python-csv文件操作
目录
简介
csv文件规范
包
csv
读取csv
写入csv
Pandas
读取-read_csv
写入-to_csv
参考
简介
python中使用csv文件保存数据比较常见,之前一直使用自带的csv,今天又找了找资料,看见了两个。
因为csv可以和.xls、xlsx转换,这里也提一下,对于.xls,.xlsx文件,也可以使用xlwt(新建写入)、xlrd(只读)、xlutils(复制、修改),这些包还可以进行合并单元格等操作,如果只是简单的读写数据,不必使用。
csv文件规范
1、使用回车/换行这两个字符作为行分隔符,最后一行数据可以没有这两个字符。
2、标题行是否需要,要双方显示约定
3、每行记录的字段数要相同,使用逗号分隔。逗号是默认使用的值,双方可以约定别的。
4、任何字段的值都可以使用双引号括起来. 为简单起见,可以要求都使用双引号。
5、字段值中如果有回车符、换行符,双引号,逗号(或约定的其他符号),必须要使用双引号括起来,这是必须的。
6、如果值中有双引号,使用一对双引号来表示原来的一个双引号。
包
csv
csv_test.csv数据如下:
name,sex,date,city
frank,male,2020/8/8,shijiazhuang
lady,female,2020/8/9,beijing
killer,male,2020/6/6,shanghai
yu,female,2020/8/9,baoding读取csv
csv.reader(csvfile, dialect='excel', **fmtparams)
返回一个 reader 对象,该对象将逐行遍历 csvfile。如果 csvfile 是文件对象,则打开它时应使用 newline=''
遍历这个对象可以得到一个列表,每个元素就是该行的某列值,全部为字符串。
with open('csv_test.csv', newline='', encoding='utf-8') as csv_file:
rows = csv.reader(csv_file)
for row in rows:
# print(type(row))
print(row)结果如下:
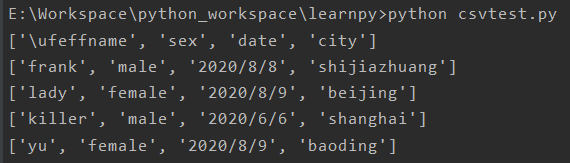 每行结果
每行结果
第一行第一列有点问题。 可以使用encoding="utf-8-sig"来解决。
DictReader(f, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds)
创建一个对象,其操作类似于常规 reader 但会将每行中的信息映射到一个 OrderedDict,其中的键由可选的 fieldnames 形参给出。
with open('csv_test.csv', newline='', encoding='utf-8-sig') as csv_file:
dict_reader = csv.DictReader(csv_file)
for row in dict_reader:
# print(type(row))
print(row['name'], row['city'])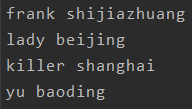 name和city
name和city
一般我们不需要列名,而是需要通过列名作为键值来获取数据,这种读的方式是比较好的。
写入csv
writer(csvfile, dialect='excel', **fmtparams)
返回一个 writer 对象,该对象负责将用户的数据在给定的文件类对象上转换为带分隔符的字符串。
with open('csv_test.csv', 'a', newline='', encoding='utf-8-sig') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['bo', 'male', '2020/09/02', 'QinHuangdao'])写入后结果如下
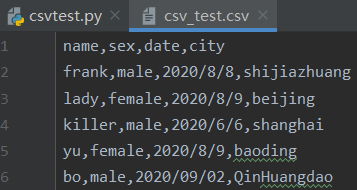 csv_test.csv数据
csv_test.csv数据
DictWriter(f, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, **kwds)
创建一个对象,该对象在操作上类似常规 writer,但能将字典映射到输出行。fieldnames 参数是由 key(键)组成的 序列,用于指定字典中的 value (值)的顺序,这些值会按指定顺序传递给 writerow() 方法并写入 f 文件。如果字典缺少 fieldnames 中的键,则可选参数 restval 用于指定要写入的值。如果传递给 writerow() 方法的字典的某些键在 fieldnames 中找不到,则可选参数 extrasaction 用于指定要执行的操作。如果将其设置为 'raise' (默认值),则会引发 ValueError。 如果将其设置为 'ignore',则字典中的其他键值将被忽略。fieldnames 参数不是可选参数。
with open('names.csv', 'w', newline='') as csv_file:
fieldnames = ['first_name', 'last_name']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})生成的names.csv
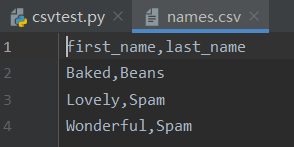 names.csv
names.csv
Pandas
读取-read_csv
| 参数名 | 类型 | 含义 | 举例 |
|---|---|---|---|
| filepath_or_buffer | str | 文件路径 | D://test.csv |
| sep | str,默认为英文逗号"," | 指定的分隔符 | ; |
| encoding | str | 编码 | utf-8 |
| header | int | 数据标题 | 1 |
| usecols | [] | 返回哪几列数据 | [1,2] |
| engine | str,默认c,可选python | 引擎 | python |
| skiprows | []、int | 要跳过的行号 | [2,3]、5 |
| skipfooter | int,默认0(支持c引擎) | 从底部开始忽略 | 1 |
返回DataFrame
| 属性 | 类型 | 含义 |
|---|---|---|
|
|
RangeIndex | DataFrame的索引(行标签)。 |
|
|
Index | DataFrame的列标签。 |
|
|
Series | 返回DataFrame中的dtype。 |
|
|
打印DataFrame的简要摘要。 |
|
|
|
根据列dtypes返回DataFrame列的子集。 |
|
|
|
numpy.adarray | 返回DataFrame的Numpy表示形式。 |
|
|
[index,column,dtype] | 返回一个表示DataFrame轴的列表。 |
|
|
int | 返回一个表示轴数/数组维数的整数。 |
|
|
int | 返回表示此对象中元素数量的int。 |
|
|
(行数,列数) | 返回一个表示DataFrame维数的元组。 |
|
|
返回每列的内存使用情况(以字节为单位)。 |
|
|
|
指示DataFrame是否为空。 |
test.csv数据如下
frank,yu,lady,killer name,type,value,date 1,2,3,4 0,1,2,3 4,5,6,7.34 7,8,9.2,5
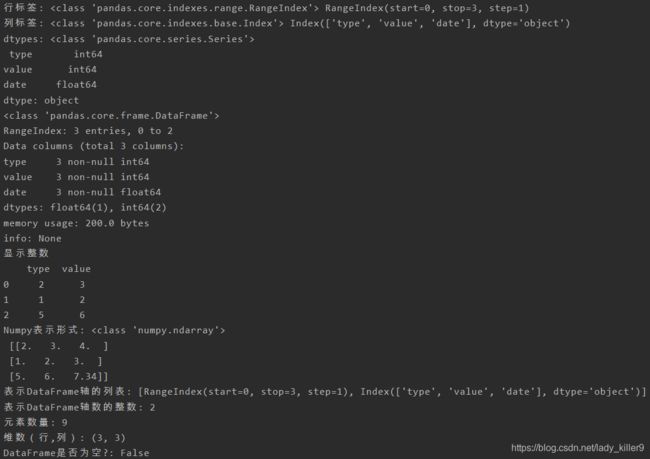 属性
属性
读取read_csv调用部分
pd.read_csv('test.csv', encoding='utf-8', header=0, usecols=[1, 2, 3], engine='python', skiprows=1,skipfooter=1)选择1,2,3列,前后去除一行,剩下的如下,第一行为标题
type,value,date2,3,41,2,35,6,7.34
| 函数 | 类型 | 含义 | 举例 |
|---|---|---|---|
|
|
返回前n行。 |
head(-2) | |
|
|
访问行/列标签对的单个值。 |
at[2,'value'] | |
|
|
通过整数位置访问行/列对的单个值。 |
|
|
|
|
通过标签或布尔数组访问一组行和列。 |
|
|
|
|
基于位置的纯基于整数位置的索引。 |
|
|
|
|
None | 将列插入到DataFrame中的指定位置。 |
|
|
|
遍历(列名,系列)对。 |
csv_data.items() | |
|
|
遍历(列名,系列)对。 |
csv_data.items() | |
|
|
获取“信息轴”(有关更多信息,请参见索引)。 |
csv_data.keys() | |
|
|
将DataFrame行作为(索引,系列)对进行迭代。 |
csv_data.iterrows() | |
|
|
以namedtuple的形式遍历DataFrame行。 |
csv_data.itertuples(index=False) | |
|
|
DataFrame基于标签的“花式索引”功能。 |
csv_data.lookup([1, 2], ['type', 'value']) | |
|
|
将某列从DataFrame中删除。 |
csv_data.pop('date') | |
|
|
返回最后n行。 |
csv_data.tail(2) |
|
|
|
从Series / DataFrame返回横截面。 |
||
|
|
从对象获取给定键的项目(例如:DataFrame列)。 |
||
|
|
DataFrame中的每个元素是否包含在值中。 |
csv_data.isin([1, 2, 6]) | |
|
|
替换条件为False的值。 |
||
|
|
替换条件为True的值。 |
||
|
|
使用布尔表达式查询DataFrame的列。 |
写入-to_csv
参数
path_or_buf:str或文件句柄,默认为None
文件路径或对象,如果提供None,则结果以字符串形式返回。如果传递了文件对象,则应使用newline =''打开它 ,从而禁用通用换行符。
sep:str,默认为“,”
长度为1的字符串。输出文件的字段分隔符。
na_rep:str,默认''
缺失数据的表示。
float_format:str,默认值None
浮点数的格式字符串。
columns:sequence,可选
要写的列。
header:bool或str组成的列表,默认为True
写出列名。如果给出了字符串列表,则假定它是列名的别名。
index:bool,默认为True
写行名(索引)。
index_label:str或sequence,或者为False,默认为None
索引列的列标签(如果需要)。如果没有给出,并且标头和索引为True,则使用索引名。如果对象使用MultiIndex,则应给出一个序列。如果为False,则不打印索引名称的字段。使用index_label = False可以更轻松地导入R中。
mode:str
Python写入模式,默认为“ w”。
encoding:str,可选
表示要在输出文件中使用的编码的字符串,默认为'utf-8'。
compression:str或dict,默认为“推断”
如果为str,则表示压缩模式。如果是dict,则“方法”中的值是压缩模式。压缩模式可以是以下任何可能的值:{'infer','gzip','bz2','zip','xz',None}。如果压缩模式为“推断”,而path_or_buf与路径类似,则从以下扩展名检测压缩模式:“。gz”,“。bz2”,“。zip”或“ .xz”。(否则不压缩)。如果给定的dict和mode为{'zip','gzip','bz2'}之一,或推断为上述之一,则将其他条目作为附加压缩选项传递。
quoting:csv模块中的可选常量
默认为csv.QUOTE_MINIMAL。如果设置了float_format, 则浮点数将转换为字符串,因此csv.QUOTE_NONNUMERIC会将其视为非数字形式。
quotechar:str,默认为“”
长度为1的字符串。用于引用字段的字符。
line_terminator:str,可选
在输出文件中使用的换行符或字符序列。默认为os.linesep,这取决于调用此方法的操作系统(对于Linux为'n',对于Windows为'rn')。
在版本0.24.0中更改。
chunksize:int或None
一次写入的行数。
date_format:str,默认值None
日期时间对象的格式字符串。
doublequote:bool,默认为True
控制字段内quotechar的引用。
escapechar:str,默认值None
长度为1的字符串。 在适当时用于转义sep和quotechar的字符。
decimal:str,默认为“.”
字符被识别为小数点分隔符。例如,对于欧洲数据,请使用“,”。
errors:str,默认为“strict”
指定如何处理编码和解码错误。
举例:
csv_data.to_csv('demo.csv', header=True, index=False, columns=['type', 'value'])生成的demo.csv数据如下
type,value 2,3 1,2 5,6
全部代码
"""
--coding:utf-8--
@File: csvtest.py
@Author:frank yu
@DateTime: 2020.09.01 14:18
@Contact: [email protected]
@Description:
"""
import pandas as pd
from pandas import DataFrame as df
def pd_test():
# 读取csv文件,返回DataFrame对象
csv_data = pd.read_csv('test.csv', encoding='utf-8', header=0, usecols=[1, 2, 3], engine='python', skiprows=1,
skipfooter=1)
# 属性
# print("行标签:", type(csv_data.index), csv_data.index)
# print("列标签:", type(csv_data.columns), csv_data.columns)
# print("dtypes:", type(csv_data.dtypes), "\n", csv_data.dtypes)
# print("info:", csv_data.info(verbose=True))
# print("显示整数\n", csv_data.select_dtypes(include="int64"))
# print("Numpy表示形式:", type(csv_data.values), "\n", csv_data.values)
# print("表示DataFrame轴的列表:", csv_data.axes)
# print("表示DataFrame轴数的整数:", csv_data.ndim)
# print("元素数量:", csv_data.size)
# print("维数(行,列):", csv_data.shape)
# print("DataFrame是否为空?:", csv_data.empty)
# 迭代器
print('后2行数据:\n', csv_data.head(-2))
print("2行value列的数据:", csv_data.at[2, 'value'])
print("2行2列的数据:", csv_data.iat[2, 2])
print("0行、2行的数据:\n", csv_data.loc[[True, False, True]])
print("1行到3行(不包括)的数据:\n", csv_data.iloc[1:3])
csv_data.insert(1, 'name', [10, 11, 12])
print("name列插入为1列(10 11 12)\n", csv_data.values)
print("column, serie")
for column, serie in csv_data.items():
print(column)
print(serie)
break
for column, serie in csv_data.iteritems():
print(column)
print(serie)
break
print("信息轴:", csv_data.keys())
row = next(csv_data.iterrows())[1]
print("第一行:", row)
print("所有行:")
for row in csv_data.itertuples(index=False):
print(row)
print('查找1行type列,2行value列', csv_data.lookup([1, 2], ['type', 'value']))
csv_data.pop('date')
print('date列已删除\n', csv_data)
print('最后两行\n', csv_data.tail(2))
print('数值是否为1/2/6\n', csv_data.isin([1, 2, 6]))
# 写入csv
csv_data.to_csv('demo.csv', header=True, index=False, columns=['type', 'value'])
if __name__ == "__main__":
pd_test()
参考
csv文件读写
更多python相关内容:【python总结】python学习框架梳理
本人b站账号:lady_killer9
有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!如有侵权,请及时联系。如果您感觉有所收获,自愿打赏,可选择支付宝18833895206(小于),您的支持是我不断更新的动力。