LLM大模型——langchain相关知识总结
目录
- 一、简介
-
- LangChain的主要价值支柱
- 简单安装
- 二、 LangChain的主要模块
-
- 1.Model I/O
-
- prompt模版定义
- 调用语言模型
- 2. 数据连接
- 3. chains
- 4. Agents
- 5. Memory
- Callbacks
- 三、其他记录
-
- 多进程调用
主要参考以下开源文档
文档地址:https://python.langchain.com/en/latest/
学习github:https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
一、简介
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。主要有 2 个能力:
- 可以将 LLM 模型与外部数据源进行连接
- 允许与 LLM 模型进行交互
LangChain的主要价值支柱
-
组件:用于处理语言模型的抽象,以及每个抽象的实现集合。无论是否使用LangChain框架的其余部分,组件都是模块化的,易于使用。
-
现成的链:用于完成特定更高级别任务的组件的结构化组装,可以理解为一个个任务。
简单安装
pip install langchain
二、 LangChain的主要模块
1.Model I/O
提供了丰富的语言模型的借口供用户调用
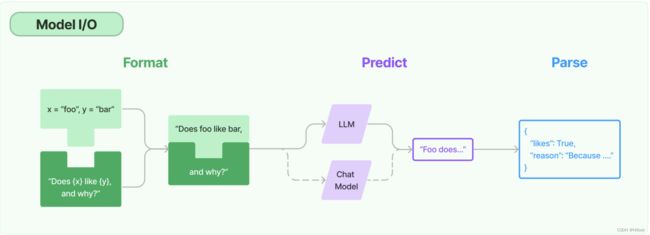
这里主要记录一波我觉得比较有用的几个点:
prompt模版定义
这个适用于批量处理某些问题,我可以定义一个模版,然后替换中间的某些内容喂入llm即可:
from langchain import PromptTemplate
template = """
你好请你回答下面的问题:
{question}?
"""
prompt = PromptTemplate.from_template(template)
prompt.format(product="question")
有时候对于一个模版,我们可能需要传递多个参数。那么可以用下面的操作:
template = """
我会给你一些例子如下:
{example},
请你参考上面的例子,回答下面的问题:
{question}?
"""
prompt = PromptTemplate(
input_variables=["example", "question"],
template=template
)
parm={"example": "xxxx", "question":"qqqqqq"}
prompt.format(**parm)
调用语言模型
这里有两种类别:一种是llm,仅以单个文本为输入;另一种是chat model,以文本列表为输入。
llm调用:openai的模型需要key,这里需要点科技,自己去openai官网申请下
import os
from langchain.llms import OpenAI
os.environ["OPENAI_API_KEY"] = '你的api key'
llm = OpenAI(model_name="text-davinci-003", max_tokens=1024)
result = llm("你是谁?")
chat model调用
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(openai_api_key="...")
result = chat([HumanMessage(content="你是谁?")])
2. 数据连接
提供了特定数据的接口,包括文档加载,文档处理,词嵌入等类,可以很方便处理输入。类似的构建基于知识库的聊天模型或者处理超长文本输入时,用这个就很方便。

这里记录一个处理超长文本输入的例子,首先使用document_loaders加载文本。如果想要用openai api输入一个超长的文本并进行返回,一旦文本超过了 api 最大的 token 限制就会报错。一个解决办法是使用text_splitter对输入进行分段,比如通过 tiktoken 计算并分割,然后将各段发送给 api 进行总结,最后将各段的总结再进行一个全部的总结。
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader("test.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')
# 加载 llm 模型
llm = OpenAI(model_name="text-davinci-003", max_tokens=1500)
# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)
# 执行总结链
chain.run(split_documents)
3. chains
结构化调用序列:虽然说单独地使用LLM对于简单的应用程序来说很方便,但有时候我们可能需要使用不同的LLM,这时候使用chain来管理就很方便了。LangChain为此类“链式”应用程序提供了Chain接口。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = OpenAI(temperature=0.95)
prompt = PromptTemplate(
input_variables=["question"],
template="回答下面问题 {question}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run("1+1=?"))
4. Agents
让链根据给定的高级指令选择使用哪些工具,这里我没怎么用过,到时候用到就看文档吧
5. Memory
在链运行之间保留应用程序状态
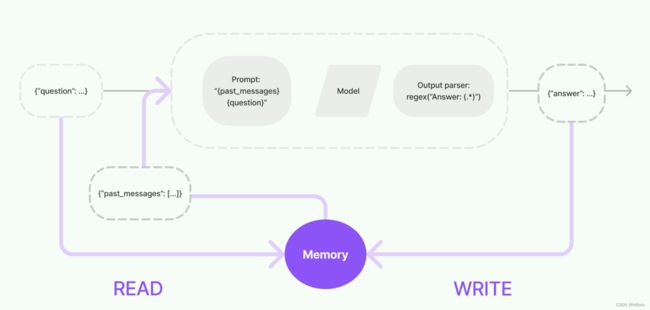
这里典型的应用就是聊天模型,我们需要记忆以往的聊天内容,用这个就比较方便了
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0.95)
template = """你是我的聊天机器人,让我们聊天吧。
历史对话内容如下:
{chat_history}
那现在新的问题如下: {question}
请你回复进行:
"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "你好"})
做个for循环重复调用即可
Callbacks
记录并流式传输任何链的中间步骤,这个回调系统允许我们挂接在LLM应用程序的各个阶段。这对于日志记录、监视、流式传输和其他任务非常有用。
三、其他记录
多进程调用
如果有一大批数据需要预测,可以使用python的多进程调用
import os
import openai
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
# 运行此API配置,需要将目录中的.env中api_key替换为自己的
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
from concurrent.futures import ProcessPoolExecutor, as_completed
import time
import collections
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试调整该参数。
# 以下的对话均无记忆,即每次调用预测不会记得之前的对话。(想要有记忆功能请看下一节的langchain的Memory模块)
chat = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
print(chat)
# 定义预测函数
def predict(params):
query, input = params
res = chat(input)
res = res.content
return query, res
# def predict(prompt):
# return prompt
def main():
start_time = time.time()
# 多进程并行预测
# 您可能需要根据自己的需求调整间隔时间。另外,您可以根据需要调整进程池的大小,以获得更好的性能。
template_string = """请回答下面的问题:{query}"""
input_data = ['1+1等于几啊?', '2+2等于几啊?', '3+3等于几啊?', '4+4等于几啊?']
prompt_template = ChatPromptTemplate.from_template(template_string)
from langchain.schema import HumanMessage, SystemMessage
system_msg = SystemMessage(content="你是一个数学家。")
print(system_msg)
# output_data = collections.defaultdict(int)
with ProcessPoolExecutor(max_workers=2) as executor:
# 异步调用(多进程并发执行)
futures = []
for query in input_data:
prompt = prompt_template.format_messages(query=query)
job = executor.submit(predict, (query, [system_msg]+prompt))
futures.append(job)
# 因为异步等待结果,返回的顺序是不定的,所以记录一下进程和输入数据的对应
query2res = collections.defaultdict(int)
# 异步等待结果(返回顺序和原数据顺序可能不一致) ,直接predict函数里返回结果?
for job in as_completed(futures):
query, res = job.result(timeout=None) # 默认timeout=None,不限时间等待结果
query2res[query] = res
time.sleep(1) # 为了避免超过OpenAI API的速率限制,每次预测之间间隔1秒
end_time = time.time()
total_run_time = round(end_time-start_time, 3)
print('Total_run_time: {} s'.format(total_run_time))
print(query2res)
# 保存结果
import pandas as pd
df = pd.DataFrame({'query': list(query2res.keys()), 'infer_result': list(query2res.values())})
df.to_excel('./chatgpt_infer_result.xlsx', index=False)