原文来自 https://karpathy.medium.com/software-2-0-a64152b37c35, 作者是 Andrej Karpathy
有时候我看到有人把神经网络仅仅看作是“机器学习工具箱中的另一个工具”。它们有一些优点和缺点,可以在这里或那里发挥作用,有时候你可以用它们赢得 Kaggle 比赛。然而,这种解释完全忽视了树木,只看到了森林。神经网络不仅仅是另一种分类器,它们代表着我们在软件开发方式上发生的根本性转变。它们是软件2.0。
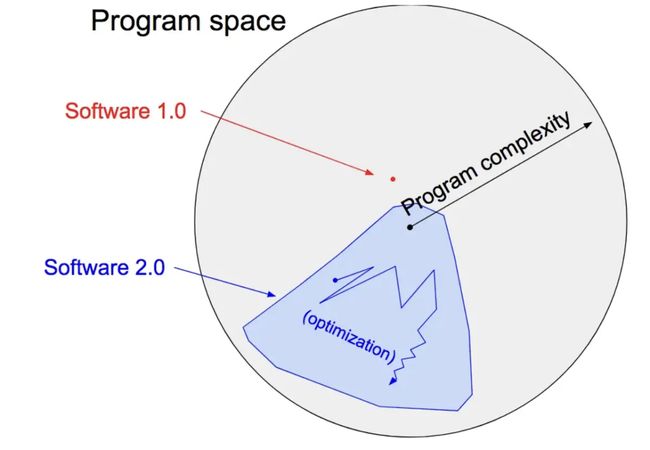
“经典栈”的软件1.0是我们都熟悉的——它使用诸如Python、C++等语言编写。它由程序员编写的计算机显式指令组成。通过编写每一行代码,程序员确定了程序空间中具有某种理想行为的特定点。
相比之下,Software 2.0 则是用更加抽象和不太适合人类理解的语言编写的,比如神经网络的权重。没有人类参与编写这些代码,因为权重非常多(典型的神经网络可能有数百万个),而且直接用权重进行编码相当困难(我曾尝试过)。
相反,我们的方法是对理想程序的行为设定一些目标(例如,“满足输入输出示例数据集”或“赢得围棋比赛”),编写代码的大致框架(即神经网络架构),以此来确定程序空间的一个子集进行搜索,并利用我们拥有的计算资源来搜索这个空间,寻找一个有效的程序。对于神经网络,我们将搜索范围限制在程序空间的一个连续子集,通过反向传播和随机梯度下降这一(有些令人惊讶的)高效搜索过程。
为了明确这个类比,在软件1.0中,由人工编写的源代码(例如一些.cpp文件)被编译成可执行二进制文件,从而完成实用的工作。而在软件2.0中,源代码通常由以下两部分组成:1)定义所需行为的数据集,2)提供了代码大致框架的神经网络架构,但具体细节(权重)还需要填充。训练神经网络的过程就像将数据集编译成最终的二进制文件——即最终的神经网络。在当今大多数实际应用中,神经网络架构和训练系统越来越趋于标准化,成为一种商品,因此大部分活跃的“软件开发”采取的形式是对带有标签的数据集进行策划、增长、处理和清洗。这从根本上改变了我们迭代软件的编程范式,因为团队分成了两部分:2.0程序员(数据标记者)负责编辑和增加数据集,而少数1.0程序员则负责维护和迭代周围的训练代码基础设施、分析、可视化和标注接口。
事实证明,很大一部分实际世界中的问题具有这样的特性:收集数据(或更一般地说,确定所需行为)比显式编写程序要容易得多。正因为如此以及下文中提到的软件2.0的许多其他优点,我们正在目睹整个行业发生巨大的转变,许多1.0代码被转换为2.0代码。软件(1.0)正在主宰世界,而现在AI(软件2.0)正在吞噬软件。
正在进行的转变
让我们简要地看一些具体的例子,说明这个正在进行的转变。在这些领域中,当我们放弃试图通过编写显式代码来解决复杂问题,并将代码转换为2.0堆栈时,我们在过去几年中已经看到了一些改进。
视觉识别: 过去通常是由经过工程化处理的特征组成,最后加上一点机器学习的技巧(例如,SVM)。自那时以来,我们通过获取大型数据集(例如ImageNet)并在卷积神经网络架构空间中进行搜索,发现了更强大的视觉特征。最近,我们甚至不再相信自己能手工编码这些架构,我们已经开始对它们进行搜索。
语音识别: 过去涉及大量预处理、高斯混合模型和隐马尔可夫模型,但今天几乎完全由神经网络组成。一个与之相关且常被引用的幽默语录据说是来自1985年的Fred Jelinek:“每次我解雇一个语言学家,我们的语音识别系统性能都会提高”。
语音合成: 在历史上采用了各种拼接机制,但如今,最先进的模型是大型卷积神经网络(例如WaveNet),可以生成原始音频信号输出。
机器翻译: 通常采用基于短语的统计技术,但神经网络正在迅速成为主导。我最喜欢的架构是在多语言环境中进行训练的,一个模型可以从任何源语言翻译到任何目标语言,在弱监督(或完全无监督)的情况下进行训练。
游戏: 过去,人工编码的围棋程序已经开发了很长一段时间,但是现在AlphaGo Zero(一个查看棋盘的原始状态并进行下棋的卷积神经网络)已经成为迄今为止最强大的围棋选手。我预计我们在其他领域,例如DOTA 2或星际争霸中也会看到非常类似的结果。****
数据库: 在人工智能之外的更传统系统也出现了早期的转变迹象。例如,“学习索引结构的案例”用神经网络替换了数据管理系统的核心组件,在速度上比优化缓存的B-树提高了多达70%,同时节省了数量级的内存。****
上面提到的许多链接都涉及到了谷歌的工作。这是因为谷歌目前处于将自己大部分内容重写为软件2.0代码的前沿。“一个模型统领天下”(One model to rule them all)提供了一个早期的草图,展示了这种转变可能的样子,其中各个领域的统计强度被融合为对世界的一致理解。
软件2.0的优势
为什么我们应该倾向于将复杂程序转换为软件2.0呢?显然,一个简单的答案是,在实践中它们表现更好。然而,还有许多其他便利的理由支持这种堆栈的选择。让我们来看一下软件2.0(比如:ConvNet)相对于软件1.0(比如:生产级别的C++代码库)的一些优点。软件2.0的特点包括:
- 计算上的同质性
一个典型的神经网络在一级上由两种操作组成:矩阵乘法和零阈值(ReLU)处理。相比之下,传统软件的指令集更加异构和复杂。因为你只需要为一小部分核心计算原语(比如矩阵乘法)提供软件1.0的实现,所以更容易做出各种正确性和性能保证。
- 容易融入芯片
作为必然结果,由于神经网络的指令集相对较小,因此在更接近芯片的位置实现这些网络要容易得多,例如使用定制的ASIC、神经形态芯片等。当低功耗智能在我们周围广泛应用时,世界将发生变化。例如,小型廉价芯片可以带有预训练的ConvNet、语音识别器和 WaveNet语音合成网络,全部集成在一个小型原型脑(protobrain)中,你可以将它附加到各种设备上。
- 运行时间恒定
典型神经网络前向传播的每次迭代所需的FLOPS完全相同。与通过一些庞大的C++代码库可能采用的不同执行路径相比,这里没有变动性。当然,你可以有动态计算图,但执行流程通常仍然受到相当多的限制。这样我们几乎可以保证永远不会意外陷入无限循环。
- 内存使用恒定
与上述相对应,这里没有任何动态分配的内存,因此也很少有交换到磁盘的可能性,或者你需要在代码中追踪的内存泄漏。
- 高度可移植
与传统的二进制文件或脚本相比,一系列矩阵乘法在任意计算配置上运行要容易得多。
- 非常灵活
如果你有一个C++代码,有人想让你让它的运行速度变快两倍(如果需要可以牺牲性能),那么为新规格调整系统将非常复杂。然而,在软件2.0中,我们可以拿出我们的网络,移除一半的通道,重新训练,然后它就以正好两倍的速度运行,并且效果稍微差一些。这就是魔法所在。相反,如果你得到更多的数据/计算资源,只需添加更多的通道并重新训练,就可以立即使你的程序变得更好。
- 模块可以融合成最佳整体
我们的软件通常被分解为通过公共函数、API或端点进行通信的模块。然而,如果两个最初分别训练的软件2.0模块进行交互,我们可以很容易地回传整体。想象一下,如果你的网络浏览器可以自动重新设计10层下的低级系统指令,以实现更高效地加载网页,那会是多么令人惊奇。或者如果你导入的计算机视觉库(如OpenCV)可以根据你的具体数据进行自动调优。在2.0中,这是默认行为。
- 优于人类智能
最后,也是最重要的一点,神经网络在很大一部分有价值的垂直领域中是比你我能想出的任何代码都要优秀的,这些领域目前至少涉及到图像/视频和声音/语音。
软件2.0的局限性
软件2.0堆栈也有一些自身的缺点。在优化结束时,我们得到了良好工作的大型网络,但很难弄清楚其工作原理。在许多应用领域,我们将面临一个选择:使用我们理解的90%准确的模型,还是不理解的99%准确的模型。
软件2.0堆栈可能以不直观和尴尬的方式失败,或者更糟糕的是,它们可能“默默失败”(silently fail),例如,在其训练数据中悄然采用偏见(biases),在大多数情况下,当其大小通常达到数百万时,这些偏见非常难以正确分析和检查。
最后,我们仍然在发现这个技术栈的一些奇特特性。例如,对抗性例子和攻击的存在凸显了这个技术栈的非直观性质 ( unintuitive nature) 。
在2.0 技术栈中编程
软件1.0是我们编写的代码。软件2.0是根据评估标准(例如“正确分类这些训练数据”)进行优化后编写的代码。 任何设置中,只要程序不是显而易见的,但可以反复评估其性能(例如——你是否正确分类了一些图像?你能赢得围棋游戏吗?)都可能受到这种转变的影响,因为优化可以找到比人类编写的代码更好的代码。
我们观察趋势的角度很重要。如果你将软件2.0视为一个新兴的编程范式,而不仅仅将神经网络视为机器学习技术类别中的一个相当不错的分类器,那么推断变得更加明显,而且很明显还有很多工作要做。
特别地,我们已经建立了大量的工具来帮助人类编写1.0代码,例如拥有诸如语法高亮、调试器、性能分析工具、跳转到定义、Git集成等功能的强大IDE。在2.0堆栈中,编程是通过积累、处理和清洗数据集来完成的。例如,当网络在某些复杂或罕见的情况下失败时,我们不会通过编写代码来修复这些预测,而是通过包含更多这些情况的标记示例来解决。谁会开发第一个适用于所有数据集累积、可视化、清洗、标记和获取的软件2.0 IDE呢?也许IDE会根据每个示例的损失值推测哪些图像被网络错误标记,或通过使用预测结果为标签初始化标记过程,或者根据网络预测的不确定性建议有用的示例进行标记。
同样地,Github是一个非常成功的软件1.0代码托管平台。是否有空间适用于软件2.0的 github 呢?在这种情况下,代码库是数据集,提交是标签的添加和编辑。
传统的软件包管理器以及与之相关的服务基础设施,如pip、conda、docker等,帮助我们更轻松地部署和组合二进制文件。那么我们如何有效地部署、共享、导入和处理软件2.0二进制文件呢?对于神经网络来说,有什么类似于conda的工具呢?
在短期内,只要有可能且成本较低地进行重复评估,以及算法本身难以明确设计的任何领域,软件2.0将越来越普遍。在这个新的编程范式下,有许多令人兴奋的机会,可以考虑整个软件开发生态系统,并将其适应这种新的编程范式。从长远来看,这个范式的未来是光明的,因为越来越清楚的是,当我们开发通用人工智能(AGI)时,它肯定会是由软件2.0编写的。
本文翻译自 https://karpathy.medium.com/software-2-0-a64152b37c35, 版权归其作者 Andrej Karpathy