On Evaluation of Embodied Navigation Agents 论文阅读
论文信息
题目:On Evaluation of Embodied Navigation Agents
作者:Peter Anderson,Angel Chang
来源:arXiv
时间:2018
Abstract
过去两年,导航方面的创造性工作激增。这种创造性的输出产生了大量有时不兼容的任务定义和评估协议。为了协调该领域正在进行和未来的研究,我们召集了一个工作组来研究导航研究的实证方法。本文件总结了该工作组的共识建议。我们讨论不同的问题陈述和泛化的作用,提出评估措施,并提供可用于基准测试的标准场景。
Introduction
通用任务定义和评估协议的融合促进了计算机视觉领域的巨大进步
Goal Specification and Sensory Input
导航任务可以从几个维度来区分。
一是目标的性质。我们确定三种类型的目标:
• PointGoal。代理必须导航到特定位置。例如,假设代理从原点开始,目标可能是导航到位置 (100, 300),其中单位为米。如果环境是空的,这个任务就很简单,但超出了现有系统在之前从未探索过的现实杂乱环境中的能力[28]。
• ObjectGoal。代理必须导航到特定类别的对象。该类别可以从预定义的集合中提取。例如,“冰箱”、“汽车”或“钥匙”。为了执行此任务,智能体必须利用有关世界的先验知识,例如“冰箱”的外观以及可以在哪里找到它。
• AreaGoal。代理必须导航到指定类别的区域。例如,“厨房”、“车库”或“门厅”。此任务还依赖于有关不同区域的外观和布局的先验知识。
不同类型的目标可以通过不同的方式来指定。
前面的描述中举例说明了基本规范:
PointGoal 的坐标、ObjectGoal 和 AreaGoal 的分类标签。
还有另外两种有趣且值得注意的规范类型:
图像(或其他感知输入)和语言。例如,ObjectGoal 任务可以通过相关对象的图像来指定 [32]。 PointGoal 任务可以通过自然语言的描述来指定[1]。其中一些规范模式还支持 ObjectGoal 和 AreaGoal 任务的实例特定形式:例如,找到此图像中显示的特定汽车(而不是任何汽车)。
该代理可能配备不同的传感模式,例如视觉(RGB 图像)、深度或触觉。另一种可能的输入是环境示意图,类似于人类在导航时使用的那种。
Generalization and Exploration
另一个主要区别是先前暴露于评估试剂的环境的程度。
最近的工作涉及广泛。一方面是在新环境中评估代理的协议,在测试之前不暴露于环境 [12, 28]。另一端是在代理测试的相同环境中进行广泛训练的协议,为代理提供数天或数周的测试场景训练[20]。
在整个范围内,有一些协议让代理在评估之前短暂暴露于测试环境(大约几分钟的主观体验);在此初步暴露期间,代理可以构建一个内部表示,然后用于支持导航[27]。
我们的基本原则是,应严格量化和报告代理在导航事件之前暴露于测试环境的程度。在导航试验之前需要在测试环境中获得丰富经验的方法可能是合理的,但必须明确量化和记录事先暴露于环境的情况。我们可以确定一些关于泛化的制度:
• No prior exploration。事先没有暴露于测试环境。特工被要求在前所未有的新环境中找到出路 [12, 28]。
• Pre-record prior exploration。代理会获得环境中探索轨迹的记录。探索由第三方(例如,人类或自动探索策略)执行,并为每个测试环境提供记录,作为基准测试设置的一部分。代理可以使用提供的记录来构建可以支持后续导航的环境的内部表示[27]。
• Time-limited exploration by the agent。代理获得勘探预算。在导航事件之前,智能体可以自由地穿越环境,直到其轨迹长度达到给定的预算。这种体验可用于构建环境的内部表示,以支持后续的导航事件。探索政策处于代理的控制之下,但暴露于测试环境的程度仍然是有限和量化的。
Evaluation Measures
我们解决的第一个问题是代理是否需要发出已完成任务的信号。在最近的一些工作中,一旦智能体足够接近目标,导航事件就会终止并被视为成功。我们建议不要这样做,因为这样的协议不会测试智能体是否理解它已经达到了目标。
我们认为这种理解至关重要:智能体不能只是偶然发现目标,它必须明白目标已经达到。为了表明这种理解,我们建议在代理的词汇表中添加专门的操作。该操作可以称为“完成”,表示代理已准备好进行评估。当代理产生这个特殊信号“完成”时,应该评估代理相对于目标的配置以及到达目标所采取的路径。如果没有这样的信号,即使智能体接近目标,导航事件也不应被视为成功
建议 1. 代理必须配备特殊操作,表明其已完成导航事件并准备好进行评估。代理相对于目标的配置必须在产生此动作时进行评估,而不是在情节期间某个有利的先前时间进行评估
建议 2:为了测量接近度(例如,智能体与目标的接近度),我们建议使用测地距离,即环境中的最短路径距离。
我们现在继续描述我们建议用于评估导航性能的具体措施。
为了定义这样的衡量标准,我们首先采用导航事件是否成功的二元标准。为了评估这个标准,我们考虑代理在输出操作“完成”时的配置。
(如果智能体没有产生这样的动作,则该情节自动被视为不成功。)如果此时智能体足够接近目标,则该情节成功。
对于 PointGoal 或 ObjectGoal,如果智能体与目标之间的距离低于阈值 τ,则该情节成功。我们建议默认使用 2× 代理身体宽度的阈值。
对于 AreaGoal,如果智能体的质心位于指定区域内,则该情节成功。
配备了情景成功的二元定义,我们进行了 N 个测试情景。在每一集中,代理的任务是实现目标。令 i 为第 i 集中智能体从起始位置到目标的最短路径距离,并令 pi 为智能体在本集中实际采取的路径长度。令 Si 为第 i 集成功的二元指标。我们定义了代理在测试集中的导航性能的汇总度量,如下所示:
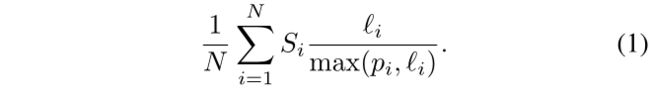
我们将此度量称为 SPL,是“按(归一化逆)路径长度加权的成功”的缩写。让我们考虑一些例子。如果 50% 的测试片段成功,并且智能体在所有测试片段中都采取最佳路径实现目标,则其 SPL 为 0.5。如果所有测试集都成功,但智能体达到目标的时间是其最佳表现时的两倍,则 SPL 也为 0.5。如果 50% 的测试集成功,并且所有测试集的 pi = 2‘i,则 SPL 为 0.25。
请注意,SPL 是一项相当严格的衡量标准。当在以前从未见过的相当复杂的环境中进行评估时,我们预计 0.5 的 SPL 是良好的导航性能水平。通过测量人类受试者的声压级,可以在每个数据集上更可靠地校准这一点。
建议 3. 我们建议采用 SPL 作为导航性能的主要衡量标准。
虽然我们建议将 SPL 作为主要评估指标,但我们注意到还有其他指标可以提供有关代理绩效的补充信息。除了 SPL 之外,我们鼓励报告此类辅助措施。对于辅助措施的一些建议是:a) 成功率与智能体所经过的归一化反距离的函数关系,b) 事件结束时到目标的距离(绝对或通过“i”归一化),c) SPL 扫描在不同的阈值 τ 上,d) 归一化逆路径长度的分布 ('i/ max(pi, 'i)),e) 违规次数(例如,与障碍物接触),以及 f) 轨迹上消耗的驱动时间和能量执行。
Experimental Testbeds
最近提出了许多室内环境模拟平台[4,12,16,28,30,31]。
它们基于环境集合,例如 AI2-THOR [16]、SUNCG [29]、Matterport3D [7] 和 Gibson [31]。其他用于研究导航的模拟器包括 ViZDoom 和 DeepMind Lab [15, 2](相对整洁的走廊布局)和 CARLA [10](室外城市环境)。我们不会推荐特定的模拟器而不是其他模拟器。相反,我们提出了两项技术建议,可以为未来模拟平台的设计提供信息。
建议4.我们建议使用连续状态空间,这样智能体可以在连续空间中自由移动。离散环境可以很方便,并且可以支持有趣的实验和结果 [1,3,19,22],但连续空间可以更好地反映代理在物理世界中部署的条件。
建议 5。为了可解释性和互操作性,我们建议在模拟器中采用 SI 单位。模拟器中的距离 1 应对应于 1 米
建议 6:我们建议模拟器由开源软件支持,使经过模拟训练的代理能够使用标准组件部署到物理机器人上
Standard Scenarios
SUNCG。我们使用 500 个不同复杂程度的单层 SUNCG 房屋(每个房屋有 1 到 10 个房间),分为 300/100/100 个训练/验证/测试环境。这些房屋共有 2,737 个房间、41,158 件物品,总建筑面积约 110,000 平方米。平均每户有5.5个房间,每间平均建筑面积为42平方米。这些环境代表了各种室内装饰,包括家庭住宅、办公室和餐厅等公共空间。代理的身体宽度为 0.2 m,我们将成功导航到目标的距离阈值 τ 设置为身体宽度的两倍 (0.4 m)。场景规范文件位于 github.com/minosworld/scenarios
Matterport3D。我们采用原始数据集 [7] 指定的 61/11/18 训练/验证/测试室分割。这些房屋共有 190 层,共有 2,206 个房间区域。平均每户有24.5个房间,建筑面积560平方米。这些环境主要是私人住宅、酒店和公司办公空间。与 SUNCG 场景类似,代理身体宽度为 0.2 m,距离阈值 τ 为 0.4 m。场景规范文件可从 github.com/minosworld/scenarios 获取。
AI2-THOR。 AI2-THOR 1.0版本包含120个场景,涵盖四个场景类别:厨房、客厅、卧室和浴室。每个类别中的前 20 个场景应用于训练(例如,厨房的 FloorPlan1 到 FloorPlan20)。每个类别中接下来的五个场景应用于验证(例如,厨房的 FloorPlan21 到 FloorPlan25),最后五个场景用于测试。训练应该在所有训练场景(总共80个场景)上进行。我们考虑 AI2-THOR 的两种目标规范:PointGoal 和 ObjectGoal。当前版本的 AI2-THOR 不适合 AreaGoal,因为每个场景仅包含一个房间。下面我们描述每个目标设置的规范。
PointGoal:对于每个测试场景,我们随机选择 5 个点作为目标,并将目标坐标提供给代理。我们还考虑了代理的 5 种不同起点和 5 种不同的场景配置(通过将对象移动到不同位置或更改其状态)。总共,每个测试场景有 5 × 5 × 5 = 125 个场景。如果智能体与目标点之间的距离低于智能体宽度的 2 倍,则该回合被认为是成功的。
此设置的操作集为:向前移动、向后移动、向右旋转、向左旋转和终止
ObjectGoal:我们提供对象类别标签来指定目标。如果对象对代理“可见”,则导航成功。在 AI2-THOR 中,如果某个物体距离摄像机 1 m 以内且位于智能体的视野范围内,则该物体被标记为“可见”。与 PointGoal 类似,我们为每个测试场景考虑 5 个不同的随机起点。选择目标有两种情况:
-
Navigation-only:在此设置中,以只能通过导航操作到达的方式选择目标。例如,仅通过导航操作无法到达柜子内的杯子,因为代理需要打开柜子才能看到杯子。为此设置设置的操作为:向前移动、向后移动、向右旋转、向左旋转、向上查找、向下查找和终止。
-
Interaction-based:在这种情况下,找到一些目标需要交互。此设置的操作集为:向前移动、向后移动、向右旋转、向左旋转、向上查找、向下查找、打开 X、关闭 X 和终止
Gibson。 Gibson 数据集包括 572 座建筑物,共 1,447 层,总面积为 211,000 平方米。这些空间是使用 3D 扫描仪扫描的真实建筑物。每栋建筑都具有一定的杂乱程度 (SSA) 和导航复杂性。空间及其元数据的可视化可在 http://gibson.vision/database/ 上获得。考虑到数据集的大小,我们指定了一些不同大小的标准分区以方便实验,例如小型(35 座建筑物)、中型(140 座建筑物)和完整(572 座建筑物)。每个分区的训练/验证/测试划分为:微小 (25/5/5)、中等 (100/20/20)、完整 (402/85/85),全部大约为 70%/15%/15%。
Agent Architectures
建议 7:体现代理设计的一个中心问题是代理在其环境中导航时构建和维护的内部表示的结构。我们鼓励对这个问题进行全面和开放的研究,我们认为这是人工智能发展的基础。