Spark中的WholeStageCodegenExec(全代码生成)
背景
在之前的文章中Spark DPP(动态分区裁剪)导致的DataSourceScanExec NullPointerException问题分析以及解决,我们直接跳过了动态代码生成失败这版本一步部分,这次我们来分析一下,SQL还是在以上提到的文章中。
分析
运行完该sql,我们可以看到如下的物理计划:
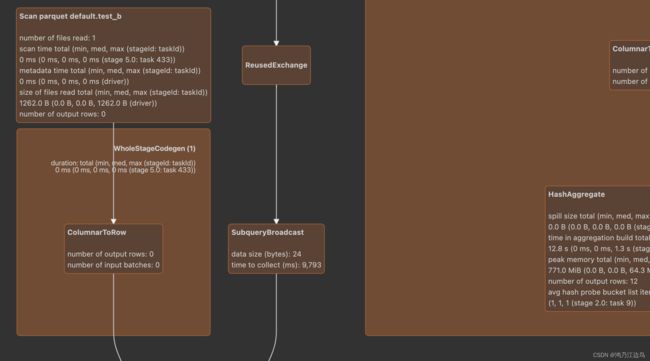
我们看到FilterExec和ColumnarRoRowExec并没有在一个WholeStageCodegen 中, 这是为什么呢?
这是因为exists方法是继承自CodegenFallback Trait。
我们可以跟踪一下物理规则CollapseCodegenStages,对应的代码如下:
private def insertWholeStageCodegen(plan: SparkPlan): SparkPlan = {
plan match {
// For operators that will output domain object, do not insert WholeStageCodegen for it as
// domain object can not be written into unsafe row.
case plan if plan.output.length == 1 && plan.output.head.dataType.isInstanceOf[ObjectType] =>
plan.withNewChildren(plan.children.map(insertWholeStageCodegen))
case plan: LocalTableScanExec =>
// Do not make LogicalTableScanExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CodegenSupport if supportCodegen(plan) =>
// The whole-stage-codegen framework is row-based. If a plan supports columnar execution,
// it can't support whole-stage-codegen at the same time.
assert(!plan.supportsColumnar)
WholeStageCodegenExec(insertInputAdapter(plan))(codegenStageCounter.incrementAndGet())
case other =>
other.withNewChildren(other.children.map(insertWholeStageCodegen))
}
在FilterExec做supportCodegen判断的时候,还会扫描他的表达式是否存在CodegenFallback的子类,如果存在则不会把FilterExec做全代码代码生成。显然这里是不满足条件的, 而他的child,也就是ColumnarRoRowExec 他是符合的,所以ColumnarRoRowExec是可以用全代码代码生成的。
所以在driver端生成RDD的时候,FilterExec还是会走自身的doExecute方法,也就是先会运行createCodeGeneratedObject代码部分,最终还是会调用到subexpressionElimination这个方法,从而报错。
其实我们可以修改一下对应的sql,让它走全代码生成,去掉exists的过滤条件.
FROM test_b where scenes='gogo' and exists(array(date1),x-> x =='2021-03-04') -> FROM test_b where scenes='gogo'
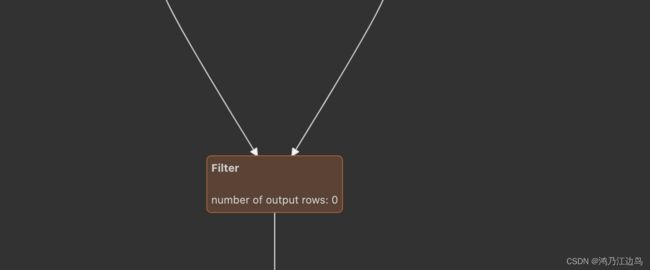
这样我们可以得到如下的物理计划:


可以看到FilterExec和ColumnerExec是在一个WholeStageCodegen中,从代码级别来说,就是会生成类似如下的数据结构:
WholeStageCodegenExec(FilterExec(ColumnarToRowExec(InputAdapter(FileSourceScanExec))))
所在在driver端生成对应RDD的时候,就会走到WholeStageCodegenExec的doExecute方法,如下:
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
// try to compile and fallback if it failed
val (_, compiledCodeStats) = try {
CodeGenerator.compile(cleanedSource)
} catch {
case NonFatal(_) if !Utils.isTesting && sqlContext.conf.codegenFallback =>
// We should already saw the error message
logWarning(s"Whole-stage codegen disabled for plan (id=$codegenStageId):\n $treeString")
return child.execute()
}
...
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
if (rdds.length == 1) {
rdds.head.mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter)
...
而 doCodeGen方法还是按照produce->doProduce->consume-doConsume>的调用方式来组织各个物理计划间的代码。
而最终还是会调用到FilterExec的doConsume代码,而这里面涉及到的DPP的表达式代码就是通过代码生成的:
override def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
val numOutput = metricTerm(ctx, "numOutputRows")
/**
* Generates code for `c`, using `in` for input attributes and `attrs` for nullability.
*/
def genPredicate(c: Expression, in: Seq[ExprCode], attrs: Seq[Attribute]): String = {
val bound = BindReferences.bindReference(c, attrs)
val evaluated = evaluateRequiredVariables(child.output, in, c.references)
// Generate the code for the predicate.
val ev = ExpressionCanonicalizer.execute(bound).genCode(ctx)
val nullCheck = if (bound.nullable) {
s"${ev.isNull} || "
} else {
...
通过genCode方法调用expression的 doGenCode方法。
对应到我们sql对应的表达式为DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId)) .
而DynamicPruningExpression的还是调用child的genCode的方法,也就是最终会调用到InSubqueryExec的doGenCode方法:
override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
prepareResult()
inSet.doGenCode(ctx, ev)
}
...
private def prepareResult(): Unit = {
require(resultBroadcast != null, s"$this has not finished")
if (result == null) {
result = resultBroadcast.value
}
}
prepareResult方法是准备broadcast的值。
inSet 方法只是正常对一行row进行计算。
全代码生成完后,进行代码的编译,如下:
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
if (rdds.length == 1) {
rdds.head.mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter))
这里的rdds是会调用inputRDDs方法,而该方法是递归调用child的inputRDDs方法,最终会调用到ColumnarToRowExec的inputRDDs方法,
从而调用InputAdapter的executeColumnar方法,最终会调用到FileSourceScanExec的doExecuteColumnar方法,从而生成对应的RDD。
生成的代码会在executor端再次被编译,从而进行运算。
注意:resultBroadcast的值是在WholeStageCodegenExec的方法execute中完成的:
final def execute(): RDD[InternalRow] = executeQuery {
if (isCanonicalizedPlan) {
throw new IllegalStateException("A canonicalized plan is not supposed to be executed.")
}
doExecute()
}
其中executeQuery方法如下:
protected final def executeQuery[T](query: => T): T = {
RDDOperationScope.withScope(sparkContext, nodeName, false, true) {
prepare()
waitForSubqueries()
query
}
}
...
final def prepare(): Unit = {
// doPrepare() may depend on it's children, we should call prepare() on all the children first.
children.foreach(_.prepare())
synchronized {
if (!prepared) {
prepareSubqueries()
doPrepare()
prepared = true
}
}
}
prepare和prepareSubqueries方法递归调用,从而使子节点都能把准备工作做好,如这里的driver端的广播,从而在executor端能够获取对应的广播变量。
至此,分析就完成了。