: 保存结果
# todo:3-关闭SparkContext
sc.stop()
1.8Spark容错机制
1.8.1数据容错方案
目标:掌握常见的数据容错方案
问题一:计算机在存储数据的过程中如何保证数据的安全?
磁盘:副本机制
软副本:一个数据冗余存储多份,类似于HDFS
硬副本:硬盘构建备份,磁盘冗余阵列RAID1
内存-操作日志
hdfs:edits
mysql:binlog
hbase:wal
问题二:Spark中RDD的数据如何保证数据的安全?
现有Task,还是先有RDD的数据,现有Task,Task在运行过程中构建RDD的数据
RDD的数据就构建在内存中
Lineage血缘机制
rdd第三特性:每个Rdd都会保留自己的血缘关系
每个rdd在构建数据时,会根据自己来源一步步倒推到数据来源,然后再一步步开始构建RDD数据
例如:
# step1: 构建RDD
rdd_test = sc.textFile("HDFS上的文件")
rs_rdd = rdd_test
.filter # 过滤操作得到一个filter_rdd
.flatmap # 降维操作得到一个flatMap_rdd
.map # 转换操作得到一个map_rdd
#.reduceByKey # 聚合操作得到rs_rdd
# step2: 调用RDD
rs_rdd.foreach(lambda x: print(x)) # 触发job,构建Task1 - 2 ,Task结束,Task占用的内存被释放
rs_rdd.first # 触发job,构建Task3 - 4 ,Task结束,Task占用的内存被释放
rs_rdd.count # 触发job,构建Task5 - 6 ,Task结束,Task占用的内存被释放
当rdd的数据被触发调用时,就会根据RDD的血缘关系层层构建RDD的数据
如果在计算过程中,RDD的数据丢失,就会通过依赖关系重新构建,彻底保证了RDD的数据安全.
1.8.2RDD容错机制:persist
目标:掌握RDD的容错机制持久化
1.cache算子
功能:将RDD缓存在内存中
语法:cache(0
本质:底层调用的还是persist,但是只缓存在内存,如果内存不够,缓存会失败
场景:资源充足,需要将RDD缓存在内存中
2.persist
功能:将RDD进行缓存,可以自己指定缓存的级别
语法:persist
级别:StorageLevel决定了缓存位置和缓存几份
代码示例:
# 缓存在磁盘中
StorageLevel.DISK_ONLY = StorageLevel(True, False, False, False)
StorageLevel.DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
StorageLevel.DISK_ONLY_3 = StorageLevel(True, False, False, False, 3)
# 缓存在内存中
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False)
StorageLevel.MEMORY_ONLY_2 = StorageLevel(False, True, False, False, 2)
# 缓存在内存中,如果内存不足就写入磁盘
StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False)
StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2)
# 缓存在堆外内存中
StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1)
# 缓存在内存中,如果内存不足就写入磁盘并且不经过序列化
StorageLevel.MEMORY_AND_DISK_DESER = StorageLevel(True, True, False, True)
推荐:实际工作中一般推荐使用以下两种
StorageLevel.MEMORY_AND_DISK
StorageLevel.MEMORY_AND_DISK_2
3.unpersist
功能:将缓存的RDD进行释放
语法:unpersist,等释放完再继续下一步
场景:明确RDD已经不再使用,将Rdd的数据从缓存中释放,避免占用资源
注意:如果不释放,这个spark程序结束,也会释放这个程序中的所有内存
测试:
没有缓存:每次需要重新构建
配置缓存:
# 由于这个rs_rdd会被调用多次,将rs_rdd进行缓存
# cache方法:直接调用即可
# rs_rdd.cache()
# persist方法:允许指定缓存的位置和副本数
rs_rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 打印结果
rs_rdd.foreach(lambda x: print(x))
# 结果保存到文件中:路径不能提前存在
rs_rdd.saveAsTextFile("../datas/output/wcoutput1")
# unpersist:如果某一个缓存过的RDD明确不再被使用,一定要进行释放缓存,避免一直占用资源,除非这个程序马上就结束
rs_rdd.unpersist(blocking=True)
场景:高性能
适合:RDD需要多次使用,或者RDD是经过非常复杂的转换过程所构建
不适合:RDD只使用1次而且构建比较简单
1.8.3RDD容错机制:checkpoint
目标:掌握RDD的容错机制checkpoint
checkpoint:检查点
功能:将RDD的数据存储在HDFS上
语法:
# 设置一个检查点目录
sc.setCheckpointDir("../datas/chk/chk1")
# 将RDD的数据持久化存储在HDFS
rs_rdd.checkpoint()

1.8.4spark共享变量-数据共享
目标:理解数据共享问题
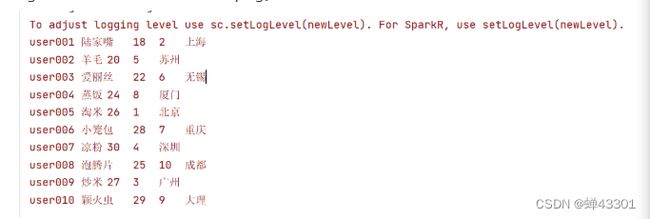
数据:users.tsv
user001 陆家嘴 18 2
user002 羊毛 20 5
user003 爱丽丝 22 6
user004 蒸饭 24 8
user005 淘米 26 1
user006 小笼包 28 7
user007 凉粉 30 4
user008 泡腾片 25 10
user009 炒米 27 3
user010 颖火虫 29 9
city:城市信息数据
city_dict = {
1: "北京",
2: "上海",
3: "广州",
4: "深圳",
5: "苏州",
6: "无锡",
7: "重庆",
8: "厦门",
9: "大理",
10: "成都"
}
需求:对上述两个文件进行处理,最后得到结果如下
用户id 用户名 年龄 城市id 城市名称
代码示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
import re
"""
-------------------------------------------------
Description : TODO:
SourceFile : 03.pyspark_core_share_var_broadcast
Author : Frank
Date : 2022/5/26
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("App Name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# 定义一个字典
city_dict = {
1: "北京",
2: "上海",
3: "广州",
4: "深圳",
5: "苏州",
6: "无锡",
7: "重庆",
8: "厦门",
9: "大理",
10: "成都"
}
# 读取用户数据
user_rdd = sc.textFile("../datas/broadcast/users.tsv", minPartitions=2)
# step2: 处理数据
# 关联城市名称的方法
def join_city(line):
# 从数据中获取城市id
city_id = re.split("\\s+", line)[3]
# 根据城市id从字典中获取城市名称
city_name = city_dict.get(int(city_id))
# 拼接返回城市名称
return line + "\t" + city_name
# 一对一转换,将每条数据中增加城市名称
rs_rdd = user_rdd.map(lambda line: join_city(line))
# step3: 保存结果
rs_rdd.foreach(lambda x: print(x))
# todo:3-关闭SparkContext
sc.stop()
1.8.5Broadcast Variables广播变量
目标:掌握Spark中广播变量的概念及使用
官网:https://spark.apache.org/docs/latest/rdd-programming-guide.html#broadcast-variables
功能:将一个变量元素进行广播到每台Worker节点的Executor中,让每个Task直接从本地读取数据,减少网络传输IO

step1:将一个变量定义成为一个广播变量
step2:当需要用到这个变量时,就从广播变量中获取它的值
step3:释放广播变量
broadcast_city_dict.unpersist()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
import re
"""
-------------------------------------------------
Description : TODO:
SourceFile : 03.pyspark_core_share_var_broadcast
Author : Frank
Date : 2022/5/26
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("App Name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# 定义一个字典:在Driver内存中
city_dict = {
1: "北京",
2: "上海",
3: "广州",
4: "深圳",
5: "苏州",
6: "无锡",
7: "重庆",
8: "厦门",
9: "大理",
10: "成都"
}
# 将这个字典进行广播,广播给所有节点一份
broadcast_city_dict = sc.broadcast(city_dict)
# 读取用户数据
user_rdd = sc.textFile("../datas/broadcast/users.tsv", minPartitions=2)
# step2: 处理数据
# 关联城市名称的方法
def join_city(line):
# 从数据中获取城市id
city_id = re.split("\\s+", line)[3]
# 根据城市id从字典中获取城市名称:从广播变量中获取这个字典
city_name = broadcast_city_dict.value.get(int(city_id))
# 拼接返回城市名称
return line + "\t" + city_name
# 一对一转换,将每条数据中增加城市名称:10个分区 = 10个Task = 每个Task获取这字典 = Task运行在Executor中,但是字典在Driver中
rs_rdd = user_rdd.map(lambda line: join_city(line))
# step3: 保存结果
rs_rdd.foreach(lambda x: print(x))
# todo:3-关闭SparkContext
sc.stop()

场景:
a:广播一个比较大的数据,减少每次从Driver复制的数据量,降低网络IO损耗,提高性能
b:两张表进行join时,将小表进行广播,与大表的每个部分进行join,实现Broadcast,避免Shuffle join
特点:广播变量是一个制度变量,不能修改
1.8.6分布式计算问题
目标:理解分布式计算的问题
需求:对搜狗日志的数据进行处理,统计10点搜索的数据一共多少条
代码示例:
input_rdd = sc.textFile("../datas/sogou/sogou.tsv")
# 定义一个计数变量
sum = 0
# 计算总个数
def accumulator(line):
# 申明全局变量
global sum
# 获取小时
hour = re.split("\\s+", line)[0][0:2]
# 判断是否等于10点
if "10".__eq__(hour):
sum = sum + 1
#print(sum)
return None
input_rdd.foreach(lambda line: accumulator(line))
# 输出结果
print(sum)

为甚命名按照计算规则累加了,但是在调用结果时,值没有发生改变?
每个Task到Driver中取了sum的副本,进行累加,但是这个累加的结果并没有返回Driver中
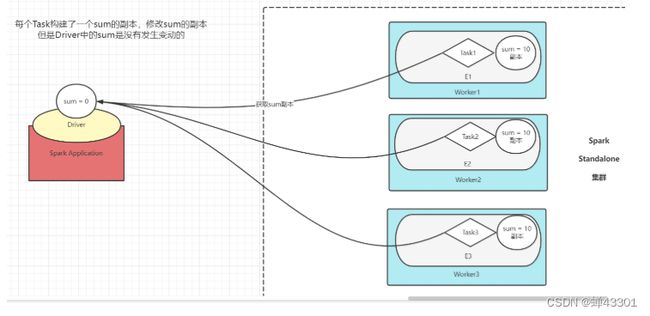
1.8.7Accumulators累加器
目标:掌握Spark中Accumulators累加器的使用
官网:https://spark.apache.org/docs/latest/rdd-programming-guide.html#accumulators
功能:实现分布式的计算,在每个Task内部构建一个副本进行累加,并且返回每个Task的结果最后进行合并
step1:定义一个累加器
step2:在需要进行累加的地方进行累加即可
解决:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
import re
"""
-------------------------------------------------
Description : TODO:
SourceFile : 04.pyspark_core_share_var_acc
Author : Frank
Date : 2022/5/26
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("App Name")
sc = SparkContext(conf=conf)
# todo:2-数据处理:读取、转换、保存
input_rdd = sc.textFile("../datas/sogou/sogou.tsv")
# 定义一个全局计数变量
sum = 0
# 定义一个累加器:告诉所有人,你们用到我的时候,最终需要返回
sc_accumulator = sc.accumulator(0)
# 计算总个数
def accumulator(line):
# 申明全局变量
global sum
# 获取小时
hour = re.split("\\s+", line)[0][0:2]
# 判断是否等于10点
if "10".__eq__(hour):
# sum = sum + 1
# 通过累加器实现累加
sc_accumulator.add(1)
# print(sum)
return None
# 调用foreach,对每条数据进行处理判断
input_rdd.foreach(lambda line: accumulator(line))
# 输出结果
# print(sum)
# 输出累加器结果
print(sc_accumulator.value)
# todo:3-关闭SparkContext
sc.stop()
场景:
a:实现分布式的累加计数
b:实现分区内部的计算并且返回结果
1.8.8Spark内核调度
目标:理解Spark应用提交流程
实施:
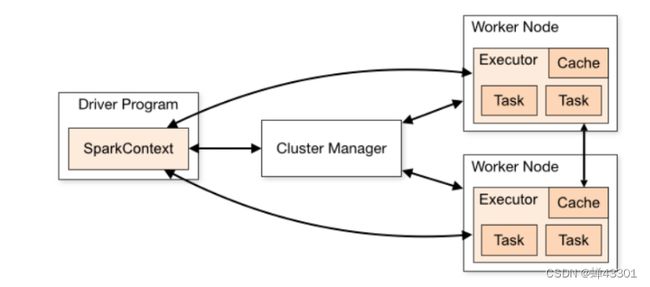
Cluster Manager:分布式资源管理的主节点
- Yarn:ResourceManager
- Standalone:Master
- 负责管理所有从节点
- 负责接收客户端请求
- 负责资源管理和任务调度
Worker:分布式资源管理的从节点
- Yarn:NodeManager
- Standalone:Worker
- 负责运行利用所在节点的资源运行每个程序的Executor进程
Application:Spark的应用程序
- 由用户所开发的Spark代码就作为一个Spark程序
- 每个Spark程序在运行时都包含一个Driver进程和多个Executor进程
Driver:Spark程序的驱动进程
- 每个Spark程序都包含一个Driver进程
- Driver运行以后HIIT解析代码通过SparkContext来实现Driver功能
- 负责向ClusterManager主节点申请启动Executor
- 负责解析代码构建Task
- 负责调度,分配以及监控Task的运行
Executor:Spark程序的执行过程
- 每个Spark程序都包含一个或者多个Executor进程
- 由Driver向ClusterManager申请启动,ClusterManager会根据资源情况将Executor分配运行在Worker节点上
- 每个Spark应用程序都拥有数据自己的Executor,不同程序的Executor并不共享
- Executor用于运行Task计算任务,并且将计算数据存储在内存或者磁盘中
JOb
- job是执行分布式并行Task的最小单元,一个job触发多个Task的运行,一个Spark Application中可以有多个job
- job由触发函数触发,当代码中遇到触发函数,就会触发job,构建job需要的Task
- Driver解析代码,遇到触发函数,就触发job的产生,job产生以后,构建Task实现job
Stage
- 每个job的执行会划分成多个Stage阶段,类似于将一个job中的流程划分成多个Map过程、Reduce过程
- job构建以后,会通过回溯算法【倒推】构建DAG图,然后按照是否产生Shuffle来划分Stage
- job中有N个Shuffle过程,就会对应这个N+1个Stage
- Stage由编号从小到大开始依次执行,每个Stage由一部分Task来完成
Task
- Task是Spark中执行任务的最小单元,每个Task处理RDD的1个分区的数据,占用1Core CPU
- Driver解析代码,根据每个Stage生成对应Task,将Task分配到Executor中运行
- 每个Stage由不同Task来实现处理,Task个数怎么决定?由这个Stage中RDD的最大分区数决定
1.8.9spark应用执行流程
目标:理解spark应用执行流程
流程图:
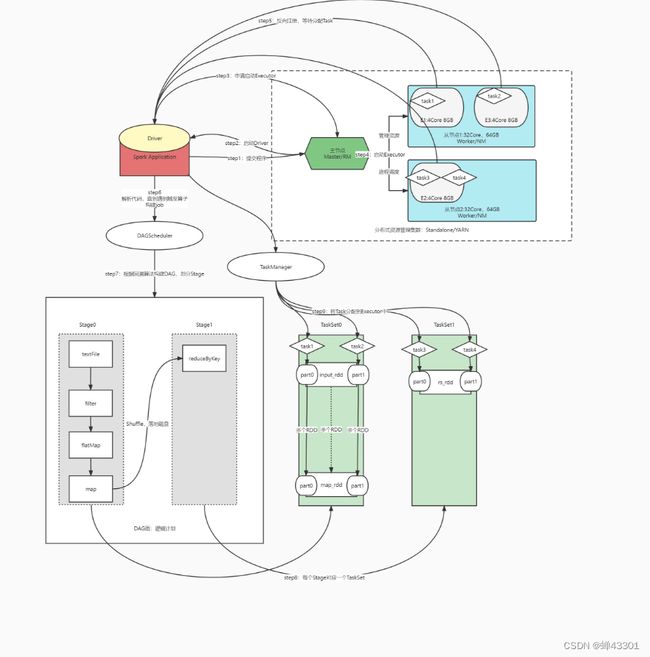
- step0:先启动分布式资源管理的集群:Spark Standalone / YARN
- step1:客户端提交用户开发好的Spark Application程序给ClusterManager
- step2:ClusterManager根据配置参数运行程序,启动Driver进程
- step3:Driver进程向主节点提交申请启动Executor进程
- step4:主节点根据资源配置和请求,在从节点上启动Executor进程
- step5:所有Executor启动成功以后,会向Driver反向注册,等待分配Task
- step6:Driver解析代码,直到遇到触发算子,开始触发job的运行
- step7:Driver会调用DAGScheduler组件为当前这个job通过回溯算法构建DAG图,并划分Stage
- step8:Driver会将这个job中每个Stage转换为TaskSet:TaskSet就是Task的集合,根据Stage中RDD的最大分区数来构建Task
- step9:Driver调用TaskManager将Task调度分配到Executor中运行
1.8.10Spark中的宽窄依赖
目标:掌握Spark中的宽窄依赖
窄依赖:Narrow Dependencies
定义:父RDD的一个分区的数据只给了子RDD的一个分区(不调用分区器)
示例:

特点:一对一或者多对一,不经过shuffle,性能相对比较快,但是无法实现全局分区,排序,分组等,一个stage内部的计算都是宽窄依赖的过程
宽依赖:Wid?shuffle Dependeciesd
定义:父RDD中的一个分区的数据给了子RDD的多个分区(需要调用shuffle的分区器来实现)
示例:
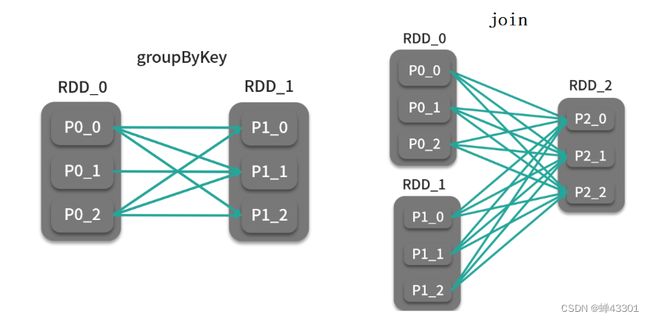
特点:一对多,必须经过shuffle,性能想多较慢,可以实现全局分区,排序,分组等
Sprk的job中按照宽窄依赖划分Stage
为什么要设计对RDD的关系标记宽窄依赖?
提高数据容错的性能,避免分区数据丢失时,需要重新构建整个RDD
- 场景:如果子RDD的某个分区的数据丢失
- 不标记:不清楚父RDD与子RDD数据之间的关系,必须重新构建整个父RDD所有数据
提高数据转换的性能,将连续窄依赖操作使用同一个Task都放在内存中直接转换
- 场景:如果RDD需要多个map、flatMap、filter、reduceByKey、sortByKey等算子的转换操作
- 不标记:每个转换不知道会不会经过Shuffle,都使用不同的Task来完成,每个Task的结果要保存到磁盘
- 标记了:多个连续窄依赖算子放在一个Stage中,共用一套Task在内存中完成所有转换,性能更快
1.8.11spark的shuffle设计
目标:理解spark的shuffle设计
什么是shuffle,为什么需要shuffle
场景:假设有一个hdfs文件,分成三个Block块,每台机器上一个Block
- node1-Block1:(a,1)(c,9)(c,6)(d,3)
- node2-Block2:(b,4)(a,8)(d,2)
- node3-Block3:(b,7)(d,5)
需求:在分布式大数据量计算过程中,如果需要对所有数据进行全局分组/全局排序/重新分配怎么办?
全局分组:相同单词放在一组 - node1-Block1:(a, [1,8])(c, [9,6])
- node2-Block2:(b, [4,7])
- node3-Block3:(d, [3,2,5])
全局排序:按照整体value降序排序
node1-Block1:(c,9)(a,8)(b,7)(c,6)
node2-Block2:(d,5)(b,4)(d,3)
node3-Block3:(d,2)(a,1)
重新分区:数据分配不均衡,希望更加均衡
node1-Block1:(a,1)(a,8)(d,3)
node2-Block2:(b,4)(b,7)(d,2)
node3-Block3:(c,9)(c,6)(d,5)
功能:shuffle的本质是基于磁盘来解决分布式的全局分组,全局排序,重新分区的问题
我们如何知道我们的代码的过程是否一定经过shuffle?
大数据量全局分组,全局排序,重新分区(调大)一定会经过shuffle过程
问题2:MapReduce的shuffle过程是什么样的?
功能:分区,排序,分组
阶段:Map端shuffle,Reduce端shuffle
流程
- Map端Shuffle:进入环形缓冲区,内存排序,溢写生成有序小文件,磁盘合并排序生成整体有序大文件
- 分区:所有Map输出的数据先调用分区器进行分区标记
- 进入环形缓存区Spill:为了多个生成有序的小文件
达到一定的阈值:80%
在内存中进行排序:快排
将排序好的数据写入生成小文件 - 实现小文件整体合并Merge:将每个分区的数据放在一起,并且构建每个分区内部有序
合并排序:归并排序:基于多个有序小文件磁盘合并算法
每个MapTask产生一个大文件:相同分区的数据放在一起,每个分区内部是有序 - Reduce端Shuffle:拉取分区数据,内存或者磁盘合并排序生成整体有序的数据文件,再分组
- 拉取:每个Reduce到每个MapTask产生的大文件中拉取属于自己的数据
- 将多个Map中自己的数据合并Merge:对所有数据进行排序,构建整体有序
合并排序:归并排序:基于多个有序数据的内存或者磁盘合并算法 - 分组:按照key进行分组,相同的Key的Value放入同一个列表中

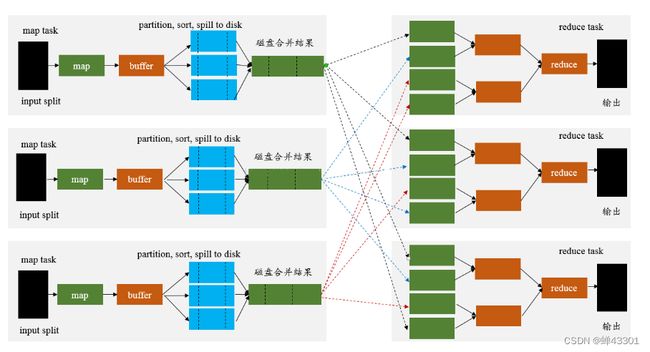
Spark的shuffle过程是什么样的?
介绍:Spark Shuffle过程也叫作宽依赖过程,Spark不完全依赖于内存计算,面临以上问题时,也需要Shuffle过程

功能:分区,排序,分组
阶段:shuffle write和shuffle read - shuffle wirt:类似于Map端shuffle过程,将当前Stage的结果进行分区,排序后写入hdfs
- shuffle read:类似于reduce端shuffle过程,读取上一个stage的结果,进行排序,分组等操作
流程
- Sort Shuffle:类似于MapReduce Shuffle的Shuffle过程,Spark1.2以后默认的Shuffle类型
- Shuffle Write**:有三种Shuffle write
Stage输出的结果先写入内存缓冲区
内存中排序以后,生成小文件
小文件合并成整体有序的大文件以及索引文件
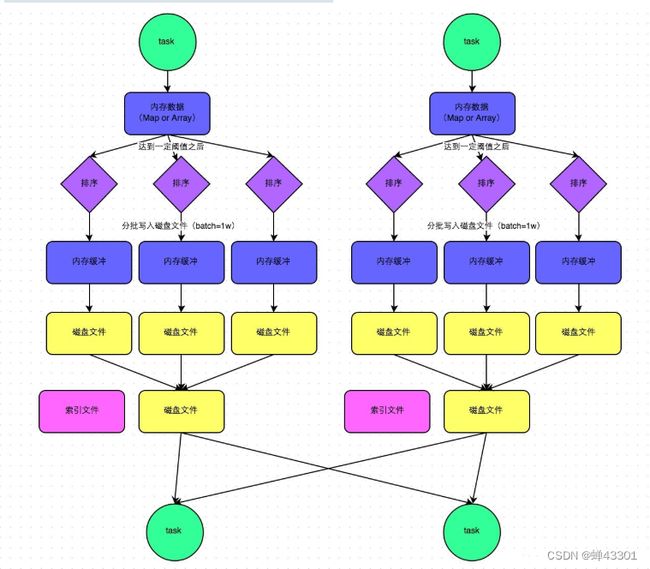
- shuffle Read
- 下一个Stage的每个Task根据索引文件读取属于自己的数据
- Spark中的Shuffle Read根据算子的功能实现不同的操作,有别于MR的Reduce Shuffle一定会有排序、分组
repartition:读取数据
sortByKey:读取数据,每个分区内部进行排序
reduceByKey:读取数据,每个分区内部进行聚合
面试:MR Shuffle过程和Spark Shuffle过程有什么区别? - 整体过程类似
- Spark中叫做Shuffle Write 和 Shuffle Read
- Shuffle Write阶段除了生成整体大文件以外,还有一个索引文件
- Shuffle Read根据算子来实现不同的过程
1.9SparkSQl设计及入门
1.9.1sparkCore重点
目标:理解SparCore的重点
理论:
- Spark的功能及应用场景
- Spark的集群架构设计
- Spark的程序运行流程
- Spark的宽窄依赖及shuffle
- Spark on Yarn
- RDD的五大特性
- RDD的算子特性
- RDD的容错机制
1.9.2Spark的优化思路
目标:理解SparkCore的优化思想
RDD的构建
- 避免创建重复的RDD:同样的一份数据只构建一个RDD
- 尽可能复用同一个RDD:尽量使用已有的RDD构建得到想要的数据,减少RDD个数
RDD的缓存
- 对多次使用的RDD进行persist持久化缓存
- persist后及时unpersist
RDD的并行度
- 读取数据后数据量大提高RDD分区数
- 聚合数据后数据量小降低RDD分区数
分区个数由什么决定?
读取数据:由读取规则决定
- 读文件:如果指定了就按照指定的划分最小分区,实际分区按块的个数决定,没有指定最大为2
- 读列表:如果指定了就生成指定的分区个数,如果没有指定就为默认的并行度
- 默认并行度:spark.default.parallelism
处理数据
- 不经过shuffle:默认为父RDD的分区个数
- 经过shuffle但未指定分区个数:默认为父RDD的分区个数
- 经过shuffle但指定了分区个数:就是指定的分区个数
- 如果调用repartition或者coalesce:就是调整后的分区个数
选择性能更好的算子
- 尽量避免使用shuffle类的宽依赖算子
- 优先使用map-side预聚合的shuffle操作
- 优先使用高性能的算子:分区操作算子xxxxPartition,repartitionAndSortWithinPartitions算子代替repartition+sort
使用广播变量
- 将较大的数据变量进行广播,减少网络IO
- Join数据时,实现Broadcast Join
1.9.3SparkCore的缺点
目标:理解SparkCore的缺点
问题:在大数据业务场景中,经常处理结构化的数据,数据来源往往是一些结构化数据,结构化的文件,对于结构化的数据处理最方便的开发机构就是SQL接口
- SparkCore类似于MapReduce的编程方式,写代码,提交运行
- 构建对象实例RDD,调用函数来处理
- SparkCore处理结构化的数据非常不方便
举个例子:
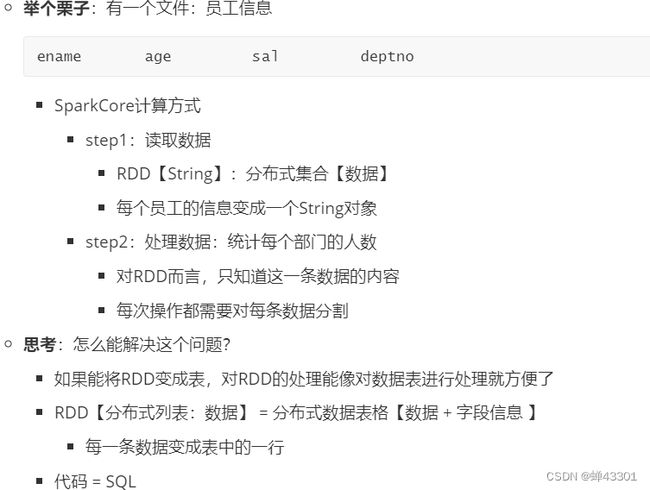
1.9.4SparkSQL的介绍
目标:了解WordCount的实现方案
实施:
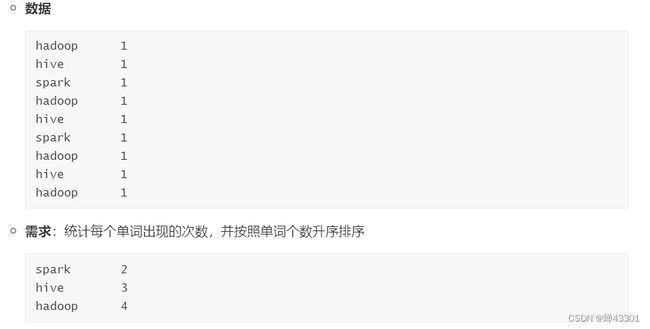
SparkCore的实现:
# 构建SparkContext
conf = SparkConf().setMaster().setAppName()
sc = SparkContext(conf)
# 读取数据
input_rdd = sc.textFile()
# 处理数据
rs_rdd = input_rdd
# 先分割,得到列表
.map(lambda line: re.split("\\s+",line))
# 将列表转换成元组
.map(lambda line: (line[0],int(line[1])))
# 按照Key分组聚合
.reduceByKey(lambda tmp,item: tmp+item)
# 按照个数排序
.sortBy(lambda tuple: tuple[1])
sql实现:
select word, count(*) as cnt from table group by word order by cnt;
对比:
- SQL:简洁直观,灵活性差,功能局限性比较大,适合做简单的数据统计分析的任务
- Python/Scala/Java:更灵活,功能可以自己实现,相对复杂
1.9.5SparkSQL的介绍
目标:理解SparkSQL的介绍
问题:SparkCore只能通过普通代码编程的方式来使用,对于统计分析的需求不是特别的友好


1.9.6SQL与Core的对比
目标:理解Spark中SparkSQL与SparkCore的对比
实施:
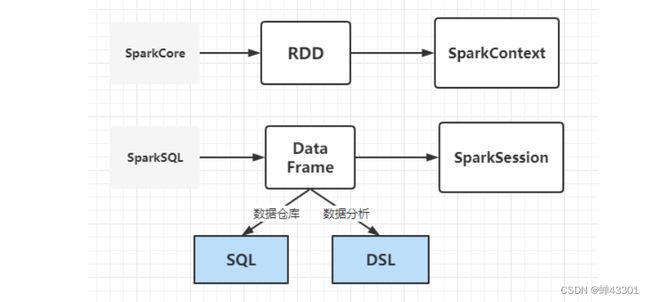
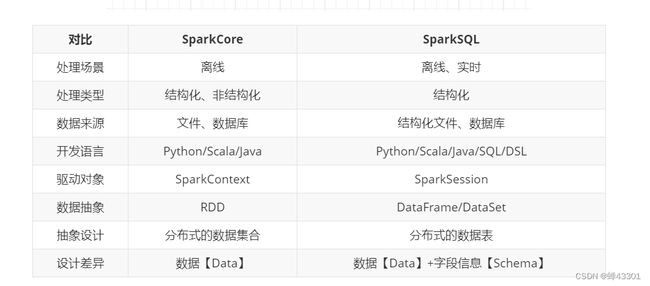
1.9.7SparkSQL的编程规则
目标:掌握SparkSQL的编程规则
实施:
- step1:Python代码中构建驱动对象
- step2:读取数据变成DataFrame,使用SQL或者DSL进行处理,保存处理好的结果
- step3:关闭驱动对象
驱动接口:
任何一个Spark程序都需要包含一个SpakContext对象,用于构建Driver进程负责的功能
sparkcore:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName(appName).setMaster(master).set(Key, Value)
sc = SparkContext(conf=conf)
sparkSql:
from pyspark.sql import SparkSession
# 任何一个SparkSQL的程序都需要包含构建SparkSession对象
# 常规构建方式:变量名 = 类名(属性1=值1, 属性2=值2): spark = SparkSession(……)
# 封装构建方式:建造者设计模式:变量名 = 类名.builder.属性配置…….getOrCreate()/build()
# 构建一个SparkSession对象:SparkSession对象中包含了一个SparkContext和SparkConf对象
spark = SparkSession \
# 获取一个建造器
.builder \
# 在建造器中配置这个对象属性:运行模式
.master("run mode")
# 在建造器中配置这个对象属性:程序名称
.appName("Python Spark SQL basic example") \
# 在建造器中配置这个对象属性:其他属性的配置
.config("spark.some.config.option", "some-value") \
# 由建造器返回这个对象的实例
.getOrCreate()
# 可以从SparkSession获取这个SparkContext对象
sc = spark.SparkContext()
# SparkSession与SparkContext一样,程序结束需要释放
spark.stop()
SQL规则:
流程:
- step1:先将DataFrame注册成一张临时的视图
DataFram是分布式数据对象,毕竟是逻辑上分布式数据对象
SQL是对表进行处理,需要将DataFrame注册成一个视图 - step2:使用SQL对临时视图进行处理,得到新的DataFrame
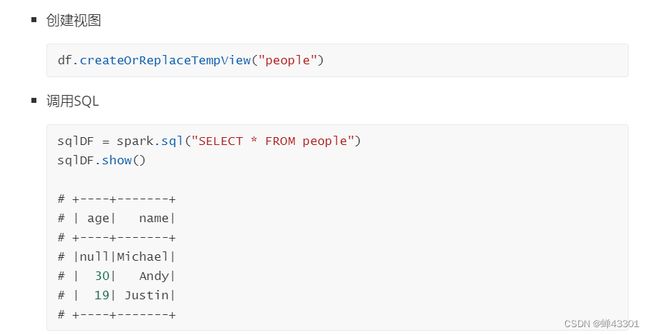
DSL规则:
流程:直接调用DataFrame的DSL函数进行处理
部分RDD算子函数:map,filter,flatmap,reparition,coalesce,persist,unpersist,checkpoint
使用:
df.printSchema()
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true)
df.select("name").show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+
df.select(df['name'], df['age'] + 1).show()
# +-------+---------+
# | name|(age + 1)|
# +-------+---------+
# |Michael| null|
# | Andy| 31|
# | Justin| 20|
# +-------+---------+
df.where(df['age'] > 21).show()
# +---+----+
# |age|name|
# +---+----+
# | 30|Andy|
# +---+----+
df.groupBy("age").count().show()
# +----+-----+
# | age|count|
# +----+-----+
# | 19| 1|
# |null| 1|
# | 30| 1|
# +----+-----+
1.9.8SparkSQL实现WordCount
目标:掌握SparkSQL实现Wordcount
实施:
step1:构建SparkSession
spark = SparkSession\
.builder\
.appName("SparkSQLAppName")\
.master("local[2]")\
.config("spark.sql.shuffle.partitions",2)\
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
step2:读取数据,SQL或者DSL转换数据,输出结果
读取数据:
# step1: 读取数据
# 将数据读取到程序中封装成分布式的数据表对象:DataFrame【数据 + Schema】
input_df = spark.read.text("../datas/wordcount")
# 打印数据和Schema信息
input_df.printSchema() # 用于输出当前DataFrame的Schema信息【列的信息】,|-- 列名: 列的类型 (是否允许为空 = true)
input_df.show(truncate=False) # 用于打印DataFrame的数据,参数n表示行数,默认显示20行,参数truncate表示如果数据太长是否省略显示,默认为true
SQL转换:
# step2: 处理数据
"""SQL处理,规则:1-将DataFrame注册成临时视图 2-使用SQL对临时视图进行处理"""
# a.注册成视图:只读的表
input_df.createOrReplaceTempView("tmp_view_words")
# b.写SQL实现数据转换处理
rs_df = spark.sql("""
with tmp as (
select
explode(split(value, " ")) as word
from tmp_view_words
)
select
word,
count(*) as cnt
from tmp
group by word
order by cnt
""")
# step3: 保存结果
rs_df.printSchema()
rs_df.show()
DSL转换:
"""DSL处理方式:直接使用函数式编程,调用算子来实现"""
rs_df = ( input_df
# 展开,将一行多个单词变成一行一个单词,col用于在DSL中表示这个字符串是一个列的名称,alias用于将列取别名
.select(explode(split(col("value"), ' ')).alias("word"))
# 分组
.groupBy(col("word"))
# 聚合
.agg( count(col("word")).alias("cnt") )
# 排序
.orderBy(col("cnt").asc())
)
# step3: 保存结果
rs_df.printSchema()
rs_df.show()
完整代码示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
import os
from pyspark.sql.functions import explode, split, col, count
"""
-------------------------------------------------
Description : TODO:
SourceFile : 01.pyspark_sql_wordcount
Author : Frank
Date : 2022/5/28
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkSession
spark = SparkSession \
.builder \
.appName("SparkSQLAppName") \
.master("local[2]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 设置日志级别为WARN
spark.sparkContext.setLogLevel("WARN")
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# 将数据读取到程序中封装成分布式的数据表对象:DataFrame【数据 + Schema】
input_df = spark.read.text("../datas/wordcount")
# 打印数据和Schema信息
# input_df.printSchema() # 用于输出当前DataFrame的Schema信息【列的信息】,|-- 列名: 列的类型 (是否允许为空 = true)
# input_df.show(truncate=False) # 用于打印DataFrame的数据,参数n表示行数,默认显示20行,参数truncate表示如果数据太长是否省略显示,默认为true
# step2: 处理数据
"""SQL处理,规则:1-将DataFrame注册成临时视图 2-使用SQL对临时视图进行处理"""
# a.注册成视图:只读的表
# input_df.createOrReplaceTempView("tmp_view_words")
# b.写SQL实现数据转换处理
# rs_df = spark.sql("""
# with tmp as (
# select
# explode(split(value, " ")) as word
# from tmp_view_words
# )
# select
# word,
# count(*) as cnt
# from tmp
# group by word
# order by cnt
# """)
"""DSL处理方式:直接使用函数式编程,调用算子来实现"""
rs_df = ( input_df
# 展开,将一行多个单词变成一行一个单词,col用于在DSL中表示这个字符串是一个列的名称,alias用于将列取别名
.select(explode(split(col("value"), ' ')).alias("word"))
# 分组
.groupBy(col("word"))
# 聚合
.agg( count(col("word")).alias("cnt") )
# 排序
.orderBy(col("cnt").asc())
)
# step3: 保存结果
rs_df.printSchema()
rs_df.show()
# todo:3-关闭SparkSession
spark.stop()
1.9.10DataFrame的设计
1.9.10.1DataFrame的设计与发展
目标:理解DataFram的设计与发展
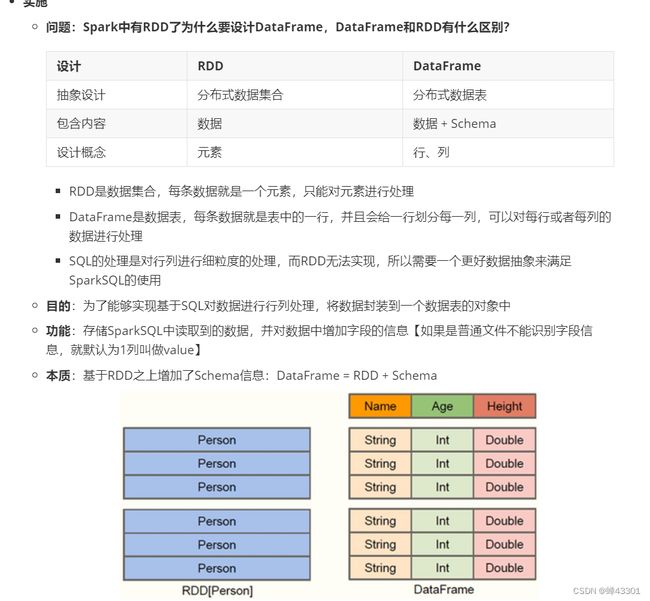

测试
查看JSON文件的内容
{"name":"Michael", "salary":3000}
{"name":"Andy", "salary":4500}
{"name":"Justin", "salary":3500}
{"name":"Berta", "salary":4000}
用RDD去读取
# a.读取变成rdd
input_rdd = spark.sparkContext.textFile("../datas/resources/employees.json")
input_rdd.foreach(lambda x: print(x))
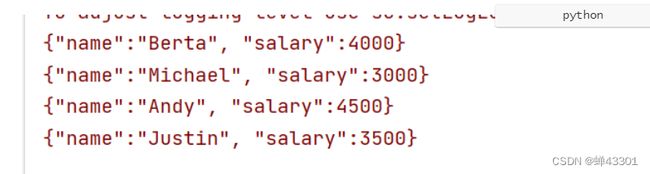
会将每条数据作为一个字符串,进行输出,并不会解析数据中有列
用DataFrame去读取
# b.读取变成DF
input_df = spark.read.json("../datas/resources/employees.json")
input_df.printSchema()
input_df.show()
从DataFrame中获取RDD和Schema
# 关系 DataFrame = RDD + Schema
# 从Df中获取RDD
input_df_rdd = input_df.rdd
input_df_rdd.foreach(lambda x: print(x))
print("=======================================")
# 从DF中获取Schema
input_df_schema = input_df.schema
print(*input_df_schema)

1.9.10.2Row和Schema的概念及使用
目标:理解Schema的概念及使用
实施:
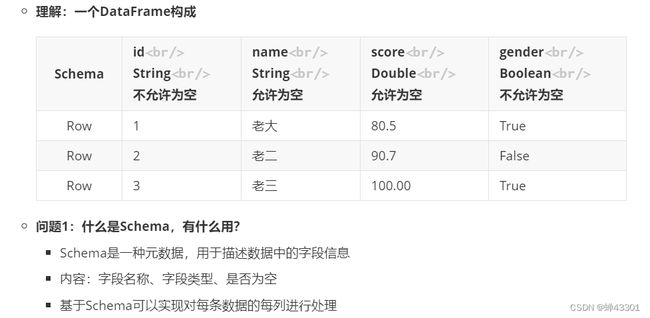
问题2:Scheme怎么用?
打印:

构建:
"""
需求:构建一个Schema对象,包含四列:id、name、score、gender
StructType:表示一个DataFrame的Schema信息,包含多列的信息
StructField:表示一列的Schema信息,包含列名、类型、是否允许为空
"""
# 定义每一列的信息
col_id = StructField(name="id", dataType=StringType(), nullable=False)
col_name = StructField(name="name", dataType=StringType(), nullable=True)
col_score = StructField(name="score", dataType=DoubleType(), nullable=True)
col_gender = StructField(name="gender", dataType=BooleanType(), nullable=True)
# 构建成一个DataFrame的Schema信息
create_schema = StructType(fields=[col_id, col_name, col_score, col_gender])
# 打印Schema信息
print(create_schema)
问题3:什么事Row,有什么用?
- Row是一个数据类型,类似于str/int/boolean,用于存储DataFrame中的每条数据的内容
- DataFrame中每条数据就是一个Row对象,类似于str等数据类型一样
问题4:Row怎么用?
获取:
# 方式一:通过引用属性名称获取对应的值
name = row['name']
salary = row['salary']
print(name,salary)
# 方式二:通过点调用方法获取对应的值
name = row.name
salary = row.salary
print(name,salary)
创建:
row = Row(name="周杰伦", music="我的地盘")
print(row.name, row.music)
1.9.10.3自动推断类型转换Dataframe
目标:掌握自动推断类型转换DataFrame

测试:
数据:datas/movie/u.data
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
转换:
# step1: 读取数据
# 用RDD方式进行读取
movie_rdd = spark.sparkContext.textFile("../datas/movie/u.data")
# step2: 处理数据
"""自动推断:RDD中每条数据必须为Row类型,Spark就可以实现自动推断"""
# a.将str类型的RDD变成Row类型的RDD
movie_rdd_row = ( movie_rdd
# 先将每个字符串分割,变成列表
.map(lambda line: re.split("\\s+", line))
# 将每个列表转换成一条Row类型对象数据
.map(lambda item: Row(userid=item[0], movieid=item[1], rate=float(item[2]), ts=int(item[3])))
)
# b.将RDD转换成DF
movie_df = spark.createDataFrame(movie_rdd_row)
# step3: 保存结果
movie_df.printSchema()
movie_df.show()
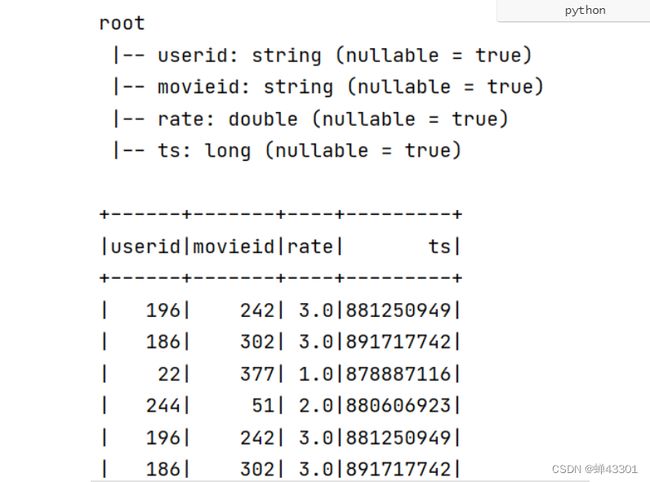
1.9.10.4自定义Schema转换DataFrame
目标:掌握自定义Schema转换DataFrame
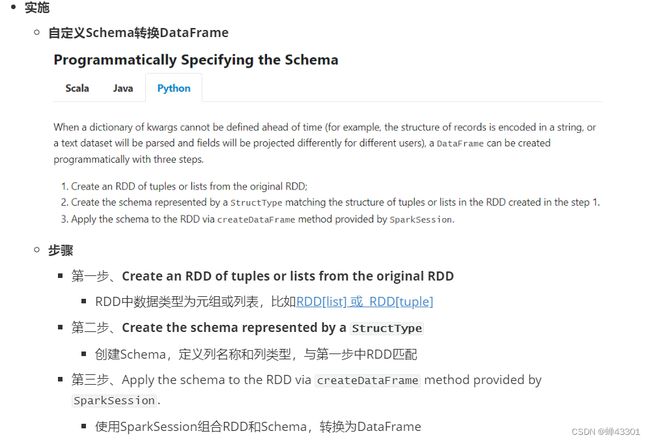
测试:
# step1: 读取数据
# 用RDD方式进行读取
movie_rdd_str = spark.sparkContext.textFile("../datas/movie/u.data")
# step2: 处理数据
"""自定义Schema:自己定义RDD中数据对应的Schema"""
# a.将str类型的RDD变成Row类型的RDD
movie_rdd_list = ( movie_rdd_str
# 先将每个字符串分割,变成列表
.map(lambda line: re.split("\\s+", line))
# 将每个列表转换成一条Row类型对象数据
.map(lambda item: [item[0], item[1], float(item[2]), int(item[3])] )
)
# b.定义与这个RDD中每一列向匹配的Schema
movie_schema = StructType([
StructField(name="userid", dataType=StringType(), nullable=False),
StructField(name="movieid", dataType=StringType(), nullable=False),
StructField(name="rate", dataType=DoubleType(), nullable=False),
StructField(name="ts", dataType=LongType(), nullable=False)
])
# c.将RDD与Schema合并
movie_df = spark.createDataFrame(movie_rdd_list, movie_schema)
# step3: 保存结果
movie_df.printSchema()
movie_df.show()
1.9.10.5指定列名称转换DataFrame
目标;掌握指定列名称转换DataFrame
实施:
toDF函数:
功能:将元素类型为元组类型的RDD直接转换为DataFrame
语法:
def toDF(self: RDD[RowLike], schema: List[str]) -> DataFrame
测试:
# step1: 读取数据
# 用RDD方式进行读取
movie_rdd_str = spark.sparkContext.textFile("../datas/movie/u.data")
# step2: 处理数据
"""自定义Schema:自己定义RDD中数据对应的Schema"""
# a.将str类型的RDD变成Row类型的RDD
movie_rdd_list = ( movie_rdd_str
# 先将每个字符串分割,变成列表
.map(lambda line: re.split("\\s+", line))
# 将每个列表转换成一条Row类型对象数据
.map(lambda item: (item[0], item[1], float(item[2]), int(item[3])) )
)
# b.将RDD转换成DF
movie_df = movie_rdd_list.toDF(["userid", "movieid", "rate", "ts"])
# step3: 保存结果
movie_df.printSchema()
movie_df.show()
1.9.11电影评分top10
1.9.11.1电影数据及需求分析
目标:理解电影数据及需求分析
实施:电影评分数据:datas/movie.ratings.dat【用户id、电影id、评分、评分时间】
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275
1::2355::5::978824291
1::1197::3::978302268
1::1287::5::978302039
1::2804::5::978300719
1::594::4::978302268
1::919::4::978301368
1::595::5::978824268
电影信息数据:datas/movie/movies.dat【电影id、电影名称、分类】
1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
4::Waiting to Exhale (1995)::Comedy|Drama
5::Father of the Bride Part II (1995)::Comedy
6::Heat (1995)::Action|Crime|Thriller
7::Sabrina (1995)::Comedy|Romance
8::Tom and Huck (1995)::Adventure|Children's
9::Sudden Death (1995)::Action
需求**:统计评分次数大于2000的所有电影中平均评分最高的Top10,结果显示电影名称、电影平均评分、电影评分次数
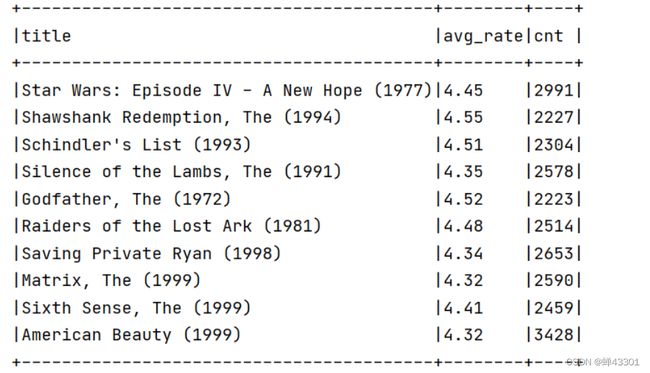
分析
step1:加载数据并解析数据字段封装成DataFrame
step2:使用SQL实现统计TopN
使用SQL进行分析
-- 先计算出评分次数大于2000的所有电影的平均评分
select
movieid,
avg(rate) as avg_rate,
count(*) as cnt
from tmp_view_rate
group by movieid
having cnt > 2000
order by avg_rate desc
limit 10;
step3:实现两张表的关联并输出结果
-- 关联电影名称
select
b.moviename,
a.avg_rate,
a.cnt
from tmp a
join tmp_view_movie b on a.movieid = b.movieid
1.9.11.2读取数据并封装DF
目标:实现读取数据并封装DF
需求:读取两份数据,并对数据进行解析,构建成DataFrame
实现:
# step1: 读取数据
# a. 读取评分数据
rate_df =( spark.sparkContext.textFile("../datas/movie/ratings.dat")
# 先分割得到列表
.map(lambda line: re.split("::", line))
# 类型转换并且构建元组
.map(lambda item: (item[0], item[1], float(item[2]), int(item[3])))
# 转换为DF
.toDF(["userid", "movieid", "rate", "ts"])
)
# b. 读取电影信息
movie_df = ( spark.sparkContext.textFile("../datas/movie/movies.dat")
# 先分割得到列表
.map(lambda line: re.split("::", line))
# 类型转换并且构建元组
.map(lambda item: (item[0], item[1], item[2]))
# 转换为DF
.toDF(["movieid", "title", "genres"])
)
# c.测试打印读取数据
rate_df.printSchema()
rate_df.show(n=10)
movie_df.printSchema()
movie_df.show(n=10)
结果:


1.9.11.3基于SQL实现TopN
目标:实现基于SQL实现TopN
需求:统计评分次数大于2000的所有电影中平均分最高的Top10
实现:
# a.先计算所有评分次数高于2000的电影平均评分最高的前10个
rate_df.createOrReplaceTempView(name="tmp_view_rate")
rs_tmp_df = spark.sql("""
select
movieid,
round(avg(rate), 2) as avg_rate,
count(*) as cnt
from tmp_view_rate
group by movieid
having cnt > 2000
order by avg_rate desc, cnt desc
limit 10
""")
# 输出临时结果
rs_tmp_df.printSchema()
rs_tmp_df.show()
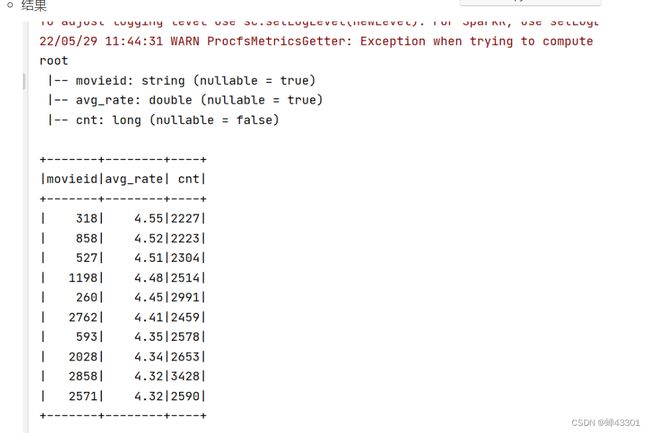
1.9.11.4关联数据构建结果
目标:实现关联数据构建结果
需求:将Top10结果与电影信息进行关联得到电影名称
实现:
# b.关联电影名称
# 将两张要关联DF构建成视图
rs_tmp_df.createOrReplaceTempView(name="rs_tmp")
movie_df.createOrReplaceTempView(name="tmp_view_movie")
# SQL关联处理视图
rs_df = spark.sql("""
select
b.title,
a.avg_rate,
a.cnt
from rs_tmp a
join tmp_view_movie b on a.movieid= b.movieid
""")
# step3: 保存结果
rs_df.printSchema()
rs_df.show(truncate=False)

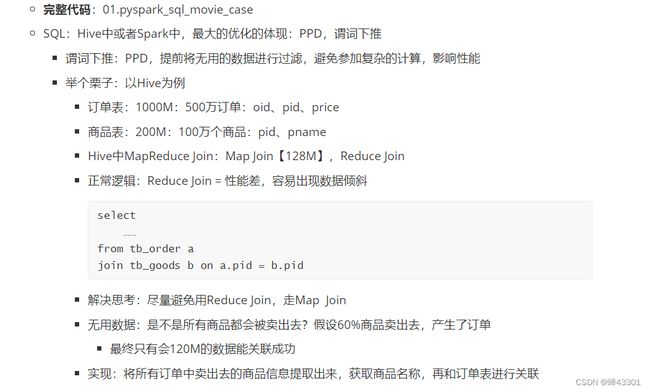

1.9.11.5SQL和DSL的使用
目标:掌握SparkSQL中SQL开发的使用
实施:
step1:将DataFrame注册成临时的视图表
DataFrame.createOrReplaceTempView("视图名称")
step2:使用SQL语句对临时视图进行处理
RS_DF = spark.sql("处理视图的SQL语句")
语法:
- 基本语法与Hive整体90%的语法类似,当做Hive上来使用
- https://spark.apache.org/docs/latest/sql-ref.html
测试:数据
# emp.tsv【员工id、员工名称、员工薪水、员工奖金、部门id】
7369 SMITH 800.00 0.00 20
7499 ALLEN 1600.00 300.00 30
7521 WARD 1250.00 500.00 30
7566 JONES 2975.00 0.00 20
7654 MARTIN 1250.00 1400.00 30
7698 BLAKE 2850.00 0.00 30
7782 CLARK 2450.00 0.00 10
7788 SCOTT 3000.00 0.00 20
7839 KING 5000.00 0.00 10
7844 TURNER 1500.00 0.00 30
7876 ADAMS 1100.00 0.00 20
7900 JAMES 950.00 0.00 30
7902 FORD 3000.00 0.00 20
7934 MILLER 1300.00 0.00 10
# dept.csv【部门id、部门名称、部门位置】
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON
需求:查询统计每个部门薪资最高的前两名员工的信息以及员工所在的部门名称
员工id、员工名称、员工薪水、员工奖金、部门id、部门名称
-
join:两张表进行列的拼接,得到部门名称
-
经验:如果需求中出现了每个、各个、不同等词,说明这个需求要么分组要么分区
-
分组:group by:一组只返回一条
分区:partition by:一组要返回多条
实现:# step1: 读取数据 # a.读取员工表的数据 emp_df = ( spark.sparkContext.textFile("../datas/emp/emp.tsv") .map(lambda line: re.split("\\s+", line)) .map(lambda item: (item[0], item[1], float(item[2]), float(item[3]), item[4])) .toDF(["empid", "ename", "salary", "bonus", "deptid"]) ) # emp_df.printSchema() # emp_df.show() # b.读取部门表数据 dept_df = (spark.sparkContext.textFile("../datas/emp/dept.csv") .map(lambda line: re.split(",", line)) .map(lambda item: (item[0], item[1], item[2])) .toDF(["deptid", "dname", "loc"]) ) # dept_df.printSchema() # dept_df.show() # step2: 处理数据 # c.注册视图 emp_df.createOrReplaceTempView("tmp_view_emp") dept_df.createOrReplaceTempView("tmp_view_dept") # d.SQL分析:取每个部门薪资最高的前两名的信息 rs_df = spark.sql(""" with tmp as ( select a.*, b.dname, row_number() over (partition by a.deptid order by a.salary desc) as rn from tmp_view_emp a join tmp_view_dept b on a.deptid = b.deptid ) select * from tmp where rn < 3 """) # step3: 保存结果 rs_df.printSchema() rs_df.show()

1.9.11.6DSL开发使用API函数
目标:理解DSL开发中API函数的使用
实施:
DSL方式:类似于RDD中调用算子的方式,实现对数据的处理
DSL函数:
API函数:类似于RDD中的算子,用法基本一致,但是支持的算子不多,支持一些缓存、调整分区、简单的算子
SQL函数:将SQL语句中的关键词转换成函数:select、groupBy、orderBy、where

- count:统计行数
- collect:将DataFrame转换成一个数组
- take:取DataFrame中前N行的数据
- first:取DataFrame中第一行的数据
- head:默认取DataFrame中第一行的数据,可以指定返回前N行的数据
- tail:可以指定返回后N行的数据
- foreach:对DataFrame中每条数据进行处理,没有返回值
- foreachPartition:对DataFrame中每个分区数据进行处理,没有返回值
- distinct:对DataFrame中每条数据进行去重处理
- union/unionAll:实现两个DataFrame的合并
- coalesce/repartition:调整DataFrame的分区数
- cache/persist:对DataFrame进行缓存
- unpersist:取消DataFrame的缓存
- columns:返回DataFrame中的所有列名
- schema:返回DataFrame中Schema的信息
- rdd:返回DataFrame中的数据放入RDD中
- printSchema**:打印DataFrame的Schema信息
完整代码示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import re
from pyspark import StorageLevel
from pyspark.sql import SparkSession
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
# todo:1-构建SparkContext
spark = SparkSession \
.builder \
.appName("MovieApp") \
.master("local[2]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# todo:2-数据处理:读取、转换、保存
people_df = spark.read.json("../datas/resources/people.json")
# 基本算子:count/collect/take/first/head/tail/foreach/foreachPartition/distinct/union/unionAll/coalesce/repartition
count = people_df.count()
print(f"总共有:{count}行")
collect = people_df.collect()
print(f"转换成列表以后的内容是:{collect}")
take = people_df.take(2)
print(f"前三行的内容是:{take}")
first = people_df.first()
print(f"前一行的内容是:{first}")
head = people_df.head()
print(f"前一行的内容是:{head}")
tail = people_df.tail(1)
print(f"最后一行的内容是:{tail}")
people_df.foreach(lambda row: print(row))
people_df.foreachPartition(lambda part: print(*part))
print("union的结果")
people_df_other = spark.read.json("../datas/resources/people.json")
people_df.union(people_df_other).show()
print("unionAll的结果")
people_df.unionAll(people_df_other).show()
print("distinct的结果")
people_df.unionAll(people_df_other).distinct().show()
print(f"原来的分区数:{people_df.rdd.getNumPartitions()}")
print(f"减少后分区数:{people_df.coalesce(1).rdd.getNumPartitions()}")
print(f"增大后分区数:{people_df.repartition(4).rdd.getNumPartitions()}")
# 持久化算子
people_df.cache()
people_df.persist(StorageLevel.MEMORY_AND_DISK_2)
people_df.unpersist(blocking=True)
# 其他算子
columns = people_df.columns
print(f"所有列的名称:{columns}")
schema = people_df.schema
print(f"所有列的信息:{schema}")
rdd = people_df.rdd
rdd.foreach(lambda x: print(x))
people_df.printSchema()
# todo:3-关闭SparkContext
spark.stop()
1.9.11.7DSL开发使用SQL函数
目标:理解DSL开发中SQL函数的使用
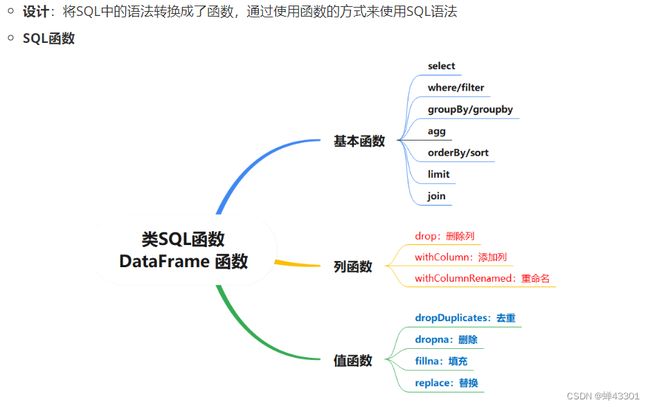
# 1、选择函数select:选取某些列或者某些函数表达式的值
def select(self, *cols: Union[Column, str]) -> DataFrame
# 2、过滤函数filter/where:设置过滤条件,类似SQL中WHERE语句
def filter(self, condition: Union[Column, str]) -> DataFrame
# 3、分组函数groupBy/rollup/cube:对某些字段分组,在进行聚合统计
def groupBy(self, *cols: Union[Column, str]) -> GroupedData
# 4、聚合函数agg:通常与分组函数连用,使用一些count、max、sum等聚合函数操作
def agg(self, *exprs: Union[Column, Dict[str, str]]) -> DataFrame
# 5、排序函数sort/orderBy:按照某写列的值进行排序(升序ASC或者降序DESC)
def sort(self,
*cols: Union[str, Column, List[Union[str, Column]]],
ascending: Union[bool, List[bool]] = ...) -> DataFrame
# 6、限制函数limit:获取前几条数据,类似RDD中take函数
def limit(self, num: int) -> DataFrame
# 7、重命名函数withColumnRenamed:将某列的名称重新命名
def withColumnRenamed(self, existing: str, new: str) -> DataFrame
# 8、删除函数drop:删除某些列
def drop(self, cols: Union[Column, str]) -> DataFrame
# 9、增加列函数withColumn:当某列存在时替换值,不存在时添加此列
def withColumn(self, colName: str, col: Column) -> DataFrame
- 注意**:在调用函数对列进行操作时,可以使用col或者column函数将字符串转换成一个列的对象
- 测试案例:将电影评分案例通过DSL SQL函数来实现
测试案例:将电泳评分案例通过DSL SQL函数来实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
import os
import re
import pyspark.sql.functions as F
"""
-------------------------------------------------
Description : TODO:
SourceFile : 04.pyspark_sql_movie_case_dsl
Author : Frank
Date : 2022/5/29
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkSession
spark = SparkSession \
.builder \
.appName("SparkSQLAppName") \
.master("local[2]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 设置日志级别为WARN
spark.sparkContext.setLogLevel("WARN")
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# a. 读取评分数据
rate_df =( spark.sparkContext.textFile("../datas/movie/ratings.dat")
# 先分割得到列表
.map(lambda line: re.split("::", line))
# 类型转换并且构建元组
.map(lambda item: (item[0], item[1], float(item[2]), int(item[3])))
# 转换为DF
.toDF(["userid", "movieid", "rate", "ts"])
)
# b. 读取电影信息
movie_df = ( spark.sparkContext.textFile("../datas/movie/movies.dat")
# 先分割得到列表
.map(lambda line: re.split("::", line))
# 类型转换并且构建元组
.map(lambda item: (item[0], item[1], item[2]))
# 转换为DF
.toDF(["movieid", "title", "genres"])
)
# step2: 处理数据
# a.先计算所有评分次数高于2000的电影平均评分最高的前10个
rate_df.createOrReplaceTempView(name="tmp_view_rate")
rs_tmp_df = ( rate_df
# 将数据中需要的字段提取出来
.select(F.col("movieid"), F.col("rate"))
# 按照电影id进行分组
.groupBy(F.col("movieid"))
# 聚合
.agg(
# 统计评分次数
F.count(F.col("movieid")).alias("cnt"),
# 统计平均的评分
F.round(F.avg(F.col("rate")), 2).alias("avg_rate")
)
# 过滤:评分次数要高于2000
.where(F.col("cnt") > 2000)
# 按照平均分进行降序排序
.orderBy(F.col("avg_rate").desc(), F.col("cnt").desc())
# 取出前10名
.limit(10)
)
# b.关联电影名称
rs_df = ( rs_tmp_df
# 关联得到电影名称
.join(other=movie_df, on=["movieid"], how="inner")
# 获取最后结果想要的字段
.select(F.col("movieid"), F.col("title"), F.col("avg_rate"), F.col("cnt"))
# 排序
.orderBy(F.col("avg_rate").desc())
)
# step3: 保存结果
rs_df.printSchema()
rs_df.show(truncate=False)
# todo:3-关闭SparkSession
spark.stop()
1.9.11.8Catalyst优化器
目标:了解Catalyst优化器

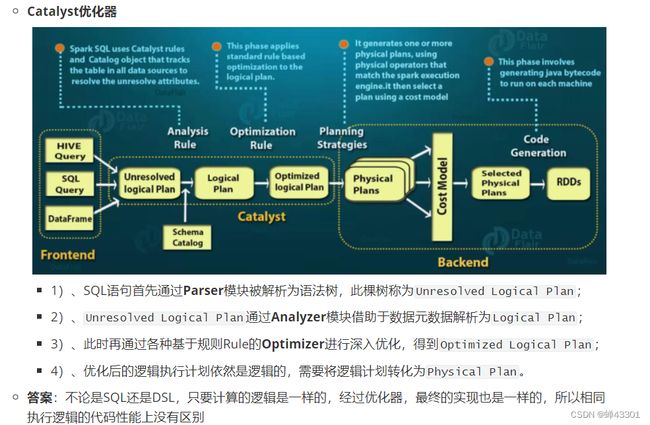
1.9.12 SparkSQL外部数据源
1.9.12.1SparkSQL读写数据的方式
目标:理解SparkSQL读写数据的方式
官网**:https://spark.apache.org/docs/latest/sql-data-sources.html
- 输入Source
类型:text / csv / json / orc / parquet / jdbc / table
语法
方式一:给定读取数据源的类型和地址
spark.read.format("json").load(path)
spark.read.format("csv").load(path)
spark.read.format("parquet").load(path)
方式二:直接调用对应数据源类型的方法
spark.read.json(path)
spark.read.csv(path)
spark.read.parquet(path)
特殊参数:option,用于指定读取时的一些配置选项
spark.read.format("csv").option("sep", "\t").load(path)
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.load()
示例
# 读取文件,不指定类型:默认就是parquet类型文件
df = spark.read.load(path="examples/src/main/resources/users.parquet")
# 读取文件,指定为json类型
df = spark.read.format("json").load(path="examples/src/main/resources/people.json")
df = spark.read.load(path="examples/src/main/resources/people.json", format="json")
# 读取文件,指定为csv,并且分隔符为分号
df = spark.read\
.format("csv")\
.option("sep", ";")\
.load(path="examples/src/main/resources/people.csv")
df = spark.read.load(
path="examples/src/main/resources/people.csv",
format="csv",
sep=";"
)
# 读取orc类型文件,直接使用类型函数
df = spark.read.orc("examples/src/main/resources/users.orc")
- 输出Sink
类型:text / csv / json / orc / parquet / jdbc / table
语法
方式一:给定输出数据源的类型和地址
df.write.format("json").save(path)
df.write.format("csv").save(path)
df.write.format("parquet").save(path)
方式二:直接调用对应数据源类型的方法
df.write.json(path)
df.write.csv(path)
df.write.parquet(path)
特殊参数:option,用于指定输出时的一些配置选项
df.write \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.save()
- 输出模式:OutputMode
功能:用于保存时指定怎么将数据写入目标数据源
类别

append: 追加模式,当数据存在时,继续追加
overwrite: 覆写模式,当数据存在时,覆写以前数据,存储当前最新数据;
error/errorifexists: 如果目标存在就报错,默认的模式
ignore: 忽略,数据存在时不做任何操作
用法
df.write.mode(saveMode="append").format("csv").save(path)
示例
# 调用类型函数将DataFrame的数据写入textfile文件中
df.write.text("/export/data/testfile.txt")
# 指定文件类型将DataFrame的数据写入textfile文件中
df.write.format("text").save("/export/data/testfile.txt")
# 指定文件类型以及配置将DataFrame的数据写入parquet文件中
df.write.format("parquet")
.option("parquet.bloom.filter.enabled#favorite_color", "true")
.option("parquet.bloom.filter.expected.ndv#favorite_color", "1000000")
.option("parquet.enable.dictionary", "true")
.option("parquet.page.write-checksum.enabled", "false")
.save("users_with_options.parquet")
# 指定文件类型以及配置将DataFrame的数据追加写入parquet文件中
df.write.mode("append").format("parquet")
.option("parquet.bloom.filter.enabled#favorite_color", "true")
.option("parquet.bloom.filter.expected.ndv#favorite_color", "1000000")
.option("parquet.enable.dictionary", "true")
.option("parquet.page.write-checksum.enabled", "false")
.save("users_with_options.parquet")
1.9.12.2读写Text文件使用
目标:掌握SparkSQL读写Text文件使用
实施
读取
# 读取
textfile_df1 = spark.read.text("../datas/resources/people.txt")
textfile_df1.printSchema()
textfile_df1.show()
textfile_df2 = spark.read.format("text").load("../datas/resources/people.txt")
textfile_df2.printSchema()
textfile_df2.show()
textfile_df3 = spark.read.load(path="../datas/resources/people.txt", format="text")
textfile_df3.printSchema()
textfile_df3.show()

输出
# 保存
textfile_df1.write.text(path="../datas/output/text/text01")
textfile_df2.write.format("text").save(path="../datas/output/text/text02")
textfile_df3.write.mode("overwrite").format("text").save(path="../datas/output/text/text02")
1.9.12.3读写Json文件使用
目标:掌握SparkSQL读写JSON文件的使用
实施
读取
# 读取
json_df1 = spark.read.json(path="../datas/resources/people.json")
json_df1.printSchema()
json_df1.show()
json_df2 = spark.read.format("json").load(path="../datas/resources/people.json")
json_df2.printSchema()
json_df2.show()
json_df3 = spark.read.format("json").option("path", "../datas/resources/people.json").load()
json_df3.printSchema()
json_df3.show()

json_df1.write.json(path="../datas/output/json/json01")
json_df2.write.format("json").save(path="../datas/output/json/json02")
json_df3.write\
.mode("overwrite")\
.format("json")\
.option("path", "../datas/output/json/json03")\
.save()
1.9.12.4 读写Parquet文件使用
目标:掌握SparkSQL读写Parquet文件的使用
实施
读取
# 读取
parquet_df1 = spark.read.parquet("../datas/resources/users.parquet")
parquet_df1.printSchema()
parquet_df1.show()
parquet_df2 = spark.read.load(path="../datas/resources/users.parquet")
parquet_df2.printSchema()
parquet_df2.show()
parquet_df3 = spark.read.format("parquet").load(path="../datas/resources/users.parquet")
parquet_df3.printSchema()
parquet_df3.show()

输出
# 输出
parquet_df1.write.parquet(path="../datas/output/parquet/parquet01")
parquet_df2.write.format("parquet").save(path="../datas/output/parquet/parquet02")
parquet_df3.write\
.mode("overwrite")\
.format("parquet")\
.option("path", "../datas/output/parquet/parquet03")\
.save()

1.9.12.5读写CSV文件使用
目标:掌握SparkSQL读写CSV文件的使用
实施
场景:任何一种有固定单字节分隔符的文本数据
读取
# 读取
# 逗号分隔的文件
csv_df1 = spark.read.csv("../datas/resources/people.txt")
csv_df1.printSchema()
csv_df1.show()
# 分号作为分隔的文件
csv_df2 = spark.read.format("csv").option("sep", ";").load("../datas/resources/people.csv")
csv_df2.printSchema()
csv_df2.show()
# 制表符作为分隔符sep,以第一行的内容作为列名header,自动推断类型inferSchema
csv_df3 = spark.read.format("csv")\
.option("sep", "\t")\
.option("header", "true")\
.option("inferSchema", "true")\
.load("../datas/resources/people.tsv")
csv_df3.printSchema()
csv_df3.show()
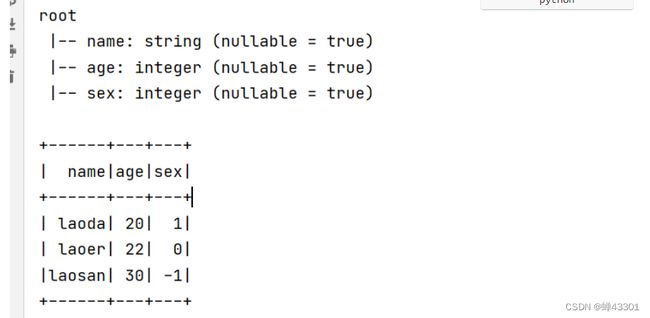
输出
# 输出
csv_df1.write.csv("../datas/output/csv/csv01")
csv_df2.write.format("csv").save(path="../datas/output/csv/csv02")
csv_df3.write\
.mode("overwrite")\
.format("csv")\
.option("sep", "\t")\
.save(path="../datas/output/csv/csv03")
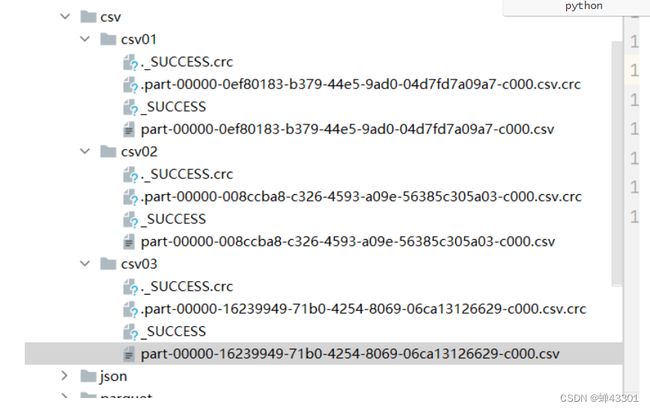
1.9.12.6读写JDBC使用
目标:掌握SparkSQL读写JDBC的使用
实施
场景:使用SparkSQL读写RDBMS数据的数据
准备
MySQL中查看数据表:第一台机器上,密码123456
use db_company;
select * from emp;
MySQL中创建数据表
CREATE TABLE db_company.emp_v2 (
`empno` int(11) NOT NULL,
`ename` varchar(10) DEFAULT NULL,
`job` varchar(9) DEFAULT NULL,
`sal` double DEFAULT NULL,
`deptno` int(11) DEFAULT NULL,
PRIMARY KEY (`empno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE db_company.emp_v3 (
`empno` int(11) NOT NULL,
`ename` varchar(10) DEFAULT NULL,
`job` varchar(9) DEFAULT NULL,
`sal` double DEFAULT NULL,
`deptno` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
Python环境放入MySQL连接驱动
找到工程中pyspark库包所在的环境,将驱动包放入环境所在的jars目录中
如果是Windows上:${ANACONDA_HOME}/Lib/site-packages/pyspark/jars



如果是Linux上
# 进入目录
cd /export/server/anaconda3/lib/python3.8/site-packages/pyspark/jars
# 上传jar包:mysql-connector-java-5.1.32.jar
rz
读取
prop = {"user": "root", "password": "123456", "driver": "com.mysql.jdbc.Driver"}
jdbc_df1 = spark.read.jdbc(
url="jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
table="db_company.emp",
properties=prop
)
jdbc_df1.printSchema()
jdbc_df1.show()
jdbc_df2 = spark.read\
.format("jdbc")\
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")\
.option("dbtable", "db_company.emp")\
.option("user", "root") \
.option("password", "123456")\
.option("driver", "com.mysql.jdbc.Driver")\
.load()
jdbc_df2.printSchema()
jdbc_df2.show()
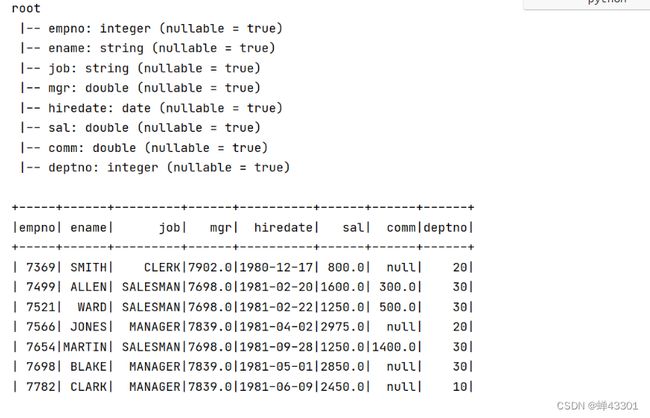
输出
jdbc_df1\
.select('empno', 'ename', 'job', 'sal', 'deptno')\
.write.jdbc(
url="jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
table="db_company.emp_v2",
mode="overwrite",
properties=prop
)
jdbc_df2 \
.select('empno', 'ename', 'job', 'sal', 'deptno') \
.write\
.mode("append")\
.format("jdbc")\
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")\
.option("dbtable", "db_company.emp_v3")\
.option("user", "root") \
.option("password", "123456")\
.option("driver", "com.mysql.jdbc.Driver")\
.save()

1.9.12.7 读写Hive使用
目标:掌握SparkSQL读写Hive使用
实施
场景:Hive底层默认是MR引擎,计算性能特别差,一般用Hive作为数据仓库,使用SparkSQL对Hive中的数据进行计算
问题:SparkSQL怎么能访问到Hive中有哪些表,以及如何知道Hive中表对应的HDFS的地址?
命令行集成
step1:第一台机器启动HDFS和Hive的Metastore
# 启动HDFS服务:NameNode和DataNodes
start-dfs.sh
# 启动HiveMetaStore 服务
start-metastore.sh

step2:在Spark中构建配置文件指定metastore地址
# 进入配置文件目录创建配置文件
cd /export/server/spark-local/conf
vim hive-site.xml
# 添加以下内容
hive.metastore.uris
thrift://node1.itcast.cn:9083
step3:启动Spark Shell命令行查看
/export/server/spark-local/bin/pyspark --master local[2] --conf spark.sql.shuffle.partitions=2
step4:方式一:直接测试SQL读写Hive
# 列举
spark.sql("show databases").show()
spark.sql("show tables in db_hive") .show()
# DQL分析
spark.sql("""
select
d.dname, round(avg(e.sal), 2) as avg_sal
from db_hive.emp e
join db_hive.dept d
on e.deptno = d.deptno
group by d.dname
order by avg_sal desc
""").show()
# DDL建表
spark.sql("create table db_hive.tb_test(word string)")
step5:方式二:加载Hive表的数据变成DF,可以调用DSL或者SQL的方式来实现计算
# 读取Hive表构建DataFrame
hiveData = spark.read.table("db_hive.emp")
hiveData.printSchema()
hiveData.show()
Pycharm中集成
规则:Pycharm工具集成Hive开发SparkSQL,必须申明Metastore的地址和启用Hive的支持
spark = SparkSession \
.builder \
.appName("HiveAPP") \
.master("local[2]") \
.config("spark.sql.warehouse.dir", 'hdfs://node1.itcast.cn:8020/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://node1.itcast.cn:9083') \
.config("spark.sql.shuffle.partitions", 2) \
.enableHiveSupport()\
.getOrCreate()
测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import re
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
# todo:1-构建SparkContext
spark = SparkSession \
.builder \
.appName("HiveAPP") \
.master("local[2]") \
.config("spark.sql.warehouse.dir", 'hdfs://node1.itcast.cn:8020/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://node1.itcast.cn:9083') \
.config("spark.sql.shuffle.partitions", 2) \
.enableHiveSupport() \
.getOrCreate()
# todo:2-数据处理:读取、转换、保存
# 读取
# type1:直接使用SQL进行处理
spark.sql("""
create table db_hive.test_rs01 as
select
d.dname, round(avg(e.sal), 2) as avg_sal
from db_hive.emp e
join db_hive.dept d
on e.deptno = d.deptno
group by d.dname
order by avg_sal desc
""").show()
# type2:读取Hive表作为DataFrame
hive_df = spark.read.table("db_hive.emp")
hive_df.printSchema()
hive_df.show()
rs_df = hive_df\
.select("deptno", "sal")\
.groupBy("deptno")\
.agg(F.round(F.avg("sal"), 2).alias("avg_sal"))
rs_df.printSchema()
rs_df.show()
# 输出
rs_df.write\
.mode("overwrite")\
.format("hive")\
.saveAsTable("db_hive.test_rs02")
# todo:3-关闭SparkContext
spark.stop()
1.9.13 SparkSQL的UDF
1.9.13.1 UDF函数的设计
目标:理解SparkSQL中UDF函数的设计
实施
问题:如果我不会RDD处理,我只会SQL,但是SQL中没有对应的函数能实现需求怎么办?
解决:自定义函数:User Define Function(UDF)
分类
- UDF:一对一的函数【User Defined Functions】
- substr、split、ceil、floor、date_add、from_unixtime
- UDAF:多对一的函数【User Defined Aggregation Functions】
- count、sum、avg、max、collect_list
- UDTF:一对多的函数【User Defined Tabular Functions】
- explode、json_tuple、parse_url_tuple
Hive中UDF开发和使用:Hive允许直接调用Python代码来作为处理逻辑
Hive允许直接调用代码来作为处理逻辑
step1:开发代码,打成jar包
step2:在Hive中注册一个函数
create function
step3:使用自定义函数
Spark中支持的UDF:https://spark.apache.org/docs/latest/sql-ref-functions.html
User-Defined Functions (UDFs) are a feature of Spark SQL that allows users to define their own functions when the system’s built-in functions are not enough to perform the desired task. To use UDFs in Spark SQL, users must first define the function, then register the function with Spark, and finally call the registered function. The User-Defined Functions can act on a single row or act on multiple rows at once. Spark SQL also supports integration of existing Hive implementations of UDFs, UDAFs and UDTFs.
Spark中支持UDF和UDAF两种,支持直接使用Hive中的UDF、UDAF、UDTF
PySpark中UDF定义的方式
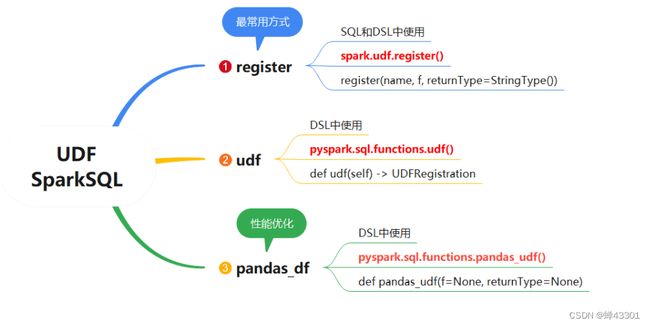
1.9.13.2 register方式定义UDF函数
目标:掌握SparkSQL中register方式定义UDF函数
实施
特点:最常用的方式,既能用于SQL中,也能用于DSL中
语法
UDF变量名 = spark.udf.register(UDF函数名, 函数的处理逻辑)
定义:spark.udf.register()
UDF变量名:DSL中调用UDF使用的
UDF函数名:SQL中调用UDF使用
需求
原始数据:datas/udf/music.tsv
01 周杰伦 150/175
02 周杰 130/185
03 周华健 148/178
目标结果
01 周杰伦 150斤/175cm
02 周杰 130斤/185cm
03 周华健 148斤/178cm
测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
import os
import re
"""
-------------------------------------------------
Description : TODO:
SourceFile : 01.pyspark_sql_udf_register
Author : Frank
Date : 2022/5/30
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkSession
spark = SparkSession \
.builder \
.appName("SparkSQLAppName") \
.master("local[2]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 设置日志级别为WARN
spark.sparkContext.setLogLevel("WARN")
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
music_df = spark.read.format("csv")\
.option("sep", "\t")\
.load("../datas/udf/music.tsv")\
.withColumnRenamed(existing="_c0", new="id")\
.withColumnRenamed(existing="_c1", new="name")\
.withColumnRenamed(existing="_c2", new="info")
music_df.printSchema()
music_df.show()
# step2: 处理数据
# a.先定义一个UDF,在UDF中实现添加单位
def to_new_info(oldinfo):
# 对每一行的内容进行分割:150/175
item = re.split("\\/", oldinfo)
# 加上单位然后返回
return item[0]+"斤"+"/"+item[1]+"cm"
# UDF变量名 = spark.udf.register(UDF函数名, 处理函数)
music_udf = spark.udf.register(name="addinfo", f=lambda oldinfo: to_new_info(oldinfo))
# b.在代码中使用UDF
# SQL中使用:UDF函数名
music_df.createOrReplaceTempView("tmp_view_music")
spark.sql("select id, name, info, addinfo(info) as newinfo from tmp_view_music").show()
# DSL中使用:UDF变量名
music_df.select("id", "name", "info", music_udf("info").alias("newinfo")).show()
# step3: 保存结果
# todo:3-关闭SparkSession
spark.stop()
运行结果
1.9.13.3 udf注册方式定义UDF函数
目标:掌握SparkSQL中udf注册方式定义UDF函数
实施
特点:不常用,只能用于DSL开发中
语法
# 导包:DSL函数库
import pyspark.sql.functions as F
# 定义
UDF变量名 = F.udf(函数的处理逻辑, 返回值类型)
需求
原始数据:datas/udf/music.tsv
01 周杰伦 150/175
02 周杰 130/185
03 周华健 148/178
目标结果
01 周杰伦 150斤/175cm
02 周杰 130斤/185cm
03 周华健 148斤/178cm
测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
import os
import re
import pyspark.sql.functions as F
from pyspark.sql.types import StringType
"""
-------------------------------------------------
Description : TODO:
SourceFile : 01.pyspark_sql_udf_function
Author : Frank
Date : 2022/5/30
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkSession
spark = SparkSession \
.builder \
.appName("SparkSQLAppName") \
.master("local[2]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 设置日志级别为WARN
spark.sparkContext.setLogLevel("WARN")
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
music_df = spark.read.format("csv")\
.option("sep", "\t")\
.load("../datas/udf/music.tsv")\
.withColumnRenamed(existing="_c0", new="id")\
.withColumnRenamed(existing="_c1", new="name")\
.withColumnRenamed(existing="_c2", new="info")
music_df.printSchema()
music_df.show()
# step2: 处理数据
# a.先定义一个UDF,在UDF中实现添加单位
def to_new_info(oldinfo):
# 对每一行的内容进行分割:150/175
item = re.split("\\/", oldinfo)
# 加上单位然后返回
return item[0]+"斤"+"/"+item[1]+"cm"
# UDF变量名 = pyspark.sql.functions.udf(处理函数, 返回值类型)
music_udf = F.udf(f=lambda oldinfo: to_new_info(oldinfo), returnType=StringType())
# b.在代码中使用UDF
# DSL中使用:UDF变量名
music_df.select("id", "name", "info", music_udf("info").alias("newinfo")).show()
# step3: 保存结果
# todo:3-关闭SparkSession
spark.stop()
执行结果

1.9.14 零售数据分析案例
1.9.14.1 案例数据及需求分析
目标:理解案例数据集需求分析
实施
背景:某零售公司网点分布全国,每天基于订单收银系统产生大量的收银数据,现需要基于公司在全国所有网点的收银系统的订单数据进行数据分析,支撑公司的运营决策。

数据:收银系统中,每个订单会产生一条JSON数据,传递到后台的数据存储系统中
{
"discountRate":1,
"dayOrderSeq":8,
"storeDistrict":"雨花区",
"isSigned":0,
"storeProvince":"湖南省",
"origin":0,
"storeGPSLongitude":"113.01567856440359",
"discount":0,
"storeID":4064,
"productCount":4,
"operatorName":"OperatorName",
"operator":"NameStr",
"storeStatus":"open",
"storeOwnUserTel":12345678910,
"corporator":"hnzy",
"serverSaved":true,
"payType":"alipay",
"discountType":2,
"storeName":"杨光峰南食店",
"storeOwnUserName":"OwnUserNameStr",
"dateTS":1563758583000,
"smallChange":0,
"storeGPSName":"",
"erase":0,
"product":[
{
"count":1,
"name":"百事可乐可乐型汽水",
"unitID":0,
"barcode":"6940159410029",
"pricePer":3,
"retailPrice":3,
"tradePrice":0,
"categoryID":1
},
{
"count":1,
"name":"馋大嘴盐焗鸡筋110g",
"unitID":0,
"barcode":"6951027300076",
"pricePer":2.5,
"retailPrice":2.5,
"tradePrice":0,
"categoryID":1
},
{
"count":2,
"name":"糯米锅巴",
"unitID":0,
"barcode":"6970362690000",
"pricePer":2.5,
"retailPrice":2.5,
"tradePrice":0,
"categoryID":1
},
{
"count":1,
"name":"南京包装",
"unitID":0,
"barcode":"6901028300056",
"pricePer":12,
"retailPrice":12,
"tradePrice":0,
"categoryID":1
}
],
"storeGPSAddress":"",
"orderID":"156375858240940641230",
"moneyBeforeWholeDiscount":22.5,
"storeCategory":"normal",
"receivable":22.5,
"faceID":"",
"storeOwnUserId":4082,
"paymentChannel":0,
"paymentScenarios":"PASV",
"storeAddress":"StoreAddress",
"totalNoDiscount":22.5,
"payedTotal":22.5,
"storeGPSLatitude":"28.121213726311993",
"storeCreateDateTS":1557733046000,
"payStatus":-1,
"storeCity":"长沙市",
"memberID":"0"
}
- 核心字段
- “storeProvince”:订单所在的省份信息,例如:湖南省
- “storeID”:订单所产生的店铺ID,例如:4064
- “receivable”:订单收款金额:例如:22.5
- “payType”:订单支付方式,例如:alipay
- “dateTS”:订单产生时间,例如:1563758583000
需求
1-统计查询每个省份的总销售额【订单金额要小于1万】

2-统计查询销售额最高的前3个省份中,统计各省份每日平均销售额超过1000的店铺个数1

3-统计查询销售额最高的前3个省份中,每个省份的平均订单金额

4-统计查询销售额最高的前3个省份中,每个省份的每种支付类型的占比

分析
1-统计查询每个省份的总销售额
指标:总销售额:累加所有订单金额:sum(receivable)
维度:省份:group by storeProvince
2-统计查询销售额最高的前3个省份中,每日平均销售额超过1000的各省份的店铺个数
指标:店铺个数:count(distinct storeID)
维度:省份:group by storeProvince
条件:前提:提前将销售额最高的前三个省份的数据先过滤出来
销售额前三的省份: where storeProvince in (前三省份名称)
每日销售额超过1000 : group by 省份,店铺,天 having sum(receivable) > 1000
4-统计查询销售额最高的前3个省份中,每个省份的每种支付类型的占比
指标:支付类型占比 = 支付类型订单个数 / 总订单个数
维度:省份,支付类型:group by storeProvince,payType
条件:前提:提前将销售额最高的前三个省份的数据先过滤出来
销售额前三的省份: where storeProvince in (前三省份名称)
1.9.14.2 案例数据加载及数据清洗
目标:实现案例数据加载及字段转换
实施
需求:读取数据变成DataFrame,并对不合法的数据进行清洗【过滤、转换】
订单金额超过10000的订单不参与统计
storeProvince不为空:None 也不为 ‘null’值
只保留需要用到的字段,将字段名称转换成Python规范:a_b_c
并对时间戳进行转换成日期,获取天
对订单金额转换为decimal类型
实现
# step1: 读取数据
# 由于数据文件为JSON文件,直接使用JSON格式进行读取
input_df = spark.read.json("../datas/order/retail.json")
# 输出验证
# input_df.printSchema()
# input_df.show()
# step2: 处理数据
# a.数据清洗:过滤、转换
etl_df = ( input_df
# 将不需要的行或者不合法的行进行过滤:订单金额小于1万,省份不为空也不为null值:where province is not null and province != 'null'
.filter((F.col("receivable") < 10000) & (F.col("storeProvince").isNotNull()) & (F.col("storeProvince") != 'null'))
# 仅保留需要用到的列:省份、店铺id、天、金额、支付方式,并且实现对应的转换
.select(
# 更换命名规则
F.col("storeProvince").alias("store_province"),
F.col("storeID").alias("store_id"),
F.col("payType").alias("pay_type"),
# 将时间戳转换为日期获取年月日yyyy-MM-dd = from_unixtime(时间戳[秒],转换后的格式)
F.from_unixtime(F.substring(F.col("dateTs"), 0, 10), "yyyy-MM-dd").alias("daystr"),
# 将receivable金额转换为Decimal类型
F.col("receivable").cast(DecimalType(10, 2)).alias("receivable_money")
)
)
etl_df.printSchema()
etl_df.show()
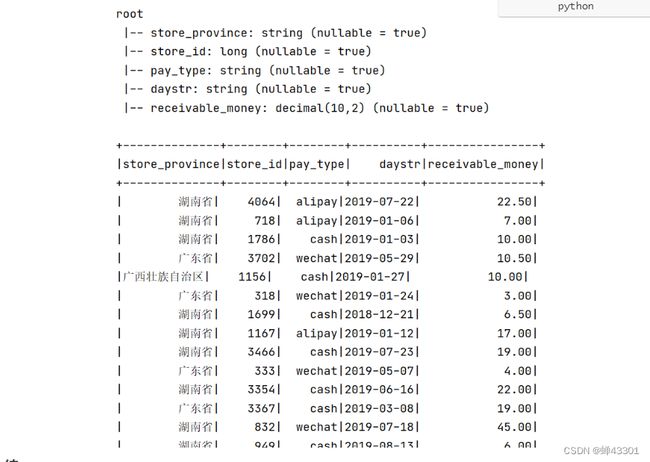
1.9.14.3 每个省份总销售额统计
目标:实现每个省份总销售额的统计
实施
需求:统计每个省份的总销售额
实现
# b.需求一:统计每个省份的销售额
rs1 = ( etl_df
# 先分组
.groupBy(F.col("store_province"))
# 再聚合
.agg(F.sum("receivable_money").alias("total_money"))
)
rs1.printSchema()
rs1.show()
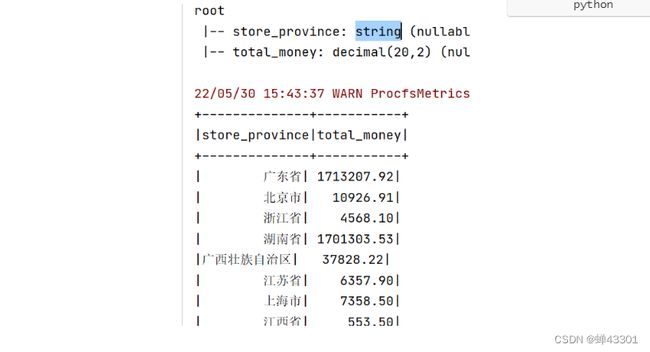
1.9.14.4 销售额Top3省份数据过滤
目标:实现销售额Top3省份的数据过滤
实施
需求:为了实现后续需求的统计,需要将销售额Top3的省份的数据过滤出来
实现
# c.过滤数据:将销售额最高的前三个省份的数据过滤出来
# 将前三个省份的名称放入一个列表中
top3_province_list = ( rs1
# 降序排序取前3
.orderBy(F.col("total_money").desc())
.limit(num=3)
# 将数据转换成RDD
.rdd
# 从每条数据中获取省份名称
.map(lambda row: row.store_province)
# 放入列表
.collect()
)
print(top3_province_list)
# 对所有数据挨个进行判断过滤,是前三个省份的数据就保留
top3_province_df = ( etl_df
# 过滤前三省份的数据:where id in (1,2,3)
.filter(F.col("store_province").isin(top3_province_list))
)
top3_province_df.printSchema()
top3_province_df.show()
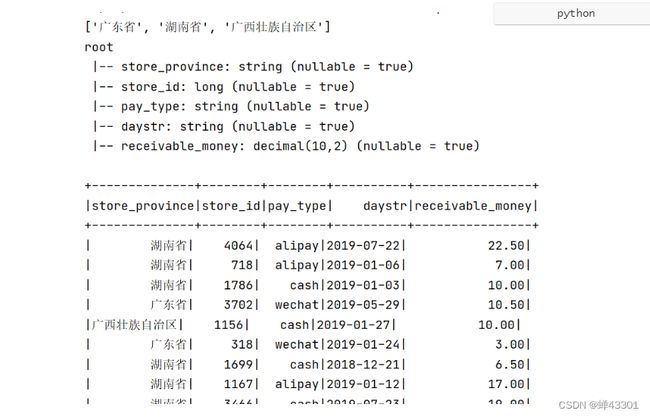
1.9.14.5 销售额Top3省份的店铺个数
目标:实现销售额Top3省份的店铺个数统计
实施
需求:统计销售额最高的前3个省份中每个省份的店铺个数,要求店铺每日销售额要高于1000
实现
# etl_df在后续不会再出现,释放缓存
etl_df.unpersist(blocking=True)
# d.需求二:统计每个省份每天营业额都超过1000的店铺个数[店铺每日的营业额超过1000才参与统计]
# 注册视图
top3_province_df.createOrReplaceTempView("tmp_view_top3_data")
# 由于视图的数据会使用多次,避免重复构建,对视图进行缓存
spark.catalog.cacheTable("tmp_view_top3_data")
# 如果这个视图不再被使用,释放缓存
# spark.catalog.uncacheTable("tmp_view_top3_data")
# 先计算每个省份每个店铺每天的营业额,将营业额高于1000的店铺过滤出来,再统计每个省份的店铺个数
rs2 = spark.sql("""
with tmp as (
select
store_province, store_id, daystr,
sum(receivable_money) as total_money
from tmp_view_top3_data
group by store_province, store_id, daystr
having total_money > 1000
)
select
store_province,
count(distinct store_id) as store_cnt
from tmp
group by store_province
""")
rs2.printSchema()
rs2.show()
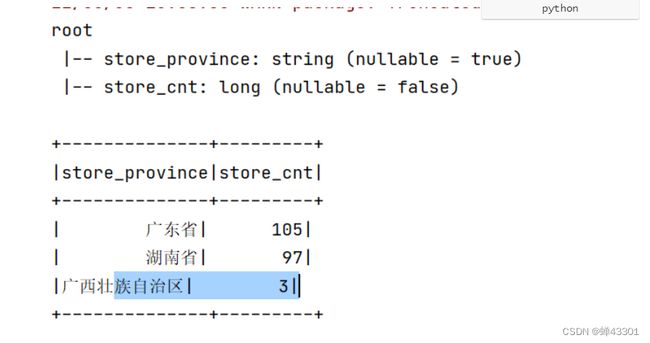
1.9.14.6 销售额Top3省份的平均订单金额
目标:实现销售额Top3省份的平均订单金额统计
实施
需求:统计Top3省份的平均每单的订单金额
实现
# e.需求三:统计这三个省份的平均订单金额
rs3 = spark.sql("""
select
store_province,
round(avg(receivable_money), 2) as avg_money
from tmp_view_top3_data
group by store_province
""")
rs3.printSchema()
rs3.show()
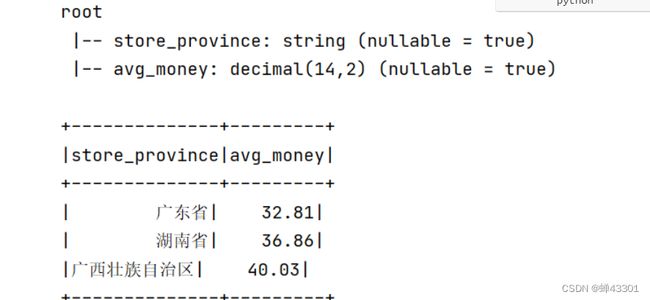
1.9.14.7 销售额Top3省份的支付类型占比
目标:实现销售额Top3省份的支付类型占比统计
实施
需求:统计销售额前3的省份,各种支付方式类型的占比
省份 支付方式 支付类型订单个数
| 将每个省份所有类型的订单个数相加就是总订单个数
省份 支付方式 支付类型订单个数 总订单个数
| 支付类型订单个数 / 总订单个数
省份 支付方式 占比
3 4 = 12条
实现
# f.需求4:统计每个省份每种支付方式订单占比
"""
广东省 支付宝 10
广东省 微信 10
广东省 银行卡 10
广东省 现金 10
|
广东省 支付宝 10 40
广东省 微信 10 40
广东省 银行卡 10 40
广东省 现金 10 40
|
广东省 支付宝 25%
广东省 微信 25%
广东省 银行卡 25%
广东省 现金 25%
"""
rs4 = spark.sql("""
with tmp1 as (
select
store_province, pay_type,
count(1) as cnt
from tmp_view_top3_data
group by store_province, pay_type
),
tmp2 as (
select
tmp1.*,
sum(cnt) over (partition by store_province) as all_total
from tmp1
)
select
tmp2.store_province,
tmp2.pay_type,
round((tmp2.cnt / tmp2.all_total), 2) as rate
from tmp2
""")
rs4.printSchema()
rs4.show()

完整代码:03.pyspark_sql_anlaysis_case
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark import StorageLevel
from pyspark.sql import SparkSession
import os
import pyspark.sql.functions as F
from pyspark.sql.types import DecimalType
"""
-------------------------------------------------
Description : TODO:
SourceFile : 03.pyspark_sql_anlaysis_case
Author : Frank
Date : 2022/5/30
-------------------------------------------------
"""
if __name__ == '__main__':
# todo:0-设置系统环境变量
os.environ['JAVA_HOME'] = 'D:/jdk1.8.0_241'
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.0'
os.environ['PYSPARK_PYTHON'] = 'D:/Anaconda/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/Anaconda/python.exe'
# todo:1-构建SparkSession
spark = SparkSession \
.builder \
.appName("SparkSQLAppName") \
.master("local[2]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 设置日志级别为WARN
spark.sparkContext.setLogLevel("WARN")
# todo:2-数据处理:读取、转换、保存
# step1: 读取数据
# 由于数据文件为JSON文件,直接使用JSON格式进行读取
input_df = spark.read.json("../datas/order/retail.json")
# 输出验证
# input_df.printSchema()
# input_df.show()
# step2: 处理数据
# a.数据清洗:过滤、转换
etl_df = ( input_df
# 将不需要的行或者不合法的行进行过滤:订单金额小于1万,省份不为空也不为null值:where province is not null and province != 'null'
.filter((F.col("receivable") < 10000) & (F.col("storeProvince").isNotNull()) & (F.col("storeProvince") != 'null'))
# 仅保留需要用到的列:省份、店铺id、天、金额、支付方式,并且实现对应的转换
.select(
# 更换命名规则
F.col("storeProvince").alias("store_province"),
F.col("storeID").alias("store_id"),
F.col("payType").alias("pay_type"),
# 将时间戳转换为日期获取年月日yyyy-MM-dd = from_unixtime(时间戳[秒],转换后的格式)
F.from_unixtime(F.substring(F.col("dateTs"), 0, 10), "yyyy-MM-dd").alias("daystr"),
# 将receivable金额转换为Decimal类型
F.col("receivable").cast(DecimalType(10, 2)).alias("receivable_money")
)
)
# etl_df.printSchema()
# etl_df.show()
# 由于etl的结果需要使用多次, 为了避免重复构建影响性能,可以缓存
etl_df.persist(StorageLevel.MEMORY_AND_DISK)
# b.需求一:统计每个省份的销售额
rs1 = ( etl_df
# 先分组
.groupBy(F.col("store_province"))
# 再聚合
.agg(F.sum("receivable_money").alias("total_money"))
)
# rs1.printSchema()
# rs1.show()
# c.过滤数据:将销售额最高的前三个省份的数据过滤出来
# 将前三个省份的名称放入一个列表中
top3_province_list = ( rs1
# 降序排序取前3
.orderBy(F.col("total_money").desc())
.limit(num=3)
# 将数据转换成RDD
.rdd
# 从每条数据中获取省份名称
.map(lambda row: row.store_province)
# 放入列表
.collect()
)
# print(top3_province_list)
# 对所有数据挨个进行判断过滤,是前三个省份的数据就保留
top3_province_df = ( etl_df
# 过滤前三省份的数据:where id in (1,2,3)
.filter(F.col("store_province").isin(top3_province_list))
)
# top3_province_df.printSchema()
# top3_province_df.show()
# etl_df在后续不会再出现,释放缓存
etl_df.unpersist(blocking=True)
# d.需求二:统计每个省份每天营业额都超过1000的店铺个数[店铺每日的营业额超过1000才参与统计]
# 注册视图
top3_province_df.createOrReplaceTempView("tmp_view_top3_data")
# 由于视图的数据会使用多次,避免重复构建,对视图进行缓存
spark.catalog.cacheTable("tmp_view_top3_data")
# 如果这个视图不再被使用,释放缓存
# spark.catalog.uncacheTable("tmp_view_top3_data")
# 先计算每个省份每个店铺每天的营业额,将营业额高于1000的店铺过滤出来,再统计每个省份的店铺个数
rs2 = spark.sql("""
with tmp as (
select
store_province, store_id, daystr,
sum(receivable_money) as total_money
from tmp_view_top3_data
group by store_province, store_id, daystr
having total_money > 1000
)
select
store_province,
count(distinct store_id) as store_cnt
from tmp
group by store_province
""")
# rs2.printSchema()
# rs2.show()
# e.需求三:统计这三个省份的平均订单金额
rs3 = spark.sql("""
select
store_province,
round(avg(receivable_money), 2) as avg_money
from tmp_view_top3_data
group by store_province
""")
# rs3.printSchema()
# rs3.show()
# f.需求4:统计每个省份每种支付方式订单占比
"""
广东省 支付宝 10
广东省 微信 10
广东省 银行卡 10
广东省 现金 10
|
广东省 支付宝 10 40
广东省 微信 10 40
广东省 银行卡 10 40
广东省 现金 10 40
|
广东省 支付宝 25%
广东省 微信 25%
广东省 银行卡 25%
广东省 现金 25%
"""
rs4 = spark.sql("""
with tmp1 as (
select
store_province, pay_type,
count(1) as cnt
from tmp_view_top3_data
group by store_province, pay_type
),
tmp2 as (
select
tmp1.*,
sum(cnt) over (partition by store_province) as all_total
from tmp1
)
select
tmp2.store_province,
tmp2.pay_type,
round((tmp2.cnt / tmp2.all_total), 2) as rate
from tmp2
""")
rs4.printSchema()
rs4.show()
# step3: 保存结果
# todo:3-关闭SparkSession
spark.stop()
1.9.15 SparkSQL使用方式及优化
1.9.15.1 spark-sql脚本的使用
目标:掌握spark-sql脚本的使用
实施
问题:平常做SQL测试,能不能像Hive中一样,直接启动一个命令行做测试?
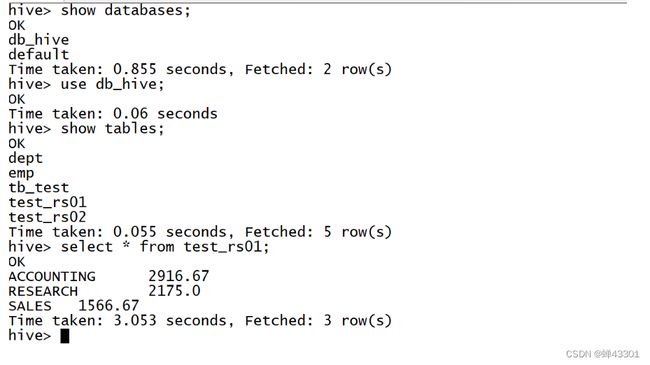
spark-sql脚本:类似于Hive中的hive脚本
启动
# 启动HDFS服务:NameNode和DataNodes
start-dfs.sh
start-yarn.sh
# 启动HiveMetaStore 服务
start-metastore.sh
# 设置Spark日志级别
cd /export/server/spark-local/conf/
mv log4j.properties.template log4j.properties
vim log4j.properties
#修改INFO为WARN
log4j.rootCategory=WARN, console
# 启动spark-sql命令行
/export/server/spark-local/bin/spark-sql --master local[2] --conf spark.sql.shuffle.partitions=2
使用
spark-sql> show databases ;
spark-sql> use db_hive ;
spark-sql> show tables ;
spark-sql> select * from db_hive.emp ;
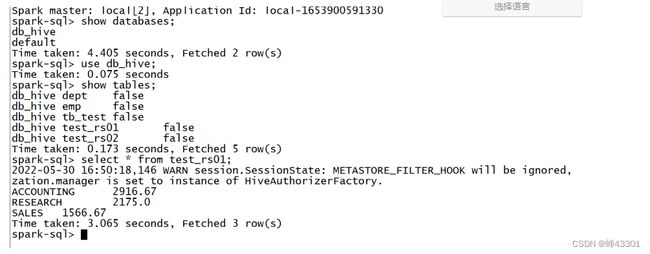
场景:交互性不够友好,一般不用于做测试,用于执行SQL脚本
1.9.15.2 ThriftServer的使用
目标:掌握ThriftServer的使用
实施
问题:Hive中可以使用Beeline或者DataGrip连接HiveServer进行测试,那SparkSQL中如何实现?
ThriftServer
功能:类似于HiveServer2,负责解析客户端提交的SQL语句,转换成Spark的任务进行执行
本质:Spark中的一个特殊的程序,利用程序的资源运行所有SQL,该程序除非手动关闭,否则一直运行
启动
/export/server/spark-local/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10001 \
--hiveconf hive.server2.thrift.bind.host=node1.itcast.cn \
--master local[2] \
--conf spark.sql.shuffle.partitions=2
关闭
/export/server/spark-local/sbin/stop-thriftserver.sh
监控
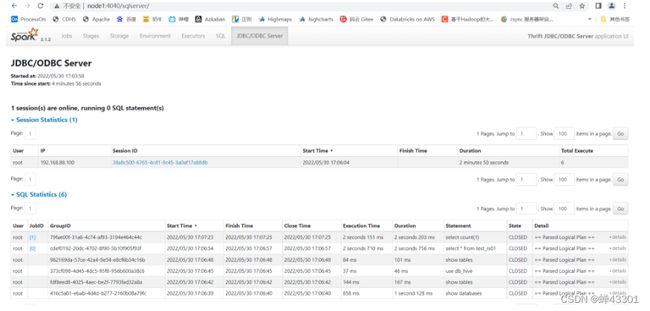
Beeline:beeline -u jdbc:hive2://node1:10001 -n root -p 123456
show databases;
use db_hive;
show tables;
select * from emp;
DataGrip
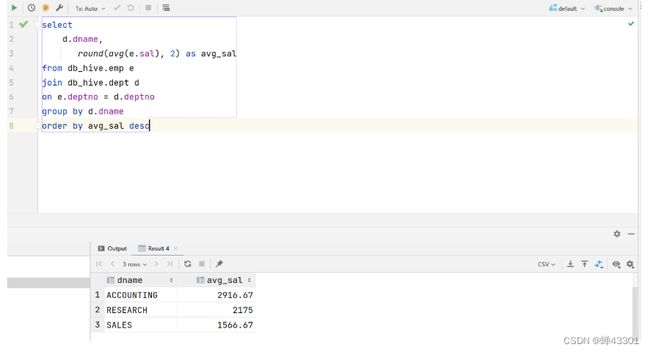
select
d.dname,
round(avg(e.sal), 2) as avg_sal
from db_hive.emp e
join db_hive.dept d
on e.deptno = d.deptno
group by d.dname
order by avg_sal desc
1.9.15.3 工作中不同场景下的使用方式
目标:掌握SparkSQL不同场景下的使用方式
实施
问题:工作中怎么用SparkSQL?
开发测试场景
方式一:启动ThriftServer,使用Beeline或者DataGrip连接ThriftServer,测试SQL语句的开发
数据源主要用于对Hive表做处理
产生:SQL语句
方式二:启动Pycharm,使用Python代码在本地运行或者远程提交,测试SQL或者DSL的开发
数据源多样化:Hive表、MySQL、结构化文件
产出:Python文件
生产场景
方式一:Pycharm中开发SparkSQL程序完毕以后,使用spark-submit脚本提交运行Python代码【SQL或者DSL】
/export/server/spark-yarn/bin/spark-submit \
--master yarn \
--deploy-mode client \
--conf "spark.pyspark.driver.python=/export/server/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/export/server/anaconda3/bin/python3" \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
开发的Python程序.py \
参数……
方式二:将测试好的SQL语句封装到一个SQL文件中,使用spark-sql运行SQL文件【仅SQL】
SQL文件:vim /export/data/spark-app.sql
show databases;
use db_hive;
show tables;
select * from emp;
create table test_rs03
select
d.dname,
round(avg(e.sal), 2) as avg_sal
from db_hive.emp e
join db_hive.dept d
on e.deptno = d.deptno
group by d.dname
order by avg_sal desc;
spark-sql运行
# 运行SQL文件
/export/server/spark-local/bin/spark-sql --master yarn -f /export/data/spark-app.sql

1.9.15.4 Spark总结优化及数据倾斜
目标:理解Spark优化及数据倾斜
实施
参数优化
Shuffle中参数
# 开启Shuffle过程中的压缩
spark.shuffle.compress = true
# 是否开启shuffle block file的合并,默认为false
spark.shuffle.consolidateFiles = true
# reduce task的拉取缓存,默认48m
spark.reducer.maxSizeInFlight = 96
# map task的写磁盘缓存,默认32k
spark.shuffle.file.buffer = 64
# 拉取失败的最大重试次数,默认3次
spark.shuffle.io.maxRetries = 5
# 拉取失败的重试间隔,默认5s
spark.shuffle.io.retryWait = 3
# 用于reduce端聚合的内存比例,默认0.2,超过比例就会溢出到磁盘上
spark.shuffle.memoryFraction = 0.4
其他参数
# 指定Spark的Shuffle过程中Task的默认并行度
spark.default.parallelism = 500
# 指定Spark中默认的压缩格式
spark.io.compression.codec = lz4
# 开启广播变量的压缩
spark.broadcast.compress = true
# 开启Checkpoint的压缩
spark.checkpoint.compress = true
# 指定SparkSQL中parquet格式的压缩类型
spark.sql.parquet.compression.codec = snappy
# 指定Spark序列化的类型
spark.serializer = org.apache.spark.serializer.KryoSerializer
# 关闭Spark自带的parquet解析
spark.sql.hive.convertMetastoreParquet = false
开发优化
RDD/DSL
- 避免创建重复的RDD:同样的一份数据只构建一个RDD
- 尽可能复用同一个RDD:尽量使用已有的RDD构建得到想要的数据,减少RDD个数
- 对多次使用的RDD进行persist持久化缓存
- 聚合数据后降低RDD分区数
- persist后及时unpersist
- 尽量避免使用shuffle类的宽依赖算子
- 优先使用map-side预聚合的shuffle操作
- 优先使用高性能的算子:分区操作算子xxxxPartition,repartitionAndSortWithinPartitions算子代替repartition+sort
- 广播较大的非RDD的数据变量
- SQL:遵循谓词下推的原则
设计优化
分区表、列式存储、合适的压缩
数据倾斜
-
现象:部分Task执行时间过长
-
定位:从4040监控中看到某个Stage中的Task运行时间远高于别的Task
-
原因:数据分配不均衡
-
解决
-
提高Shuffle过程中的并行度
-
选用带有分区内聚合的算子
-
将小表数据进行广播,实现广播Join
-
采样抽取倾斜的数据,单独Join,最后Union合并【Skew Join:内连接有效】
-
增加随机前缀
-
自定义分区器
-
小表扩大N倍,大表增加1 ~ N的随机前缀
- 小表:扩大3倍
1a
2a
3a
1b
2b
3b
1c
2c
3c
1d
2d
3d -
大表:增加1-N随机前缀,以3为例
1a
3a
1a
2a
3a
2a
2a
1b
3c
SparkSQL要点
理论
SparkSQL的功能和应用场景:结构化数据,对各种结构化数据做处理,Hive数仓进行构建
DataFrame的设计:DataFrame和RDD的区别
DataFrame和RDD转换
技术
SparkSQL开发规则:SparkSession
SQL语法:注册视图、spark.sql
DSL语法:select、where、groupBy
常见数据源读写
UDF定义
使用方式