微服务——elasticsearch
初识ES——什么是elasticsearch



elasticsearch的发展



初识ES——正向索引和倒排索引


初识ES——es与mysql的概念对比

类比到mysql中是表结构约束
 概念对比
概念对比


初始ES——安装es和kibana
1.部署单点es
1.1创建网络
要安装es容器和kibana容器并让他们之间相连,这里就要先创建一个网络
docker network create es-net1.2拉取es镜像
docker pull elasticsearch:7.12.11.3运行
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1docker run -d --name es -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" -v es-data:/usr/share/elasticsearch/data -v es-plugins:/usr/share/elasticsearch/plugins --privileged --network es-net -p 9200:9200 -p 9300:9300 elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-e "discovery.type=single-node":非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
--privileged:授予逻辑卷访问权
--network es-net:加入一个名为es-net的网络中
-p 9200:9200:端口映射配置
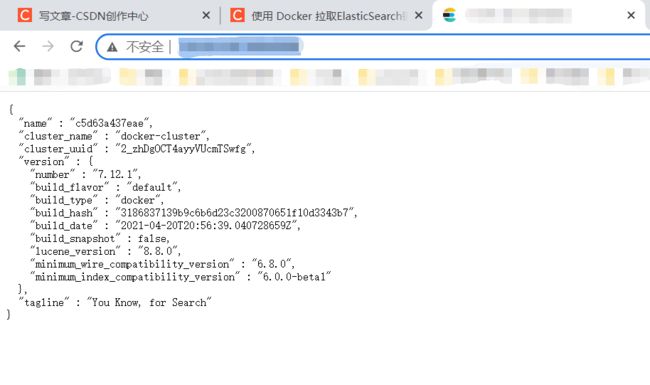
在浏览器中输入:http://xxx.xxx.xxx.xxx:9200/ 即可看到elasticsearch的响应结果:
2.部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
2.1.拉取镜像
docker pull kibana:7.12.12.2部署
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1-
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中 -
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch -
-p 5601:5601:端口映射配置
此时,在浏览器输入地址访问:http://xxx.xxx.xxx.xxx:5601,即可看到结果
2.2.DevTools
kibana中提供了一个DevTools界面:
如果一直是这个界面的话说明苟日的内存炸了.....tmd,不就是开了个nacos,rabbitmq,redis,然后就顶不住了es+kibana

正常进来之后如下
进入DevTools
下面的DSL命令就是查询es中的所有数据,

模拟发送一个GET请求,和上面的es:9200得到的东西一样。

初始ES——安装IK分词器

如下所见对中文的分词支持不友好,完全逐字来分
一般中文分词用的是IK分词器
在线安装ik插件
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "北岭山脚鼠鼠学习java"
}再次测试得到如下结果,
{
"tokens" : [
{
"token" : "北",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "岭",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "山脚",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "鼠",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "鼠",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "学习",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "java",
"start_offset" : 8,
"end_offset" : 12,
"type" : "ENGLISH",
"position" : 6
}
]
}
IK分词器的扩展和停用词典
在IK分词器的底层会依赖一个词典,比如一些网络用语组成的词语。什么鸡你太美。。。
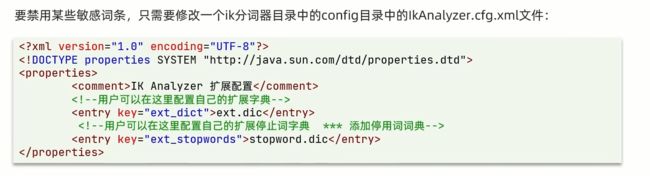
新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
奥力给
北岭山
北岭山脚鼠鼠
在 stopword.dic 添加停用词
蔡徐坤重启elasticsearch
# 重启服务
docker restart elasticsearch
docker restart kibana