从excel中提取嵌入式图片的解决方法
1 发现问题
我的excel中有浮动图片和嵌入式图片,但是openpyxl的_image对象只提取到了浮动图片,通过阅读其源码发现,这是因为openpyxl只解析了drawing文件导致的,所以确定需要自己解析
2 解决思路
1、解析出media资源
2、解析出xml,这可以得到资源的rNvpr-rId-image target的关系
3、从xlrd或openpyxl中得到单元格cNvpr,定位到图片
3 解析xlsx
先把xlsx解压出来,得到的文件如下,其中xl文件夹是我们需要的

我分析了里面的所有文件,发现这两个文件存储了嵌入式图片的关键信息
- xl/cellimages.xml
- xl/_rels/cellimages.xml
打开这两个文件看看,到底存储了什么?
3.1 xl/cellimages.xml
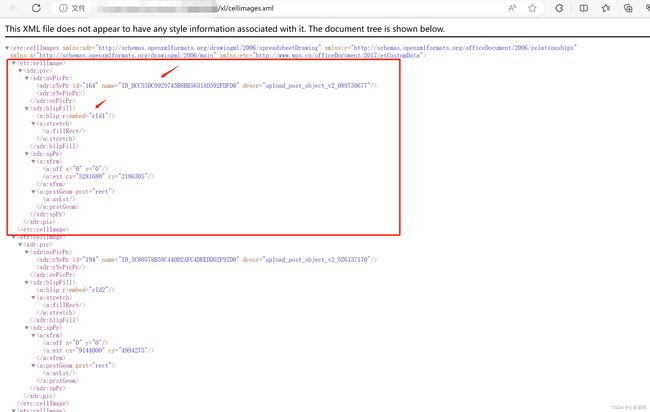
有效信息在cellImage对象中
- cellImage.pic.nvPicPr.cNvPr.name:记录了函数名
- cellImage.pic.blipFill.blip.embed:记录了rId
记录这个关系,并建立映射关系 { ID_xxx: rId }
3.2 xl/_rels/cellimages.xml
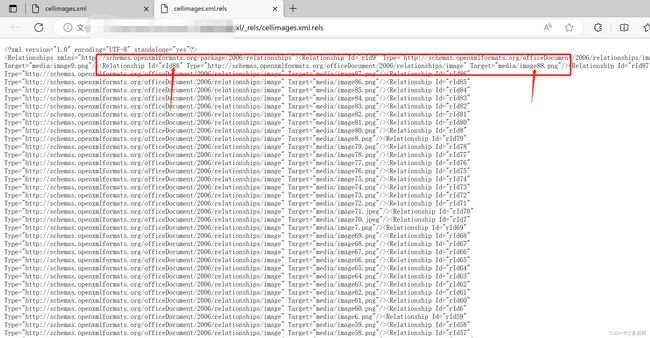
有效信息在Relationship对象中
- Relationship.id:文件rId
- Relationship.target:图片地址
建立这个映射关系 { rId: target }
到这一步我们已经可以从函数名定位到图片资源了,剩下一步建立excel单元格和图片的关系,接下来解析excel文件
{ ID_xxx: rId } + { rId: target } = ID_xxx -> target
4 代码实现
接下来简单的代码实现,有问题可以评论区留言,看到会回复
此实现基于openpyxl
from xml.etree.ElementTree import fromstring
from io import BytesIO
from zipfile import ZipFile
from openpyxl import load_workbook
from openpyxl.packaging.relationship import get_rels_path, get_dependents
from openpyxl.xml.constants import SHEET_DRAWING_NS, REL_NS, IMAGE_NS
from openpyxl.drawing.image import Image, PILImage
def parse_element(element):
"""
将XML解析为 {ID_XXX: rId}
:param element:
:return:
"""
data = {}
xdr_namespace = "{%s}" % SHEET_DRAWING_NS
targets = level_order_traversal(element, xdr_namespace + "nvPicPr")
for target in targets:
# 是一个cellimage
cNvPr = embed = ""
for child in target:
if child.tag == xdr_namespace + "nvPicPr":
cNvPr = child[0].attrib["name"]
elif child.tag == xdr_namespace + "blipFill":
_rel_embed = "{%s}embed" % REL_NS
embed = child[0].attrib[_rel_embed]
if cNvPr:
data[cNvPr] = embed
return data
def level_order_traversal(root, flag):
"""层次遍历,查找目标节点"""
queue = [root]
targets = []
while queue:
node = queue.pop(0)
children = [child.tag for child in node]
if flag in children:
targets.append(node)
continue
for child in node:
queue.append(child)
return targets
def handle_images(deps, archive) -> []:
"""
将图片二进制内容封装为Image对象
"""
images = []
if not PILImage: # Pillow not installed, drop images
return images
for dep in deps:
if dep.Type != IMAGE_NS:
msg = "{0} image format is not supported so the image is being dropped".format(dep.Type)
print(msg)
continue
try:
image_io = archive.read(dep.target)
image = Image(BytesIO(image_io))
except OSError:
msg = "The image {0} will be removed because it cannot be read".format(dep.target)
print(msg)
continue
if image.format.upper() == "WMF": # cannot save
msg = "{0} image format is not supported so the image is being dropped".format(image.format)
print(msg)
continue
image.embed = dep.id # 文件rId
image.target = dep.target # 文件地址
images.append(image)
return images
def main():
CELLIMAGE_PATH = "xl/cellimages.xml"
PARSE_FILE_PATH = 'C:/Users/user/Downloads/TCI验收问题.xlsx'
archive = ZipFile(PARSE_FILE_PATH, "r")
wb = load_workbook(PARSE_FILE_PATH)
src = archive.read(CELLIMAGE_PATH) # 打开cellImage.xml文件
deps = get_dependents(archive, get_rels_path(CELLIMAGE_PATH)) # 解析cellImage.xml._rel文件
image_rels = handle_images(deps=deps.Relationship, archive=archive)
node = fromstring(src)
cellimages_xml = parse_element(node)
cellimages_rel = {}
for image in image_rels:
cellimages_rel[image.embed] = image
for cnvpr, embed in cellimages_xml.items():
cellimages_xml[cnvpr] = cellimages_rel.get(embed)
# df = pd.read_excel(PARSE_FILE_PATH)
# df["行号"] = df.index + 2
# image_mappings = ParserXLSXEmbed(wb=wb, df=df).extract_images(start_from=max(0, 1) + 1)
# image_mappings.update(cellimages_xml)
archive.close() # 关闭压缩文件对象,防止内存泄漏
print(cellimages_xml)
if __name__ == '__main__':
main()