Java常见ID生成方式比较
1、为什么需要分布式全局唯一ID
在单体架构环境下UUID或者auto_increment即可满足,保证ID的全局唯一,随着业务的发展,分布式微服务架构,导致UUID或者auto_increment不能保证全局的唯一,这就带来了需要生成全局唯一的分布式ID的需求。
2、ID生成规则要求
1、全局唯一,不能出现重复ID,用来标识唯一。
2、趋势递增,Mysql的InnoDB引擎使用的是聚簇索引,由于多数RDBMS使用Btree的数据结构存储索引数据,主键有序可以提高写入性能。
3、单调递增,主键ID单调递增,利于后续排序等功能。
4、信息安全,连续的ID容易暴露交易信息,如果是订单号就可以推出订单量等信息,一些场景下的无规则才能保证信息安全,不容易泄露。
5、含时间戳,时间戳有利于统计,问题定位分析等。
3、分布式ID常见生成方案
3.1、UUID
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符。
UUID是16字节128位长的数字,通常以36字节的字符串表示,示例如下:
3F2504E0-4F89-11D3-9A0C-0305E82C3301
其中的字母是16进制表示,大小写无关。
Java:jdk1.5以上支持UUID
import java.util.UUID;
String uuid = UUID.randomUUID().toString();优点:性能高,唯一性,没有网络消耗。
缺点:无序,过长。
3.2、数据库自增主键
优点:有序,递增,唯一
缺点:集群分布式下需要设置不同的增长步长。
3.3、利用Redis生成id
优点:Redis单线程天生保证原子性,可以使用INCR与INCRBY来实现,适合分布式集群,全局唯一,有序递增。
缺点:要单独维护Redis集群,并保证高可用,维护成本高。与MySQL相同集群分布式下需要设置不同的增长步长同时key要设置有限期。比如一个集群5台Redis,初始化Redis值分别是1,2,3,4,5,然后步长都是5。
import cn.jiqistudy.redis_1.Redis1Application;
import cn.jiqistudy.redis_1.pojo.User;
import cn.jiqistudy.redis_1.service.UserService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Redis1Application.class)
public class Test_8 {
private static final Logger log = LoggerFactory.getLogger(UserService.class);
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final String ID_KEY = "id:generator:user";
/**
* 生成全局唯一id
*/
@Test
public void incrementId() {
for (int i = 0; i <100 ; i++) {
//步骤1:生成分布式id
long id=this.stringRedisTemplate.opsForValue().increment(ID_KEY);
System.out.println(id);
//全局id,代替数据库的自增id
User user = new User();
user.setId(id);
//步骤2:取模,计算表名
//类似于海量的数据,例如淘宝一般是分为1024张表,这里为了演示方便,只分为8张表。
int table=(int)id % 8;
String tablename="user_"+table;
log.info("插入表名{},插入内容{}",tablename,user);
}
}
}3.4、雪花算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。
使用hutool包生成:
cn.hutool
hutool-all
5.4.2
cn.hutool.core.lang.Snowflake
public synchronized long nextId() {
// 获取当前时间戳
long timestamp = genTime();
// lastTimestamp表示你的程序在最后一次获取分布式唯一标识的时间戳(ms)
// 一台机器正常情况下,timestamp 是要大于 lastTimestamp的.如果timestamp < lastTimestamp表明服务器的时间有问题,存在时钟后退.
if (timestamp < lastTimestamp) {
// 容忍2秒内的时钟后退
if(lastTimestamp - timestamp < 2000){
timestamp = lastTimestamp;
} else{
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
}
if (timestamp == lastTimestamp) {
// 相同毫秒内,序列号自增
sequence = (sequence + 1) & sequenceMask;
// 同一毫秒的序列数已经达到最大
if (sequence == 0) {
// 循环等待下一个时间
timestamp = tilNextMillis(lastTimestamp);
}
} else {// timestamp > lastTimestamp
// 不同毫秒内, 序列号置为0
sequence = 0L;
}
lastTimestamp = timestamp;
// 通过按位或将各个部分拼接起来
return ((timestamp - twepoch) << timestampLeftShift) // 时间戳部分
| (dataCenterId << dataCenterIdShift) // 数据中心部分
| (workerId << workerIdShift) // 机器标识部分
| sequence; // 序列号部分
}
优点:
(1)高性能高可用:生成时不依赖于数据库,完全在内存中生成。
(2)容量大:每秒中能生成数百万的自增ID。
(3)节省空间:生成64位id,只占用8个字节节省存储空间。
(4)ID趋势自增:存入数据库中,索引效率高。
缺点:依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成id冲突或者重复。
3.5、美团Leaf分布式ID生成系统
①Leaf-segment数据库方案
在使用数据库的方案上,做了如下改变:
- 原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
- 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
下表为数据库设计:
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step。
架构图:

test_tag在第一台Leaf机器上是1-1000的号段,当这个号段用完时,会去加载另一个长度为step=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是3001~4000。同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000,更新号段的SQL语句如下:
Begin
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx
SELECT tag, max_id, step FROM table WHERE biz_tag=xxx
Commit
优点:
- Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来。
缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
- DB宕机会造成整个系统不可用。
②Leaf-snowflake方案
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,我们提供了 Leaf-snowflake方案。
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。Leaf-snowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
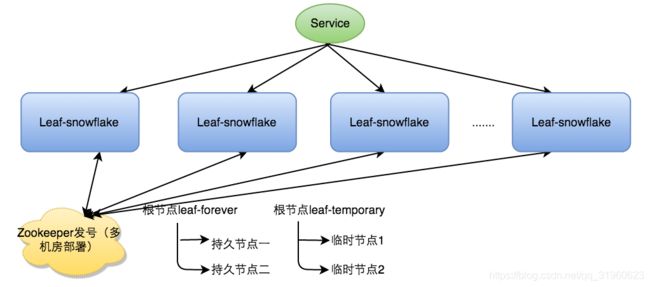
但Leaf-snowflake对Zookeeper是一种弱依赖关系,除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。一旦ZooKeeper出现问题,恰好机器出现故障需重启时,依然能够保证服务正常启动。
启动Leaf-snowflake模式也比较简单,起动本地ZooKeeper,修改一下项目中的leaf.properties文件,关闭leaf.segment模式,启用leaf.snowflake模式即可。
leaf.segment.enable=false
#leaf.jdbc.url=jdbc:mysql://127.0.0.1:3306/xin-master?useUnicode=true&characterEncoding=utf8
#leaf.jdbc.username=junkang
#leaf.jdbc.password=junkang
leaf.snowflake.enable=true
leaf.snowflake.zk.address=127.0.0.1
leaf.snowflake.port=2181 /**
* 雪花算法模式
* @param key
* @return
*/
@RequestMapping(value = "/api/snowflake/get/{key}")
public String getSnowflakeId(@PathVariable("key") String key) {
return get(key, snowflakeService.getId(key));
}优点:ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
缺点:依赖ZooKeeper,存在服务不可用风险
参考:美团(Leaf)分布式ID算法_wh柒八九的博客-CSDN博客_美团leaf算法
微服务 分布式ID生成方式雪花算法_靖节先生的博客-CSDN博客_分布式id生成雪花算法
redis 实现分布式全局唯一id_小哇666的博客-CSDN博客_redis生成全局唯一id
hutool工具中的雪花算法_书唐瑞的博客-CSDN博客_hutool雪花算法