【python】我用python写了一个可以批量查询文章质量分的小项目(纯python、flask+html、打包成exe文件)
web 效果预览:
文章目录
- 一、API 分析
-
- 1.1 质量分查询
- 1.2 文章url获取
- 二、代码实现
-
- 2.1 Python
-
- 2.11 分步实现
- 2.12 一步完成
- 2.13 完整代码
- 2.2 python + html
-
- 2.21 在本地运行
- 2.22 打打包成exe文件
- 2.23 部署到服务器
一、API 分析
1.1 质量分查询
先去质量查询地址:https://www.csdn.net/qc
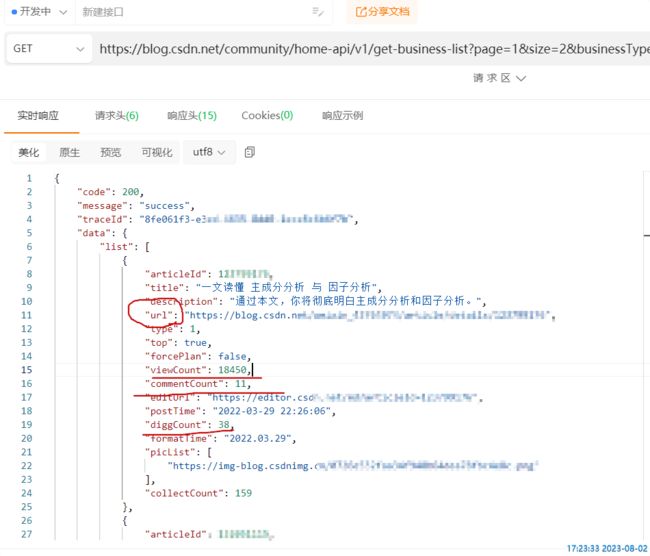
输入任意一篇文章地址进行查询,同时检查页面,在Network选项下即可看到调用的API的请求地址、请求方法、请求头、请求体等内容:

请求头里面很多参数是不需要的,我们用ApiPost这个软件来测试哪些是必要参数。
经过测试,请求头只需要下面这几个参数即可。

请求体是:
url:文章地址
测试结果:

文章质量分查询的问题已经解决了。下面来批量获取文章的URL。
1.2 文章url获取
点击个人主页,开启检查,然后点击主页的文章选项。
在这个选项下即可看到返回的文章列表:

方法是:GET
请求URL:
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=id
参数说明:
- page:请求的页面数
- size:每页数量
- username:你的csdn
id
测试结果:可以返回每篇文章的地址、阅读量、评论量等数据。
二、代码实现
2.1 Python
2.11 分步实现
为了便于理解,把程序分为2个部分:
- 批量获取文章信息,保存为excel文件;
- 从excel中读取文章url,查询质量分,再将质量分添加到excel。
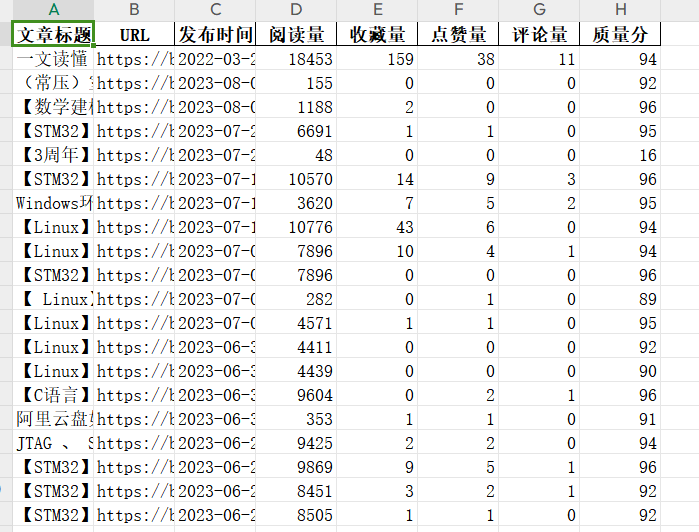
批量获取文章信息:
效果(获取20篇):

代码:
# 批量获取文章信息并保存到excel
class CSDNArticleExporter:
def __init__(self, username, size, filename):
self.username = username
self.size = size
self.filename = filename
def get_articles(self):
url = f"https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size={self.size}&businessType=blog&orderby=&noMore=false&year=&month=&username={self.username}"
with urllib.request.urlopen(url) as response:
data = json.loads(response.read().decode())
return data['data']['list']
def export_to_excel(self):
df = pd.DataFrame(self.get_articles())
df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']]
df.columns = ['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']
# df.to_excel(self.filename)
# 下面的代码会让excel每列都是合适的列宽,如达到最佳阅读效果
# 你只用上面的保存也是可以的
# Create a new workbook and select the active sheet
wb = Workbook()
sheet = wb.active
# Write DataFrame to sheet
for r in dataframe_to_rows(df, index=False, header=True):
sheet.append(r)
# Iterate over the columns and set column width to the max length in each column
for column in sheet.columns:
max_length = 0
column = [cell for cell in column]
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 5)
sheet.column_dimensions[column[0].column_letter].width = adjusted_width
# Save the workbook
wb.save(self.filename)
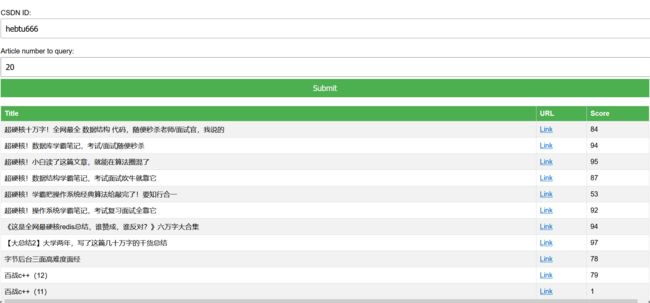
批量查询质量分:
效果:
代码:请求头的参数自己安装前面的方法获取
# 批量查询质量分
class ArticleScores:
def __init__(self, filepath):
self.filepath = filepath
@staticmethod
def get_article_score(article_url):
url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
headers = {
"Accept": "...",
"X-Ca-Key": "...",
"X-Ca-Nonce": "...",
"X-Ca-Signature": "...",
"X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce",
"X-Ca-Signed-Content-Type": "multipart/form-data",
}
data = urllib.parse.urlencode({"url": article_url}).encode()
req = urllib.request.Request(url, data=data, headers=headers)
with urllib.request.urlopen(req) as response:
return json.loads(response.read().decode())['data']['score']
def get_scores_from_excel(self):
# Read the Excel file
df = pd.read_excel(self.filepath)
# Get the 'URL' column
urls = df['URL']
# Get the score for each URL
scores = [self.get_article_score(url) for url in urls]
return scores
def write_scores_to_excel(self):
df = pd.read_excel(self.filepath)
df['质量分'] = self.get_scores_from_excel()
df.to_excel(self.filepath,index=False)
2.12 一步完成
前面的代码还是有点臃肿的,可以在获取文章信息后,就查询出质量分,然后再把所有数据写入到excel。
这部分代码你自己实现吧。
2.13 完整代码
import urllib.request
import json
import pandas as pd
from openpyxl import Workbook, load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
# 批量获取文章信息并保存到excel
class CSDNArticleExporter:
def __init__(self, username, size, filename):
self.username = username
self.size = size
self.filename = filename
def get_articles(self):
url = f"https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size={self.size}&businessType=blog&orderby=&noMore=false&year=&month=&username={self.username}"
with urllib.request.urlopen(url) as response:
data = json.loads(response.read().decode())
return data['data']['list']
def export_to_excel(self):
df = pd.DataFrame(self.get_articles())
df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']]
df.columns = ['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']
# df.to_excel(self.filename)
# 下面的代码会让excel每列都是合适的列宽,如达到最佳阅读效果
# 你只用上面的保存也是可以的
# Create a new workbook and select the active sheet
wb = Workbook()
sheet = wb.active
# Write DataFrame to sheet
for r in dataframe_to_rows(df, index=False, header=True):
sheet.append(r)
# Iterate over the columns and set column width to the max length in each column
for column in sheet.columns:
max_length = 0
column = [cell for cell in column]
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 5)
sheet.column_dimensions[column[0].column_letter].width = adjusted_width
# Save the workbook
wb.save(self.filename)
# 批量查询质量分
class ArticleScores:
def __init__(self, filepath):
self.filepath = filepath
@staticmethod
def get_article_score(article_url):
url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
headers = {
"Accept": "...",
"X-Ca-Key": "...",
"X-Ca-Nonce": "...",
"X-Ca-Signature": "...",
"X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce",
"X-Ca-Signed-Content-Type": "multipart/form-data",
}
data = urllib.parse.urlencode({"url": article_url}).encode()
req = urllib.request.Request(url, data=data, headers=headers)
with urllib.request.urlopen(req) as response:
return json.loads(response.read().decode())['data']['score']
def get_scores_from_excel(self):
# Read the Excel file
df = pd.read_excel(self.filepath)
# Get the 'URL' column
urls = df['URL']
# Get the score for each URL
scores = [self.get_article_score(url) for url in urls]
return scores
def write_scores_to_excel(self):
df = pd.read_excel(self.filepath)
df['质量分'] = self.get_scores_from_excel()
df.to_excel(self.filepath,index=False)
if __name__ == '__main__':
# 获取文章信息
exporter = CSDNArticleExporter(你的csdn id, 要查询的文章数量, 'score.xlsx') # Replace with your username
exporter.export_to_excel()
# 批量获取质量分
score = ArticleScores('score.xlsx')
score.write_scores_to_excel()
2.2 python + html
思路:
-
用户输入:首先,我们需要获取用户的输入。在这个项目中,用户需要输入他们的CSDN用户名和他们想要获取的文章数量。我们使用HTML的
元素来创建输入框,让用户输入这些信息。 -
获取文章信息:当用户点击"Submit"按钮时,我们使用jQuery的
$.getJSON()函数来发送一个GET请求到CSDN的API。这个API返回一个包含用户文章信息的JSON对象。我们从这个对象中提取出我们需要的信息,包括文章的标题、URL和分数。 -
获取文章分数:为了获取每篇文章的分数,我们需要发送一个POST请求到我们自己的服务器。我们的服务器会接收到这个请求,然后发送一个POST请求到CSDN的另一个API来获取文章的分数。这个API返回一个包含文章分数的JSON对象。我们的服务器将这个分数返回给前端。
-
显示结果:最后,我们在网页上显示获取到的文章信息。我们创建一个HTML表格,每行显示一篇文章的信息。我们使用jQuery的
$.when.apply()函数来确保所有的POST请求都完成后再显示结果。这是因为POST请求是异步的,如果我们不等待所有的请求都完成,我们可能会在某些文章的分数还没有获取到时就显示结果。
2.21 在本地运行
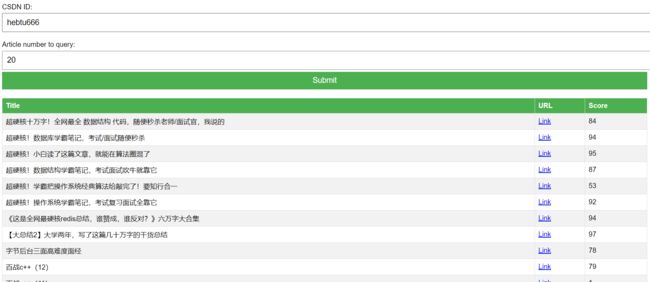
先看效果: 这是兔老大的博客质量分
创建一个Flask应用,并定义一个路由’/',它对GET和POST请求做出响应。对于GET请求,它返回一个HTML表单。对于POST请求,它获取表单中的username和size,然后获取相应的文章,并将它们显示在屏幕上。
app.py:请求头的参数依旧是自己去获取
from flask import Flask, request, jsonify
from flask_cors import CORS
import urllib.request
import json
app = Flask(__name__)
CORS(app)
@app.route('/get_score', methods=['POST'])
def get_score():
article_url = request.json['url']
url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"
headers = {
"Accept": "application/json, text/plain, */*",
"X-Ca-Key": "...",
"X-Ca-Nonce": "....",
"X-Ca-Signature": "....",
"X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce",
"X-Ca-Signed-Content-Type": "multipart/form-data",
}
data = urllib.parse.urlencode({"url": article_url}).encode()
req = urllib.request.Request(url, data=data, headers=headers)
with urllib.request.urlopen(req) as response:
score = json.loads(response.read().decode())['data']['score']
return jsonify(score=score)
if __name__ == '__main__':
app.run(debug=True)
html 可视化:
DOCTYPE html>
<html>
<head>
<title>CSDN Article Infotitle>
<style>
body {
font-family: Arial, sans-serif;
}
form {
margin-bottom: 20px;
}
label {
display: block;
margin-top: 20px;
}
input, button {
width: 100%;
padding: 10px;
margin-top: 5px;
font-size: 18px;
}
button {
background-color: #4CAF50;
color: white;
border: none;
cursor: pointer;
}
button:hover {
background-color: #45a049;
}
table {
width: 100%;
border-collapse: collapse;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
tr:nth-child(even) {
background-color: #f2f2f2;
}
th {
background-color: #4CAF50;
color: white;
}
style>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js">script>
<script>
$(document).ready(function(){
$("#submit").click(function(event){
event.preventDefault();
var username = $("#username").val();
var size = $("#size").val();
var url = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=" + size + "&businessType=blog&orderby=&noMore=false&year=&month=&username=" + username;
$.getJSON(url, function(data) {
var articles = data.data.list;
var promises = [];
for (var i = 0; i < articles.length; i++) {
(function(article) {
var promise = $.ajax({
url: "http://localhost:5000/get_score",
type: "POST",
data: JSON.stringify({url: article.url}),
contentType: "application/json; charset=utf-8",
dataType: "json"
}).then(function(data){
return "" + article.title + " " +
"Link " +
"" + data.score + " Title URL Score
";
$("#result").html(html);
});
});
});
});
script>
head>
<body>
<form>
<label for="username">CSDN ID:label>
<input type="text" id="username" name="username">
<label for="size">Article number to query:label>
<input type="text" id="size" name="size">
<button id="submit">Submitbutton>
form>
<div id="result">div>
body>
html>
使用方法:
先运行app.py,再打开html即可。
也可以在命令行运行,先进入app.py所在的目录,地址栏输入cmd(powershell这些也可以),回车即可,我这个代码用的是conda虚拟环境,所以先进入虚拟环境:
conda activate first_env
然后运行app.py即可:
python app.py
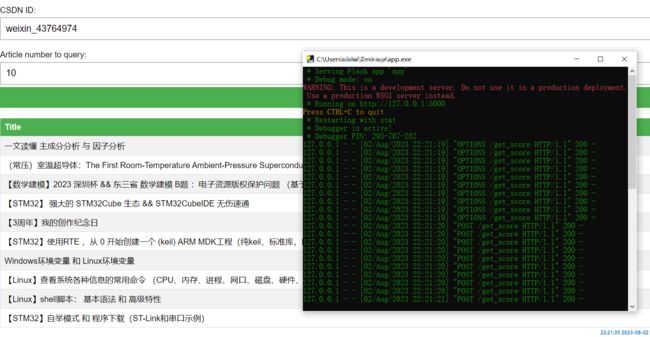
最后打开html进行查询。
2.22 打打包成exe文件
我用的是conda的虚拟环境。
进入虚拟环境:
conda activate first_env
先在你目前的虚拟环境安装: pyinstaller
(只要进入这个虚拟环境,使用conda、pip都可以)
继续在命令行打包:
pyinstaller --onefile --paths=E:\anaconda3\envs\first_env\Lib\site-packages app.py
注意:
- 前面的路径是我的python程序运行的虚拟环境(first_env),我在里面已经安装了相关的模块,比如flask;
- 这个命令是在app.py所在目录下运行,并且是进入虚拟环境了。
打包完成后:在dist目录下即可找到这个exe文件。
打开如果显示缺失什么模块,那你就需要自己解决一下。
如果可以运行,那么就可以把这个exe移动到任意位置运行,比如我把他复制到桌面,然后双击打开即可运行。
然后浏览器打开Html就可以查询了。
2.23 部署到服务器
你也可以把它部署到服务器,以后直接用url即可打开查询页面。
感兴趣的自己部署吧。
把 永 远 爱 你 写 进 诗 的 结 尾 ~