Kubernetes深入浅出
前言
本文对资料进行了一些整理,能够快速学习,理解到核心
k8s的设计理念,包括系统架构的设计与原则、组件的可插拔方式、调度的过程、系统的可扩展性与容错性、代码的设计模式、资源与功能的抽象方式、watch机制的设定等等都可以为开发者带来许多的灵感,有兴趣的同学可以深入研究,全文1万字左右,阅读时间30-60分钟
简介
kubernetes,简称K8s,是用“8”代替8个字符“ubernete”而成的缩写。
kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,它的目标是让部署容器化的应用简单并且高效(powerful),其提供了应用部署,规划,更新,维护的一种机制。
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
Kubernetes 拥有一个庞大且快速增长的生态系统。
Kubernetes 的服务、支持和工具广泛可用。
k8s可以更快的更新,更新时不中断服务,服务器故障不停机,从开发环境到测试环境到生产环境的迁移极其方便,一个配置文件搞定,一次生成image,到处运行。
Kubernetes的前世今生
Kubernetes,名称 Kubernetes 源于希腊语,意为“舵手”或“飞行员”,Google 在 2014 年开源了 Kubernetes 项目,Kubernetes 建立在 Google 在大规模运行生产工作负载方面拥有十几年的经验 的基础上,结合了社区中最好的想法和实践,目前K8S在github的star数量已经70K+
它的Logo设置成舵盘,而Docker的Logo是一只装满集装箱的鲸鱼 。
深意:google 要用Kubernetes去掌握大航海时代的话语权,去捕获和指引着这条鲸鱼按照主人设定的路线去巡游。
时光回溯
传统部署时代
早期,组织在物理服务器上运行应用程序,可能会出现如下问题:
1、无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题
2、ALL IN ONE的模式,可能出现操作系统版本不兼容,应用程序之间的依赖库不兼容等等
3、可能会出现一个应用程序占用大部分资源的情况, 结果可能导致其他应用程序的性能下降
4、物理服务器的闲置的碎片资源过多,无法得到充分利用
5、机器发生故障,迁移成本过高
一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法快速动态扩展, 并且组织维护许多物理服务器的成本很高。
虚拟化部署时代
作为解决方案,引入了虚拟化。虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)。
虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全,因为一个应用程序的信息 不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器上的资源,且因为可轻松地添加或更新应用程序 来实现更好的可伸缩性,降低硬件成本等等。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
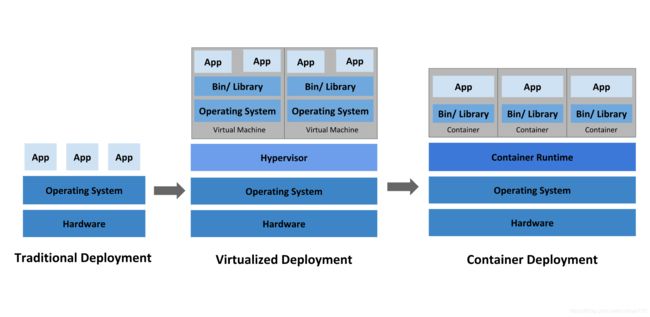
容器部署时代
容器类似于 VM,但是它们具有被放宽的隔离属性,可以在应用程序之间共享操作系统(OS)。
因此,容器被认为是轻量级的。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。
容器不仅可以部署在物理服务器上,也可以部署在虚拟机上,由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来。下面列出的是容器的一些好处:
- •敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率
- •持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署
- •关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像, 从而将应用程序与基础架构分离
- •可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号
- •跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行
- •跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行
- •以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序
- •松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行
- •资源隔离:可预测的应用程序性能
- •资源利用:高效率和高密度
Kubernetes 能做什么
容器是打包和运行应用程序的好方式。
在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。
例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法!
Kubernetes 为你提供了一个可弹性运行分布式系统的框架。
Kubernetes 会满足你的扩展要求、故障转移、部署模式等。
现代化的互联网服务,用户希望应用程序能够 24/7 全天候使用,开发人员希望每天可以多次发布部署新版本的应用程序。
容器化可以帮助软件包达成这些目标,使应用程序能够以简单快速的方式发布和更新,而无需停机。
Kubernetes 确保这些容器化的应用程序在您想要的时间和地点运行,并帮助应用程序找到它们需要的资源和工具。
Kubernetes 是一个可用于生产的开源平台,根据 Google 容器集群方面积累的经验,以及来自社区的最佳实践而设计。
Kubernetes是编排和管理容器的工具,它是基于Docker构建一个容器的调度服务,提供资源调度、均衡容灾、服务注册、动态扩缩容等功能套件。
Kubernetes提供应用部署、维护、 扩展机制 等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下:
- 数据卷: 实现Pod中容器之间数据共享。
- 应用程序健康检查: 容器内服务可能进程阻塞无法处理请求,可以设置监控检查策略保证应用健壮性。
- 复制应用程序实例: 控制器维护着Pod副本数量,保证一个Pod或一组同类的Pod数量始终可用。
- 弹性伸缩: 根据设定的指标(CPU利用率)自动缩放Pod副本数。
- 服务发现: 使用环境变量或DNS服务插件保证容器中程序发现Pod入口访问地址。
- 负载均衡:
一组Pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他Pod可通过这个ClusterIP访问应用。 - 滚动更新: 更新服务不中断,一次更新一个Pod,而不是同时删除整个服务。
- 服务编排: 通过文件描述部署服务,使得应用程序部署变得更高效。
- 资源监控:
Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDB时序数据库,再由Grafana展示。当然你也可以使用Prometheus。 - 提供认证和授权: 支持属性访问控制(ABAC)、角色访问控制(RBAC)认证授权策略。
Kubernetes 环境安装
CNCF做过一份k8s的调研:
41%的用户卡在了架构设计,如何让自己的应用结合k8s
16%的用户卡在了安装的问题上,但是目前已经涌现了中多的开源方案,部署也变得更加便捷
14%的用户觉得日常管理比较的麻烦
以下推荐了几个开源的k8s部署方案:
Kubernetes 中文指南/云原生应用架构实践手册
https://github.com/rootsongjc/kubernetes-handbook
•minikube:
minikube is a tool that lets you run Kubernetes locally.你可以在自己的本地window、mac上快速的运行一个k8s的环境。
•kubeadm
Kubeadm is a tool built to provide kubeadm init and kubeadm join as best-practice “fast paths” for creating Kubernetes clusters。官方出品,目前已经可以用于生产环境部署
•kubeoperate
KubeOperator 是一个开源的轻量级Kubernetes 发行版,专注于帮助企业规划、部署和运营生产级别的K8s 集群。
KubeOperator 提供可视化的 Web UI,支持离线环境,支持物理机、VMware 和 OpenStack 等 IaaS 平台,支持 x86 和 arm64 架构,支持 GPU,内置应用商店,已通过 CNCF 的 Kubernetes 软件一致性认证。
•rancher
Rancher是一个开源的企业级容器管理平台。
通过Rancher,企业再也不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用的管理Docker和Kubernetes的全栈化容器部署与管理平台。
•kubespray
Kubespray开源的一个部署生产级别的Kubernetes服务器集群的开源项目,
它整合了Ansible作为部署的工具,支持的组件也特别多,如超过10种网络插件的支持。
•kubeasz
国人开源的项目,致力于提供快速部署高可用k8s集群的工具, 同时也努力成为k8s实践、使用的参考书;
基于二进制方式部署和利用ansible-playbook实现自动化。
•kubesphere
青云开源的产品,在 Kubernetes 之上构建的以应用为中心的多租户容器平台,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。
其他还有很多,目前开源社区非常活跃,生态逐步完善,这里就不一一列出了。
Kubernetes基础概念
Pods
- •Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
- •Pod(就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明, 这些容器都是紧密耦合在一起的。
- •Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。
除了应用容器,Pod 还可以包含在 Pod 启动期间运行的 Init 容器,它是一种特殊容器,在 Pod 内的应用容器启动之前运行,可以包括一些应用镜像中不存在的实用工具和安装脚本。
你也可以在集群中支持临时性容器 的情况外,为调试的目的注入临时性容器。
)
控制器类型
ReplicaSet:ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
ReplicationController:确保在任何时候都有特定数量的 Pod 副本处于运行状态。 换句话说,ReplicationController 确保一个 Pod 或一组同类的 Pod 总是可用的。
Deployments:一个 Deployment 控制器为 Pods 和 ReplicaSets 提供声明式的更新能力。
StatefulSets:用来管理有状态应用的工作负载 API 对象。
DaemonSet:确保全部(或者某些)节点上运行一个 Pod 的副本。
Jobs:Job 会创建一个或者多个 Pods,并确保指定数量的 Pods 成功终止。
服务、负载均衡和联网
Kubernetes 网络解决的问题包括:
一个 Pod 中的容器之间通过本地回路(loopback)通信;
集群网络在不同 pod 之间提供通信;
Service 资源允许你对外暴露 Pods 中运行的应用程序,以支持来自于集群外部的访问。
Servcie
可以使用 Services 来发布仅供集群内部使用的服务。
Service:拓扑可以让一个服务基于集群的 Node 拓扑进行流量路由。
例如,一个服务可以指定流量是被优先路由到一个和客户端在同一个 Node 或者在同一可用区域的端点。
Ingress
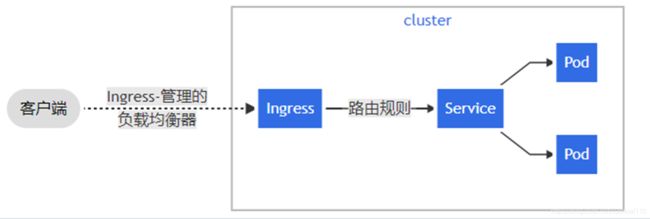
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由,流量路由由 Ingress 资源上定义的规则控制。
ingress支持的控制器也非常之多,如常见的F5 Networks、Haproxy、基于Istio的Ingress、Kong、nginx、Traefix等等。
Kubernetes 架构与核心组件
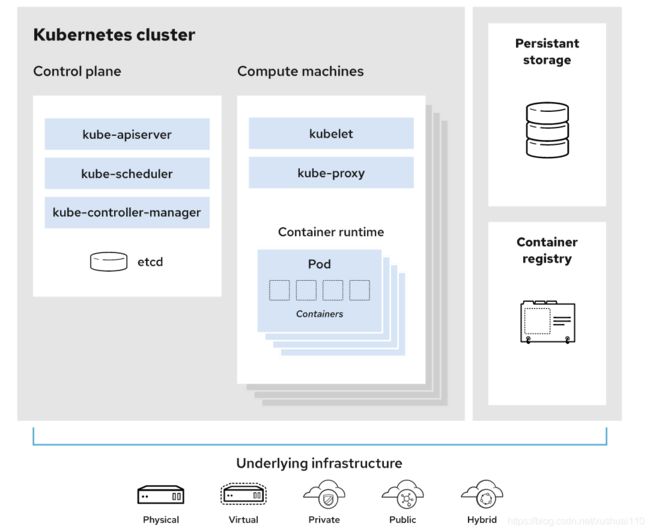
k8s中可以简单的认为两大块,一个是master主节点用于控制计算节点,一个是node,就是我们常说的计算节点,用来部署pod的实际使用的物理机或者虚拟机。
- •api server:所有服务访问统一入口,提供了资源操作的唯一入口,并提供认证、授权、访问控制、api注册和发现等机制
- •crontrollermanager:维持副本期望数目, 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
- •scheduler:负责资源的调度,按照预定的调度策略将pod调度到相应的机器上
- •etcd:键值对数据库,保存了整个集群的状态,存储k8s集群所有重要信息(持久化)
- •kubelet:直接跟容器引擎交互,负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理
- •kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡,负责写入规则至iptables,ipvs实现服务映射访问的其他重要的插件
- •coredns:可以为集群中的service创建一个域名ip的对应关系解析
- •dashboard:给k8s集群提供一个b/s结构访问体系
- •ingress controller:官方只能实现4层代理,ingress可以实现7层代理
- •federation:提供一个可以跨集群中心多k8s统一管理功能
- •prometheus:提供k8s集群的监控能力
- •elk:提供k8s集群日志统一分析介入平台
- •Container runtime: 负责镜像管理,以及Pods可以在其中真正运行(CRI),常用的几个容器运行时,如docker、CRI-O、containerd等等
在k8s中网络与存储也支持多种多样的方案,下面简单阐述一些:
集群网络系统是 Kubernetes 的核心部分,但是想要准确了解它的工作原理可是个不小的挑战。
-
1.高度耦合的容器间通信:这个已经被 Pods 和 localhost 通信解决了。
-
2.Pod 间通信:这个网络插件要解决的重点问题。
-
3.Pod 和服务间通信:这个已经在服务、负载均衡和联网 里讲述过了。
-
4.外部和服务间通信:这也已经在服务、负载均衡和联网 里讲述过了。
针对第2点,目前k8s支持的网络插件,如Flannel、Calico、Cilium、OpenVSwitch、Kube-router、Multus(多 CNI 插件) 等等。
存储卷的支持种类繁多,如cephfs、cinder、nfs、rbd、glusterfs、hostPath等等。
Scheduler调度
k8s中最核心的功能就是调度,能够为容器运行时所需要的计算,存储和网络资源进行调配,并且总能选择最合适的节点。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等。
你可以约束一个 Pod 只能在特定的 Node(s) 上运行,或者优先运行在特定的节点上。
有几种方法可以实现这点,推荐的方法都是用标签选择器来进行选择。
通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 pod 分散到节点上,而不是将 pod 放置在可用资源不足的节点上等等),但在某些情况下,你可能需要更多控制 pod 停靠的节点,
例如,确保 pod 最终落在连接了 SSD 的机器上,或者将来自两个不同的服务且有大量通信的 pod 放置在同一个可用区。
k8s的调度利用node标签,pod标签进行了实现的简单例子,
首先对两组机器分别打上env=dev、env=prod两个标签:
A组机器3台:标签 env=dev
B组机器10台:标签evn=prod
此时需要对某个pod进行调度,指定改pod被调度时选择evn=dev,则该pod永远在A组机器上面运行。
k8s调度举例:
NodeSelector:定向的节点调度,简单来说,就是指定pod运行的机器。
NodeAffinity:节点的亲和性调度,简单来说,我需要将运行数据库的pod调度到ssd机器上,该方式就可以实现。
PodAffinity: pod的亲和性与反亲和性调度,简单来说,我希望同样一个应用部署多份,但不能部署在同一机器上面。
Deployment:自动调度,完全依赖k8s底层调度控制。
当然调度远没有这么简单,你还可以了解调度的硬性要求与软性要求,也可以创建自己的调度算法
以下简单的描述了k8s中内置的一些调度策略
Kubernetes Scheduler组件
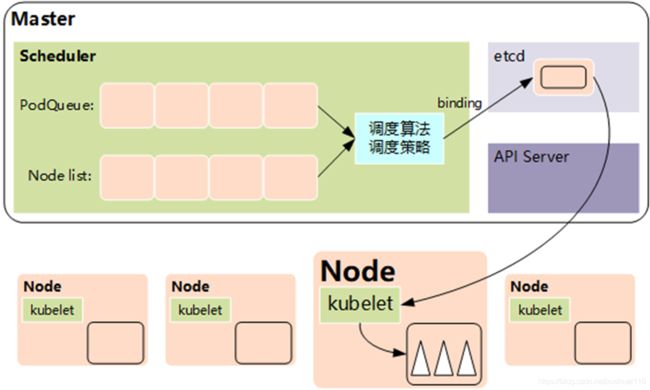
其作用是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等)按照特定的调度算法和调度策略绑定(Binding)到集群中某个合适的Node上,并将绑定信息写入etcd中。
概述而言,就是通过调度算法调度,为待调度Pod列表中的每个Pod从Node列表中选择一个最适合的Node。
随后,目标节点上的kubelet通过API Server监听到Kubernetes Scheduler产生的Pod绑定事件,
然后获取对应的Pod清单,下载Image镜像并启动容器。
在整个调度过程中涉及三个对象,分别是待调度Pod列表、可用Node列表,以及调度算法和策略。
kube-scheduler 给一个 pod 做调度选择包含两个步骤:1、过滤 2、打分
过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。
例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下,这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
支持以下两种方式配置调度器的过滤和打分行为:
-
1.调度策略 允许你配置过滤的 谓词(Predicates) 和打分的 优先级(Priorities) 。
-
2.调度配置 允许你配置实现不同调度阶段的插件,包括:QueueSort, Filter, Score, Bind, Reserve, Permit 等等。你也可以配置 kube-scheduler 运行不同的配置文件。
过滤
首先我们看下预选调度中的调度策略有哪些:
- •PodFitsHostPorts:检查 Pod 请求的端口(网络协议类型)在节点上是否可用
- •PodFitsHost:检查 Pod 是否通过主机名指定了 Node
- •PodFitsResources:检查节点的空闲资源(例如,CPU和内存)是否满足 Pod 的要求
- •MatchNodeSelector:检查 Pod 的节点选择算符 和节点的 标签 是否匹配
- •NoVolumeZoneConflict:给定该存储的故障区域限制, 评估 Pod 请求的卷在节点上是否可用
- •NoDiskConflict:根据 Pod 请求的卷是否在节点上已经挂载,评估 Pod 和节点是否匹配
- •MaxCSIVolumeCount:决定附加 CSI 卷的数量,判断是否超过配置的限制
- •CheckNodeMemoryPressure:如果节点正上报内存压力,并且没有异常配置,则不会把 Pod 调度到此节点上
- •CheckNodePIDPressure:如果节点正上报进程 ID 稀缺,并且没有异常配置,则不会把 Pod 调度到此节点上
- •CheckNodeDiskPressure:如果节点正上报存储压力(文件系统已满或几乎已满),并且没有异常配置,则不会把 Pod 调度到此节点上
- •CheckNodeCondition:节点可用上报自己的文件系统已满,网络不可用或者 kubelet 尚未准备好运行 Pod。 如果节点上设置了这样的状况,并且没有异常配置,则不会把 Pod 调度到此节点上
- •PodToleratesNodeTaints:检查 Pod 的容忍 是否能容忍节点的污点
- •CheckVolumeBinding:基于 Pod 的卷请求,评估 Pod 是否适合节点,这里的卷包括绑定的和未绑定的 PVCs 都适用
经过了上面预选调度的筛选,剩下的node计算节点就都是可以被调度的节点了。 那么,我们需要从这些节点中选择出一个最适合的节点,该如何选择呢?
最简便靠谱的方法当然是给每一个节点都得一个分值,分值最高者则是最适合的节点。
打分
以下优先级实现了打分接口:
- •SelectorSpreadPriority:属于同一 Service、 StatefulSet 或 ReplicaSet 的 Pod,跨主机部署
- •InterPodAffinityPriority:实现了 Pod 间亲和性与反亲和性的优先级
- •LeastRequestedPriority:偏向最少请求资源的节点。 换句话说,节点上的 Pod 越多,使用的资源就越多,此策略给出的排名就越低
简单来说:计算Pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优,
得分计算公式:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2 - •MostRequestedPriority:支持最多请求资源的节点。 该策略将 Pod 调度到整体工作负载所需的最少的一组节点上
节点上各项资源(CPU、内存)使用率最均衡的为最优,得分计算公式:10 – abs(totalCpu/cpuNodeCapacity-totalMemory/memoryNodeCapacity)*10 - •RequestedToCapacityRatioPriority:使用默认的打分方法模型,创建基于 ResourceAllocationPriority 的 requestedToCapacity
- •BalancedResourceAllocation:偏向平衡资源使用的节点
- •NodePreferAvoidPodsPriority:根据节点的注解 scheduler.alpha.kubernetes.io/preferAvoidPods 对节点进行优先级排序。 你可以使用它来暗示两个不同的 Pod 不应在同一节点上运行
- •NodeAffinityPriority:根据节点亲和中 PreferredDuringSchedulingIgnoredDuringExecution 字段对节点进行优先级排序。 你可以在将 Pod 分配给节点中了解更多
- •TaintTolerationPriority:根据节点上无法忍受的污点数量,给所有节点进行优先级排序。 此策略会根据排序结果调整节点的等级
- •ImageLocalityPriority:偏向已在本地缓存 Pod 所需容器镜像的节点
- •ServiceSpreadingPriority:对于给定的 Service,此策略旨在确保该 Service 关联的 Pod 在不同的节点上运行。 它偏向把 Pod 调度到没有该服务的节点。 整体来看,Service 对于单个节点故障变得更具弹性
- •EqualPriority:给予所有节点相等的权重
- •EvenPodsSpreadPriority:实现了 Pod 拓扑扩展约束的优先级排序
如果你真的希望或者有这方面的需求,kube-scheduler 在设计上是允许你自己写一个调度组件并替换原有的 kube-scheduler。