「从零入门推荐系统」22:chatGPT、大模型在推荐系统中的应用
作者 | gongyouliu
编辑 | gongyouliu
提示:全文2.5万字,预计阅读时长2小时,可以先收藏再慢慢阅读。
我们在上一章介绍了chatGPT、大模型的基本概念、核心技术原理等基础知识,有了这些背景知识的铺垫,下面我们来介绍chatGPT、大模型在推荐系统中的应用,为了简单起见下面我们将chatGPT、大模型应用于推荐系统统称为大模型在推荐系统中的应用(其实大家都知道驱动chatGPT的底层技术也是大模型——基于GPT-3.5演化而来,只不过chatGPT基于对话进行了特定的优化,最终采用对话的方式为用户提供服务,这种方式可以革新传统的推荐系统交互逻辑,22.2.3节我们会讲到)。
预训练语言模型(Pre-trained Language Models,PLM)当模型参数、训练数据量增大后,会在下游任务中表现出一些独特的能力,比如复杂推理、知识发现、通用常识理解等。在学术界,当模型规模变大时(一般参数至少要超过10B,也就是100亿),出现前面提到的这些能力叫做能力涌现(emergent,关于能力涌现的介绍见参考文献1),具备这些能力的模型才是真正意义上的大模型(Large Language Models,LLM)。
能力涌现是一个非常重大的发现和突破。大模型通过海量数据的预训练(pre-training),学习到了一些基础的能力,预训练好的大模型具备通用的能力,可以应对一些没有进行针对性训练的下游任务(比如预训练后直接用于翻译),那么我们自然想到能不能用大模型做个性化推荐(因为对chatGPT、GPT-4等大模型来说,推荐系统也是一个下游任务)。
上面这个想法其实是可行的,目前有很多相关论文已经在利用大模型来解决推荐系统问题了,虽然目前的研究主要集中在学术界,但在不久的将来,我相信大模型一定能应用在企业级推荐系统中,就像深度学习在刚出现时也是在学术上进行推荐系统探索,最终工业界最主流的推荐算法都被深度学习推荐算法革新了。我认为大模型对推荐系统的革新会跟深度学习对推荐系统的革新如出一辙。
作者最近2个月通过研读非常多的大模型应用于推荐系统的论文,对大模型应用于推荐系统非常看好。本章基于作者自己的理解并结合众多论文来讲解大模型在推荐系统中的应用,让读者了解大模型怎么用于推荐系统,这个趋势是势不可挡的,提前让读者熟悉,也可以给读者更多的警示,希望读者多关注这方面的技术成果和应用场景落地。
具体来说,本章我们会从大模型为什么能应用于推荐系统、大模型在推荐系统上的应用方法、大模型应用于推荐系统的问题及挑战、大模型推荐系统的发展趋势与行业应用等4个维度来展开。希望读者通过本章的学习,了解大模型与推荐系统的关系。本章算是一个入门的综述,希望读者后面可以多花时间学习、研究、跟进并实践大模型推荐系统。
在讲解之前,这里提一下,我们本章的大模型推荐系统是一个比较宽泛的概念,利用BERT、T5、GPT系列、LLaMA系列等较大的预训练模型进行个性化推荐都在本章的讨论范围之内。
22.1 大模型为什么能应用于推荐系统
大模型是通过海量的互联网文本信息,通过在底层构建Transformer语言架构,预测下一个token(token可能是一个单词也可能是一个单词的一部分)出现的概率来训练模型的。由于有海量互联网文本数据,模型的训练过程不需要人工标注(当然是需要对数据进行预处理的),一旦模型完成预训练就可以用于解决语言理解和语言生成任务。简单来说,大模型基于海量文本中token序列中下一个token出现的概率进行统计建模,来学习在给定语言片段后出现下一个token的概率来解决下游任务(比如摘要、翻译、生成文本等)。
对于推荐系统,用户过往的操作行为其实就是一个有序的序列,每个用户的操作序列类似于一篇文本,所有用户的操作行为序列类似于大模型的训练语料库。那么预测用户下一个操作行为就类似于预测词序列的下一个token(这里推荐系统的物品类似语言模型中的一个token)。通过这个简单的类比,我们就知道推荐系统是可以嵌入到大模型的理论框架中的。因此,直观地看,大模型一定是可以用于解决推荐系统问题的。我们在下面22.2.3.1节介绍的BERT4Rec模型就是这么做的。
上面的这个思路算比较简单,只用到了用户与物品的交互信息。实际上,推荐系统的数据来源更复杂,除了有上面提到的用户交互序列,还有用户画像信息、物品画像信息等。部分用户画像、物品画像信息(比如用户的年龄、性别、偏好等,物品的标题、标签、描述文本等)也可以利用自然语言来呈现,行为交互序列、用户画像、物品画像等信息都可以输入到大模型中给大模型提供更多的背景知识,这样获得的推荐会更加精准。
推荐系统涉及到的数据很多都是多模态的(比如物品有描述文本、有图片、甚至有介绍的视频等),这些异构的信息对于推荐系统的效果相当重要(特定的深度学习推荐算法能够利用多种信息进行推荐系统建模)。当前的大模型以处理文本数据为主,还无法很好地处理多模态数据(虽然GPT-4具备部分多模态能力,midjourney、runway的Gen-2等能够基于文本生成图片、视频等),因此,利用大模型解决好推荐系统相关的问题、带来比较好的业务效果也是任重道远的。
虽然大模型暂时还无法充分利用推荐系统的所有多模态数据,但是利用好文本数据就已经很强大了。大模型最强大之处是具备zero-shot、few-shot的能力(简单解释一下,zero-shot就是预训练后直接可以解决未知下游任务,few-shot就是给出几个式例,大模型可以解决类似的问题,即所谓的in-context learning能力,也就是举一反三的能力)。这个两个强大的能力是可以用于解决推荐问题的,有很多论文就是利用了大模型这两个能力进行推荐,只不过需要在使用大模型过程中设计一些prompt(提示)和模板(template)来激活大模型的推荐能力(这里说一下我个人对激活的理解,大模型有上百亿、上千亿、甚至上万亿参数,是一个非常庞大的神经网络,当用一些prompt告诉大模型作为一个推荐系统角色进行推荐时,就激活了深度神经网络中的某些连接,这些连接是神经网络的某个子网络,而这个子网络具备进行个性化推荐的能力,这个过程非常类似人类大脑神经元的工作机制,比如你看到美食时,就会激活大脑中负责进食的区域——这个区域是大脑整个复杂神经元网络的子网络,导致看到美食可能流口水、吞咽等行为,这里看到美食就类似大模型的prompt)。对于few-shot可能更复杂一些,需要在prompt中告诉大模型一些怎么进行推荐的案例(比如用户看了A、B、C三个视频后,会看另外一个视频D),让它临时学习怎么做推荐。
prompt学习是没有改变大模型的参数的(即没有进行梯度下降的反向传播训练),但为什么具备few-shot的能力呢?这还是上面说的,prompt作为一个整体,激活了大模型神经网络的某个功能区域。大模型具备多伦对话能力的道理也是类似的,我们可以将多伦对话作为一个整体,这个整体激活了大模型在某个对话主题下的功能区域,导致大模型能“记住”(因为是将这个对话作为整体输入大模型的)多伦对话之前的信息。但是这个对话中的新信息是没有被大模型学习到的,因为目前的大模型不具备增量学习的能力(也就是遇到一个新信息马上学习到了模型的参数中,人是具备增量学习能力的,增量学习肯定是大模型未来最重要的一个发展方向)。
另外,大模型还可以帮助缓解数据稀疏性问题,特别是冷启动问题(因为大模型学习的是海量的互联网的知识,对于新物品、新用户都可以很好应对冷启动问题,我们下面会讲解),这是当前深度学习推荐模型的主要瓶颈。通过从不同模型架构中学习的预训练模型中提取和迁移知识,可以在从通用性、稀疏性、效率和有效性等多个角度提高推荐系统的性能。
大模型另外一个很大的优势是可以利用对话的方式跟用户互动,就如chatGPT所呈现的那样,如果能将推荐系统设计成一个跟用户互动的对话式推荐引擎,那么大模型可以利用自然语言响应用户的个性化需求,从而提高用户整体体验和参与度。
通过上面的介绍,相信读者能够大致知道为什么大模型可以应用于推荐系统了,也知道了大模型应用于推荐系统的几个独特的优势,那么大模型怎么应用于推荐系统呢?这就是我们下一节要讲解的主题,也是本章最核心的主题。
22.2 大模型在推荐系统上的应用方法
大模型由于其压缩了海量的世界知识,能够以语言理解、语言生成和对话的方式解决各类问题,有了上一节的铺垫,我们知道大模型的这些能力可以用在推荐系统整个链路中的各个部分。下面我们就从数据处理与特征工程、召回与排序、交互控制、冷启动、推荐解释、跨领域推荐等6个维度来讲解大模型怎么赋能推荐系统。
22.2.1 大模型用于数据处理、特征工程
大模型具备文本生成的能力,这是大模型最直接、最被大众感知的能力。文本生成当然也可以直接用于个性化推荐的数据生成中。我们知道在很多场景下,推荐系统存在数据不足的问题(比如产品刚发布,没有太多用户和用户行为数据),那么利用大模型生成辅助数据就是一个非常朴素的想法。
参考文献2提供了一种基于大模型微调的方法针对表格数据(也就是可以利用Excel、MySQL等这样的表格形式来存储的数据,这也是推荐系统中最核心的一类数据,用户画像、物品画像都可以以这种形式的数据存放)生成样本的方法——GReaT。先将表格数据构成文本输入大模型进行微调(见下面图1),微调后的模型就可以基于一定的策略来生成新样本了(见下面图2)。该方法可以保证生成的样本跟原始样本分布一致,这对于数据量不足的推荐场景是一个比较好的补充。与其它方法相比,GReaT允许在没有对模型重新训练(只需要在大模型上进行微调)的情况下,可以对特征子集进行任意组合,即可以通过对任何特征名称或特征名称和值的组合进行数据采样。除了可以用来生成新的样本数据,对数据的缺失值进行补充也是可行的。
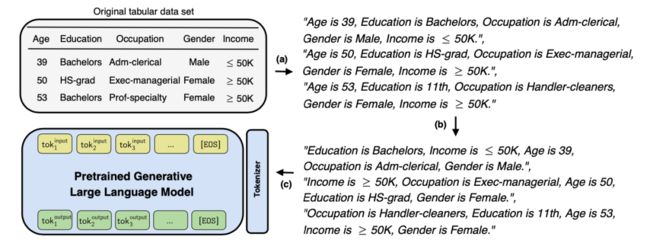
图1:微调步骤的GReaT数据管道。首先,文本编码步骤将表格数据转换为有意义的文本(a)。随后应用特征顺序置换步骤(b),最后获得的句子可以用于大型语言模型的微调(c)。(图片来源于参考文献2)

图2:合成数据生成方法的采样过程。为了使用预训练的LLM生成新的数据,需要将单个特征名称或特征值对的任意组合转换为文本(a)。随后,输入微调后的LLM完成采样(b),最终可以被转换回表格格式(c)。(图片来源于参考文献2)
在传统的推荐系统中,结构化数据通常被转为one-hot编码,并且采用简单的嵌入层作为特征编码器来获得稠密的嵌入表示。随着语言模型的出现,我们完全可以采用大模型作为辅助文本特征编码器,比如可以利用BERT将各类信息(物品标题、标签、描述文本等)进行嵌入获得嵌入向量作为其它推荐模型(可以是大模型,也可以是传统的推荐模型)的输入特征。
利用大模型获取新的特征,可以获得两大好处:(1)为后期的神经网络推荐模型进一步丰富具有语义信息的用户/物品表示;(2) 以自然语言为桥梁实现跨领域推荐,因为跨领域的特征可能不共享。
22.2.2 大模型用于召回、排序
推荐系统最核心的模块莫过于召回、排序了,我们在本书前面的章节中讲了很多召回、排序的策略和算法。大模型也能应用于召回、排序,可以说,这是大模型在推荐系统中最主流、最核心的应用了,下面我们就来重点介绍。
在讲解之前,我们先说一下大模型应用于召回、排序的使用方式。我们知道大模型一般会分为预训练、微调两个阶段,那么针对大模型应用于推荐系统,就可以有3种最主要的使用方式(参考下面图3),分别是:利用推荐系统的数据进行预训练再进行推断(即下面的预训练范式)、利用预训练好的大模型进行微调再进行推断(即下面的预训练、微调范式)、利用预训练好的大模型通过prompt进行推断(即下面的预训练、提示范式)。下面的讲解我们也是按照这3种方式分别展开。
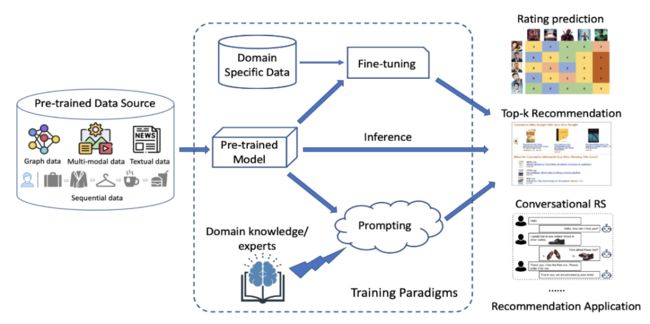
图3:语言模型应用于推荐系统的一般范式(图片来源于参考文献4)
22.2.2.1 预训练(pre-training)范式
所谓预训练方式就是利用推荐系统相关数据来预训练大模型,然后让大模型直接进行推荐召回、排序,这相当于构建一个推荐系统领域的垂直大模型。一般来说,由于推荐系统数据量相对互联网海量文本来说,规模较小(即使是抖音这样的公司,用户行为数据也无法跟互联网海量数据相提并论),数据形式也比较特殊(22.1节提到了),所以这种预训练的方式一般基于一个中等规模的开源大模型来预训练,比如基于BERT、T5、M6(阿里的大模型)来进行预训练。基于BERT的推荐算法读者可以阅读参考文献3(文献中该方法称为U-BERT)、5(文献中该方法称为BERT4Rec),基于T5开源模型的预训练方法读者可以阅读参考文献6(文献中该方法陈为P5),基于M6的预训练大模型推荐系统,读者可以阅读参考文献7(文献中该方法陈为M6-Rec)。
BERT4Rec基于Transformer和BERT架构来学习一个双向的神经网络大模型,为了避免信息泄露(双向的模型导致用户行为序列中后面待预测的物品也用于了建模,相当于提前泄露了信息),采用完形填空(Cloze)目标函数进行训练,也就是随机遮盖(mask)序列中的某个token,通过模型来预测该遮盖的token的概率来建模,这也是完形填空目标函数这个词组的由来。
下面简单说一下该模型的核心思想(模型架构见下面的图4)。在序列推荐(sequential recommendation,即预测下一个)任务中,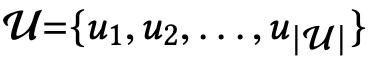 代表用户集,
代表用户集,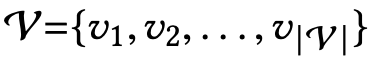 代表物品集,列表
代表物品集,列表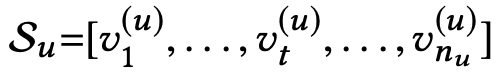 是用户
是用户 按照时间排列的交互序列,这里
按照时间排列的交互序列,这里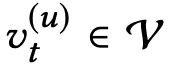 是用户u在时间t进行交互的物品,
是用户u在时间t进行交互的物品,![]() 是用户u的交互序列的长度。给定交互历史
是用户u的交互序列的长度。给定交互历史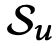 ,顺序推荐旨在预测用户u在时间
,顺序推荐旨在预测用户u在时间![]() 与之交互的物品。它可以被形式化为在时间步骤
与之交互的物品。它可以被形式化为在时间步骤![]() 对用户u的所有可能的交互物品的概率进行建模:
对用户u的所有可能的交互物品的概率进行建模: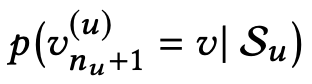 。
。
BERT4Rec由于可以利用预测token前后的token信息,能够获得更多的样本数据,也跟实际上用户的行为序列之间的依赖关系保持一致(也即用户行为序列中间的物品确实是跟前后都有关联的),因此效果是非常不错的。参考文献8中提出的一种算法SASRec就是一个单向的自注意力网络,BERT4Rec可以看成它的一种自然推广。
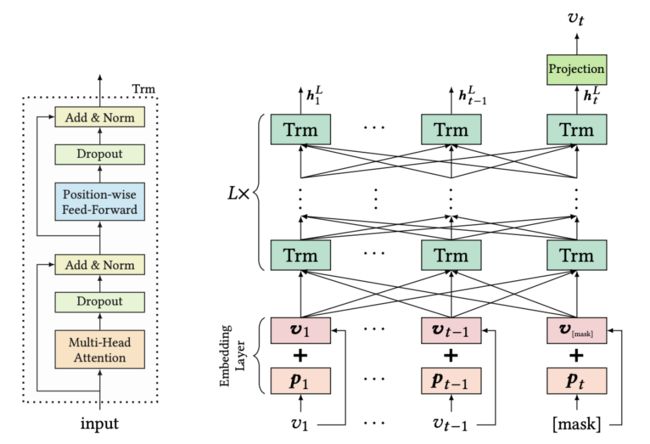
图4:BERT4Rec通过完形填空任务(Cloze task)学习双向模型
P5是将预测评分、评论、推荐解释、序列推荐、直接推荐(direct recommendation)构建在一个统一的模板框架下(见下面图5通用的统一的prompt模板),然后利用T5(见参考文献9)开源大模型来预训练,预训练好模型之后,直接利用prompt模板来为用户进行各种推荐。
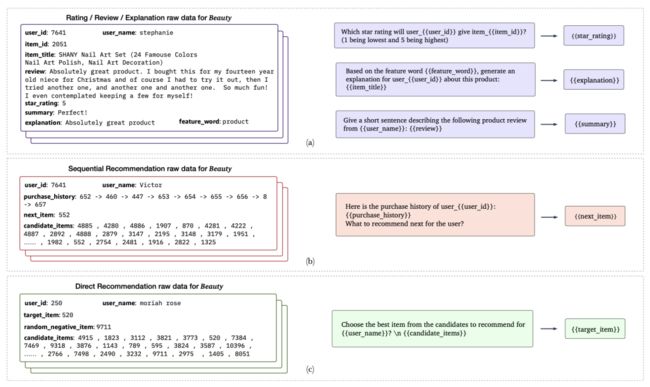
图5:P5的个性化提示模板,从原始数据构建输入-目标对,只需将提示中的字段替换为原始数据中的相应信息。P5的五个任务族的原始数据来自三个独立的来源。具体而言,评分/评论/解释prompt具有共享的原始数据(a)。序列推荐(b)和直接推荐(c)使用类似的原始数据,但前者需要用户交互历史。(图片来源于参考文献6)
在模型架构方面,P5建立在编码器-解码器框架上,论文使用Transformer块来构建编码器和解码器。假设输入token序列的嵌入是![]() ,如下面图6所示,在将嵌入序列灌入双向文本编码器
,如下面图6所示,在将嵌入序列灌入双向文本编码器![]() 之前,我们将位置编码
之前,我们将位置编码![]() 添加到原始嵌入以捕获它们在序列中的位置信息。此外,为了让P5知道输入序列中包含的个性化信息,论文中还应用整词嵌入(whole-word embeddings)来指示连续的子词标记是否来自同一原始词,例如,如果我们直接将ID号为7391的物品表示为“item_7391”,则单词将被句子片段分词器(Sentence-Piece tokenizer)拆分为4个单独的token(即“item”、“_”、“73”、“91”)。在共享的全词嵌入“⟨w10⟩”的帮助下,P5可以更好地识别具有个性化信息的句子片段。
添加到原始嵌入以捕获它们在序列中的位置信息。此外,为了让P5知道输入序列中包含的个性化信息,论文中还应用整词嵌入(whole-word embeddings)来指示连续的子词标记是否来自同一原始词,例如,如果我们直接将ID号为7391的物品表示为“item_7391”,则单词将被句子片段分词器(Sentence-Piece tokenizer)拆分为4个单独的token(即“item”、“_”、“73”、“91”)。在共享的全词嵌入“⟨w10⟩”的帮助下,P5可以更好地识别具有个性化信息的句子片段。
然后,文本编码器取上述三个嵌入的和![]() 并输出它们的上下文表示
并输出它们的上下文表示![]() 。然后解码器
。然后解码器![]() 结合之前生成的token
结合之前生成的token![]() 和编码器输出
和编码器输出![]() ,并预测未来token:
,并预测未来token:![]() 。在预训练阶段,P5通过以端到端方式最小化以输入文本x为条件的label token y的负对数似然性来学习模型参数 :
。在预训练阶段,P5通过以端到端方式最小化以输入文本x为条件的label token y的负对数似然性来学习模型参数 :
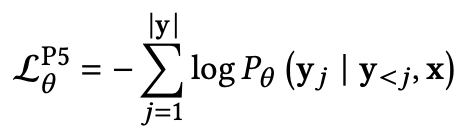
P5框架下的所有推荐任务都有同样的目标函数。因此,推荐任务统一为一个模型、一个损失函数和一种数据格式。P5这种大一统的思路还是非常有意思的,通过一个模型可以解决各种各样推荐系统问题,这避免了为每类推荐任务构建单独的模型这种耗时耗力的过程,这也跟大模型的一次预训练就解决多个下游任务的思路是一脉相承的。这篇文章作者认为非常好,读者可以好好阅读一下。

图6:P5模型架构示意图。对于prompt输入案例“你认为user_23会给item_7391什么评分?”,P5采用编码器-解码器框架:首先用双向文本编码器对输入进行编码,然后通过文本自回归解码器生成答案。与特定任务的推荐模型相比,P5依赖于在大规模个性化prompt集合上基于多任务prompt的预训练,使得P5能够适应不同的推荐任务,甚至可以推广到新的任务中。(图片来源于参考文献6)
前面的M6-Rec我们这里没有深入介绍,有兴趣的读者可以自行学习。除了上面介绍的BERT4Rec、P5、M6-Rec等预训练大模型推荐系统外,这方面的方法还是很多的,如参考文献31中提到的Transformers4rec等,读者可以自行学习。大模型预训练除了可以直接用于任务预测外,也可以获得用户或者物品的嵌入向量(参考22.2.1节介绍),再利用向量去做召回。
22.2.2.2 预训练、微调(fine-tuning)范式
所谓预训练、微调范式是指基于预训练好的大模型,再利用推荐系统特定的领域数据去微调预训练好的大模型,待大模型微调好后再进行下游的个性化推荐。微调过程也会进行模型的梯度下降训练,只不过微调是对模型进行小规模调整,训练时间、成本等更小。
预训练、微调范式是非常重要的一种范式,主要价值体现在3点:1)预训练提供了更好的模型初始化,通常会对不同的下游推荐任务产生更好的泛化能力,从各个角度提高推荐性能,并且在微调阶段加速收敛;2) 在庞大的源语料库上进行预训练,可以学习到通用知识,有利于下游推荐;3) 预训练可以看作是一种正则化,以避免在低资源和小数据集上过拟合。
预训练、微调范式是非常灵活的,预训练可以采用各种各样的大模型(一般可以采用开源的大模型,如T5、LLaMA等),微调过程也可以分为对整个模型进行微调、对模型的部分层进行微调、对模型的额外部分进行微调(如在预训练模型上新增加一层用于下游推荐系统任务,微调这个新增加的一层),这3个分类方法见参考文献4,下面我们分别介绍。
22.2.2.2.1 微调整个模型
在这一微调范式下,模型是用不同的数据源进行预训练和微调的,微调过程通过调整整个模型参数来实现。预训练和微调阶段的学习目标也可能不同。对不同领域的数据源进行预训练和微调,也称为跨领域推荐。
受BERT在NLP中成功应用的启发,参考文献3中提出了一种新的基于预训练和微调的方法U-BERT。与典型的BERT应用不同,U-BERT是为推荐而定制的,并在预训练和微调中使用不同的框架。在预训练中,U-BERT专注于内容丰富的领域,并引入了一个用户编码器和一个评论编码器来对用户的行为进行建模。在微调中,U-BERT专注于目标内容不足的领域,除了从预训练阶段继承的用户和评论编码器外,U-BERT还引入了一个物品编码器来对物品表示进行建模。此外,还提出了一个评论协同匹配层,以捕捉用户和物品评论之间更多的语义交互。最终U-BERT将用户表示、物品表示和评论交互信息相结合,以提高推荐性能。下面图7就是U-BERT利用大模型在一个场景的丰富信息来获取用户和评论的嵌入表示,迁移到另外一个场景进行个性化推荐,下面我们重点说一下U-BERT的核心算法原理。

图7:同一用户为来自不同领域的两个物品撰写的两条评论(图片来源于参考文献3)
在预训练阶段,U-BERT进行两项自我监督任务,根据内容丰富领域的大量评论来学习用户的一般表示;在微调阶段,U-BERT使用监督学习从内容不足领域进一步细化用户对评论的表示。为了完成推荐任务,我们需要在同一框架中对用户ID、物品ID和评论进行建模,在预训练和微调阶段,用户ID的保持不变,而物品ID的由于场景差异不重叠。因此,U-BERT分别在预训练和微调阶段引入了两种不同的架构。
在预训练阶段,U-BERT引入了一个基于多层Transformer的评论编码器(这里对两个场景中的评论统一建模,即两个场景的评论数据都用起来了)和一个用户编码器来对评论文本进行建模,并构造了评论增强(review-enhanced)的用户表示(即下面图中Review Encoder向左边的箭头\leftarrow,将评论的嵌入信息整合到了用户嵌入中)。此外,提出了两个新的预训练任务——掩盖意见token预测(Masked Opinion Token Prediction)和意见评分预测(Opinion Rating Prediction)来训练这两个任务(完整的模型架构参考下面图8,这里的Opiton是用户对物品的评分的关键词,比如五星好评、非常棒等这类表达用户意见的文本信息)。

图8:U-BERT的预训练阶段架构(图片来自参考文献3)
在微调阶段,U-BERT进一步使用物品编码来表示物品,并使用评论协同匹配层来捕捉用户和物品评论之间的语义交互信息。最后,将所有获取的用户表示、物品表示和评论交互信息灌入到目标域中的下游推荐系统预测层中(完整的模型架构参考下面图9,从图中我们可以看到微调阶段的架构跟预训练稍微有点不一样了,有一些小幅度调整,但是整体还是一致的)。
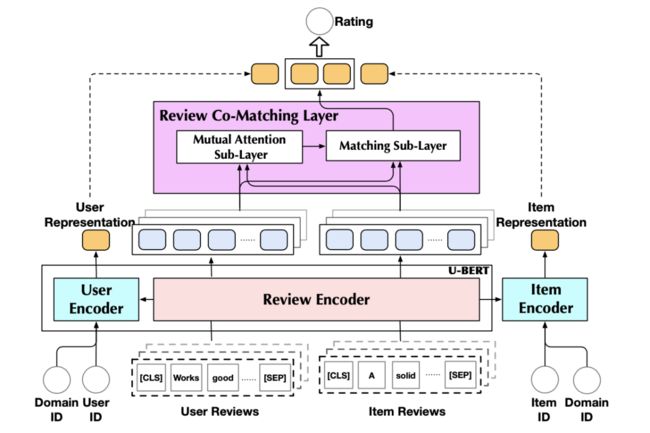
图9:U-BERT的评分预测阶段架构(图片来自参考文献3)
严格来说U-BERT是先预训练一个完整的模型,然后对整个模型进行微调(U-BERT还是在修改了模型的架构后进行的微调)。微调整个模型整体来说效果会更好,但是需要的数据量、计算量等都会更大。
22.2.2.2.2 微调部分模型
由于微调整个模型通常耗时且灵活性较低,许多大模型推荐系统选择微调模型的部分参数,以平衡训练开销和推荐性能。
参考文献10提出了一个新的方法——UniSRec,它应用线性变换层来变换来自不同领域的物品的BERT表示,然后应用自适应组合策略来获得通用物品表示,以处理领域bias问题。同时,考虑到从多个特定领域的行为模式中学习可能会出现冲突的现象,UniSRec在预训练阶段提出了用于多任务学习的序列-物品和序列-序列对比任务。这种方法只需要对模型参数的一小部分进行微调,就能使模型快速适应冷启动或新物品的未知领域(参见下面图10)。
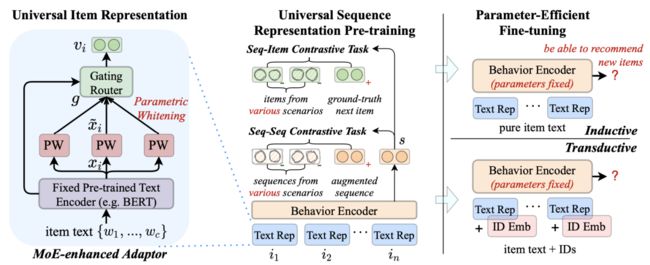
图10:UniSRec的物品表示(左)、序列表示(中)与微调架构(右)(图片来自参考文献10)
对于物品表示,基于物品文本(item text)来学习可迁移的物品表示,该文本以自然语言的形式描述物品特征。自然语言提供了一种通用的数据形式来弥合不同任务或领域之间的语义差距。基于这一思想,UniSRec首先利用预先训练的语言模型来学习文本嵌入。由于来自不同领域的文本表示可能跨越不同的语义空间(即使使用相同的文本编码器),UniSRec提出了基于参数白化(parametric whitening)和混合专家(MoE)的增强适配技术,将文本语义转换为适合推荐任务的通用形式。
由于不同的领域通常对应于不同的用户行为模式,因此简单地混合来自多个领域的交互序列进行预训练可能效果不佳。而且,很可能从多个特定领域的行为模式中学习导致出现冲突现象。UniSRec的解决方案是引入序列-物品和序列-序列两种对比学习任务,这可以进一步增强不同领域在学习物品表征时的融合和适应性。在预训练阶段,利用多任务训练策略来联合优化序列-物品对比损失函数和序列-序列对比损失函数。
由于UniSRec模型可以学习交互序列的通用表示,所以可以固定主要架构的参数,只需微调MoE增强适配器的一小部分参数(即图10左边Gating Router部分),以增加模型的适应性。MoE增强适配器可以快速适应新的领域,能够融合预先训练的模型与新的领域特征,并在新领域获得较好的预测效果。
22.2.2.2.3 微调模型的额外部分
除了上述介绍的两种微调策略外,另外一种微调策略利用预训练模型之上增加的特定任务层来执行推荐任务,通过优化这个新增加的聚焦特定任务层的参数来实现微调的目标(见参考文献11)。另一种方法是在微调阶段使用预训练模型初始化具有类似架构的新模型,并使用微调的新模型进行推荐(见参考文献12)。关于这部分我们这里就不展开了,读者可以自行学习这里提到的两篇参考文献。
22.2.2.3 预训练、提示(prompting)范式
预训练、提示范式跟上面两个范式不同,大模型完成预训练后不需要进行微调直接用于个性化推荐,这里的预训练大模型一般是通用的大模型(比如chatGPT、GPT-4、Bard、LLaMA、M6等),而不是单独为推荐任务进行预训练过的大模型。
我们在22.1节提到了,大模型是基于海量文本数据预训练的,海量文本中本身就压缩了各个领域的基础知识,这些知识是可以被激发出来用于进行个性化推荐的。只不过,我们需要用特定的提示(prompt)才能激发大模型的个性化推荐能力。
推荐系统的提示需要采用特定的模板(template)才能更好地激发大模型的推荐能力。推荐系统跟其它下游任务最大的不同是个性化的,因此提示也需要是个性化的,个性化提示包括不同用户和物品的个性化字段。例如,用户的偏好可以通过物品ID或用户的描述(如姓名、性别、年龄等)来表示。此外,个性化提示的预期模型输出也应该根据输入的物品而变化,这意味着用户对不同物品的偏好变化。这些的物品字段可以由物品ID或包含详细描述的物品元数据来表示。
大模型不需要进行任何微调就可以直接用于下游推荐任务,只需要利用特定提示激发大模型的推荐能力,我们将这种能力叫做zero-shot能力。另外,我们在22章中提到,大模型具备In-Context Learning的能力,也就是给出几个输入-输出样本案例,大模型就能够按照案例给定的信息进行推理(这个过程是一个迁移学习的过程,我们在22.1节也解释了大模型为什么具备这个能力),这就是大模型的few-shot能力。因此,利用预训练、提示范式进行个性化推荐可以分为zero-shot推荐、few-shot推荐两大类,下面我们也按照这个划分来展开讲解。
22.2.2.3.1 zero-shot推荐
zero-shot就是直接利用预训练好的大模型,通过设计特定的prompt和模板来让大模型完成推荐任务。这类推荐的效果主要由大模型自身的通用能力及prompt的独特设计决定,一般会用chatGPT、GPT-4等超大的大模型,这类模型的通用能力会更好。参考文献13就提供了一个比较好的zero-shot推荐的案例,下面我们来介绍一下具体的步骤和原理(读者也可以阅读参考文献14、15、16,了解更多的zero-shot推荐实现方案)。
参考文献13将推荐看成一个有条件的排序任务(思路有点类似贝叶斯估计),给定用户的历史交互序列 (按照交互时间升序排列)作为初始条件,大模型推荐系统的任务是对召回的候选集
(按照交互时间升序排列)作为初始条件,大模型推荐系统的任务是对召回的候选集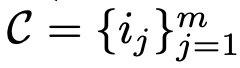 (可以是其它传统的召回算法获得的,候选物品来自于整个物品池
(可以是其它传统的召回算法获得的,候选物品来自于整个物品池 ,另外,每个物品i有一个关联的文本描述
,另外,每个物品i有一个关联的文本描述![]() )进行排序,使得用户最喜欢的物品排在前面。这就是一个典型的利用大模型进行推荐系统排序的方案。
)进行排序,使得用户最喜欢的物品排在前面。这就是一个典型的利用大模型进行推荐系统排序的方案。
对每个用户,首先构造两个自然语言模式(pattern):一个是用户的历史交互行为序列 ,一个是抽取的候选物品集
,一个是抽取的候选物品集 ,然后将这两个模式输入到一个自然语言模板
,然后将这两个模式输入到一个自然语言模板![]() 中形成最终的指令(prompt)。通过这种方式,期望大模型理解指令并按照指令的建议输出推荐排序结果。大模型排序方法的总体框架如下面图11所示。接下来,我们描述详细的指令设计过程。
中形成最终的指令(prompt)。通过这种方式,期望大模型理解指令并按照指令的建议输出推荐排序结果。大模型排序方法的总体框架如下面图11所示。接下来,我们描述详细的指令设计过程。
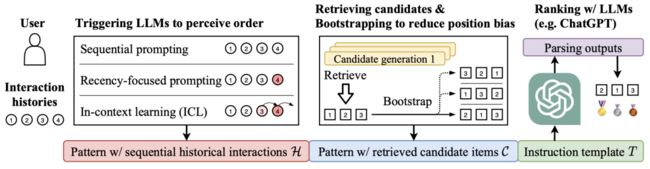
图11:利用大模型进行zero-shot排序推荐的技术方案(图片来源于参考文献13)
用户历史序列交互:为了研究LLM是否可以从用户历史行为中捕获用户偏好,我们将顺序历史交互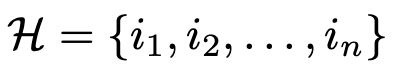 作为LLM的输入包含在指令中。为了使LLM能够意识到历史交互的顺序性,有如下三种构建指令的方法:
作为LLM的输入包含在指令中。为了使LLM能够意识到历史交互的顺序性,有如下三种构建指令的方法:
顺序提示:按时间顺序排列历史交互。例如:“I’ve watched the following movies in the past in order: ’0. Multiplicity’, ’1. Jurassic Park’, . . .”。
关注最近的提示:除了顺序的交互记录外,我们还可以添加一句话来强调最近的交互。例如:“I’ve watched the following movies in the past in order: ’0.Multiplicity’,’1.JurassicPark’,.... Note that my most recently watched movie is Dead Presidents. . . .”。
上下文学习(ICL):ICL是LLM解决各种任务的一种效果突出的提示方法,它在提示中包括式例样本(可能带有任务描述),并指示LLM解决特定任务。对于个性化推荐任务,简单地引入其他用户的示例可能会引入噪声,因为不同的用户通常具有不同的偏好。我们通过调整ICL,增补输入交互序列来引入式例样本。例如:“ If I’ve watched the following movies in the past in order: ’0. Multiplicity’, ’1. Jurassic Park’, . . ., then you should recommend Dead Presidents to me and now that I’ve watched Dead Presidents, then ...”。
抽取候选物品集:通常要排序的候选物品由几个候选生成模型生成(即多路召回)。为了用LLM对这些候选物品进行排序,我们先按顺序排列候选物品|C|。例如:“Now there are 20 candidate movies that I can watch next: ’0. Sister Act’, ’1. Sunset Blvd’, . . .”。按照经典的候选生成方法,候选物品没有特定的顺序。我们将不同候选集生成模型的召回结果放到一个集合中,并随机排序。我们考虑了一个相对较小的候选集,并保留了20个候选物品(即m=20)进行排序。实验表明,LLM对提示中示例的顺序很敏感。因此,我们在提示中为候选物品生成了不同的顺序,这使我们能够进一步验证LLM的排序结果是否受到候选集排列顺序的影响,即位置偏差,以及如何通过bootstrapping来减轻位置偏差。
使用大型语言模型进行排序。为了使用LLM作为排序模型,我们最终将上述模式集成到指令模板T中。一个可行的示例指令模板可以是:“ [pattern that contains sequential historical interactions H] [pattern that contains retrieved candidate items C] Please rank these movies by measuring the possibilities that I would like to watch next most, according to my watching history. You MUST rank the given candidate movies. You cannot generate movies that are not in the given candidate list.”。
解析LLM的输出。通过将指令输入LLM,我们可以获得LLM的排序结果以供推荐。请注意,LLM的输出仍然是自然语言文本,我们使用启发式文本匹配方法解析输出,并将推荐结果与候选集进行匹配。具体来说,当物品的文本较短且能够区分时,如电影标题,我们可以在LLM输出和候选物品的文本之间直接执行高效的子串匹配算法,如KMP。否则,我们可以为每个候选物品分配一个索引,并指示LLM直接输出排序后的物品索引。尽管提示中包含了候选物品,但LLM可能生成候选集合之外的物品。而对于GPT-3.5,这种误差的比例非常小,约为3%。在这种情况下,我们可以提醒LLM这个错误让它重新输出,也可以简单地将其视为不正确的输出而忽略。
参考文献13在两个公开数据集上进行实验,得出了几个关键发现,这些发现可以用于指导如何将LLM作为推荐系统的排序模型:
LLM可以利用用户历史行为进行个性化排序,但很难感知给定的交互历史的顺序。
通过采用专门设计的提示,如关注最近提示和上下文学习,可以触发LLM感知历史互动的顺序,从而提高排序效果。
LLM优于以前的zero-shot推荐方法,特别是在多个不同的召回排序算法生成的候选集上有较好的表现,因此是一种非常有竞争力的zero-shot方法。
LLM在排序时存在位置bias和热门bias,这可以通过提示或bootstrapping策略来缓解。
22.2.2.3.2 few-shot推荐
所谓few-shot推荐,就是在预训练好的大模型基础上,提供指导大模型进行推荐的几个式例样本告诉大模型该怎么推荐,然后激活大模型的个性化推荐能力,让大模型进行个性化推荐。参考文献6中设计的方法就是一个非常好的案例,下面我们来简单讲解一下参考文献17的核心思想。
参考文献17设计了一组提示,并评估了ChatGPT在五种推荐场景(包括评分预测、序列推荐、直接推荐、解释生成和评论摘要)中的表现。与传统的推荐方法不同,整个评估过程中不会微调ChatGPT,只依靠提示本身将推荐任务转换为自然语言任务。此外,还探索了使用few-shot提示来注入包含用户潜在兴趣的交互信息,以帮助ChatGPT更好地了解用户的需求和兴趣。在Amazon Beauty数据集上的实验结果表明,ChatGPT在某些任务中取得了较好的结果,在其他任务中也能够达到基线水平。
使用ChatGPT完成推荐任务的工作流程如下面图12所示,包括三个步骤。首先,根据推荐任务的具体特征构建不同的prompt。其次,这些prompt被用作ChatGPT的输入,期望ChatGPT根据prompt中指定的要求生成推荐结果。最后,优化(refinement)模块对ChatGPT的输出进行检查和优化,优化后的结果作为最终推荐结果返回给用户。下面分别对这3个步骤加以说明。
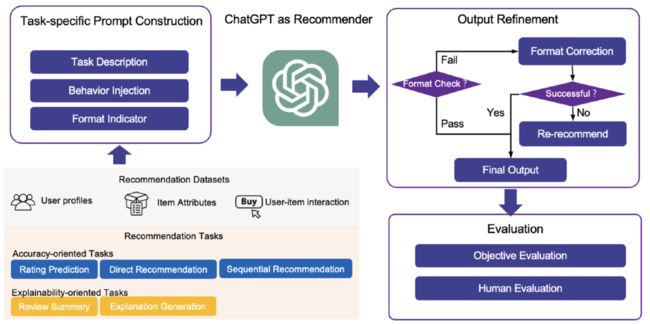
图12:利用ChatGPT执行五项推荐任务并评估其推荐性能的工作流程(图片来源于参考文献17)
步骤1:特定任务的prompt构造
特地任务的prompt构造通过设计针对不同任务的prompt来激发ChatGPT的推荐能力。每个prompt包含三个部分:任务描述(task description)、行为注入(behavior injection)和格式指示符(format indicator)。任务描述用于使推荐任务适应自然语言处理任务。行为注入旨在评估few-shot prompt的影响,它整合了用户-物品交互,以帮助ChatGPT更有效地确定用户偏好和需求。格式指示符用于约束输出格式,使推荐结果更易于理解和评估。下面图13、14是prompt的式例。

图13:亚马逊Beauty数据集上基于准确性任务的prompt示例。黑色文本表示任务描述,红色文本表示格式要求,蓝色文本表示用户历史信息或few-shot信息,灰色文本表示当前输入(图片来源于参考文献17)
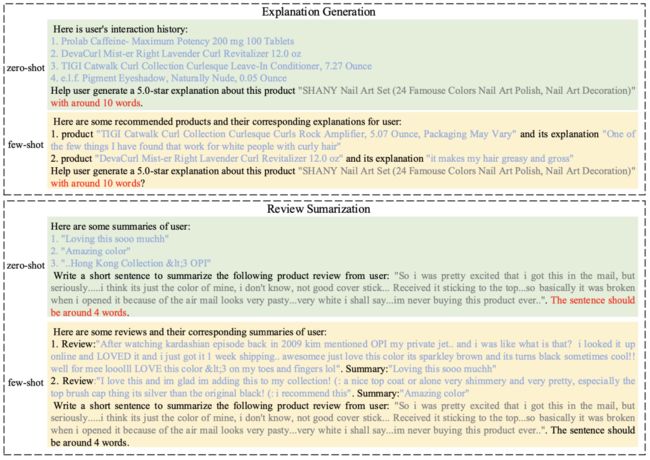
图14:亚马逊Beauty数据集上面向可解释性任务的prompt示例。黑色文本表示任务描述,红色文本表示格式要求,蓝色文本表示用户历史信息或few-shot信息,灰色文本表示当前输入(图片来源于参考文献17)
步骤2:利用chatGPT生成推荐结果
这一步就是将上面构造好的prompt作为自然语言对话的形式注入chatGPT(比如通过调用chatGPT的API等)获得最终的输出(即推荐结果)。由于这一步完全是基于chatGPT的自然语言生成能力,属于黑盒,我们这里不展开说明。
步骤3:推荐结果优化
为了确保生成结果的多样性,ChatGPT在其响应生成过程中加入了一定程度的随机性,这可能会导致对相同输入产生不同的输出。因此,当使用ChatGPT进行推荐时,这种随机性有时会导致评估推荐物品的困难。虽然提示结构中的格式指示符可以部分缓解这一问题,但在实际使用中,它仍然不能保证预期的输出格式。因此,才需要输出优化模块来检查ChatGPT的输出格式。如果输出通过了格式检查,它将直接用作最终输出。如果没有通过,则会根据预定义的规则对其进行修改。如果格式校正成功,则校正后的结果将用作最终输出。如果没有校正成功,则将相应的提示输入ChatGPT以进行重新推荐,直到满足格式要求为止。
需要注意的是,在评估ChatGPT的输出时,不同的任务有不同的输出格式要求。例如,对于评分预测,输出只需要特定的分数,而对于序列推荐或直接推荐,输出是推荐物品的列表。特别是对于序列推荐,一次将数据集中的所有物品注入ChatGPT是一项挑战(因为chatGPT有输入token数量限制)。因此,ChatGPT的输出可能与数据集中的物品集不匹配(即输出的物品不在数据集中)。为了解决这个问题,论文中引入了一种基于相似性的文本匹配方法,将ChatGPT的预测映射回原始数据集。尽管这种方法可能不能完全反映ChatGPT的能力,但它仍然可以间接展示chatGPT在序列推荐中的潜力。
22.2.3 大模型用于交互控制
所谓大模型应用于交互控制,就是指利用chatGPT、LaMDA(LaMDA是Google2022年初发布的基于对话的大模型,比chatGPT还早,见参考文献18)这类基于对话的大模型能力来革新现有的推荐交互范式,让chatGPT、LaMDA来控制整个推荐的流程,这包括两个方面:一是让chatGPT、LaMDA来整合所有的推荐模块(比如召回、排序等)控制整个推荐流程,chatGPT、LaMDA来决定在什么时间节点、什么场景下调用哪个模块来与用户交互;二是采用对话交互的方式给用户进行推荐,而不是传统的APP上用户通过触屏互动的方式进行推荐(这个场景在汽车、智能音箱、机器人等应用中进行个性化推荐非常有吸引性,也可能是唯一可行的交互方式)。
利用chatGPT、LaMDA的交互控制能力来进行个性化推荐,目前有一些相关的研究,其中参考文献19、20就是这方面的尝试。参考文献19是利用chatGPT整合传统推荐召回模块来控制整个推荐流程,而参考文献20是利用LaMDA进行交互式对话推荐(当然文献19中也是利用对话的形式进行推荐的),这两篇文章刚好覆盖了上面提到的对话大模型应用于推荐系统流程控制的两个方面,下面我们分别展开详细说明。
22.2.3.1 利用chatGPT控制推荐流程
参考文献19提出了一种新的基于chatGPT的大模型推荐系统Chat-REC。Chat-REC可以通过上下文有效地学习用户偏好,并在用户和待推荐物品之间建立联系,这使推荐过程更具互动性和可解释性。此外,在Chat-REC框架内,用户的偏好可以迁移到不同的物品中进行跨领域推荐,并且基于prompt的信息注入(大模型)也可以处理新物品的冷启动场景。Chat-REC有效地改进了top-k推荐的效果,并在zero-shot评分预测任务中表现很好。Chat-REC的流程架构见下面图15,下面我们简单介绍一下相关原理。
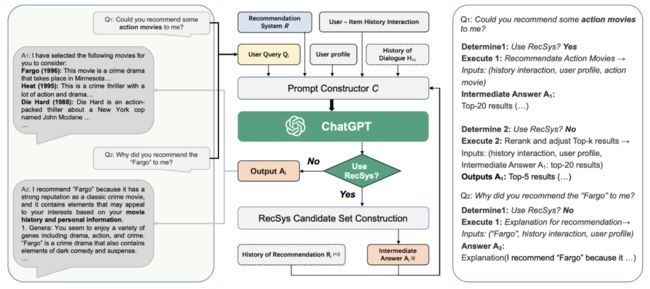
图15:Chat-REC的流程架构。左侧显示了用户和ChatGPT之间的对话。中间部分的流程图显示了Chat-REC是如何将传统推荐系统与ChatGPT等对话人工智能联系起来的。右侧描述了交互过程中的具体判断逻辑。(图片来源于参考文献19)
Chat-REC的输入包括4部分(参见图15中间上面部分):用户物品的交互历史记录(user-item history interaction)、用户画像(user profile)、用户查询 (user query)、历史对话
(user query)、历史对话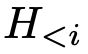 (history of dialogue)、另外一个传统的推荐系统
(history of dialogue)、另外一个传统的推荐系统![]() 。如果该任务被确定为推荐任务,则Chat-REC使用
。如果该任务被确定为推荐任务,则Chat-REC使用![]() 来生成候选物品集。否则直接回应用户,例如生成任务的解释或对推荐物品进行详细介绍。Chat-REC的prompt构造器模块采用上面提到的4类输入来生成捕获用户的查询和推荐信息的自然语言段落,下面详细介绍一下。
来生成候选物品集。否则直接回应用户,例如生成任务的解释或对推荐物品进行详细介绍。Chat-REC的prompt构造器模块采用上面提到的4类输入来生成捕获用户的查询和推荐信息的自然语言段落,下面详细介绍一下。
用户物品历史交互信息,指的是用户过去与物品的交互,例如点击、购买或评分的物品,此信息用于了解用户的偏好并为推荐注入个性化。
用户画像,其中包含有关用户的人口统计学信息和偏好信息。这可能包括年龄、性别、地点和兴趣。用户画像有助于系统了解用户的特征和偏好。
用户查询
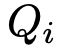 ,这是用户对信息或推荐的特定请求。这可能包括他们感兴趣的特定物品或类型,或者对特定类别物品的推荐请求。
,这是用户对信息或推荐的特定请求。这可能包括他们感兴趣的特定物品或类型,或者对特定类别物品的推荐请求。对话历史记录
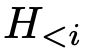 ,其中包含用户和系统之间先前对话。该信息用于理解用户的上下文信息,借助这些信息可以让Chat-REC提供更个性化和相关的反馈。
,其中包含用户和系统之间先前对话。该信息用于理解用户的上下文信息,借助这些信息可以让Chat-REC提供更个性化和相关的反馈。
如下面图16所示,Chat-REC是一个具有对话界面的推荐系统,使交互式和可解释的推荐成为可能。基于上述输入,prompt构造函数模块生成一个自然语言段落(参见下面的图17、18),总结用户的查询和推荐信息,并对用户的请求提供更个性化和相关的反馈。推荐系统生成的中间答案随后用于细化prompt构造函数,并生成优化的prompt以进一步从推荐候选集中筛选更匹配的物品,最终的推荐结果和简单的解释会一并反馈给用户。

图16:交互式推荐的案例。图中展示了不同用户和LLM之间的两个对话。其中用户画像和用户历史对话被转换为个性化推荐的相应prompt,但这部分prompt的输入对用户来说是不可见的。左边的对话显示,当用户询问为什么推荐电影时,LLM可以根据用户的偏好和推荐的电影的具体信息给出解释。右侧的对话框显示,Chat-REC可以根据用户反馈进行多轮推荐。关于电影细节的问题也可以用特定的方式回答。LLM在推荐电影时也会考虑到伦理和道德问题。(图片来源于参考文献19)

图17:top-k推荐的prompt(图片来源于参考文献19)
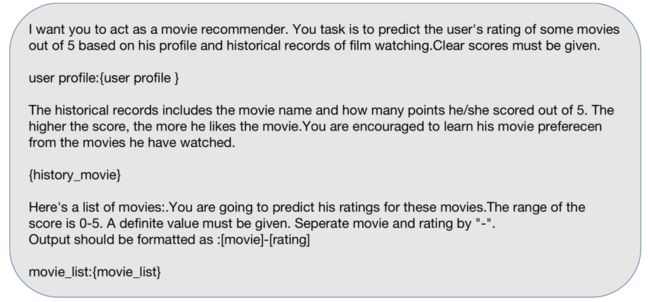
图18:评分预测的prompt(图片来源于参考文献19)
Chat-REC可以看成是基于传统推荐召回算法的一种排序策略。传统的推荐系统通常会生成少量经过排序的候选物品,每个物品都有反映推荐系统推荐结果的置信度或质量的分数。然而,考虑到物品集的巨大规模,大多数现有推荐系统的性能都远远不能令人满意,仍有很大的改进空间。
Chat-REC通过将chatGPT跟传统推荐系统结合,通过缩小候选集来提高推荐系统的性能。推荐系统生成一大堆候选物品,这对用户来说可能有点多。chatGPT在缩小候选物品集的范围方面发挥着关键作用。首先,我们将用户的画像、历史互动信息、商品描述和用户评分转换为prompt。其次,chatGPT根据上述信息总结用户对候选集中物品的偏好,chatGPT可以从上下文中学习,并有效地捕捉用户的背景信息和偏好。有了这些信息,就可以建立物品属性和用户偏好之间的关系,最终才能够做出更好的物品推荐。通过利用上下文学习,LLM可以增强其推荐推理能力,从而获得更准确、更个性化的物品推荐。
一旦chatGPT了解了用户的偏好,由传统推荐系统生成的候选集就被提供给chatGPT。LLM可以进一步根据用户的偏好对候选集进行筛选和排序。chatGPT确保向用户提供一组更小、更相关的物品,增加了找到用户喜欢的物品的可能性。
22.2.3.2 利用LaMDA进行对话式推荐
参考文献20实现了一个基于Google的LaMDA对话大模型的对话式推荐系统(Conversational Recommender System,CRS)——RecLLM,RecLLM实现了端到端的对话式推荐,借助大模型可以实现用户偏好理解、灵活的对话管理和可解释的推荐。为了实现个性化,利用大模型理解自然语言表示的用户画像,并使用它们来优化与用户的互动会话,并提出了基于大模型技术的用户模拟器以生成合成会话,以解决会话数据不足的问题。RecLLM的整体架构参考下面图19。

图19:RecLLM的主要模块。(1) 对话管理模块使用大模型与用户对话、跟踪上下文并进行系统调用,例如向推荐引擎提交请求,所有这些都在一个统一语言模型控制下进行。(2) 在大模型CRS框架下,实现物品库中物品的抽取。(3) ranker模块使用大模型将从对话上下文中提取的偏好与物品元数据相匹配,并生成给用户的推荐列表。大模型还同时生成推荐的解释,这些解释可以呈现给用户。(4) 大模型利用自然语言描述的用户画像来调节会话上下文,目的是增加个性化。(5) 利用大模型实现的用户模拟器可以作为插件接入CRS,以生成用于训练各个系统模块的数据。(图片来源于参考文献20)
关于上图的5个模块,我们这里简单说明一下。①是对话管理系统,是RecLLM的核心,我们下面会重点说明。②就是传统的推荐搜索系统,在合适的时机对话系统会进行调用。③我们在前面召回、排序中也讲过类似的思路,RecLLM的Ranker模块的一个特点是在生成排序的同时生成一段解释,这样可以提升用户的信任度和体验。④是用户画像的存储模块,RecLLM将用户的画像按照自然语言的形式来存储,比如“I do not like listening to jazz while in the car”,每一条信息当成一条知识存到用户画像模块的后端存储系统中,在需要的时候基于用户会话的最后一句话进行嵌入,然后在用户画像的所有知识中进行相似性查询(用户画像的知识也是离线进行过向量化了的),找出最相似的一条知识。
下面来详细说一下对话管理模块。对话管理是CRS的核心模块,充当用户与系统其他部分之间的接口。它负责引导用户对推荐语料库进行多轮探索,并为用户生成合理、有用的反馈信息。在这个过程中,它必须隐式或显式地执行上下文跟踪,以提取用户偏好和意图的有用表示。这些信息可用于通知对话策略,也可以作为API调用以启动系统操作的信号(例如,通过向传统的推荐引擎后端发送搜索查询)。从端到端的角度来看,对话管理器的目标是基于给定的上下文信息(对话历史、用户画像、物品摘要等)执行相关的动作或者生成应对用户的自然语言应答,对话管理模块的原理图参考下面图20。
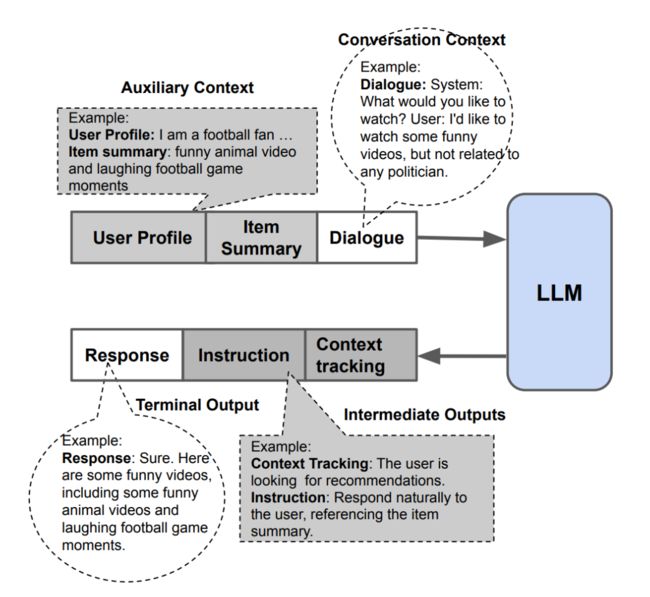
图20:统一的大模型对话管理模块。大模型将完整的会话上下文作为输入,并在终端输出一系列消息,这些消息就是CRS对用户请求的回应。(图片来源于参考文献20)
22.2.4 大模型用于解决冷启动
冷启动是当用户或物品与推荐系统没有交互记录时,在推荐系统中无法进行很好地推荐的问题。为了解决这个问题,可以对内容特征进行建模或从辅助领域迁移知识。前一种方法侧重于根据物品或用户的内容(如文本、图像或元数据)获得其特征(如22.2.3.2节中的U-BERT方法)。后一种方法涉及利用来自其他领域的信息,如社交网络或产品描述,来推断用户偏好(如22.2.3.2节提到的U-BERT、UniSRec方法)。此外,还有一种方法是让推荐系统快速适应新的领域(如通过EE、或者跟用户互动的方式快速探索出用户的兴趣)。推荐模型在冷启动中的良好泛化能力对于确保更好的用户体验和提高参与度至关重要。
借助上面提供的思路,大模型的推理能力和压缩的世界知识可以用于解决推荐系统中的冷启动问题。有了关于物品(无论是新物品还是旧物品)的文本描述和简介信息,大模型都可以有效地将这些物品相互关联起来,这为我们便捷地解决冷启动推荐问题提供了新的机会。在22.2.3.1节中介绍的Chat-REC就具备这种能力。
例如,如果用户要求推荐2021年上映的新电影,Chat-REC可以使用关于该电影的文本数据来生成嵌入,然后计算与系统中其他电影的相似性来进行推荐。该功能允许推荐系统对新物品进行相关且准确的推荐,从而改善整体用户体验。
大型语言模型可以使用它们所包含的大量知识来帮助推荐系统缓解新物品(即缺乏大量用户交互的物品)的冷启动问题。然而,由于ChatGPT掌握的知识仅限于2021年9月,当遇到未知物品时,ChatGPT无法很好地应对,例如用户请求推荐2023年发布的一些新电影或请求ChatGPT不知道的电影(这些电影可能不在chatGPT训练语料库中)。这时可以引入了关于新物品的外部信息,利用大型语言模型生成相应的嵌入表示并缓存它们(可以借助Milvus等向量数据库)。
当遇到新的物品推荐时,我们计算物品嵌入与用户偏好的嵌入之间的相似性,然后根据相似性检索最相关的物品信息,并构造一个prompt输入到ChatGPT进行推荐(也就是当chatGPT无法推荐时,可以增加判断规则,利用向量数据库去检索相似物品)。这种方法允许推荐系统与ChatGPT协同工作,更好地推荐新物品,从而增强用户体验(参见下面图21)。

图21:上面部分展示了Chat-REC如何利用新物品的外部信息处理新物品推荐的流程。底部展示了在合并外部信息后,Chat-REC可以有效地处理新物品的推荐。(图片来源于参考文献19)
冷启动推荐的解决方案要么学习对内容特征进行建模,以便在没有交互记录的情况下进行推荐,要么学习从辅助领域迁移表示。zero-shot或few-shot推荐的另一条工作线讨论了对新领域的快速适应,而不是仅为冷启动情况提供推荐。解决方案通常遵循元学习(meta learning)或因果学习(causal learning)框架,这些框架使模型对领域适应具有鲁棒性。
参考文献21中提出了一个PPR( Personalized prompt-based recommendation)框架可以很好地解决用户冷启动问题。对于每个用户,首先通过prompt生成器根据用户画像(即用户的静态属性,如年龄、性别等)构建个性化prompt(这里的prompt是soft prompt,即嵌入向量的形式的prompt,而不是我们前面提到的自然语言形式的prompt,关于soft prompt的介绍,读者可以阅读参考文献22、23),并将其插入用户行为序列的开头。然后将新序列输入到预先训练的序列模型中,以获得用户的行为偏好。用户画像被进一步添加到另一个网络中,以生成用户的属性(attribute)偏好。我们这里不展开讲解,有兴趣的读者可以阅读论文原文。
22.2.5 大模型应用于推荐解释
基于文本的推荐解释由于其在向用户传达丰富信息方面的优势,已成为推荐系统的一种重要解释形式。然而,当前生成句子解释的方法要么局限于预定义的句子模板,这限制了句子的表达能力,要么选择自由风格的句子生成,这使得句子质量控制变得困难。由于大模型有很好的语言理解和生成能力,利用大模型进行文本推荐解释是很自然的想法。参考文献17就利用chatGPT的zero-shot和few-shot能力进行推荐解释,具体与chatGPT进行交互的描述参考下面图22。

图22:利用chatGPT进行推荐解释(图片来源于参考文献17)
利用机器学习的一些评估指标(如BLEU-n、ROUGE-n)对chatGPT生成的推荐解释进行评估,chatGPT可能没有一些经过特定训练的模型(如P5,见参考文献6)的指标好,但是通过人工进行评估(通过众筹的方式,见参考文献17),发现chatGPT的人工评估得分更高,chatGPT能够更好地理解提供的信息,能够生成更合理、更清晰的解释。
参考文献19中提出的Chat-REC方法也是基于chatGPT进行推荐的,并且也可以生成比较合理的解释,读者可以查看上面的图16中的说明。参考文献21提出了一种神经模板(NETE)解释生成框架,该框架通过从数据中学习句子模板并生成对特定特征进行评论的、模板控制的句子,这种方法提高解释文本的表达能力和质量。参考文献25提出了一个推荐解释框架PETER(PErsonalized Transformer for Explainable Recommendation),该框架设计了一个简单有效的学习目标,利用ID(用户ID、物品ID)来预测解释文本中的单词,赋予ID语言意义,从而实现了个性化的Transformer(这是传统Transformer模型不具备的能力)。除了生成解释,PETER还可以提供个性化推荐,这使它成为一个完成推荐、解释pipeline任务的统一模型。如果读者对利用大模型做推荐解释感兴趣,可以好好阅读这两篇论文,我们这里就不过多展开说明了。
22.2.6 大模型用于跨领域推荐
为了解决推荐系统中的数据稀疏性和冷启动问题,可以利用来自其他领域的行为信息来提高目标域的推荐效果,这就是跨领域推荐。跨领域推荐是指借助一些链接信息,推荐系统在一个领域学得的知识可以用于在另外一个领域进行个性化推荐,机器学习中的迁移学习可以用于解决这类问题。大多数方法依赖两个领域的重叠数据(如重叠的用户、物品、社交网络、属性等)来进行跨领域的知识转移。有一些方法试图学习面向用户的不同下游任务的通用用户表示,然而,需要这两个领域有共享的数据限制了该方法的应用范围。
跨领域的推荐是一个非常大的、非常复杂的问题,有兴趣的读者可以阅读参考文献26进行了解。同时,参考文献26的参考文献也提供了非常多的跨领域推荐的成果,大家可以进行有选择的学习。本节我们主要聚焦怎么利用大模型解决跨领域推荐问题。
由于大模型压缩了互联网世界的海量信息,那么任何两个领域之间在大模型中可能存在某种链接,只要找到这两个领域的链接关系,是可以借助大模型来进行跨领域推荐的。比如借助物品的描述信息,可以采用大模型作为物品描述特征编码器,以实现迁移学习和跨领域推荐,这里描述物品信息的自然语言就是连接来自不同领域的异构信息的桥梁。
参考文献19种的Chat-REC模型就是一个利用chatGPT进行跨领域推荐的很好的案例。利用互联网上的信息预先训练的chatGPT大模型实际上可以作为多视角的知识库。除了电影等一个领域的目标物品外,大模型不仅对音乐和书籍等许多其他领域的产品有着广泛的了解,而且还了解上述领域的物品之间的关系。
例如,如下面图23所示,一旦关于电影推荐的对话结束,用户就向Chat-REC询问关于其他类型作品的建议。Chat-REC随后根据用户的电影偏好推荐各种选项,如书籍、电视剧、播客和视频游戏。这展示了Chat-REC将用户偏好从电影转移到其他作品的能力,从而产生跨域推荐。这种跨领域推荐能力有可能显著扩展推荐系统的范围和相关性。

图23:Chat-REC跨领域推荐的案例(图片来源于参考文献19)
前面22.2.2.2节中提到的U-BERT(见参考文献3)大模型推荐系统也属于跨领域推荐。在预训练中,U-BERT专注于内容丰富的领域,并引入了一个用户编码器和一个评论编码器来对用户的行为进行建模。在微调中,U-BERT借助预训练模型获得的用户表示,在目标内容不足的领域进行个性化推荐。
另外,前面22.2.2.2.2节中提到的UniSRec模型就可以很好地解决跨领域推荐问题。UniSRec模型通过基于文本的预训练模型以通用的方式表示物品,可以实现领域自适应,该方法不要求源域和目标域密切相关。UniSRec通过精心设计的通用预训练任务和MoE增强的适配器架构,借助UniSRec模型中的通用SRL(Sequence Representation Learning)方法可以在来自多个源域的数据上进行预训练,并应用到没有共享数据的目标域中。
22.3 大模型应用于推荐系统的问题及挑战
我们上面讲解了大模型在推荐系统各个方面的应用,推荐系统的每一个子领域或者细分方向都可以被大模型赋能,看起来大模型像是无所不能,实际上大模型在推荐系统的应用还处在非常初级的阶段,目前大多数还是在学术研究、业务探索阶段。将大模型应用于推荐系统不是一件容易的事情,会面临非常多的问题和挑战,下面我们就针对这方面做简单说明,让读者大致了解大模型推荐系统当前可能存在的问题。
大语言模型本身就存在一些已知的问题,比如幻觉、知识过时(大模型只能获取在训练的当前时间物料库中对应的知识)、资源消耗(训练、推理需要大量的GPU计算资源)等。这些问题目前也有一些处理方式,比如幻觉可以利用RLHF等技术缓解,知识过时可以在大模型应用时接入搜索引擎,推理时资源消耗目前也可以通过模型蒸馏等技术优化,但是这些问题还是无法彻底地解决,这对大模型应用于推荐系统也会产生副作用。
本节我们不深入探讨大模型本身的问题带来的困难与挑战,我们主要从推荐系统的角度来讲解大模型应用于推荐系统这个下游任务时可能存在的问题及挑战,下面我们分5个维度展开说明。
22.3.1 大模型进行信息交互的形式限制
目前大模型主要还是语言大模型,推荐系统跟大模型交互必须将所有信息编码为文本信息注入模型,而推荐系统的重要信息除了文本外还有用户ID、物品ID,这些一般是数字或者字符串的形式,他们跟文本不在同一个语义空间,不适合直接当成文本使用。如果无法很好地整合这些信息,这可能会导致部分信息的丢失,导致预测准确度的降低。
针对物品ID,很多大模型方法(如参考文献17)直接用物品的标题来代替,这虽然可以部分解决冷启动问题,但是用户与物品的协同交互信息等可能会缺失,导致效果不佳。同时很多物品的标题很相似、甚至一样,导致很难区分。
用户ID识别目前也没有很好的解决方案,一般是将用户的历史行为或者与大模型交互的上下文作为信息输入大模型来给用户进行推荐。很多用户可能交互历史比较多,很难全部注入大模型(一是下面将要讲到的token限制,二是下面讲到的大模型目前存在位置bias),所以在必要的时候需要借助传统推荐系统进行召回、然后利用大模型优化召回的结果,将最终的推荐结果展示给用户。
22.3.2 大模型输入的token长度限制
目前chatGPT只能输入4000 token(约3000个单词),GPT-4 提升到了32k token(即3万2千个token,约2.4万个单词)。token的数量限制严重影响大模型的ICL(上下文学习)、CoT(思维链)能力,因此是一个非常重要的问题。
token太少了的话,对大模型应用于推荐系统至少会存在两个问题:一是待推荐的物品集可能无法全部输入到大模型,导致大模型可能会生成不在物品集中的物品。如果预测的物品不在候选物品集中,可以通过物品的title进行语义匹配,但是效果不一定好(见参考文献17);二是用户的交互行为记录或者用户跟大模型的历史会话可能无法全部输入到模型中,这导致大模型无法获得用户最全面的兴趣偏好,导致推荐精度下降。
目前虽然有论文(见参考文献27)提到可以将token拓展到一百万,但是在超大规模的大模型中是否能很好地应用还不清楚,这个方法目前也没有得到工业界的有效性验证。
22.3.3 位置bias
位置bias说的是将大模型作为ranking时,当我们将候选物品集输入大模型,输入的物品的顺序对最终预测结果影响比较大。如果待推荐的物品放到候选物品集的前面时,预测结果比放在后面好(参考文献13、17都提到了这个现象),其中参考文献13是通过bootstrap(也就是多次随机候选物品集的顺序输入大模型)的方式来缓解这个问题的。
22.3.4 流行度bias
这个问题在一般推荐系统中也存在,也就是推荐系统一般会倾向于推荐更热门的物品。大模型学习的是世界知识,那么热门的物品在大模型的训练语料库中当然会更多,所以导致大模型在应用于推荐时,也会倾向于推荐热门的物品。参考文献13中提到当输入给用户的待推荐候选集数量更少时,流行度bias会适当好些。但是候选集太少,可能会错失输入用户可能感兴趣的物品(即召回率可能会降低)。
22.3.5 输出结果的不可控性
大模型的输出是带有随机性的,一般会有一个温度参数来控制,温度参数范围为0-100,值越大生成的文本随机性也越大。大模型的输出随机性也是有价值的,这可以让大模型可以展示出一定的组合式创造能力。
大模型输出结果的不可控性会导致多次输入相同的推荐候选集获得的输出可能都不一样,这种不一致性对于推荐的追溯和排查带来一定的难度,输出结果的不一致性甚至会产生输出的物品不在候选集中的情况。目前这个问题不太好解决,一般会在大模型输出后增加一次优化逻辑,对大模型的输出结果微调,保证最终给到用户的推荐是满足要求的。
22.4 大模型推荐系统的发展趋势与行业应用
我们在上面花了非常多的篇幅讲解了大模型怎么应用于推荐系统,知道了大模型基本可以应用于推荐系统的各个方面,包括数据处理、特征工程、召回、排序、交互控制、冷启动、推荐解释、跨领域推荐等,读者也大致知道了大模型的威力了。
目前大模型在推荐系统上的应用还处于起步阶段,但是在推荐系统各个应用方面都有相关的学术探索并取得了较好的实验结果,未来几年就是在企业落地了。我相信再花1-2年,随着大模型技术的发展,大模型训练、推理一定会加速,成本也会降低,目前大模型存在的一些问题(见上面一节的介绍)也会出现比较好的解决方案,大模型的行业应用一定会遍地开花。
下面基于作者在推荐行业多年的实践经验及作者对大模型和大模型推荐系统的理解,说说大模型在未来几年的发展趋势及在行业上的应用。我们从下面5个维度来展开说明大模型应用于行业的形式及可能对行业带来的影响和变革。
22.4.1 大模型和传统推荐系统互为补充
传统推荐系统发展了这么多年,目前技术非常成熟,也在商业上获得了非常好的效果,很多方法非常有价值。在未来几年,主流的推荐系统架构还会保持不变(这主要是APP产品的形态不变,比如淘宝还是以手机上的触屏交互为主),那么大模型可能就是作为整个推荐架构中各个模块的补充,比如通过大模型提取特征、进行召回、排序、利用大模型压缩的世界知识进行跨领域、多场景的推荐等。这方面的应用上面的22.2节也介绍了非常多,无非是在未来几年怎么更好地落地到工业界,真正产生业务价值。
目前的推荐系统是场景特定的机器学习应用,这是指在任何一个新的场景需要基于新场景的数据重新训练推荐模型,每个场景的模型大小、参数等可能不一样,当前的推荐系统还无法做兼容非常多的行业、场景。有了大模型的加持,后面可以基于大模型进行预训练,然后再在不同场景进行微调或者进行zero-shot、few-shot推荐,这样就可以极大降低推荐系统应用到新行业、新场景的难度,这对于云计算厂商、或者toB创业公司将推荐系统应用到各行各业是一个非常大的优势。同理,有多个业务的生态公司,也会受益于大模型推荐系统的这种强泛化能力,可以将大模型推荐系统应用于公司的各个子业务。
22.4.2 融合多模态信息是大模型推荐的方向
大模型对于用户ID、物品ID这类数据还较难处理,目前没有很好的方法将这些信息注入到大模型中(也即将用户本身的识别问题及用户与物品ID的交互信息压缩到大模型的参数中),这个方向也是整个推荐行业需要克服的困难。
目前GPT-4已经具备了一定的多模态能力了,midjourney、runway等公司的模型能很好地生成图片、视频。待大模型的多模态能力更加完善,就可以更好地应用于推荐系统。
推荐系统的数据本身就是多源的、异构的数据(参见第4章的介绍),包含用户ID、物品ID、表格数据、文本、图片、视频、音频等。如果大模型具备一致地处理多模态数据的能力,那么这些数据中蕴含的物品物品之间、物品与用户之间、用户与用户之间的联系可以更好地被大模型学习到,进而可以做出更加精准的、一致的推荐。
22.4.3 基于增量学习的大模型推荐系统一定会出现
当前的大模型学习范式主要有三个:预训练直接使用、先预训练再微调、先预训练再zero-shot或few-shot,这很难将动态的信息压缩到模型中,而人类的学习就是增量学习的。怎么让大模型具备增量学习的能力目前是一个比较大的挑战,也是非常有业务价值的一个方向。
解决大模型增量学习的方法可能有两个:一个是通过快速微调的方式注入新信息到模型中,这个方法难度会更低,属于打补丁的做法,效果上可能也会打折扣;第二个方法是直接让整个大模型(也就是预训练过程)具备增量学习的能力,也就是新样本输入模型后在神经网络中“走一遍”就可以动态地微调大模型的参数。
一旦大模型具备了增量学习能力了,那么现在的实时推荐系统就可以做成一个自动进化的系统,无需太多的人工和工程干预就可以自动学习用户随时间的兴趣变化,做到越来越智能,越来越懂用户,最终让用户体验、商业价值得到极大的提升。
22.4.4 对话式推荐系统会成为重要的产品形态
我们在22.2.3节中介绍了2个利用大模型进行交互控制的算法案例,相信大家也有所了解了。大模型最大的价值是可以利用自然语言进行流畅的交互,就像人与人对话一样自然。这种对话式推荐最大的价值在于互动性,能够增加用户的信任感和接受度,同时在对话过程中可以逐步挖掘用户当前真实的兴趣偏好。
对话式推荐系统的应用场景未来会非常多,包括对话机器人、车载智能设备、智能音箱、智能电视等,未来这些适合对话式互动的场景一定会被基于大模型的对话式推荐系统所取代。
传统的推荐场景,比如抖音首页推荐、淘宝推荐等,如果借助对话推荐的思路,在用户滑动屏幕过程中通过提示等方式配合滑动也可以部分起到对话互动的作用,但是具体怎么实现,可能需要产品经理和设计师进行相关的探索和实践。
22.4.5 借助大模型,推荐和搜索有可能合二为一
chatGPT发布不久,微软就宣布将chatGPT整合到bing搜索中,目前百度、Google的搜索系统中都有大模型相关的能力加持。基于上面提到的大模型的互动对话能力,搜索和推荐很有可能被融合到一个统一的业务框架中(目前虽然手机百度中包含推荐,但是搜索和推荐还是比较割裂的,没有真正融为一体)。
其实,搜索是用户基于明确的目标的信息获取过程,用户通过输入关键词或者一句话来获取所需的内容。而推荐是基于用户过往的历史,通过模型学习用户的兴趣,再基于兴趣给用户进行推荐,我们可以将推荐系统理解为基于用户所有历史(或者挖掘出的用户的兴趣点)的搜索过程,在这个思考框架下它们就是统一的。另外,搜索和推荐的技术体系是一致的,在工业界都是分为召回、排序的过程,利用的算法也基本都是通用的一套,这更有利于搜索与推荐的统一。
大模型通过互动式对话就可以非常自然的在同一个对话框中融合推荐、搜索能力,也即可以通过自然语言跟用户的互动将推荐、搜索融入到了服务用户的能力当中。
总结
本章我们基于chatGPT、大模型的核心能力,讲解了chatGPT、大模型为什么能应用于推荐系统。我们详细讲解了在推荐系统的各个维度大模型是怎么应用的,包括数据处理、特征工程、召回、排序、互动对话、冷启动、推荐解释、跨领域推荐等推荐系统的重要维度都可以应用大模型。大模型在召回、排序的应用是本章的重点,读者需要了解大模型3种最重要的应用范式:预训练范式;预训练、微调范式;预训练、提示范式。
当前大模型应用于推荐系统会存在一些问题和挑战,比如受信息交互形式、输入token长度的限制,同时大模型也会出现位置bias、流行度bias及推荐结果的随机性。虽然有这么多问题,大模型未来几年一定会在行业上遍地开花。大模型会跟传统推荐系统很好地融合、取长补短,多模态信息和增量学习这些大模型目前比较难解决的问题待解决后一定会应用到推荐系统中。另外,由于大模型天然的自然语言处理能力,对话式推荐肯定会在非常多的场景中起主要作用,搜索与推荐由于解决的问题可以在自然语言下统一到一个框架之下,这一趋势在未来几年一定会出现。
目前chatGPT、大模型在推荐系统的应用还处于学术研究阶段(读者可以阅读参考文献28、29,进一步了解大模型应用于推荐系统的各种可能),只有非常少的行业探索案例。本章我们也主要是结合学术文章基于作者自己的行业经验和对推荐系统的理解进行了详细的介绍。作者对大模型在推荐系统的应用非常有信心,相信不出几年,以大模型为基础能力的推荐系统一定会革新现有的推荐体系,所以希望读者多关注这方面的研究和行业动向,多思考、多实践,一定要跟上技术的发展大势。
参考文献
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
[Borisov et al., 2023] Vadim Borisov, Kathrin Sessler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators. In The Eleventh International Conference on Learning Representations, 2023.
[Qiu et al., 2021] Zhaopeng Qiu, Xian Wu, Jingyue Gao, and Wei Fan. U-bert: Pre-training user representations for improved recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 4320–4327, 2021.
[Liu et al., 2023b] Peng Liu, Lemei Zhang, and Jon Atle Gulla. Pre-train, prompt and recommendation: A comprehensive survey of language modelling paradigm adaptations in recommender systems. arXiv preprint arXiv:2302.03735, 2023.
2019 BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
2022 Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
2022 M6-Rec- Generative Pretrained Language Models are Open-Ended Recommender Systems
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21, 140 (2020), 1–67. http://jmlr.org/papers/v21/20- 074.html
[Hou et al., 2022] Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. Towards universal sequence representation learning for recommender systems. In SIGKDD, pages 585–593, 2022.
[Shang et al., 2019] Junyuan Shang, Tengfei Ma, Cao Xiao, and Jimeng Sun. Pre-training of graph augmented transformers for medication recommendation. In IJCAI-19, pages 5953–5959, 7 2019.
[Zhou et al., 2020] Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In ACM CIKM, pages 1893–1902, 2020.
[Hou et al., 2023] Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian J. McAuley, and Wayne Xin Zhao. Large language models are zero-shot rankers for recommender systems. CoRR, abs/2305.08845, 2023.
Zero-Shot Next-Item Recommendation using Large Pretrained Language Models
[Sileo et al., 2022] Damien Sileo, Wout Vossen, and Robbe Raymaekers. Zero-shot recommendation as language modeling. In ECIR, pages 223–230, 2022.
[Ding et al., 2021] Hao Ding, Yifei Ma, Anoop Deoras, Yuyang Wang, and Hao Wang. Zero-shot recommender systems. arXiv preprint arXiv:2105.08318, 2021.
Is ChatGPT a Good Recommender? A Preliminary Study
2022.02.10 LaMDA- Language Models for Dialog Applications
2023 Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
[Friedman et al., 2023] Luke Friedman, Sameer Ahuja, David Allen, Terry Tan, Hakim Sidahmed, Changbo Long, Jun Xie, Gabriel Schubiner, Ajay Patel, Harsh Lara, et al. Leveraging large language models in conversational recommender systems. arXiv preprint arXiv:2305.07961, 2023.
[Wu et al., 2022b] Yiqing Wu, Ruobing Xie, Yongchun Zhu, Fuzhen Zhuang, Xu Zhang, Leyu Lin, and Qing He. Personalized prompts for sequential recommendation. arXiv preprint arXiv:2205.09666, 2022.
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. ACL-IJNLP (2021).
Guanghui Qin and Jason Eisner. 2021. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. In Proceedings of NAACL.
Li, L., Zhang, Y., Chen, L.: Personalized transformer for explainable recommendation. arXiv preprint arXiv:2105.11601 (2021)
Li, L., Zhang, Y., Chen, L.: Generate neural template explanations for recommendation. In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management. pp. 755–764 (2020)
Zhu, F., Wang, Y., Chen, C., Zhou, J., Li, L., Liu, G.: Cross-domain recommendation: challenges, progress, and prospects. arXiv preprint arXiv:2103.01696 (2021)
Scaling Transformer to 1M tokens and beyond with RMT
2023.06.01 A Survey on Large Language Models for Recommendation
2023.06.28 How Can Recommender Systems Benefit from Large Language Models- A Survey
