Arthas(阿尔萨斯)监控线上Java程序,解决无法线上性能调优问题
1、Arthas介绍
Arthas是阿里在2018年9月开源的Java诊断工具,支持 JDK6+,采用的是命令交互模式,提供Tab 自动补全,在线排查问题,无需重启,动态跟踪Java代码,实时监控JVM状态,方便Java大佬们定位和诊断线上程序运行问题。
开源地址:https://github.com/alibaba/arthas
官方文档:https://arthas.aliyun.com/doc/
2、Arthas使用场景(解决的问题)
1、可以全局视角来查看系统的运行状况?
2、排查CPU升高,是哪里占用CPU
3、排查运行的多线程出现死锁,阻塞的情况
4、程序运行耗时很长,排查是哪里出现耗时长
5、这个类是哪个jar包加载的?为什么会报各种类相关的Exception?
6、可以监控JVM的实时运行状态
3、工具对比
| 操作难易 | 是否开源 | 优势 | 劣势 | |
| jvisualvm | 中上 | 开源 | ||
| jprofiler | 中上 | 开源 | ||
| Arthas | 中 | 开源 |
4、下载
linux安装wget命令
sudo yum -y install wget下载安装Arthas
sudo wget https://alibaba.github.io/arthas/arthas-boot.jar
5、实操
1、进入服务器,cd 到指定目录路径下
2、查找对应的服务,找到对应的容器名

3、执行脚本,进入容器并且运行Arthas
sh run-arthas.sh skyway-oss-device-provider查到skyway-oss-device-provider.jar,输入1,点击ENTER即可
看到如图这样,说明Arthas启动成功,并且监控skyway-oss-device-provider这个服务
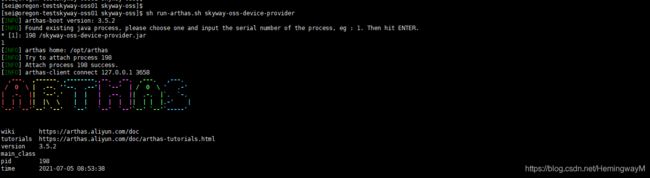
此图为run-arthas.sh脚本
![]()
4、dashboard
查看程序的线程、内存、GC、运行环境信息
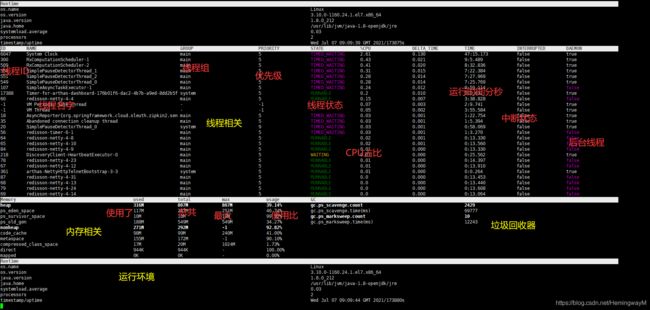
内存泄漏:
1、内容使用率不断上升,而且gc后也不下降,并且发现gc越来越频繁,很可能就内存泄漏
2、判断出现内存泄漏,通过heapdump命令把内存快照dump出来,这个命令跟jmap工具一样
$:heapdump --live /root/jvm.hprof
将成功的dump文件导入到工具中,根据快照定位具体问题
从容器中将文件copy出来:docker cp 容器名:/root/jvm.hprof /home/sei/
1、MAT工具:https://www.eclipse.org/mat/downloads.php
2、Java自动工具:jvisualvm
3、jprofler:https://www.ej-technologies.com/download/jprofiler/version_110
![]()
5、thread
查看占用CPU最高的线程,总线程数,跟线程状态对应的数量
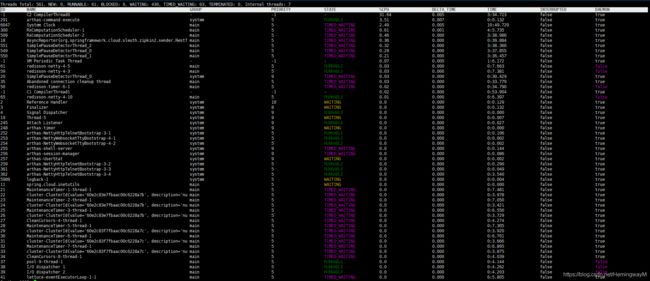
5.1 thread -n 10(查看占用CPU前十的线程)
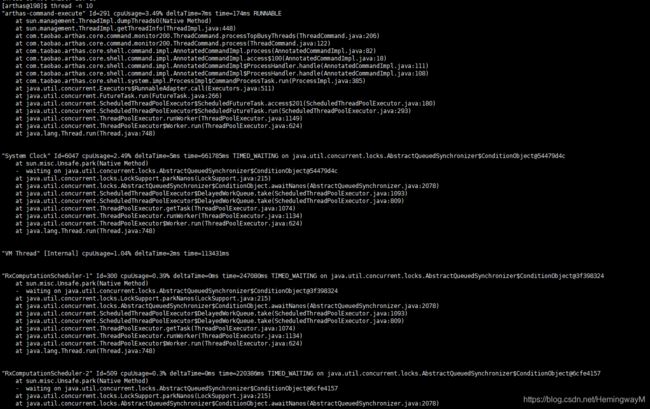
5.2 thread ID(查看ID线程的运行堆栈)
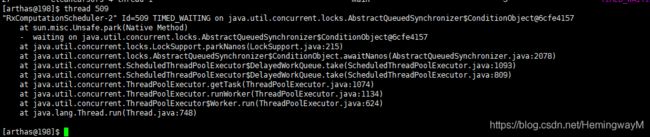
5.3 查看线程是否有死锁
thread -b
thread --state BLOCKED(查看指定状态的线程)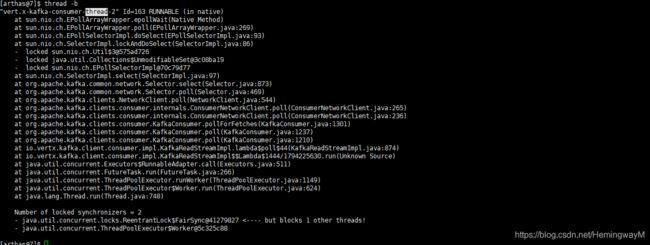
5.4 查看线程池里线程的状态
thread | grep pool
可以查看到线程池中有WAITING的线程
thread 398
5.5 统计最近1000ms内的线程CPU时间
thread -i 1000
thread -n 5 -i 1000(列出1000ms内最忙的5个线程栈) 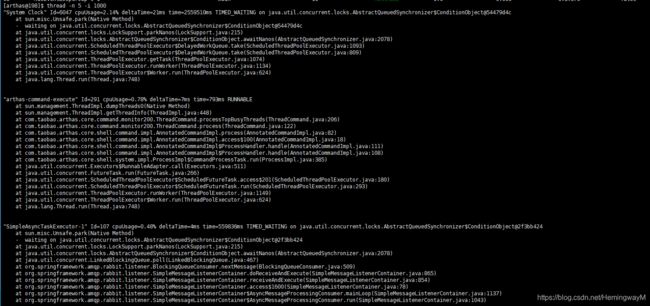
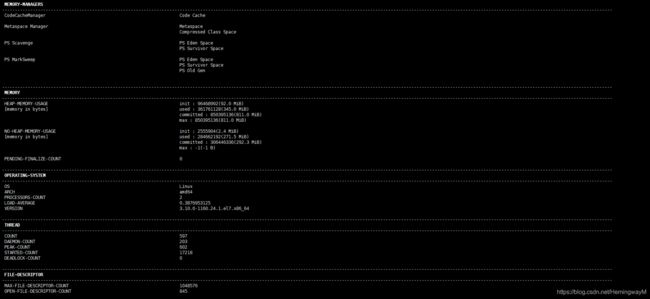
6、查看JVM的信息(输入JVM即可)
jvm命名中thread相关
- COUNT: JVM当前活跃的线程数
- DAEMON-COUNT: JVM当前活跃的守护线程数
- PEAK-COUNT: 从JVM启动开始曾经活着的最大线程数
- STARTED-COUNT: 从JVM启动开始总共启动过的线程次数
- DEADLOCK-COUNT: JVM当前死锁的线程数
7、monitor(监视一个时间段中指定方法的执行次数,成功次数,失败次数,耗时信息)
表明5秒输出一次监控的值(这个操作会导致JVM运行方法变慢,操作完之后,要关闭Arthas)
monitor -c 5 com.seirobotics.device.api.admin.DeviceGroupController getGroupList监控值说明:
timestamp:时间戳
class:Java类
method:方法(构造方法、普通方法)
total:调用次数
success:成功次数
fail:失败次数(指的是抛出的异常)
avg-rt:平均RT(根据这个平均耗时时间,模拟不同参数场景下方法耗时情况)
fail-rate:失败率

8、watch(通过watch命令定位函数的返回值)
watch命令定义了4个观察事件点,-b方法调用前,-e方法异常后,-s方法返回后,-f方法结束后
4个观察事件点-b、-e、-s默认关闭,-f默认打开,当指定观察点被打开后,在相应事件点会观察表达式进行求值并输出
这个要注意方法入参和方法出参的区别,有可能在中间被修改导致前后不一致,除了-b事件点params代表方法入参外,其余事件都代表方法出参
当使用-b时,由于观察事件点是在方法调用前,此时返回值或异常均不存在
#cost>20 (单位是ms),表示这个方法耗时20ms就会输出结果,过滤执行时间小于20ms的调用
watch com.seirobotics.device.api.admin.DeviceGroupController getGroupList "{params, returnObj}" '#cost>20' -x 2(根据耗时超过20ms进行过滤,查看返回值和出参)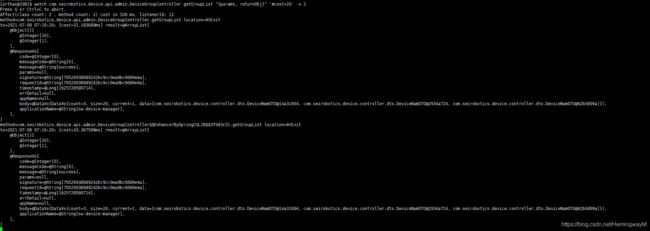
9、trace(方法内部调用路径,输出方法路径上的每个节点耗时,渲染和统计整个调用链路上的所有性能开销和追踪调用链路)
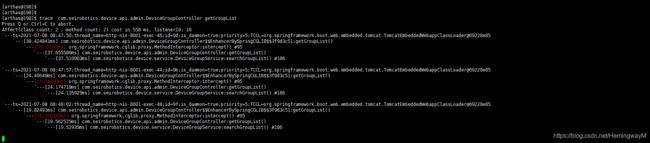
trace com.seirobotics.device.api.admin.DeviceGroupController getGroupList从监控结果可以查出得出
getGroupList()函数耗时37.6556ms
searchGroupList()函数耗时37.5109ms
由于调用链路比较短的原因,其实从链路调用函数去排查问题,接下来就是对代码进行一步一步分析,在进行优化
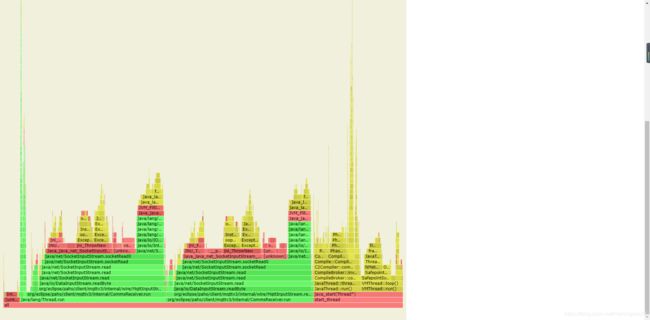
10、火焰图
什么时候用火焰图:当发现CPU的占用率与实际业务应该出现的占用率不相符,或者对Nginx worker的资源使用率(CPU、内存、磁盘IO)出啊先怀疑情况下,使用火焰图进行抓取,对 CPU 占用率低、吐吞量低的情况也可以使用火焰图的方式排查程序中是否有阻塞调用导致整个架构的吞吐量低下
启动火焰图:profiler start
获取采集的sample数量:profiler getSamples
查看profiler状态:profiler status
停止profiler:profiler stop
11、Arthas命令思维导图