深度学习(34)—— StarGAN(2)
深度学习(34)—— StarGAN(2)
完整项目在这里:欢迎造访
文章目录
- 深度学习(34)—— StarGAN(2)
-
- 1. build model
-
- (1)generator
- (2)mapping network
- (3)style encoder
- (4)discriminator
- 2. 加载数据dataloader
- 3. train
- 4. 训练 discriminator
-
- (1)real image loss
- (2)fake image loss
- 5. 训练generator
-
- (1) adversarial loss
- (2) style restruction loss
- (3) diversity sensitive loss
- (4)cycle-consistency loss
- 重点关注`!!!!!`
- debug processing
使用数据集结构:
- data
- train
- domian 1
- img 1
- img 2
- …
- domain 2
- img1
- img2
- …
- domain n
- domian 1
- val
- domian 1
- img 1
- img 2
- …
- domain 2
- img1
- img2
- …
- domain n
- domian 1
- train
1. build model
(1)generator

class Generator(nn.Module):
def __init__(self, img_size=256, style_dim=64, max_conv_dim=512, w_hpf=1):
super().__init__()
dim_in = 2**14 // img_size
self.img_size = img_size
self.from_rgb = nn.Conv2d(3, dim_in, 3, 1, 1) #(in_channels,out_channels,kernel_size,stride,padding)
self.encode = nn.ModuleList()
self.decode = nn.ModuleList()
self.to_rgb = nn.Sequential(
nn.InstanceNorm2d(dim_in, affine=True),
nn.LeakyReLU(0.2),
nn.Conv2d(dim_in, 3, 1, 1, 0))
# down/up-sampling blocks
repeat_num = int(np.log2(img_size)) - 4
if w_hpf > 0:
repeat_num += 1
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
self.encode.append(
ResBlk(dim_in, dim_out, normalize=True, downsample=True))
self.decode.insert(
0, AdainResBlk(dim_out, dim_in, style_dim,
w_hpf=w_hpf, upsample=True)) # stack-like
dim_in = dim_out
# bottleneck blocks
for _ in range(2):
self.encode.append(
ResBlk(dim_out, dim_out, normalize=True))
self.decode.insert(
0, AdainResBlk(dim_out, dim_out, style_dim, w_hpf=w_hpf))
if w_hpf > 0:
device = torch.device(
'cuda' if torch.cuda.is_available() else 'cpu')
self.hpf = HighPass(w_hpf, device)
def forward(self, x, s, masks=None):
x = self.from_rgb(x)
cache = {}
for block in self.encode:
if (masks is not None) and (x.size(2) in [32, 64, 128]):
cache[x.size(2)] = x
x = block(x)
for block in self.decode:
x = block(x, s)
if (masks is not None) and (x.size(2) in [32, 64, 128]):
mask = masks[0] if x.size(2) in [32] else masks[1]
mask = F.interpolate(mask, size=x.size(2), mode='bilinear')
x = x + self.hpf(mask * cache[x.size(2)])
return self.to_rgb(x)

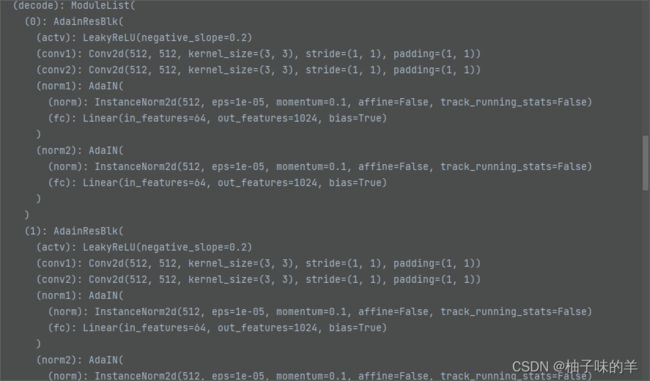
encoder 和decoder各6个ResBlk
(2)mapping network

class MappingNetwork(nn.Module):
def __init__(self, latent_dim=16, style_dim=64, num_domains=2):
super().__init__()
layers = []
layers += [nn.Linear(latent_dim, 512)]
layers += [nn.ReLU()]
for _ in range(3):
layers += [nn.Linear(512, 512)]
layers += [nn.ReLU()]
self.shared = nn.Sequential(*layers)
self.unshared = nn.ModuleList()
for _ in range(num_domains):
self.unshared += [nn.Sequential(nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, style_dim))]
def forward(self, z, y):
h = self.shared(z)
out = []
for layer in self.unshared:
out += [layer(h)]
out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
s = out[idx, y] # (batch, style_dim)
return s
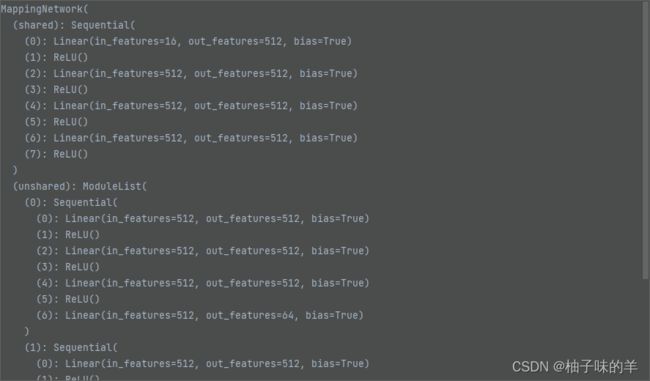

unshared中有多个相同的分支,每个domain都有一个
(3)style encoder
class StyleEncoder(nn.Module):
def __init__(self, img_size=256, style_dim=64, num_domains=2, max_conv_dim=512):
super().__init__()
dim_in = 2**14 // img_size
blocks = []
blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]
repeat_num = int(np.log2(img_size)) - 2
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
blocks += [ResBlk(dim_in, dim_out, downsample=True)]
dim_in = dim_out
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]
blocks += [nn.LeakyReLU(0.2)]
self.shared = nn.Sequential(*blocks)
self.unshared = nn.ModuleList()
for _ in range(num_domains):
self.unshared += [nn.Linear(dim_out, style_dim)]
def forward(self, x, y):
h = self.shared(x)
h = h.view(h.size(0), -1)
out = []
for layer in self.unshared:
out += [layer(h)]
out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
s = out[idx, y] # (batch, style_dim)
return s

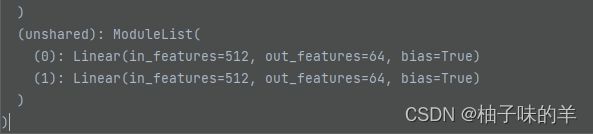
unshared和上面的mapping network一样有两个domain所以有两个linear
(4)discriminator
class Discriminator(nn.Module):
def __init__(self, img_size=256, num_domains=2, max_conv_dim=512):
super().__init__()
dim_in = 2**14 // img_size
blocks = []
blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]
repeat_num = int(np.log2(img_size)) - 2
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
blocks += [ResBlk(dim_in, dim_out, downsample=True)]
dim_in = dim_out
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, num_domains, 1, 1, 0)]
self.main = nn.Sequential(*blocks)
def forward(self, x, y):
out = self.main(x)
out = out.view(out.size(0), -1) # (batch, num_domains)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
out = out[idx, y] # (batch)
return out

和style_encoder只有后面一点点不同
build完model之后就有权重加载权重,没有略过。下面打印了每个subnet的模型参数量

2. 加载数据dataloader
def get_train_loader(root, which='source', img_size=256,
batch_size=8, prob=0.5, num_workers=4):
print('Preparing DataLoader to fetch %s images '
'during the training phase...' % which)
crop = transforms.RandomResizedCrop(
img_size, scale=[0.8, 1.0], ratio=[0.9, 1.1])
rand_crop = transforms.Lambda(
lambda x: crop(x) if random.random() < prob else x)
transform = transforms.Compose([
rand_crop,
transforms.Resize([img_size, img_size]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]),
])
if which == 'source':
dataset = ImageFolder(root, transform)
elif which == 'reference':
dataset = ReferenceDataset(root, transform)
else:
raise NotImplementedError
sampler = _make_balanced_sampler(dataset.targets)
return data.DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers,
pin_memory=True,
drop_last=True)
如果图片是train直接用ImageFold,如果是reference使用自定义的ReferenceDatabase
class ReferenceDataset(data.Dataset):
def __init__(self, root, transform=None):
self.samples, self.targets = self._make_dataset(root)
self.transform = transform
def _make_dataset(self, root):
domains = os.listdir(root)
fnames, fnames2, labels = [], [], []
for idx, domain in enumerate(sorted(domains)):
class_dir = os.path.join(root, domain)
cls_fnames = listdir(class_dir)
fnames += cls_fnames
fnames2 += random.sample(cls_fnames, len(cls_fnames))
labels += [idx] * len(cls_fnames)
return list(zip(fnames, fnames2)), labels
def __getitem__(self, index):
fname, fname2 = self.samples[index]
label = self.targets[index]
img = Image.open(fname).convert('RGB')
img2 = Image.open(fname2).convert('RGB')
if self.transform is not None:
img = self.transform(img)
img2 = self.transform(img2)
return img, img2, label
def __len__(self):
return len(self.targets)
reference 是在每个domain中选择两张图片,这两张图片有相同的label。fnames用于记录其中一张图片,fnames2记录另一张,label记录两者的标签
def get_test_loader(root, img_size=256, batch_size=32,
shuffle=True, num_workers=4):
print('Preparing DataLoader for the generation phase...')
transform = transforms.Compose([
transforms.Resize([img_size, img_size]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root, transform)
return data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers,
pin_memory=True)
3. train
def train(self, loaders):
args = self.args
nets = self.nets
nets_ema = self.nets_ema
optims = self.optims
# fetch random validation images for debugging
fetcher = InputFetcher(loaders.src, loaders.ref, args.latent_dim, 'train')
fetcher_val = InputFetcher(loaders.val, None, args.latent_dim, 'val')
inputs_val = next(fetcher_val)
# resume training if necessary
if args.resume_iter > 0:
self._load_checkpoint(args.resume_iter)
# remember the initial value of ds weight
initial_lambda_ds = args.lambda_ds
print('Start training...')
start_time = time.time()
for i in range(args.resume_iter, args.total_iters):
# fetch images and labels
inputs = next(fetcher)
x_real, y_org = inputs.x_src, inputs.y_src
x_ref, x_ref2, y_trg = inputs.x_ref, inputs.x_ref2, inputs.y_ref
z_trg, z_trg2 = inputs.z_trg, inputs.z_trg2
masks = nets.fan.get_heatmap(x_real) if args.w_hpf > 0 else None
# train the discriminator
d_loss, d_losses_latent = compute_d_loss(
nets, args, x_real, y_org, y_trg, z_trg=z_trg, masks=masks)
self._reset_grad()
d_loss.backward()
optims.discriminator.step()
d_loss, d_losses_ref = compute_d_loss(
nets, args, x_real, y_org, y_trg, x_ref=x_ref, masks=masks)
self._reset_grad()
d_loss.backward()
optims.discriminator.step()
# train the generator
g_loss, g_losses_latent = compute_g_loss(
nets, args, x_real, y_org, y_trg, z_trgs=[z_trg, z_trg2], masks=masks)
self._reset_grad()
g_loss.backward()
optims.generator.step()
optims.mapping_network.step()
optims.style_encoder.step()
g_loss, g_losses_ref = compute_g_loss(
nets, args, x_real, y_org, y_trg, x_refs=[x_ref, x_ref2], masks=masks)
self._reset_grad()
g_loss.backward()
optims.generator.step()
# compute moving average of network parameters
moving_average(nets.generator, nets_ema.generator, beta=0.999)
moving_average(nets.mapping_network, nets_ema.mapping_network, beta=0.999)
moving_average(nets.style_encoder, nets_ema.style_encoder, beta=0.999)
# decay weight for diversity sensitive loss
if args.lambda_ds > 0:
args.lambda_ds -= (initial_lambda_ds / args.ds_iter)
# print out log info
if (i+1) % args.print_every == 0:
elapsed = time.time() - start_time
elapsed = str(datetime.timedelta(seconds=elapsed))[:-7]
log = "Elapsed time [%s], Iteration [%i/%i], " % (elapsed, i+1, args.total_iters)
all_losses = dict()
for loss, prefix in zip([d_losses_latent, d_losses_ref, g_losses_latent, g_losses_ref],
['D/latent_', 'D/ref_', 'G/latent_', 'G/ref_']):
for key, value in loss.items():
all_losses[prefix + key] = value
all_losses['G/lambda_ds'] = args.lambda_ds
log += ' '.join(['%s: [%.4f]' % (key, value) for key, value in all_losses.items()])
print(log)
# generate images for debugging
if (i+1) % args.sample_every == 0:
os.makedirs(args.sample_dir, exist_ok=True)
utils.debug_image(nets_ema, args, inputs=inputs_val, step=i+1)
# save model checkpoints
if (i+1) % args.save_every == 0:
self._save_checkpoint(step=i+1)
# compute FID and LPIPS if necessary
if (i+1) % args.eval_every == 0:
calculate_metrics(nets_ema, args, i+1, mode='latent')
calculate_metrics(nets_ema, args, i+1, mode='reference')
4. 训练 discriminator
def compute_d_loss(nets, args, x_real, y_org, y_trg, z_trg=None, x_ref=None, masks=None):
assert (z_trg is None) != (x_ref is None) #X_real 为原图,y_org为原图的label。y_trg 为reference的label,z_trg 为reference随机生成的向量
# with real images
x_real.requires_grad_()
out = nets.discriminator(x_real, y_org)
loss_real = adv_loss(out, 1)
loss_reg = r1_reg(out, x_real)
# with fake images
with torch.no_grad():
if z_trg is not None:
s_trg = nets.mapping_network(z_trg, y_trg)
else: # x_ref is not None
s_trg = nets.style_encoder(x_ref, y_trg)
x_fake = nets.generator(x_real, s_trg, masks=masks)
out = nets.discriminator(x_fake, y_trg)
loss_fake = adv_loss(out, 0)
loss = loss_real + loss_fake + args.lambda_reg * loss_reg
return loss, Munch(real=loss_real.item(),
fake=loss_fake.item(),
reg=loss_reg.item())
latent 得到style 向量
(1)real image loss
- 需要先将real image输入discriminator得到结果out(batch*domain_num)
- 然后根据real image的label取真正label的结果(batch)
- 使用out计算与label的BCEloss
def adv_loss(logits, target):
assert target in [1, 0]
targets = torch.full_like(logits, fill_value=target)
loss = F.binary_cross_entropy_with_logits(logits, targets)
return loss
- 使用out计算与real image的回归loss (regression loss)
def r1_reg(d_out, x_in):
# zero-centered gradient penalty for real images
batch_size = x_in.size(0)
grad_dout = torch.autograd.grad(
outputs=d_out.sum(), inputs=x_in,
create_graph=True, retain_graph=True, only_inputs=True
)[0] # 输入是image,属于这一类的p
grad_dout2 = grad_dout.pow(2)
assert(grad_dout2.size() == x_in.size())
reg = 0.5 * grad_dout2.view(batch_size, -1).sum(1).mean(0)
return reg
(2)fake image loss
- 首先需要根据上面生成的随机向量经过mapping network生成每个风格风格向量
with torch.no_grad():
if z_trg is not None:
s_trg = nets.mapping_network(z_trg, y_trg)
else: # x_ref is not None
s_trg = nets.style_encoder(x_ref, y_trg)
- mapping network 的输入是随机生成的latent 向量和label,因为mapping network是多分支的,所以有几个domain在network的结尾就有几个分支,之后根据label选择这个分支的结果作为最后的风格向量s_trg。
- 使用得到的风格向量s_trg和当前真实的图进入generator【希望real image转换为inference那样的风格】
- generator在decoder的过程中encoder得到的向量连同风格向量s_trg一起作为decoder的输入生成属于该风格的fake image
- 将fake image和其对应的label输入discriminator【为什么还要输入对应的label,又不是计算loss?——
因为discriminator也是多分支的,要根据真实的label取出预测的这个分支的value】 - 因为是fake image,所以是和0做loss
loss_fake = adv_loss(out, 0)
到这里我们已经计算了三个loss,分别是real image的loss, fake image 的loss 和real image得到的regeression loss,三者加权相加做为最后的discriminator的loss
loss = loss_real + loss_fake + args.lambda_reg * loss_reg
reference image 得到style 向量
latent向量:d_loss, d_losses_latent = compute_d_loss(nets, args, x_real, y_org, y_trg, z_trg=z_trg, masks=masks)
reference image:d_loss, d_losses_ref = compute_d_loss(nets, args, x_real, y_org, y_trg, x_ref=x_ref, masks=masks)
- 【有reference的时候相当于有图像了,不需要根据latent向量经过mapping network生成风格向量,而是使用reference image经过style encoder生成属于该style的风格向量】
- style encoder: reference image经过encoder生成一个向量,该向量再经过多分支得到style 向量,之后根据reference image的label得到最终的style 向量
- real image 根据reference image经过style encoder生成的style向量生成fake image
- 后面的过程和上面相同
5. 训练generator
def compute_g_loss(nets, args, x_real, y_org, y_trg, z_trgs=None, x_refs=None, masks=None):
assert (z_trgs is None) != (x_refs is None)
if z_trgs is not None:
z_trg, z_trg2 = z_trgs
if x_refs is not None:
x_ref, x_ref2 = x_refs
# adversarial loss
if z_trgs is not None:
s_trg = nets.mapping_network(z_trg, y_trg)
else:
s_trg = nets.style_encoder(x_ref, y_trg)
x_fake = nets.generator(x_real, s_trg, masks=masks)
out = nets.discriminator(x_fake, y_trg)
loss_adv = adv_loss(out, 1)
# style reconstruction loss
s_pred = nets.style_encoder(x_fake, y_trg)
loss_sty = torch.mean(torch.abs(s_pred - s_trg))
# diversity sensitive loss
if z_trgs is not None:
s_trg2 = nets.mapping_network(z_trg2, y_trg)
else:
s_trg2 = nets.style_encoder(x_ref2, y_trg)
x_fake2 = nets.generator(x_real, s_trg2, masks=masks)
x_fake2 = x_fake2.detach()
loss_ds = torch.mean(torch.abs(x_fake - x_fake2))
# cycle-consistency loss
masks = nets.fan.get_heatmap(x_fake) if args.w_hpf > 0 else None
s_org = nets.style_encoder(x_real, y_org)
x_rec = nets.generator(x_fake, s_org, masks=masks)
loss_cyc = torch.mean(torch.abs(x_rec - x_real))
loss = loss_adv + args.lambda_sty * loss_sty \
- args.lambda_ds * loss_ds + args.lambda_cyc * loss_cyc
return loss, Munch(adv=loss_adv.item(),
sty=loss_sty.item(),
ds=loss_ds.item(),
cyc=loss_cyc.item())
latent 向量 生成style 向量
(1) adversarial loss
- 将real image和style向量输入generator生成fake image
- fake image 和 他的label经过discriminator辨别得到结果out
- 和上面一样计算BCEloss,但是这里虽然是生成的图,但是我们希望generator生成的fake image骗过discriminator,所以这里是和1做BCEloss:
loss_adv = adv_loss(out, 1)
(2) style restruction loss
- fake image 是我们根据real image 得到的希望的style的图片。
- 现在将fake image输入style encoder 得到这个image的style向量
- 这个向量和前面的真实style之间做loss
loss_sty = torch.mean(torch.abs(s_pred - s_trg))
(3) diversity sensitive loss
之前我们不是reference image都有两个嘛,现在排上用场了,前面我们处理的都是第一个reference,无论是latent 向量还是reference image
- 将第二个latent向量输入mapping network得到style 向量
- 将real image和这个style 向量输入generator生成第二个fake image
- 计算两个fake image之间的loss
loss_ds = torch.mean(torch.abs(x_fake - x_fake2))
我们希望同一张图片被转化为另一个风格都是不一样的,不是每次都是一样的,所以这个loss 我们希望是越大越好的
(4)cycle-consistency loss
- 我们希望real image生成的指定style的fake image经过指定real style 可以返回real image’,所以这里设置了cyclegan-consistency loss
- 根据fake image生成mask
- 使用style encoder得到real image的style向量
- generator根据fake image和real image的style向量生成rec_image
- 计算real image 和 recovery image之间做loss
loss_cyc = torch.mean(torch.abs(x_rec - x_real))
到这里generator的loss全部计算完,一共有四个,分别是对抗loss (loss_adv),风格loss(loss_sty),多样性loss(loss_ds),循环loss(loss_cyc),最终generator的loss为:loss = loss_adv + args.lambda_sty * loss_sty - args.lambda_ds * loss_ds + args.lambda_cyc * loss_cyc
reference image 生成style 向量
latent 向量:g_loss, g_losses_latent = compute_g_loss(nets, args, x_real, y_org, y_trg, z_trgs=[z_trg, z_trg2], masks=masks)
reference image:g_loss, g_losses_ref = compute_g_loss(nets, args, x_real, y_org, y_trg, x_refs=[x_ref, x_ref2], masks=masks)
重点关注!!!!!
-
无论是discriminator 还是generator都有两个过程:
- 使用latent向量经过mapping network生成的style 向量作为最终要转化的style
- 使用reference image经过style encoder生成的style向量作为最终要转化的style
-
无论latent向量还是reference image都是有两个的
debug processing
-
build_model
- generator
- mapping network
- style_encoder
- discriminator
-
data
-
train
okk,又是脑细胞死亡的一天,好饿好饿,886~
完整项目在这里:欢迎造访