TOPSIS法
TOPSIS法
文章目录
- TOPSIS法
-
-
- TOPSIS法的三点解释
- 增加指标个数
- 1.统一指标类型
-
- 极小型指标转换为极大型指标的公式
- 中间型指标转换为极大型指标的公式
- 区间型指标转换为极大型指标的公式
- 2.正向化矩阵标准化
- 3.计算得分并归一化
- 类比只有一个指标计算得分
- TOPSIS法代码
-
- 统一指标类型
-
- 判断是否需要正向化
- Positivization函数
- Min2Max函数
- Mid2Max函数
- inter2Max函数
- 对正向化的矩阵进行标准化
- 计算与最大值的距离和最小值的距离,并算出得分
-
TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution) 可翻译为逼近理想解排序法,国内常简称为优劣解距离法。是一种常用的综合评价方法,其能充分利用原始数据的信息, 其结果能精确地反映各评价方案之间的差距。
根据层次分析法的局限性:

- 在层次分析法中,需要根据方案层去推算准成层(决策层)。但评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异 可能会很大,平均随机一致性指标RI的表格中n的个数最多是15
- 若决策层中指标的数据是已知的,那么我们如何利用这些数据来使得评价的更加准确呢?我们使用层次分析法是通过查找数据计算推导决策层和目标层,然而当决策层中的指标数据是已知的,层次分析法的价值就不再体现。而TOPSIS法可以很好的应对这一点
TOPSIS法的三点解释
- 比较的对象一般要远大于两个。(例如比较一个班级的成绩)
- 比较的指标也往往不只是一个方面的,例如成绩、工时数、课外竞赛得分等。
- 有很多指标不存在理论上的最大值和最小值,例如衡量经济增 长水平的指标:GDP增速。出现这样的指标时就不适用TOPSIS法
构造计算评分的公式:
x − m i n / m a x − m i n x-min/max-min x−min/max−min

现用topsis法描述一个成绩单如上图所示
增加指标个数
若增加了指标,不再以单一指标来评分,那要怎么做呢?

- 首先我们要明确指标的类型
最常见的四种指标:
| 指标名称 | 指标特点 | 例子 |
|---|---|---|
| 极大型(效益型)指标 | 越大(多)越好 | 成绩、GDP增速、企业利润 |
| 极小型(成本型)指标 | 越小(少)越好 | 费用、坏品率、污染程度 |
| 中间型指标 | 越接近某个值越好 | 水质量评估时的PH值 |
| 区间型指标 | 落在某个区间最好 | 体温、水中植物性营养物量 |
- 我们需要将不同的指标统一化
1.统一指标类型
- 将所有指标转换为极大型称为指标正向化
极小型指标转换为极大型指标的公式
m a x − x max-x max−x
- 如果所有的元素均为正数,那么也可以用1/x
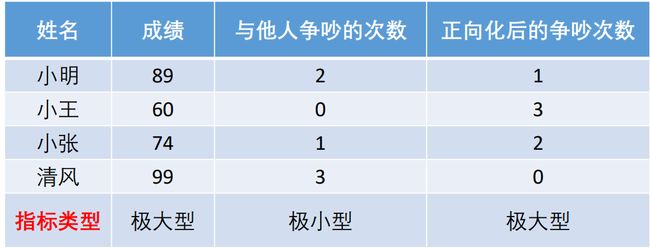
如图所示成绩是极大型指标,与他人争吵的次数是极小型指标,现将与他人争吵的次数转换为极大型指标
中间型指标转换为极大型指标的公式
指标值即不要太大也不要太小,取某特定值最好(如水质量评估PH值)
{xi}是一组中间型指标,且最佳的数值为xbest,那么正向化的公式为
M = m a x { ∣ x i − x b e s t ∣ } , x i r e t = 1 − ∣ x i − x b e s t ∣ / M M=max\{{|x_i-x_{best}|}\},x^{ret}_i=1-|x_i-x_{best}|/M M=max{∣xi−xbest∣},xiret=1−∣xi−xbest∣/M

根据公式将中间型指标PH转换位大型指标
区间型指标转换为极大型指标的公式
区间型指标指标值落在某个区间内最好,例如人的体温在36°~37°这个区间比较好。
{xi}是一组区间型指标,且最佳的区间为[a,b],那么正向化的公式为
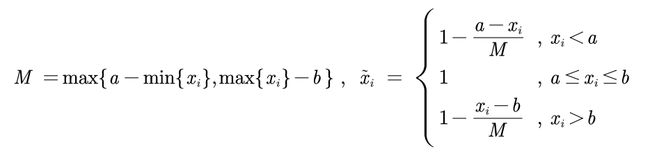

根据公式将区间型指标体温转换为极大型指标
2.正向化矩阵标准化
- 标准化的目的是消除不同指标量纲的影响

- 根据已经正向化的评价指标构建一个正向化矩阵X,然后将改矩阵X标准化,标准化的矩阵为Z
3.计算得分并归一化

-
标准化矩阵Z有n行,行数n对应n个评价对象,m列,列数m对应m个评价指标
-
定义的最大值Z+的元素和最小值Z-的元素指的是在同一个指标内的对象相比得出最大值和最小值元素,即在列内取出最大值或最小值。取出来后构成最大值矩阵Z+和最小值矩阵Z-。注意这里的两个矩阵都为行矩阵
-
定义的最大距离Di+内的Zj+-Zij指的是在同一列中的最大值减去当前位置的元素。相应的Di-内的Zj--Zij指的是同一列中的最小值减去当前位置的元素
-
计算得出最大值和最小值后,要进行归一化。归一化的得分为Si.且Si越大,Di+越小,说明越接近最大值
类比只有一个指标计算得分
当只需要对一个指标计算得分时,计算元素时需要计算权重

TOPSIS法代码
统一指标类型
在统一指标时先需要判断多个指标中是否存在极大型指标,若不存在则不需要进行正向化处理
判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);
if Judge == 1
Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: ');
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')
Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: ');
for i = 1 : size(Position,2)
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));
end
-
[n,m] 接收X矩阵的行数n和列数m
-
Judge接收1表示矩阵X内有列向量需要正向化处理,接收0则不需要
-
Position接收一个向量,向量元素为需要进行正向化处理的向量的列数
-
Type接收对应需要进行正向化处理的向量的指标类型
-
从1开始遍历,遍历完需要进行正向化处理的向量若Position为3,那么需要遍历3次
-
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i))表示:
-
- 按列遍历X矩阵的所有元素,将X矩阵的对应正向化处理的向量、需要将什么类型的向量正向化、需要处理向量的列数作为参数传参給Positivization函数
Positivization函数
function [posit_x] = Positivization(x,type,i)
if type == 1 %极小型
disp(['第' num2str(i) '列是极小型,正在正向化'] )
posit_x = Min2Max(x); %调用Min2Max函数来正向化
disp(['第' num2str(i) '列极小型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 2 %中间型
disp(['第' num2str(i) '列是中间型'] )
best = input('请输入最佳的那一个值: ');
posit_x = Mid2Max(x,best);
disp(['第' num2str(i) '列中间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 3 %区间型
disp(['第' num2str(i) '列是区间型'] )
a = input('请输入区间的下界: ');
b = input('请输入区间的上界: ');
posit_x = Inter2Max(x,a,b);
disp(['第' num2str(i) '列区间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
else
disp('没有这种类型的指标,请检查Type向量中是否有除了1、2、3之外的其他值')
end
end
- function [posit_x] = Positivization(x,type,i)是matlab使用函数的函数体。模板是
function [输出变量] = 函数名称(输入变量) - 函数里调用三种函数Min2Max(x)(极小值指标转换为极大值指标)、 Mid2Max(中间型指标转换为极大型指标)、Inter2Max(x,a,b)区间型指标转换为极大型指标
Min2Max函数
function [posit_x] = Min2Max(x)
posit_x = max(x) - x;
%posit_x = 1 ./ x; %如果x全部都大于0,也可以这样正向化
end
Mid2Max函数
function [posit_x] = Mid2Max(x,best)
M = max(abs(x-best));
posit_x = 1 - abs(x-best) / M;
end
inter2Max函数
function [posit_x] = Inter2Max(x,a,b)
r_x = size(x,1); % row of x
M = max([a-min(x),max(x)-b]);
posit_x = zeros(r_x,1); % 初始化posit_x全为0 初始化的目的是节省处理时间
for i = 1: r_x
if x(i) < a
posit_x(i) = 1-(a-x(i))/M;
elseif x(i) > b
posit_x(i) = 1-(x(i)-b)/M;
else
posit_x(i) = 1;
end
end
end
- r_x为x向量的行数
- posit_x为x向量相同大小的0向量
对正向化的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ] .* repmat(weigh,n,1) ,2) .^ 0.5;
%D+与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ] .* repmat(weigh,n,1) ,2) .^ 0.5;
% D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')