pyspark学习笔记——RDD
目录
1.程序执行入口SparkContext对象
2.RDD的创建
2.1 通过并行化集合创建(本地对象 转 分布式RDD)
2.2 读取外部数据源(读取文件)
2.2.1 使用textFile API
2.2.2 wholeTextFile API
2.3 RDD算子
2.4 常用Transformation算子
2.4.1 map算子
2.4.2 flatMap算子
2.4.3 reduceByKey算子
2.4.4 mapValues算子
2.4.5 groupBy算子
2.4.6 Filter算子
2.4.7 distinct算子
2.4.8 union算子
2.4.9 join算子
2.4.10 intersection算子
2.4.11 glom算子
2.4.12 groupByKey 算子
2.4.13 sortBy算子
2.4.14 sortByKey 算子
2.5 常用的Action算子
2.5.1 countByKey算子
2.5.2 collect算子
2.5.3 reduce算子
2.5.4 fold算子
2.5.5 first 算子
2.5.6 take() 算子
2.5.7 top算子
2.5.8 count算子
2.5.9 takeSample算子
2.5.10 takeOrder 算子
2.5.11 foreach算子
2.5.12 saveAsTextFile 算子
2.6 分区操作算子
2.6.1mapPartitions算子9
2.6.2 foreachPartition算子
2.6.3 partitionBy 算子
2.6.4 repartition算子
分布式计算需要:
1.分区控制
2.Shuffle控制
3.数据存储、序列化、发送
4.数据计算API,等一系列功能
这些功能不能通过简单的Python内置的本地集合对象(list,字典)去完成。在分布式框架中,需要有一个统一的数据抽象对象,来实现上述分布式计算所需的功能。
这个抽象对象,就是RDD
RDD:
弹性分布式数据集,分布式计算实现的载体(数据抽象)
RDD的五大特点:(前三个特征每个RDD都具备,后两个是可选的)
1.有分区
2.每一个作用在RDD分区的方法都会作用在每一个RDD分区上
3.RDD之间有依赖关系
4.可选的,KV型RDD可以有分区器
5.可选的,RDD在构建的时候会尽量靠近数据所在的位置,加速数据的存取。
1.程序执行入口SparkContext对象
Spark RDD编程的程序入口对象是SparkContext对象,只有构建出SparkContext,基于它才能执行后续的API调用和计算。本质上,SparkContext对编程来说,主要功能就是创建第一个RDD出来。

2.RDD的创建
2.1 通过并行化集合创建(本地对象 转 分布式RDD)
将本地集合——>转向分布式RDD
eg: rdd=sparkcontext.parpllelize(参数1,参数2)
# 参数1 集合对象即可,比如list
# 参数2 分区数
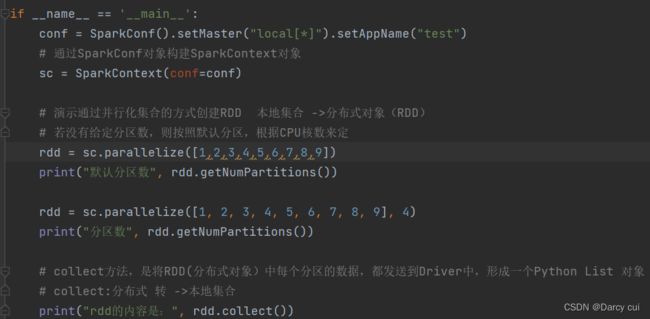
输出:
2.2 读取外部数据源(读取文件)
2.2.1 使用textFile API
这个API可以读取本地数据,也可以读取hdfs数据
使用方法:
sparkcontext.textFile(参数1,参数2)
# 参数1 ,必填,文件路径,支持本地文件,支持HDFS文件,也支持一些比如S3文件。
# 参数2, 可选,表示最小分区数量
# 注意: 参数2 话语权不足,spark有自己的判断,在它允许的范围内,参数2 是有效果的,超出spark允许的范围,则失效。
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
# 通过textFile API 读取数据
# 读取本地文件
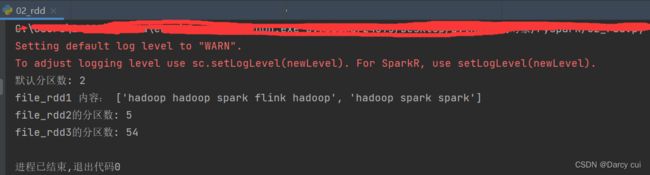
file_rdd1 = sc.textFile('./data/word.txt')
print("默认分区数:", file_rdd1.getNumPartitions())
print("file_rdd1 内容:", file_rdd1.collect())
# 加最小分区数参数的测试
file_rdd2 = sc.textFile('./data/word.txt', 4)
# 最小分区数是参考值,Spark有自己的判断,若给的太大 Spark不会理会
file_rdd3 = sc.textFile('./data/word.txt', 100)
print("file_rdd2的分区数:", file_rdd2.getNumPartitions())
print("file_rdd3的分区数:", file_rdd3.getNumPartitions())输出:
2.2.2 wholeTextFile API
读取小文件的API,有个适用场景,适合读取一堆小文件
用法:
sparkcontext.wholeTextFile(参数1,参数2)
# 参数1 ,必填,文件路径,支持本地文件,支持HDFS文件,也支持一些比如S3文件。
# 参数2, 可选,表示最小分区数量
# 注意: 参数2 话语权不足,这个API 分区数量最多也就开到文件数量
这个API偏向于少量分区读取数据
因为,这个API表明了自己是小文件读取专用,那么文件数据很小,分区很多,导致shuffle 的几率更高,所以尽量少分区读取数据。

输出:(读取的是一个文件夹,输出 元组,k为文件地址,v为文件内容,有几个文件就输出几个元组)

2.3 RDD算子
RDD的算子分为2类
1.Transformation:转换算子
定义:返回值仍旧是一个RDD的,称之为转换算子
特性:这类算子是lazy 懒加载的,如果没有action算子,Transformation算子是不工作的。
2. Action:动作(行动)算子
定义:返回值不是rdd的就是Action算子
对于这两类算子,Transformation算子,相当于在构建执行计划,action是一个指令让这个执行计划开始工作。
2.4 常用Transformation算子
2.4.1 map算子
功能:map算子,是将RDD的数据 一条条处理(处理的逻辑 基于map算子中接收的处理函数),返回新的RDD。
语法:
rdd.map(func)
# func : f:(T) -> U
# f : 表示这是一个函数(方法)
#(T) -> U 表示的是方法的定义:
#()表示传入参数,(T)表示 传入1个参数 , ()表示没有传入参数
# T是泛型的代称,在这里表示 任意类型
# U是泛型的代称,在这里表示 任意类型
# ——> U表示返回值
# (T) ——>U 总结起来的意思是:这是一个方法,这个方法接受一个参数的传入,传入参数类型不限,返回一个返回值,返回值类型不限。
#(A)——>A 总结起来的意思是:这是一个方法,这个方法接受一个参数的传入传入参数类型不限,返回一个返回值,返回值和传入参数类型一致。
2.4.2 flatMap算子
功能:对rdd执行map操作,然后解除嵌套操作
解除嵌套:
# 嵌套的list
list = [[1,2,3],[4,5,6],[7,8,9]]
# 解除嵌套
list = [1,2,3,4,5,6,7,8,9]
2.4.3 reduceByKey算子
功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。
rdd.reduceByKey(func)
# func :(V,V) ——> V
# 接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致。

输出:

2.4.4 mapValues算子
功能:针对二元元组RDD,对其内部的二元元组Value执行map操作
语法:
rdd.mapValues(func)
#func :(V)——> U
# 注意,传入的参数,是二元元组的 value值
# 我们这个传入的方法,只对value进行处理

输出:
2.4.5 groupBy算子
功能:将rdd的数据进行分组
语法:
rdd.groupBy(func)
# func 函数
#func():(T) ——>K
#函数要求传入一个参数,返回一个返回值,类型无所谓
#这个函数是 拿到你的返回值后,将所有相同返回值的放入一个组中
#分组完成后,每一个组是一个二元元组,key就是返回值,所有同组的数据放入一个迭代器对象作为 value

输出:

2.4.6 Filter算子
功能:过滤想要的数据进行保留
语法:
rdd.filter(func)
#func : (T) ——> bool 传入一个参数进来随意类型,返回值必须是True or False
# 返回是True的数据被保留,False 的数据被丢弃
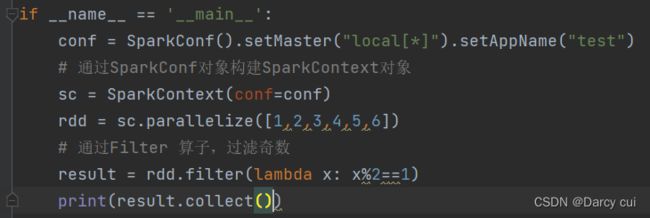
输出:

2.4.7 distinct算子
功能:对RDD数据进行去重,返回新RDD
语法:
rdd.distinct(参数1)
# 参数1 ,去重分区数量,一般不用传

输出:
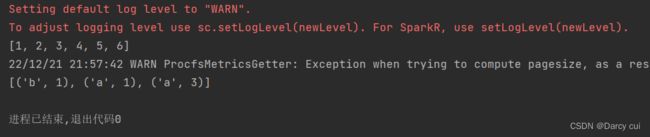
2.4.8 union算子
功能:2个rdd合并成1个rdd返回
用法:
rdd.union(other_rdd)
# 注意, 只合并,不去重
#注意, 不同类型的rdd依旧可以混合、

输出:
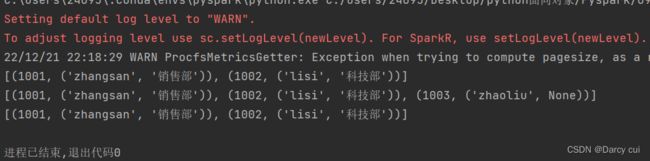
2.4.9 join算子
功能:对两个RDD执行JOIN操作(可实现SQL的内\外连接)
注意:join算子只能用于二元元组,关联条件按照二元元组的key来进行关联
语法:
rdd.join(other_rdd) # 内连接
rdd.leftOuterJoin(other_rdd) # 左外
rdd.rightOuterJoin(other_rdd) # 右外
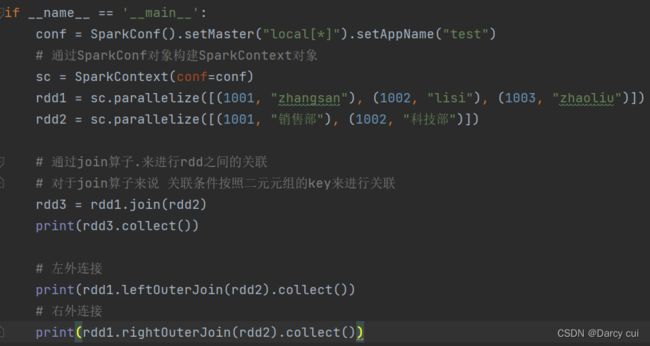
输出:
2.4.10 intersection算子
功能;求两个rdd的交集,返回一个新rdd
用法:
rdd.intersection(other_rdd)if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([(1001, "zhangsan"), (1002, "lisi"), (1003, "zhaoliu")])
rdd2 = sc.parallelize([(1001, "zhangsan"), (1002, "lisi")])
# 通过 intersection 算子求交集
rdd3 = rdd1.intersection(rdd2)
print(rdd3.collect())
# 输出结果:
[(1001, 'zhangsan'), (1002, 'lisi')]2.4.11 glom算子
功能:将RDD的数据,加上嵌套,这个嵌套按照分区来进行
比如 RDD的数据[1, 2, 3, 4,5]有2个分区 ,那么被glom后,数据变成 :[ [1,2,3] ,[4, 5] ]
使用方法:
rdd.glom()if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
rdd2 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 4)
print('rdd1:', rdd1.glom().collect())
print('rdd2:', rdd2.glom().collect())
# 输出结果
rdd1: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
rdd2: [[1, 2], [3, 4], [5, 6], [7, 8, 9]]2.4.12 groupByKey 算子
功能:针对KV型RDD,自动按照key分组
用法:rdd.groupByKey() 自动按照key分组
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([(1001, "1"), (1002, "2"), (1003, "zhaoliu"), (1001, "3"), (1003, "5")])
print('rdd1:', rdd1.groupByKey().collect())
print('rdd1:', rdd1.groupByKey().map(lambda x: (x[0], list(x[1]))).collect())
# 输出结果
rdd1: [(1001, ), (1002, ), (1003, )]
22/12/22 10:02:59 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
rdd1: [(1001, ['1', '3']), (1002, ['2']), (1003, ['zhaoliu', '5'])] 2.4.13 sortBy算子
功能:对RDD数据进行排序,基于你指定的排序依
语法:
rdd.sortBy(func,ascending =False, numPartitions =1)
# func: (T) ——>U :告知按照rdd中的哪个数据进行排序,比如lambda x: x[1] 表示按照rdd中的第二列元素进行排序
# ascending True 升序 False 降序
# numPartitions : 用多少分区排序
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([(1001, "1"), (1007, "1"), (1003, "zhaoliu"), (1006, "3"), (1002, "5")])
rdd2 = sc.parallelize([(1001, "1"), (1001, "4"), (1001, "6"), (1001, "3"), (1001, "2"), (1001, "0")])
print('rdd1:', rdd1.sortBy(lambda x: x[0],ascending=False, numPartitions=1).collect())
print('rdd2:', rdd2.sortBy(lambda x: x[1]).collect())
# 输出:
rdd1: [(1007, '1'), (1006, '3'), (1003, 'zhaoliu'), (1002, '5'), (1001, '1')]
22/12/22 10:23:55 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
rdd2: [(1001, '0'), (1001, '1'), (1001, '2'), (1001, '3'), (1001, '4'), (1001, '6')]2.4.14 sortByKey 算子
功能:针对KV型RDD,按照key()进行排序
语法:
sortByKey(ascending =True, numPartitions =None,keyfunc =
>) # ascending :升序或者降序 ,True 升序 , False降序, 默认升序
# numPartitions:按照几个分区去排序,如果全局有序,设置为1.
# keyfunc: 在排序前对key进行处理,语法是:(K) ——>U,一个参数传入,返回一个值。(只会改变排序过程中的值,结果值并不会改变)
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([(1001, "1"), (1007, "1"), (1003, "zhaoliu"), (1006, "3"), (1002, "5")])
rdd2 = sc.parallelize([(1001, "1"), (1001, "4"), (1001, "6"), (1001, "3"), (1001, "2"), (1001, "0")])
print('rdd1:', rdd1.sortByKey(ascending=False, numPartitions=1, keyfunc=lambda x:x*10).collect())
# 输出:
rdd1: [(1007, '1'), (1006, '3'), (1003, 'zhaoliu'), (1002, '5'), (1001, '1')]
2.5 常用的Action算子
2.5.1 countByKey算子
功能: 统计key 出现的次数(一般适用于KV型RDD)
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.textFile('../data/word.txt')
rdd2 = rdd.flatMap(lambda x: x.split(' ')).map(lambda x: (x, 1))
#通过countByKey 来对key进行计数
result = rdd2.countByKey()
print(result)
# 输出
defaultdict(, {'hadoop': 4, 'spark': 3, 'flink': 1}) 2.5.2 collect算子
功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个list对象
用法:
rdd.collect()
这个算子,,是将RDD各个分区数据都拉取到Driver
注意的是,RDD是分布式对象,其数据量可以很大,所以用这个算子之前
要了解,结果数据集不会太大,不然,会把Driver内存撑爆。
2.5.3 reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
语法:
rddd.reduce(func)
# func: (T, T) ——> T
# 2个参数传入返回一个返回值,返回值和参数要求类型一致。
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
r = rdd.reduce(lambda a, b: a+b)
print(r)
# 输出
152.5.4 fold算子
功能:和reduce一样,接受传入逻辑进行聚合,聚合是带有初始值的,这个初始值聚合,会作用在:
分区内聚合
分区间聚合
比如:[ [1,2,3,], [4,5,6], [7,8,9,] ]
数据分布在3个分区
分区 1 1,2,3 聚合的时候带上10 作为初始值 得到16
分区 2 4,5,6 聚合的时候带上10 作为初始值 得到25
分区 3 7,8,9 聚合的时候带上10 作为初始值 得到34
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9],3)
r = rdd.fold(10, lambda a, b: a+b)
print(r)
# 输出
852.5.5 first 算子
功能: 取出 RDD的第一个元素
用法:
rdd.first()
2.5.6 take() 算子
功能:取RDD的前N个元素,组合成list返回给你
用法:
rdd.take(N)
# N : 取前N个元素
2.5.7 top算子
功能:对RDD数据集进行降序排序,取前N个
用法:
rdd.top(N)
# N: 降序取前N个
2.5.8 count算子
功能:计算RDD有多少条数据,返回值是一个数字
用法:
rdd.count()
2.5.9 takeSample算子
功能:随机抽样RDD数据
用法:
takeSample(参数1:True or False, 参数2: 采样数, 参数3:随机数种子)
——参数1:True表示运行取同一个数据,False表示不允许取同一个数据, 和数据内容无关是否重复表示的是同一个位置的数据。
——参数2:抽样要几个
——参数3:随机数种子,这个参数传入一个数字即可,随意给
随机数种子数字可以随便传,如果传同一个数字,那么取出的结果是一致的
一般参数3 我们不传,Spark会自动给 随机的种子
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9],1)
r = rdd.takeSample(True, 22)
print(r)
r = rdd.takeSample(False, 22)
print(r)
r = rdd.takeSample(False, 5)
print(r)
# 输出
[2, 9, 7, 2, 8, 5, 3, 9, 2, 5, 6, 5, 1, 2, 8, 1, 6, 9, 7, 7, 8, 2]
[9, 2, 8, 3, 5, 6, 4, 7, 1]
[4, 6, 8, 1, 2]
2.5.10 takeOrder 算子
功能:对RDD进行排序取前N个
用法:
rdd.takeOrder(参数1, 参数2)
——参数1 :要几个数据
——参数2 : 对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子)
这个方法使用安装元素自然顺序升序排序,如果你想倒叙,需要用参数2 来对排序的数据进行处理
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9],1)
r = rdd.takeOrdered(3)
print(r)
r = rdd.takeOrdered(4, lambda x: -x)
print(r)
# 输出
[1, 2, 3]
[9, 8, 7, 6]2.5.11 foreach算子
功能:对RDD每一个元素,执行你提供的逻辑操作(和map一个意思),但是这个方法没有返回值。
用法:
rdd.foreach(func)
# func: (T) ——>None
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4],1)
r = rdd.foreach(lambda x: x*10)
print(r)
r = rdd.foreach(lambda x: print(x * 10))
#输出
None
10
20
30
40
2.5.12 saveAsTextFile 算子
功能:将RDD的数据写入文本文件中,支持本地写出,hdfs等文件系统
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4],1)
rdd.saveAsTextFile("./data/p")
创建文件夹:

2.6 分区操作算子
2.6.1mapPartitions算子
一次传递是一整个分区的数据,作为一个迭代器(一次性list)对象传入过来
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8], 3)
def process(iter):
result =list()
for it in iter:
result.append(it*10)
return result
r = rdd.mapPartitions(process).collect()
print(r)
# 输出
[10, 20, 30, 40, 50, 60, 70, 80]
2.6.2 foreachPartition算子
功能:和普通foreach一致,一次处理的是一整个分区数据
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8], 3)
def process(iter):
result =list()
for it in iter:
result.append(it*10)
print(result)
print(rdd.foreachPartition(process))
#输出
[30, 40]
[10, 20]
[50, 60, 70, 80]
None2.6.3 partitionBy 算子
功能: 对RDD进行自定义分区操作
用法:rdd.partitionBy(参数1, 参数2)
——参数1 重新分区后有几个分区
——参数2 自定义分区规则,函数传入
参数2 :(K)——> int
一个参数进来,类型无所谓,但是返回值一定是int 类型
将 key传给这个函数,自己写逻辑,决定返回一个分区编号
分区编号从0 开始,不要超出 分区数 -1
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([("hadoop", 1), ("spark", 1), ("hello", 2), ("flink", 4), ("hadoop", 1)])
# 使用partitionBy算子 自定义分区
def process(k):
if "hadoop" ==k or"hello" == k:
return 0
if "spark" ==k:
return 1
return 2
print(rdd.partitionBy(3, process).glom().collect())
#输出
[[('hadoop', 1), ('hello', 2), ('hadoop', 1)], [('spark', 1)], [('flink', 4)]]
2.6.4 repartition算子
功能:对RDD的分区执行重新分区(仅数量)
用法:
rdd.repartition(N)
传入N决定新的分区数
注意:
对分区的数量进行操作,一定要慎重
一般情况下,我们写spark代码,除了要求全局排序设置为1个分区外,
多数时候,所有API中关于分区相关的代码我们都不会太理会
因为,如果改变了分区
会影响并行计算(内存迭代的并行管道数量)
分区如果增加,极大可能导致shuffle
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8], 3)
# 使用repartition算子修改分区
print(rdd.repartition(1).getNumPartitions())
print(rdd.repartition(5).getNumPartitions())
# coalesce 修改分区
print(rdd.coalesce(1).getNumPartitions())
rdd1 = rdd.coalesce(1)
print(rdd1.glom().collect())
print(rdd.coalesce(5, shuffle=True).getNumPartitions())
rdd2 = rdd.coalesce(5, shuffle=True)
print(rdd2.glom().collect())
# 输出
1
5
1
[[1, 2, 3, 4, 5, 6, 7, 8]]
5
[[], [1, 2], [5, 6, 7, 8], [3, 4], []]