《Hadoop权威指南》学习笔记(1)——初始Hadoop及了解MapReduce
注:因为Hadoop中的代码实现用java较为方便,并且书中代码用java实现的解释较为容易理解,所以,在博客中的代码实现均会使用java。
第1章 初识Hadoop
我们为什么需要Hadoop
我们生活在一个数据爆炸的时代,现代每天产生的数据量甚至要超过从商周到清代产生的数据的总和。在这样一个时代,数据即是机遇,如何存储更多的数据,如何快速的对数据进行分析提取,就成了一个无法避免的问题。此外,我们注意到近年来硬盘的存储容量不断上升,而相应的数据读取速率却没有那么快的增长。
因此,我们需要一个工具来解决以上这些问题,Hadoop就充当了这一角色。
Hadoop的起源
Hadoop起源于Nutch项目,开始的Hadoop只有MapReduce、HDFS等核心部分,而伴随着越来越多人参与到Hadoop开发社区中来,Hadoop的技术生态圈日益壮大,如今的Hadoop已经拥有了相当多且实用的组件,如Spark、Flume等。
第2章 关于MapReduce
MapReduce是一种用于大规模数据处理的编程模型。
它通过“Map(映射)”和“Reduce(规约)”两个步骤来使程序可以运行在分布式系统上实现并行处理。
map和reduce
map和reduce是MapReduce的两个处理阶段,每个阶段都以键-值对作为上输入和输出。要实现这两个阶段,我们需要写两个函数:map函数和reduce函数。
map函数用来从给出的数据集中读取出我们所需的数据,并且对缺失值、错误值进行分析和筛除,然后输出。
在map函数和reduce函数中间还可以有一些函数来对数据进行一定程度的处理(如排序和分组),然后将结果传给reduce函数。
reduce函数根据需求对得到的数据进行处理,然后得到的结果输出。
下面是一张简单的示意图:

一个实例
从一个庞大的气象数据集中提取出每年的气象信息,使用来自NCDC(美国国家气候数据中心)的数据的格式。
原始数据过于庞大,不便于观察结果,理解MapReduce的实现因此只选取少量的几组数据。
数据以键-值对形式给出,如下:
(正式的数据可以从NCDC下载,这里的数据不全,若用这个,要对程序进行适当改动)
(0, 0067011990999991950051507004…9999999N9+00001+9999…)
(106, 0043011990999991950051512004…9999999N9+00221+9999…)
(212, 0043011990999991950051518004…9999999N9+00111+9999…)
(318, 0043012650999991949032412004…0500001N9+01111+9999…)
(424, 0043012650999991949032418004…0500001N9+00781+9999…)
其中key为行偏移量,map不需要它。加粗数字分别为年份和气温,是我们需要的,将它们提取出来输出。
//org.apache.hadoop.io包中包括了Hadoop本身提供的一套可优化的基本类型
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper
extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable>{
//四个形参分别指定map函数的输入键、输入值、输出键和输出值的类型
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if(line.charAt(87) == '+'){
airTemperature = Integer.parseInt(line.substring(88, 92));
}else{
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if(airTemperature != MISSING && quality.matches("[01459]")){
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
//四个形参指定输入类型和输出类型,reduce的输入类型要匹配map的输出类型
@Override
public void reduce(Text day, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException{
int maxValue = Integer.MIN_VALUE;
for(IntWritable value: values){
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop,mapreduce.input.FileOutputFormat;
public class MaxTemperature{
public static void main(String[] args) throws Exception{
if(args.length != 2){
System.err.println("Usage: MaxTemperature );
System.exit(-1);
}
//Job指定作业规范,用来控制整个作业的运行
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max Temperature");
//指定输入和输出路径,输入路径可多次指定实现多路径输入,而输出路径只能指定一个
//注意:运行前,输出目录是不应存在的
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定要用的map类型和reduce类型
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
//控制reduce函数的输出类型,且必须与Reduce类相匹配
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//map函数的输出类型默认情况下与reduce函数相同,
//而若mapper和reducer类型不同,则要单独设置
//提交作业并等待执行完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
更加深入一些
上面的程序显然只能在一台机器上处理少量数据,而在实际工作中,一定会有一个Hadoop集群和大量输入的数据流。所以我们要将数据分块存储在分布式文件系统中。
Hadoop将MapReduce的输入的数据划分成等长的小数据块,称为分片。
通过分片将输入数据的处理分成多个任务交给不同的计算机来进行并行处理,从而减少完成所有数据分析的所需时间。
合理的分片大小趋向于HDFS的一个块的大小,默认是128MB。
那么,为什么最佳分片应与快大小相同呢?
因为它是确保可以存储在单个结点上的最大输入块大小。若分片跨越两数据块,那么分片中的部分数据需要通过网络传输到map任务运行的节点,显然效率会降低。
map任务的输出是写入本地硬盘而非HDFS的,这是因为map输出的是中间结果,要经由reduce任务处理后才产生最终输出结果,而一旦作业完成,中间结果即可删除。
reduce任务的数量并非由输入数据大小决定,而是独立指定的。如何指定之后会介绍。
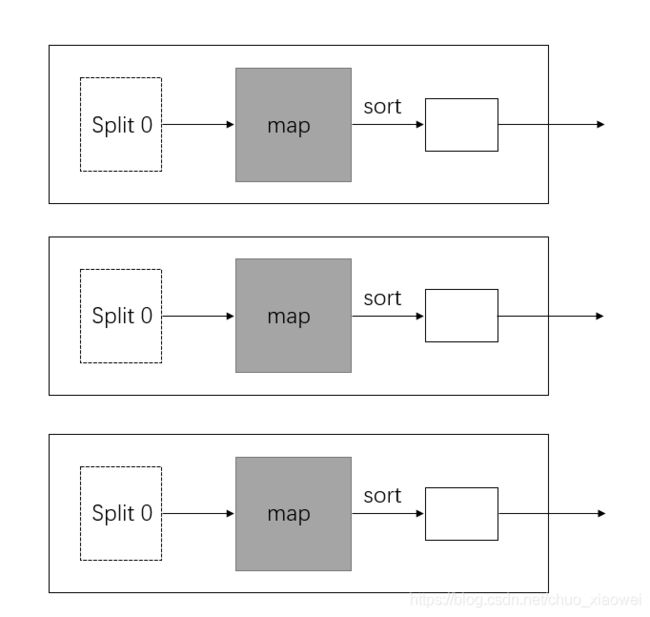
不同数量的reduce任务的情况
一个reduce任务的MapReduce数据流:

多个reduce任务的数据流:

无reduce任务的MapReduce数据流:
combiner函数
集群上的可用带宽限制了MapReduce作业的数量,因此要尽量避免map和reduce任务之间的数据传输。
一种优化方案是:针对map任务的输出指定一个combiner,combiner函数的输出作为reduce函数的输入。
Hadoop无法确定要对一个指定的map任务输出记录调用多少次combiner(若需要),所以,无论调用combiner多少次,reduce的输出结果均一样。
combiner函数不能取代reduce函数,因为不同map输出中具有相同键的记录仍需要reduce函数来处理,甚至有时使用combiner函数会干扰正确的结果。但combiner函数能帮助减少map和reduce之间的数据传输量。因此,在MapReduce作业中使用combiner函数与否需要斟酌。
combiner是通过Reducer类来定义的。对于上面的实例,combiner函数与reduce函数实现相同,在代码中指定combiner,只需要在上面的主函数中加一行即可。
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop,mapreduce.input.FileOutputFormat;
public class MaxTemperatureWithCombiner{
public static void main(String[] args) throws Exception{
if(args.length != 2){
System.err.println("Usage: MaxTemperatureWithCombiner " +
");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max Temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}