6.s081/6.1810(Fall 2022)Lab2: System calls
文章目录
- 前言
- 其他篇章
- 参考链接
- 0. 前置准备
- 1. System call tracing (moderate)
-
- 简单分析
- Hint 1
- Hint 2
- Hint 3
- Hint 4
- Hint 5
- 测试
- 2. Sysinfo (moderate)
-
- 声明
- 实现
-
- 框架
- 用户态与内核态交互
- 计算空闲内存的大小
- 计算非UNUSED进程的数量
- 测试
- 3. 总测试
前言
这个lab主要介绍了用户态到内核态的系统调用做了什么,并让我们照猫画虎完成了两个系统调用的实现。
其他篇章
环境搭建
Lab1: Utilities
Lab2: System calls
参考链接
官网链接
xv6手册链接,这个挺重要的,建议做lab之前最好读一读。
xv6手册中文版,这是几位先辈们的辛勤奉献来的呀!再习惯英文文档阅读我还是更喜欢中文一点,开源无敌!
OSTEP,对OS不熟悉的同学做之前可以看一下这本经典书籍,写得很好,也有中文版实体书。
官方文档
0. 前置准备
很惭愧,以前github用得少,这一步折腾了老半天,我再说一遍我个人的开发流程——先在windows下git一个本地仓库,然后用VS编辑,写完后git push上去,在WSL的对应地方git pull下来,然后编译运行。
前面环境配置中我为了连接到我个人的远程仓库,是直接把原本的远程仓库删了的,然后lab1做完做到lab2发现这个lab整体不是循序渐进的,而是彼此分离的,每个实验需要选择相应的分支,因此就要重新弄一下:
git remote add base git://g.csail.mit.edu/xv6-labs-2022
git fetch base
git checkout syscall
git push --set-upstream origin syscall
当然,别忘了加.gitignore

1. System call tracing (moderate)
简单分析
gdb教学我就不说了,看看这个task。

先简单研究一下我们需求的这个trace是干什么的吧,trace顾名思义,tracing,追踪、寻迹的意思,比如ray tracing,就是光线追踪,这个命令接受一个传参mask,内涵是一个掩码,每一位对应一个系统调用的一个序号,比如传入32,代表 32 1<kernel/syscall.h里,我们待会也会写

初步了解之后,就写实现吧,这个task按照hint的步骤来很清晰:

Hint 1
Add $U/_trace to UPROGS in Makefile
首先添加makefile,司空见惯了。
Hint 2
Run make qemu and you will see that the compiler cannot compile user/trace.c, because the user-space stubs for the system call don’t exist yet: add a prototype for the system call to user/user.h, a stub to user/usys.pl, and a syscall number to kernel/syscall.h. The Makefile invokes the perl script user/usys.pl, which produces user/usys.S, the actual system call stubs, which use the RISC-V ecall instruction to transition to the kernel. Once you fix the compilation issues, run trace 32 grep hello README; it will fail because you haven’t implemented the system call in the kernel yet.
然后说这个时候make,会找不到trace,我们要在用户态user/user.h里加上trace的声明,根据原文 It should take one argument, an integer “mask”, whose bits specify which system calls to trace. 可知,这玩意应该接受一个int,然后返回也是一个int(返回值其实不影响来着):
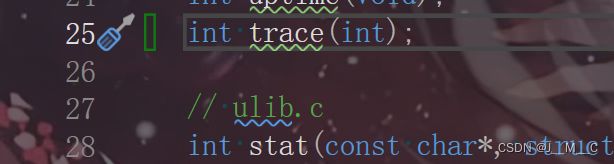
然后我们在user/usys.pl下添加这么一行,这是个Perl脚本,即使没有用过Perl的同学应该也能看出来这里的意思是声明了一个trace系统调用的入口,再通过上文展开为我们在usys.S中生成一段汇编代码。

然后在内核syscall.h中给它注册一个number

Hint 3
Add a sys_trace() function in kernel/sysproc.c that implements the new system call by remembering its argument in a new variable in the proc structure (see kernel/proc.h). The functions to retrieve system call arguments from user space are in kernel/syscall.c, and you can see examples of their use in kernel/sysproc.c.
然后模仿着添加原型?
这里简单解释一下后面这个syscalls数组,可能很多人没有看懂这,首先这是个static的不用说,然后这是个函数指针的数组(我一向很反感那些什么数组指针指针数组混着说的,直接说成装指针的数组不就一目了然了吗),函数返回值为uint64,参数为void,显然是为上面extern的那些函数准备的东西,这些都比较简单,后面的是个小feature了,它本身叫作指派初始化器(Designated Initializers),来自C99,意思就是给方括号里的那一位初始化为右边的值

但是可以看到,C99的指派初始化器的形式是[N] = expr的,中间需要一个等号连接,这里没有,它是来自GCC私货,原文出现在介绍指定初始化器的时候:An alternative syntax for this that has been obsolete since GCC 2.5 but GCC still accepts is to write ‘[index]’ before the element value, with no ‘=’. 意味着大家在自己使用时加个等号是更符合standard的写法。

然后叫我们仿照着kernel/sysproc.c里的其他函数给trace写一个定义进去:
uint64
sys_trace(void)
{
return 0;
}
使用argint从寄存器取出用户传入的参数:
int mask;
argint(0, &mask); // 保存用户传入的参数
然后我们要把接到的这个mask保存到进程的元数据中,根据原文Add a sys_trace() function in kernel/sysproc.c that implements the new system call by remembering its argument in a new variable in the proc structure (see kernel/proc.h). T 我们在kernel/proc.h中可以找到一个结构体struct proc
很显然这个结构体记录着一些元数据,我们在这个基础上再添加一条承载mask的:
int traceMask; // 用于接收trace的mask
显然每一个进程都有一个独属于自己的proc对象,我们可以通过myproc()来获取这个对象的指针,就此我们可以完成我们的sys_trace定义:
uint64
sys_trace(void)
{
argint(0, &myproc()->mask); // 尝试从用户空间读取参数
return 0;
}
Hint 4
Modify fork() (see kernel/proc.c) to copy the trace mask from the parent to the child process.
我们知道fork出的子进程会复制父进程的内存空间,根据hint我们可以找到它的实现:
可以看到,这里明显是要做一个p到np的拷贝,p指向的是父进程的proc对象,np则应该是new proc的缩写了:

我们这个mask的修改不需要持有锁,因此只需要在alloc之后的合适时机将父进程的值赋出即可:

既然提到了alloc,这里刚好就可以想到一个问题——资源的分配与释放呢?我们知道C语言访问未初始化变量的行为是UB,那么我们默认状态下的mask进行初始化了吗?在上面那张图里我们可以清晰地看到(或者说猜到)内核依赖allocproc分配内存,依赖freeproc释放内存,因此我们可以直接F12进去看一看实现:
如图,我们可以很容易地为mask初始化以及释放时赋0值。
Hint 5
Modify the syscall() function in kernel/syscall.c to print the trace output. You will need to add an array of syscall names to index into.
然后我们为syscall这个总体的函数实现我们的功能,也就是前文中的那些打印:

我们分析一下需要做的事情:当我们进行了trace调用时,我们应当追踪mask标记的所有调用,并打印出4: syscall close -> 0这样的内容,不难看出,打印内容分为三部分:PID、系统调用的名称与系统调用的返回值,其中pid我们可以通过读取proc来获取,返回值实际在框架中都告诉你了:
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
可以看到,系统调用的返回值被保存在了寄存器a0中,至于系统调用的名称呢?C语言中没有反射,我们就只好提前建立一张syscall的名称表,再根据mask去寻址:
// 系统调用的名称
static const char *syscallnames[] = {
[SYS_fork] "fork",
[SYS_exit] "exit",
[SYS_wait] "wait",
[SYS_pipe] "pipe",
[SYS_read] "read",
[SYS_kill] "kill",
[SYS_exec] "exec",
[SYS_fstat] "fstat",
[SYS_chdir] "chdir",
[SYS_dup] "dup",
[SYS_getpid] "getpid",
[SYS_sbrk] "sbrk",
[SYS_sleep] "sleep",
[SYS_uptime] "uptime",
[SYS_open] "open",
[SYS_write] "write",
[SYS_mknod] "mknod",
[SYS_unlink] "unlink",
[SYS_link] "link",
[SYS_mkdir] "mkdir",
[SYS_close] "close",
[SYS_trace] "trace",
};
搞清楚并完成了所有前置工作我们就可以开始写逻辑了,最后的syscall函数代码,很简单:
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
// Use num to lookup the system call function for num, call it,
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
if ((p->mask >> num) & 1) { // 判断系统调用是否被跟踪
printf("%d: syscall %s -> %d\n",
p->pid, syscallnames[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
测试
到这里就基本完成了,还是老规矩,我们make qemu编译,然后试一试文档中的几个命令:
trace 32 grep hello README

trace 2147483647 grep hello README

grep hello README
trace 2 usertests forkforkfork # 这一条输入之后貌似要等一会才会出一大坨

…

最后跑一下总体批分./grade-lab-syscall trace

成功通过!
2. Sysinfo (moderate)
然后让我们来完成一下task2,这个是也是添加一个系统调用,叫sysinfo:
![]()
我们先搞清楚这个调用是干啥的,从介绍可以看到,这个sysinfo接收一个struct sysinfo的指针,我们就是要写这个指针指向的对象,怎么写呢?就是将空闲的字节数存到对象里的freemem字段,将state不为UNUSED的进程数量写到nproc字段。
有一个初步的印象后就可以去写实现了,整体思路和上文trace的步骤差不多:
首先是增加$U/_sysinfotest\到Makefile:

声明
在user/user.h里加声明:
syscall.h中:

syscall.c中(第三个是上面的那个名称表):
实现
框架
写完了声明,就可以写实现了,实现我们依旧写在sysproc.c下:
#include "sysinfo.h" // 由于要接收sysinfo类型的结构体,我们先include一下
uint64
sys_sysinfo(void)
{
// TODO: 从用户态到内核态
// TODO: 计算空闲内存的大小
// TODO: 计算内存中非UNUSED的进程的数量
// TODO: 从内核态到用户态
return 0;
}
关于具体实现,文档提供了三个hint,我们还是按照这三个hint的步骤去做就行了:

用户态与内核态交互
sysinfo needs to copy a struct sysinfo back to user space; see sys_fstat() (kernel/sysfile.c) and filestat() (kernel/file.c) for examples of how to do that using copyout().
首先依旧是获取入参,hint给了我们两个参考范例,我们可以看一看:

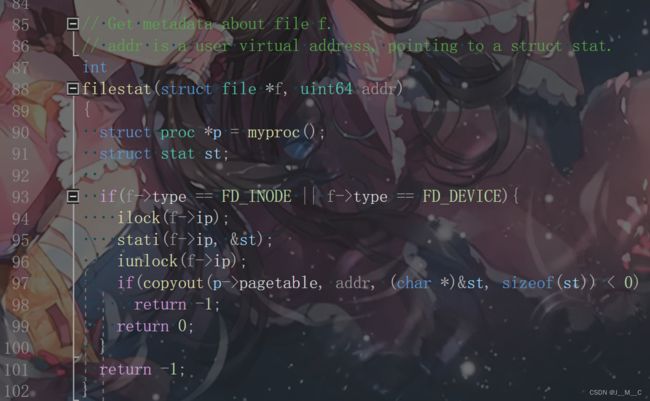
可以看(猜)到,这两个文件以struct stat类型为例子,分别向我们展示了获取类型指针的方法以及将既存对象写入获取到的指针的方法,分别使用argaddr与copyout函数实现,因此我们可以依葫芦画瓢写出以下代码:
uint64
sys_sysinfo(void)
{
uint64 addr; // 指向sysinfo结构体的指针
struct sysinfo info;
argaddr(0, &addr); // 尝试从用户空间读取参数
// TODO: 计算空闲内存的大小
// TODO: 计算内存中非UNUSED的进程的数量
if (copyout(myproc()->pagetable, addr, (char *)&info, sizeof(info)) < 0) // 将内核空间的sysinfo结构体复制到用户空间
return -1;
return 0;
}
计算空闲内存的大小
To collect the amount of free memory, add a function to kernel/kalloc.c
hint提示我们想要计算空闲内存的大小,需要在kalloc.c下添加一个函数,通过观察该文件的内容,我们不难发现,这个文件主要负责维护一个名为kmem的对象,这个名称应该是kernel memory的缩写,这个结构体内部有一个一看就是一把自旋锁的lock字段和一个一看就是负责记录空闲page的链表的freelist字段,通过综合观察我们可以知道freelist确实维护的是空闲页的数量,因此我们想要找到空闲内存的总大小,只需要遍历整个freelist,就可以找到总共空闲页的数量,而每个页有PGSIZE即4096个字节,因此我们只需要将获得的页面数乘以PGSIZE即可,于是不难写出以下代码:
// 计算空闲内存大小
uint64
kfree_mem_cnt(void)
{
struct run *r;
uint64 cnt = 0;
acquire(&kmem.lock); // 由于kmem.freelist是全局变量,所以需要加锁
r = kmem.freelist;
while(r) {
cnt++;
r = r->next;
}
release(&kmem.lock);
return cnt * PGSIZE;
}
值得一提的是,由于kmem是一个全局变量,属于临界资源,因此我们在访问时需要加锁。然后我们需要再kernel/defs.h下添加这个函数的声明,才能为我们所调用:

然后在我们的sysinfo中调用它:
uint64
sys_sysinfo(void)
{
uint64 addr; // 指向sysinfo结构体的指针
struct sysinfo info;
argaddr(0, &addr); // 尝试从用户空间读取参数
info.freemem = kfree_mem_cnt(); // 获取内存中空闲的内存大小
// TODO: 计算内存中非UNUSED的进程的数量
if (copyout(myproc()->pagetable, addr, (char *)&info, sizeof(info)) < 0) // 将内核空间的sysinfo结构体复制到用户空间
return -1;
return 0;
}
计算非UNUSED进程的数量
To collect the number of processes, add a function to kernel/proc.c
这个函数提醒我们写在kernel/proc.c中,这个文件我们上一个task其实已经接触过了,再来看一看吧。前文我们已经知道了每个进程的信息依赖proc结构体维护,进一步阅读不难发现,这里用一个全局数组来维护了我们的所有进程,因此,我们只需要遍历一遍这个数组,然后给其中非空闲的进程计数即可。
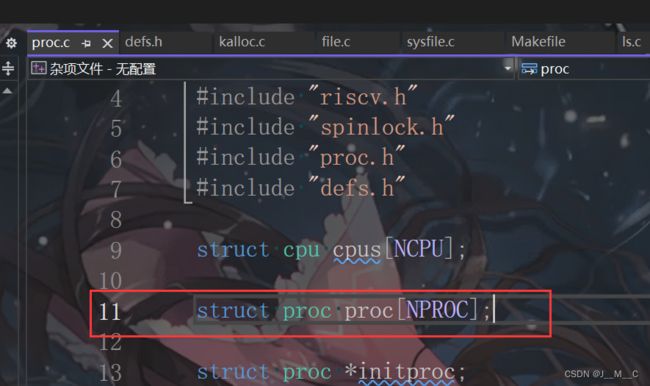
同样值得一提的是,我们翻阅struct proc的定义可以发现,注释中提示了我们,state属于临界资源,访问需要加锁:

综合上面的内容,我们就可以比较轻松地写出如下代码:
// 计算非空闲进程的数量
uint64
get_free_proc_num(void)
{
uint64 num = 0;
for(struct proc* p = proc; p < &proc[NPROC]; p++){
acquire(&p->lock); // state是临界资源,需要加锁
if (p->state != UNUSED)
num++;
release(&p->lock);
}
return num;
}
我们同样需要为它在defs.h中添加声明以供外部调用:

最后我们在sysinfo的实现中调用这个函数,完成了最终步骤:
uint64
sys_sysinfo(void)
{
uint64 addr; // 指向sysinfo结构体的指针
struct sysinfo info;
argaddr(0, &addr); // 尝试从用户空间读取参数
info.freemem = kfree_mem_cnt(); // 获取内存中空闲的内存大小
info.nproc = get_free_proc_num(); // 获取内存中非UNUSED的进程的数量
if (copyout(myproc()->pagetable, addr, (char *)&info, sizeof(info)) < 0) // 将内核空间的sysinfo结构体复制到用户空间
return -1;
return 0;
}
测试
同样的,make qemu后,按照文档中的提示运行sysinfotest,成功:

退出终端后运行./grade-lab-syscall sysinfo本地测试,成功:

3. 总测试
同样的,我们需要在根目录下创建一个time.txt,里面写上本次lab用时,比如我这个lab不算写博客花了差不多4个小时,我就写个4,然后运行make grade(跑到这一步的时候我发现gdb也叫我填一个东西在answers-syscall.txt里,答案是usertrap()),弄好后又出了个错误:
Timeout! trace children: FAIL (30.7s)
…
8: syscall fork -> -1
7: syscall fork -> -1
6: syscall fork -> -1
9: syscall fork -> -1
qemu-system-riscv64: terminating on signal 15 from pid 6958 (make)
MISSING ‘^ALL TESTS PASSED’
QEMU output saved to xv6.out.trace_children

这个主要是由于WSL性能损失的原因,之前文档也强调过这个问题了,解决方法是自己手动改测试脚本gradelib.py,放宽时间(话说上面单独跑测试都25s过了,总的测试居然过不了,还得看运气呀):
然后再跑make grade:

搞定!