RabbitMQ六种工作模式
Simple 模式
消息产生着将消息放入队列
消息的消费者 (consumer) 监听 (while) 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除 (隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失) 应用场景:聊天 (中间有一个过度的服务器;p 端,c 端)
Simple 模式也是最简单的模式

生产者 ——> 队列 ——> 消费者
就这么简单,你可以理解为 redis 里面的 list “队列”,另外多说一句 redis 里面的队列都是用 list 来模拟的,不要以为 list 就是队列,它,不是!充其量是一个列表,stream 类型是 redis5 新出的,stream 还可以够的上是一个队列,并且是乞丐版的 kafka, 应对一般的流量冲击还是搓搓有余的!
接下来我们会直接上 golang 当中操作 rabbitmq 的代码,提前提醒一下这很重要,因为接下里的五中模式都会基于此代码进行改造哈
因为我们需要使用 rabbitmq 所以在 golang 当中那就需要引入包,
go get github.com/streadway/amqp

上代码:
rbtmqone.go(一个 rabbitmq 各种操作的工具类文件):
package rbtmqcs
import (
"fmt"
"github.com/streadway/amqp"
"log")
//url 格式 amqp://账号:密码@rabbitmq服务器地址:端口号/Virtual Host
//格式在golang语言当中是固定不变的
const MQURL = "amqp://dada:[email protected]:5672/aka"
type RabbitMQ struct {
conn *amqp.Connection //需要引入amqp包 连接amqp.Dial()
channel *amqp.Channel //信道amqp.Dial().Channel() 也就是conn.Channel()
//队列名称
QueueName string
//交换机
Exchange string
//key
Key string
//链接信息
Mqurl string
}
//创建RabbitMQ结构体实例
func NewRabbitMQ(queuename string,exchange string,key string) *RabbitMQ {
rabbitmq := &RabbitMQ{QueueName:queuename,Exchange:exchange,Key:key,Mqurl:MQURL}
var err error
//创建rabbitmq连接
rabbitmq.conn,err = amqp.Dial(rabbitmq.Mqurl) //通过amqp.Dial()方法去链接rabbitmq服务端
rabbitmq.failOnErr(err,"创建连接错误!") //调用我们自定义的failOnErr()方法去处理异常错误信息
rabbitmq.channel,err = rabbitmq.conn.Channel() //链接上rabbitmq之后通过rabbitmq.conn.Channel()去设置channel信道
rabbitmq.failOnErr(err,"获取channel失败!")
return rabbitmq
}
//断开channel和connection
//为什么要断开channel和connection 因为如果不断开他会始终使用和占用我们的channel和connection 断开是为了避免资源浪费
func (r *RabbitMQ) Destory() {
r.channel.Close() //关闭信道资源
r.conn.Close() //关闭链接资源
}
//错误处理函数
func (r *RabbitMQ) failOnErr(err error,message string) {
if err != nil {
log.Fatalf("%s:%s",message,err)
panic(fmt.Sprintf("%s:%s",message,err))
}
}
//简单模式step:1.创建简单模式下的rabbitmq实例
func NewRabbitMQSimple(queueName string) *RabbitMQ {
//simple模式下交换机为空因为会默认使用rabbitmq默认的default交换机而不是真的没有 bindkey绑定建key也是为空的
//特别注意:simple模式是最简单的rabbitmq的一种模式 他只需要传递queue队列名称过去即可 像exchange交换机会默认使用default交换机 绑定建key的也不必要传
return NewRabbitMQ(queueName,"","")
}
//简单模式step:2.简单模式下生产代码
func (r *RabbitMQ) PublishSimple(message string) {
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.发送消息到队列当中
r.channel.Publish(
//交换机 simple模式下默认为空 我们在上边已经赋值为空了 虽然为空 但其实也是在用的rabbitmq当中的default交换机运行
r.Exchange,
//队列的名称
r.QueueName,
//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,
//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
false,
//要发送的消息
amqp.Publishing{
ContentType:"text/plain",
Body:[]byte(message),
})
}
//简单模式step:3.简单模式下消费者代码
func (r *RabbitMQ) ConsumeSimple() {
//申请队列和生产消息当中是一样一样滴 直接复制即可
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
//队列名称
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.接收消息
//建立了链接 就跟socket一样 一直在监听 从未被终止 这也就保证了下边的子协程当中程序的无线循环的成立
msgs,err := r.channel.Consume(
//队列名称
r.QueueName,
//用来区分多个消费者
"",
//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
true,
//是否具有排他性
false,
//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,
//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
false,
nil,
)
if err != nil {
fmt.Println(err)
}
//3.消费消息
forever := make(chan bool)
//启用协程处理消息
go func() {
//子协程不会结束 因为msgs有监听 会不断的有值进来 就算没值也在监听 就跟socket服务一样一直在监听从未被中断!
for d:=range msgs {
//实现我们要处理的逻辑函数
log.Printf("Recieved a message : %s",d.Body)
//fmt.Println(d.Body)
}
}()
log.Printf("[*] Waiting for message,To exit press CTRL+C")
//最后我们来阻塞一下 这样主程序就不会死掉
<-forever
}
pushSimple.go 发送数据 生产者网队列里面放入数据
package main
import (
"fmt"
"mqsz/rbtmqcs"
)
func main() {
rabitmq := rbtmqcs.NewRabbitMQSimple("queueone")
rabitmq.PublishSimple("hello dada!!!")
fmt.Println("发送ok!")
}
consumeSimple.go 消费者从队列里面读取数据
package main
import (
"mqsz/rbtmqcs"
)
func main() {
rabbitmq := rbtmqcs.NewRabbitMQSimple("queueone")
rabbitmq.ConsumeSimple()
}
目录结构如下:
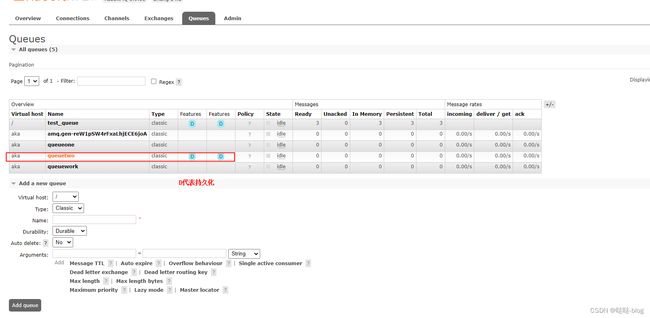
再来看一下视图界面吧:
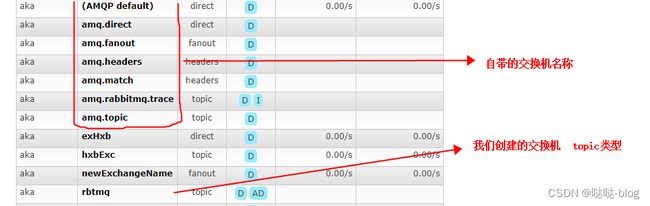
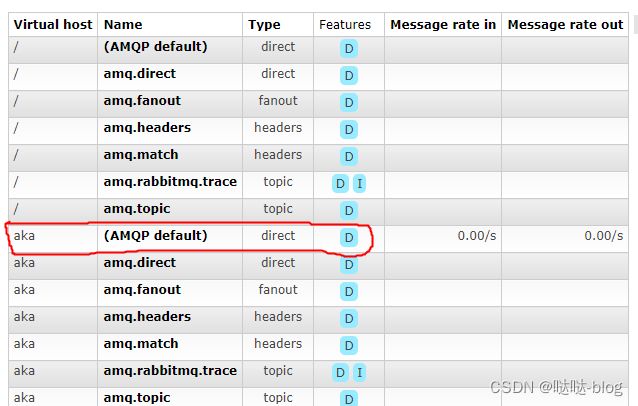
simple 模式下是灭有交换机的 exchange, 并不是这样的,其实是有的,如下图就是 aka 这个 virtual host 对应的就是默认的 default 交换机 类型是 direct
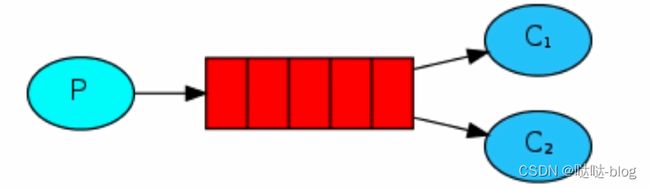
Work 模式
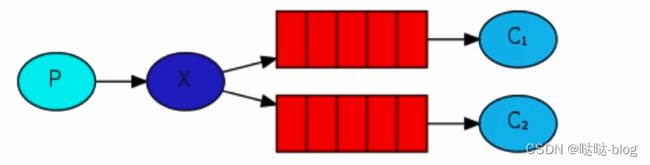
- 消息产生者将消息放入队列消费者可以有多个,消费者 1, 消费者 2, 同时监听同一个队列,消息被消费?C1 C2 共同争抢当前的消息队列内容,谁先拿到谁负责消费消息 (隐患,高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关 (syncronize, 与同步锁的性能不一样) 保证一条消息只能被一个消费者使用)
- 应用场景:红包;大项目中的资源调度 (任务分配系统不需知道哪一个任务执行系统在空闲,直接将任务扔到消息队列中,空闲的系统自动争抢)
一个消息只能被一个消费者获取
当生产者生产消息的速度大于消费者消费的速度的时候就要考虑用 work 工作模式,因为这样能提高处理速度提高负载!
其实吧,work 模式就是比 simple 模式多了一些消费者,以前 simple 模式只有一个消费者在消费,如果你弄多个消费者那就变成了 work 模式并且这多个工作者之间就会满足上边 1,2 所讲的规则
我们还是直接上代码吧:
rbtmqone.go(一个 rabbitmq 各种操作的工具类文件)
workOne.go 文件 作为生产者:
package main
import (
"fmt"
"mqsz/rbtmqcs"
"strconv"
)
func main() {
rabitmq := rbtmqcs.NewRabbitMQSimple("queuework")
for i := 0; i < 1000; i++ {
//strconv.Itoa(i) 将整形转为字符串
rabitmq.PublishSimple("hello dd "+strconv.Itoa(i))
}
fmt.Println("发送ok!")
}
workTwo.go和workThree.go一样
package main
import (
"mqsz/rbtmqcs"
)
func main() {
rabbitmq := rbtmqcs.NewRabbitMQSimple("queuework")
rabbitmq.ConsumeSimple()
}
目录结构:
输出:
你还可以搞更多的消费者 代码都一样 消费者越多那么读取队列里面消息的速度也就越快
你会发现 workTwo 读的都是奇数 workThree 读的都是偶数 这就验证了上边 1,2 当中讲到的原则!
Publish 订阅模式
- X 代表交换机 rabbitMQ 内部组件,erlang 消息产生者是代码完成,代码的执行效率不高,消息产生者将消息放入交换机,交换机发布订阅把消息发送到所有消息队列中,对应消息队列的消费者拿到消息进行消费
- 相关场景:邮件群发,群聊天,广播 (广告)
注意:Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
Publish/Subscribe (出版/订阅)订阅模式,消息被路由投递给多个队列,一个消息被多个消费者获取
rbtmq.go
//rabbitmq的核心文件 包含了链接conn channle 生产消费数据的方法 相当于公共类文件
package rbtmq
import (
"fmt"
"github.com/streadway/amqp"
"log"
)
//url 格式 amqp://账号:密码@rabbitmq服务器地址:端口号/Virtual Host
//格式在golang语言当中是固定不变的
const MQURL = "amqp://dada:[email protected]:5672/aka"
type RabbitMQ struct {
conn *amqp.Connection //需要引入amqp包 连接amqp.Dial()
channel *amqp.Channel
//队列名称
QueueName string
//交换机
Exchange string
//key
Key string
//链接信息
Mqurl string
}
//创建RabbitMQ结构体实例
func NewRabbitMQ(queuename string,exchange string,key string) *RabbitMQ {
rabbitmq := &RabbitMQ{QueueName:queuename,Exchange:exchange,Key:key,Mqurl:MQURL}
var err error
//创建rabbitmq连接
rabbitmq.conn,err = amqp.Dial(rabbitmq.Mqurl) //通过amqp.Dial()方法去链接rabbitmq服务端
rabbitmq.failOnErr(err,"创建连接错误!") //调用我们自定义的failOnErr()方法去处理异常错误信息
rabbitmq.channel,err = rabbitmq.conn.Channel() //链接上rabbitmq之后通过rabbitmq.conn.Channel()去设置channel信道
rabbitmq.failOnErr(err,"获取channel失败!")
return rabbitmq
}
//断开channel和connection
//为什么要断开channel和connection 因为如果不断开他会始终使用和占用我们的channel和connection 断开是为了避免资源浪费
func (r *RabbitMQ) Destory() {
r.channel.Close() //关闭信道资源
r.conn.Close() //关闭链接资源
}
//错误处理函数
func (r *RabbitMQ) failOnErr(err error,message string) {
if err != nil {
log.Fatalf("%s:%s",message,err)
panic(fmt.Sprintf("%s:%s",message,err))
}
}
//简单模式step:1.创建简单模式下的rabbitmq实例
func NewRabbitMQSimple(queueName string) *RabbitMQ {
//simple模式下交换机为空因为会默认使用rabbitmq默认的default交换机而不是真的没有 bindkey绑定建key也是为空的
//特别注意:simple模式是最简单的rabbitmq的一种模式 他只需要传递queue队列名称过去即可 像exchange交换机会默认使用default交换机 绑定建key的会不必要传
return NewRabbitMQ(queueName,"","")
}
//简单模式step:2.简单模式下生产代码
func (r *RabbitMQ) PublishSimple(message string) {
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.发送消息到队列当中
r.channel.Publish(
//交换机 simple模式下默认为空 我们在上边已经赋值为空了 虽然为空 但其实也是在用的rabbitmq当中的default交换机运行
r.Exchange,
//队列的名称
r.QueueName,
//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,
//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
false,
//要发送的消息
amqp.Publishing{
ContentType:"text/plain",
Body:[]byte(message),
})
}
//简单模式step:3.简单模式下消费者代码
func (r *RabbitMQ) ConsumeSimple() {
//申请队列和生产消息当中是一样一样滴 直接复制即可
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
//队列名称
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.接收消息
//建立了链接 就跟socket一样 一直在监听 从未被终止 这也就保证了下边的子协程当中程序的无线循环的成立
msgs,err := r.channel.Consume(
//队列名称
r.QueueName,
//用来区分多个消费者
"",
//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
true,
//是否具有排他性
false,
//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,
//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
false,
nil,)
if err != nil {
fmt.Println(err)
}
//3.消费消息
forever := make(chan bool)
//启用协程处理消息
go func() {
//子协程不会结束 因为msgs有监听 会不断的有值进来 就算没值也在监听 就跟socket服务一样一直在监听从未被中断!
for d:=range msgs {
//实现我们要处理的逻辑函数
log.Printf("Recieved a message : %s",d.Body)
//fmt.Println(d.Body)
}
}()
log.Printf("[*] Waiting for message,To exit press CTRL+C")
//最后我们来阻塞一下 这样主程序就不会死掉
<-forever
}
//Publish订阅模式step1:创建rabbitmq实例
func NewRabbitMQPubSub(exchangeName string) *RabbitMQ {
//创建RabbitMQ实例
return NewRabbitMQ("",exchangeName,"")
}
//订阅模式step2:生产者
func (r *RabbitMQ) PublishPub(message string) {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//直接false即可 也不知道干啥滴
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
"",
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//订阅模式step3:消费者
func (r *RabbitMQ) RecieveSub() {
//这一步和 订阅模式step2:生产者 里面的代码是一样一样滴
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写
q,err := r.channel.QueueDeclare(
//随机生产队列名称 这个地方一定要留空
"",
false,
false,
true,//具有排他性 即队列只为当前链接服务 链接断开 队列被删除 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,
//在pub/sub模式下,这里的key要为空
"",
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
r.QueueName,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
pubSubOne.go 生产者
package main
import (
"fmt"
"mqsz/rbtmq"
"strconv"
"time"
)
func main() {
rabitmq := rbtmq.NewRabbitMQPubSub("newExchangeName")
rabitmq.PublishPub("start dada!!!")
for i := 0; i < 100; i++ {
rabitmq.PublishPub("订阅模式生成第 "+strconv.Itoa(i)+" 条数据")
fmt.Println("订阅模式生成第 "+strconv.Itoa(i)+" 条数据")
time.Sleep(1*time.Second)
}
}
pubSubTwo.go 消费者一
package main
import "mqsz/rbtmq"
func main() {
rabitmq := rbtmq.NewRabbitMQPubSub("newExchangeName")
rabitmq.RecieveSub()
}
pubSubThree.go 消费者二
package main
import "mqsz/rbtmq"
func main() {
rabitmq := rbtmq.NewRabbitMQPubSub("newExchangeName")
rabitmq.RecieveSub()
}
目录结构
结果你会发现 我们执行生产者的代码将消息写入到队列当中去 然后消费者端执行代码 不管你起几个消费者 那么得到的队列里面的消息都是一样一样滴! 这也就验证了 消息被路由投递给多个队列 一个消息被多个消费者消费的原则!!! 是不是非常适合做广播、群发的功能呢?是滴!再多唠叨几句,比如一个界面,大家登陆上来之后都能看到老大发的消息,如果用 simple 那么一个消费者消费完就完事啦,如果用 worker 模式一个消费者不能消费同一个消息也不行,只有订阅模式可以,订阅模式只要老大发送消息大家都能收到,因为一个消息可以被多个消费者所消费!
Routing 路由模式
- 消息生产者将消息发送给交换机按照路由判断,路由是字符串 (info) 当前产生的消息携带路由字符 (对象的方法), 交换机根据路由的 key, 只能匹配上路由 key 对应的消息队列,对应的消费者才能消费消息;
- 根据业务功能定义路由字符串
- 从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中业务场景:error 通知;EXCEPTION; 错误通知的功能;传统意义的错误通知;客户通知;利用 key 路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误;
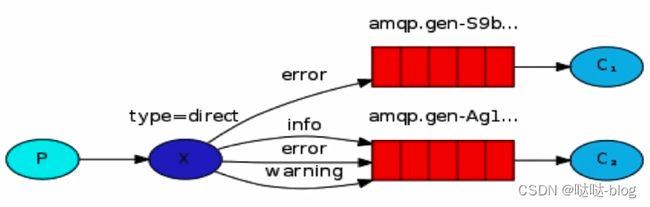
一个消息被多个消费者获取,并且消息的目标队列可以被生产者指定
从生产端就可以指定队列消息的消费者是谁
交换机的类型是 direct 类型 在订阅模式下是 faout 广播类型 这里是发生了变化的
多个消费者传入相同的 key 那么可以实现多个消费者消费一个队列的消息的功能!
rbtmqone.go
package rbtmqcs
//rabbitmq的核心文件 包含了链接conn channle 生产消费数据的方法 相当于公共类文件
import (
"fmt"
"github.com/streadway/amqp"
"log"
"time"
)
//url 格式 amqp://账号:密码@rabbitmq服务器地址:端口号/Virtual Host
//格式在golang语言当中是固定不变的
const MQURL = "amqp://dada:[email protected]:5672/aka"
type RabbitMQ struct {
conn *amqp.Connection //需要引入amqp包 连接amqp.Dial()
channel *amqp.Channel
//队列名称
QueueName string
//交换机
Exchange string
//key
Key string
//链接信息
Mqurl string
}
//创建RabbitMQ结构体实例
func NewRabbitMQ(queuename string,exchange string,key string) *RabbitMQ {
rabbitmq := &RabbitMQ{QueueName:queuename,Exchange:exchange,Key:key,Mqurl:MQURL}
var err error
//创建rabbitmq连接
rabbitmq.conn,err = amqp.Dial(rabbitmq.Mqurl) //通过amqp.Dial()方法去链接rabbitmq服务端
rabbitmq.failOnErr(err,"创建连接错误!") //调用我们自定义的failOnErr()方法去处理异常错误信息
rabbitmq.channel,err = rabbitmq.conn.Channel() //链接上rabbitmq之后通过rabbitmq.conn.Channel()去设置channel信道
rabbitmq.failOnErr(err,"获取channel失败!")
return rabbitmq
}
//断开channel和connection
//为什么要断开channel和connection 因为如果不断开他会始终使用和占用我们的channel和connection 断开是为了避免资源浪费
func (r *RabbitMQ) Destory() {
r.channel.Close() //关闭信道资源
r.conn.Close() //关闭链接资源
}
//错误处理函数
func (r *RabbitMQ) failOnErr(err error,message string) {
if err != nil {
log.Fatalf("%s:%s",message,err)
panic(fmt.Sprintf("%s:%s",message,err))
}
}
//简单模式step:1.创建简单模式下的rabbitmq实例
func NewRabbitMQSimple(queueName string) *RabbitMQ {
//simple模式下交换机为空因为会默认使用rabbitmq默认的default交换机而不是真的没有 bindkey绑定建key也是为空的
//特别注意:simple模式是最简单的rabbitmq的一种模式 他只需要传递queue队列名称过去即可 像exchange交换机会默认使用default交换机 绑定建key的会不必要传
return NewRabbitMQ(queueName,"","")
}
//简单模式step:2.简单模式下生产代码
func (r *RabbitMQ) PublishSimple(message string) {
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.发送消息到队列当中
r.channel.Publish(
//交换机 simple模式下默认为空 我们在上边已经赋值为空了 虽然为空 但其实也是在用的rabbitmq当中的default交换机运行
r.Exchange,
//队列的名称
r.QueueName,
//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,
//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
false,
//要发送的消息
amqp.Publishing{
ContentType:"text/plain",
Body:[]byte(message),
})
}
//简单模式step:3.简单模式下消费者代码
func (r *RabbitMQ) ConsumeSimple() {
//申请队列和生产消息当中是一样一样滴 直接复制即可
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
//队列名称
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.接收消息
//建立了链接 就跟socket一样 一直在监听 从未被终止 这也就保证了下边的子协程当中程序的无线循环的成立
msgs,err := r.channel.Consume(
//队列名称
r.QueueName,
//用来区分多个消费者
"",
//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
true,
//是否具有排他性
false,
//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,
//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
false,
nil,)
if err != nil {
fmt.Println(err)
}
//3.消费消息
forever := make(chan bool)
//启用协程处理消息
go func() {
//子协程不会结束 因为msgs有监听 会不断的有值进来 就算没值也在监听 就跟socket服务一样一直在监听从未被中断!
for d:=range msgs {
//实现我们要处理的逻辑函数
log.Printf("Recieved a message : %s",d.Body)
//fmt.Println(d.Body)
}
}()
log.Printf("[*] Waiting for message,To exit press CTRL+C")
//最后我们来阻塞一下 这样主程序就不会死掉
<-forever
}
//Publish订阅模式step1:创建rabbitmq实例
func NewRabbitMQPubSub(exchangeName string) *RabbitMQ {
//创建RabbitMQ实例
return NewRabbitMQ("",exchangeName,"")
}
//订阅模式step2:生产者
func (r *RabbitMQ) PublishPub(message string) {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//直接false即可 也不知道干啥滴
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
"",
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//订阅模式step3:消费者
func (r *RabbitMQ) RecieveSub() {
//这一步和 订阅模式step2:生产者 里面的代码是一样一样滴
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写
q,err := r.channel.QueueDeclare(
//随机生产队列名称 这个地方一定要留空
"",
false,
false,
true,//具有排他性 即队列只为当前链接服务 链接断开 队列被删除 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,
//在pub/sub模式下,这里的key要为空
"",
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
r.QueueName,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//路由模式step1:创建RabbitMQ实例
func NewRabbitMQRouting(exchangeName string,routingKey string) *RabbitMQ {
return NewRabbitMQ("",exchangeName,routingKey)
}
//路由模式step2:发送消息
func (r *RabbitMQ) PublishRouting(message string) {
//1.尝试创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct这个和在订阅模式下是不一样的
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
r.Key,//除了设置交换机这也要设置绑定的key值
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//路由模式step3:消费者
func (r *RabbitMQ) RecieveRouting() {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//路由模式step3:消费者
func (r *RabbitMQ) RecieveRoutingSleep() {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
fmt.Println("绑定队列到exchange中")
time.Sleep(20 * time.Second)//Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
fmt.Println("接收队列消息,开始消费")
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
routingOne.go
//路由模式生产者
package main
import (
"fmt"
"mqsz/rbtmqcs"
"strconv"
"time"
)
func main() {
//路由模式下通过key将队列绑定到交换机上 这个队列式内部自动生成的 不需要指定名称 用的时候传递key即可找到绑定的queue队列
//比如下边 传递了两个key那么就会内部绑定到交换机上两个队列 消费者只需要传递key过去即可找到交换机上绑定好的队列里面的消息进行消费
rabbitmqOne := rbtmqcs.NewRabbitMQRouting("exHxb","xiaobai_one")
rabbitmqTwo := rbtmqcs.NewRabbitMQRouting("exHxb","xiaobai_two")
for i:=0;i<=100;i++ {
rabbitmqOne.PublishRouting("hello xiaobai one" + strconv.Itoa(i))
rabbitmqTwo.PublishRouting("hello xiaobai two" + strconv.Itoa(i))
time.Sleep(1 * time.Second)
fmt.Println(i)
}
}
routingTwo.go
//路由模式消费者一
package main
import "mqsz/rbtmqcs"
func main(){
rabbitmqOne := rbtmqcs.NewRabbitMQRouting("exHxb","xiaobai_one")
rabbitmqOne.RecieveRouting()
}
routingThree.go
//路由模式消费者二
package main
import "mqsz/rbtmqcs"
func main(){
rabbitmqTwo := rbtmqcs.NewRabbitMQRouting("exHxb","xiaobai_two")
rabbitmqTwo.RecieveRouting()
}
目录格式
Topic 话题模式
- 星号井号代表通配符
- 星号代表多个单词,井号代表一个单词
- 路由功能添加模糊匹配
- 消息产生者产生消息,把消息交给交换机
- 交换机根据 key 的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
一个消息被多个消费者获取。消息的目标 queue 可用 bindingkey 以通配符(#:一个或者多个词,*: 一个词)的方式指定
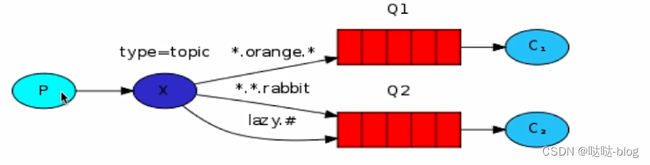
再说的直白一点其实就是根据传入的 key 进行模糊匹配 匹配到 key 之后就去找交换机上跟这个 key 绑定的队列去读取进行消费 当然匹配到可能多个 key 那么可能就会有多个队列被消费!
rbtmqone.go
package rbtmqcs
//rabbitmq的核心文件 包含了链接conn channle 生产消费数据的方法 相当于公共类文件
import (
"fmt"
"github.com/streadway/amqp"
"log"
"time"
)
//url 格式 amqp://账号:密码@rabbitmq服务器地址:端口号/Virtual Host
//格式在golang语言当中是固定不变的
const MQURL = "amqp://dada:[email protected]:5672/aka"
type RabbitMQ struct {
conn *amqp.Connection //需要引入amqp包 连接amqp.Dial()
channel *amqp.Channel
//队列名称
QueueName string
//交换机
Exchange string
//key
Key string
//链接信息
Mqurl string
}
//创建RabbitMQ结构体实例
func NewRabbitMQ(queuename string,exchange string,key string) *RabbitMQ {
rabbitmq := &RabbitMQ{QueueName:queuename,Exchange:exchange,Key:key,Mqurl:MQURL}
var err error
//创建rabbitmq连接
rabbitmq.conn,err = amqp.Dial(rabbitmq.Mqurl) //通过amqp.Dial()方法去链接rabbitmq服务端
rabbitmq.failOnErr(err,"创建连接错误!") //调用我们自定义的failOnErr()方法去处理异常错误信息
rabbitmq.channel,err = rabbitmq.conn.Channel() //链接上rabbitmq之后通过rabbitmq.conn.Channel()去设置channel信道
rabbitmq.failOnErr(err,"获取channel失败!")
return rabbitmq
}
//断开channel和connection
//为什么要断开channel和connection 因为如果不断开他会始终使用和占用我们的channel和connection 断开是为了避免资源浪费
func (r *RabbitMQ) Destory() {
r.channel.Close() //关闭信道资源
r.conn.Close() //关闭链接资源
}
//错误处理函数
func (r *RabbitMQ) failOnErr(err error,message string) {
if err != nil {
log.Fatalf("%s:%s",message,err)
panic(fmt.Sprintf("%s:%s",message,err))
}
}
//简单模式step:1.创建简单模式下的rabbitmq实例
func NewRabbitMQSimple(queueName string) *RabbitMQ {
//simple模式下交换机为空因为会默认使用rabbitmq默认的default交换机而不是真的没有 bindkey绑定建key也是为空的
//特别注意:simple模式是最简单的rabbitmq的一种模式 他只需要传递queue队列名称过去即可 像exchange交换机会默认使用default交换机 绑定建key的会不必要传
return NewRabbitMQ(queueName,"","")
}
//简单模式step:2.简单模式下生产代码
func (r *RabbitMQ) PublishSimple(message string) {
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.发送消息到队列当中
r.channel.Publish(
//交换机 simple模式下默认为空 我们在上边已经赋值为空了 虽然为空 但其实也是在用的rabbitmq当中的default交换机运行
r.Exchange,
//队列的名称
r.QueueName,
//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,
//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
false,
//要发送的消息
amqp.Publishing{
ContentType:"text/plain",
Body:[]byte(message),
})
}
//简单模式step:3.简单模式下消费者代码
func (r *RabbitMQ) ConsumeSimple() {
//申请队列和生产消息当中是一样一样滴 直接复制即可
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
//队列名称
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//2.接收消息
//建立了链接 就跟socket一样 一直在监听 从未被终止 这也就保证了下边的子协程当中程序的无线循环的成立
msgs,err := r.channel.Consume(
//队列名称
r.QueueName,
//用来区分多个消费者
"",
//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
true,
//是否具有排他性
false,
//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,
//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
false,
nil,)
if err != nil {
fmt.Println(err)
}
//3.消费消息
forever := make(chan bool)
//启用协程处理消息
go func() {
//子协程不会结束 因为msgs有监听 会不断的有值进来 就算没值也在监听 就跟socket服务一样一直在监听从未被中断!
for d:=range msgs {
//实现我们要处理的逻辑函数
log.Printf("Recieved a message : %s",d.Body)
//fmt.Println(d.Body)
}
}()
log.Printf("[*] Waiting for message,To exit press CTRL+C")
//最后我们来阻塞一下 这样主程序就不会死掉
<-forever
}
//Publish订阅模式step1:创建rabbitmq实例
func NewRabbitMQPubSub(exchangeName string) *RabbitMQ {
//创建RabbitMQ实例
return NewRabbitMQ("",exchangeName,"")
}
//订阅模式step2:生产者
func (r *RabbitMQ) PublishPub(message string) {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//直接false即可 也不知道干啥滴
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
"",
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//订阅模式step3:消费者
func (r *RabbitMQ) RecieveSub() {
//这一步和 订阅模式step2:生产者 里面的代码是一样一样滴
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写
q,err := r.channel.QueueDeclare(
//随机生产队列名称 这个地方一定要留空
"",
false,
false,
true,//具有排他性 即队列只为当前链接服务 链接断开 队列被删除 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,
//在pub/sub模式下,这里的key要为空
"",
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
r.QueueName,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//路由模式step1:创建RabbitMQ实例
func NewRabbitMQRouting(exchangeName string,routingKey string) *RabbitMQ {
return NewRabbitMQ("",exchangeName,routingKey)
}
//路由模式step2:发送消息
func (r *RabbitMQ) PublishRouting(message string) {
//1.尝试创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct这个和在订阅模式下是不一样的
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
r.Key,//除了设置交换机这也要设置绑定的key值
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//路由模式step3:消费者
func (r *RabbitMQ) RecieveRouting() {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//路由模式step3:消费者
func (r *RabbitMQ) RecieveRoutingSleep() {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
fmt.Println("绑定队列到exchange中")
time.Sleep(20 * time.Second)//Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
fmt.Println("接收队列消息,开始消费")
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//topic主题模式step1:创建RabbitMQ实例
func NewRabbitMQTopic(exchange string,routingkey string) *RabbitMQ {
//创建RabbitMQ实例
return NewRabbitMQ("",exchange,routingkey)
}
//topic主题模式step2:发送消息
func (r *RabbitMQ) PublishTopic(message string){
//1.尝试创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"topic",//类型 topic主题模式下我们需要将类型设置为topic
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
r.Key,//除了设置交换机这也要设置绑定的key值
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//topic主题模式step2:消费者
//要注意key 规则
//其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
//匹配 huxiaobai.* 表示匹配 huxiaobai.hello 但是huxiaobai.one.two 需要用huxiaobai.# 才能匹配到
func (r *RabbitMQ) RecieveTopic(){
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"topic",//类型 topic主题模式下我们需要将类型设置为topic
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
topicOne.go 生产者:
package main
//topic主题模式生产者
import (
"fmt"
"mqsz/rbtmqcs"
"strconv"
"time"
)
func main(){
rabbitmqOne := rbtmqcs.NewRabbitMQTopic("hxbExc","huxiaobai.one")
rabbitmqTwo := rbtmqcs.NewRabbitMQTopic("hxbExc","huxiaobai.two.cs")
for i:=0;i<=10;i++{
rabbitmqOne.PublishTopic("hello huxiaobai one" + strconv.Itoa(i))
rabbitmqTwo.PublishTopic("hello huxiaobai two" + strconv.Itoa(i))
time.Sleep(1 * time.Second)
fmt.Println(i)
}
}
topicTwo.go 消费者一
//topic主题模式消费者一
package main
import "mqsz/rbtmqcs"
func main(){
//#号表示匹配多个单词 也就是读取hxbExc交换机里面所有队列的消息
rabbitmq := rbtmqcs.NewRabbitMQTopic("hxbExc","#")
rabbitmq.RecieveTopic()
}
topicThree.go 消费者二
package main
import "mqsz/rbtmqcs"
func main(){
//这里只是匹配到了huxiaobai.后边只能是一个单词的key 通过这个key去找绑定到交换机上的相应的队列
rabbitmq := rbtmqcs.NewRabbitMQTopic("hxbExc","huxiaobai.*.cs")
rabbitmq.RecieveTopic()
}
自动手动ack

当消息一旦被消费者接收,队列中的消息就会被删除。那么问题来了:RabbitMQ 怎么知道消息被接收了呢?
这就要通过消息确认机制(Acknowlege)来实现了。当消费者获取消息后,会向 RabbitMQ 发送回执 ACK,告知消息已经被接收。不过这种回执 ACK 分两种情况:
- 自动 ACK:消息一旦被接收,消费者自动发送 ACK
- 手动 ACK:消息接收后,不会发送 ACK,需要手动调用
这两 ACK 要怎么选择呢?这需要看消息的重要性:
- 如果消息不太重要,丢失也没有影响,那么自动 ACK 会比较方便
- 如果消息非常重要,不容丢失。那么最好在消费完成后手动 ACK,否则接收消息后就自动 ACK,RabbitMQ 就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了。
实际上自动应答是存在缺陷的!为什么呢?比如消费端消费了队列里面的消息,读取出来了然后执行正常业务逻辑插入数据库,这个时候服务端就自动 ack 删除掉了队列里面的这个消息了,但是呢,你 sql 执行失败了,也就是正常的业务逻辑失败了,那么你回过头来一看,卧槽它妈妈,队列里面的消息也给我删除啦!那岂不是造成了业务失败了并且队列里面的消息也丢失的情况?是吧!是!
如果你是使用的手动 ack, 等到正常的业务逻辑也就是入库成功了你再告诉服务器可以删除队列里面的消息啦,服务器才会去删除也就不存在上述的情况啦!这么看来手动 ack 还是比自动 ack 要安全一些的!但是手动 ack 也是存在一些弊端的比如性能,更深入的就不谈了,因为我也没太深入的了解,因为没他么必要这么深入的玩!我能解决问题就 ok 啦!
:::info
1):什么是消息确认 ACK。
答:如果在处理消息的过程中,消费者的服务器在处理消息的时候出现异常,那么可能这条正在处理的消息就没有完成消息消费,数据就会丢失。为了确保数据不会丢失,RabbitMQ 支持消息确定 - ACK。
2):ACK 的消息确认机制。
答:ACK 机制是消费者从 RabbitMQ 收到消息并处理完成后,反馈给 RabbitMQ,RabbitMQ 收到反馈后才将此消息从队列中删除。
如果一个消费者在处理消息出现了网络不稳定、服务器异常等现象,那么就不会有 ACK 反馈,RabbitMQ 会认为这个消息没有正常消费,会将消息重新放入队列中。
如果在集群的情况下,RabbitMQ 会立即将这个消息推送给这个在线的其他消费者。这种机制保证了在消费者服务端故障的时候,不丢失任何消息和任务。
消息永远不会从 RabbitMQ 中删除,只有当消费者正确发送 ACK 反馈,RabbitMQ 确认收到后,消息才会从 RabbitMQ 服务器的数据中删除。
消息的 ACK 确认机制默认是打开的。
3):ACK 机制的开发注意事项。
答:如果忘记了 ACK,那么后果很严重。当 Consumer 退出时候,Message 会一直重新分发。然后 RabbitMQ 会占用越来越多的内容,由于 RabbitMQ 会长时间运行,因此这个” 内存泄漏” 是致命的。
4):确认机制分为三种:none、auto (默认)、manual
Auto
1、如果消息成功被消费(成功的意思是在消费的过程中没有抛出异常),则自动确认
2、当抛出 AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝,且 requeue = false(不重新入队列)
3、当抛出 ImmediateAcknowledgeAmqpException 异常,则消费者会被确认
4、其他的异常,则消息会被拒绝,且 requeue = true,此时会发生死循环,可以通过 setDefaultRequeueRejected(默认是 true)去设置抛弃消息
:::
特别提示:
如果在消费消息的时候 接收消息的时候你设置的 autoAck 为 false 但是在消费消息完成之后没有手动 ack 通知服务器的后果是什么呢?
队列里面的消息会被挨个消费一遍,但是因为服务器没有收到你手动的 ack 消息,那么它以为失败了会自动将消费的消息再回写到队列当中去,就会导致已经消费了的消息被重复消费!
所以如下图所示:
接收消息和消费完成之后的回执消息时候的设置要一致!
光有 ack 还没不行,我们还需要配合 qos 一起来使用
qos
消费者流量控制
在实际项目中使用 RabbitMQ 的时候,由于消费者自身处理消息的效率并不高,如果说这个时候生产者还是不断的在生产消息,一直推送消息到消费者,那么很容易引起消费者的宕机。
rabbitmq 提供了一个限流机制,用于限制一次性推送到消费者客户端的消息数量,让消费者都处理完了消息之后,生产者再推送新的消息过来
限流的原因
出于以下两个方面,所以需要对消费者进行一些限流策略
【a】假设某个时候,在 rabbitmq 队列中已经堆积了非常非常多的消息,这个时候,如果有一个消费者启动,那么大量的消息将会一起推送到这个消费者上面,这种瞬间超大流量,很有可能导致服务器崩溃
【b】生产者生产消息的效率比消费者处理消息的效率高很多,两端之间这种效率不平衡性。所以消费端需要做一些限流措施,否则可能导致消费端性能下降,服务器卡顿甚至崩溃等现象
总结
从某种意义上说,消费者的限流策略有助于那么处理消息效率高的消费者多消费一些消息,效率低一些的消费者少推送一些消息,从而可以达到能者多劳的目的,尽可能发挥消费者处理消息的能力。在项目中,为了缓解生产者和消费者两边效率不平衡的影响,通常会对消费者进行限流处理,保证消费者端正常消费消息,尽可能避免服务器崩溃以及宕机现象。
直接上代码:
//简单模式step:3.简单模式下消费者代码
func (r *RabbitMQ) ConsumeSimple() {
//申请队列和生产消息当中是一样一样滴 直接复制即可
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
//队列名称
r.QueueName,
//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,
//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,
//是否具有排他性
false,
//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
false,
//其他的属性,没有则直接诶传入空即可 nil
nil,
)
if err != nil {
fmt.Println(err)
}
//消费者流控 防止数据库爆库
//消息的消费需要配合Qos
r.channel.Qos(
//每次队列只消费一个消息 这个消息处理不完服务器不会发送第二个消息过来
//当前消费者一次能接受的最大消息数量
1,
0,//服务器传递的最大容量
false,//如果为true 对channel可用 false则只对当前队列可用
)
//2.接收消息
//建立了链接 就跟socket一样 一直在监听 从未被终止 这也就保证了下边的子协程当中程序的无线循环的成立
msgs,err := r.channel.Consume(
r.QueueName,//队列名称
"",//用来区分多个消费者
false,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//3.消费消息
forever := make(chan bool)
//启用协程处理消息
go func() {
//子协程不会结束 因为msgs有监听 会不断的有值进来 就算没值也在监听 就跟socket服务一样一直在监听从未被中断!
for d:=range msgs {
//实现我们要处理的逻辑函数
log.Printf("Recieved a message : %s",d.Body)
d.Ack(false)
//fmt.Println(d.Body)
}
}()
log.Printf("[*] Waiting for message,To exit press CTRL+C")
//最后我们来阻塞一下 这样主程序就不会死掉
<-forever
}

持久化
RabbitMQ生产端消息确认
Tx事务模式
从AMQP协议层面上来的事务模式;
channel.TxSelect(); 开启一个事务
channel.TxCommit();提交事务
channel.TxRollback(); //事务回滚
Confirm模式
channel.ConfirmSelect();开启确认模式
消息发送以后,提供一个回执方法WaitForConfirms(); 返回一个bool 值;
- 条消息确认: channel.waitForConfirms()
- 批量消息确认: channel.waitForConfirmsOrDie()批量确认模式
- 异步监听消息确认:channel.addConfirmListener()
简单队列的持久化
package rbtmqcs
//rabbitmq的核心文件 包含了链接conn channle 生产消费数据的方法 相当于公共类文件
import (
"fmt"
"github.com/streadway/amqp"
"log"
"time"
)
//url 格式 amqp://账号:密码@rabbitmq服务器地址:端口号/Virtual Host
//格式在golang语言当中是固定不变的
const MQURL = "amqp://dada:[email protected]:5672/aka"
type RabbitMQ struct {
conn *amqp.Connection //需要引入amqp包 连接amqp.Dial()
channel *amqp.Channel
//队列名称
QueueName string
//交换机
Exchange string
//key
Key string
//链接信息
Mqurl string
}
//创建RabbitMQ结构体实例
func NewRabbitMQ(queuename string,exchange string,key string) *RabbitMQ {
rabbitmq := &RabbitMQ{QueueName:queuename,Exchange:exchange,Key:key,Mqurl:MQURL}
var err error
//创建rabbitmq连接
rabbitmq.conn,err = amqp.Dial(rabbitmq.Mqurl) //通过amqp.Dial()方法去链接rabbitmq服务端
rabbitmq.failOnErr(err,"创建连接错误!") //调用我们自定义的failOnErr()方法去处理异常错误信息
rabbitmq.channel,err = rabbitmq.conn.Channel() //链接上rabbitmq之后通过rabbitmq.conn.Channel()去设置channel信道
//交换机持久化
err = rabbitmq.channel.ExchangeDeclare("rbtmq","topic",true,true,false,false,nil)
rabbitmq.failOnErr(err,"获取channel失败!")
return rabbitmq
}
//断开channel和connection
//为什么要断开channel和connection 因为如果不断开他会始终使用和占用我们的channel和connection 断开是为了避免资源浪费
func (r *RabbitMQ) Destory() {
r.channel.Close() //关闭信道资源
r.conn.Close() //关闭链接资源
}
//错误处理函数
func (r *RabbitMQ) failOnErr(err error,message string) {
if err != nil {
log.Fatalf("%s:%s",message,err)
panic(fmt.Sprintf("%s:%s",message,err))
}
}
//简单模式step:1.创建简单模式下的rabbitmq实例
func NewRabbitMQSimple(queueName string) *RabbitMQ {
//simple模式下交换机为空因为会默认使用rabbitmq默认的default交换机而不是真的没有 bindkey绑定建key也是为空的
//特别注意:simple模式是最简单的rabbitmq的一种模式 他只需要传递queue队列名称过去即可 像exchange交换机会默认使用default交换机 绑定建key的会不必要传
return NewRabbitMQ(queueName,"","")
}
//简单模式step:2.简单模式下生产代码
func (r *RabbitMQ) PublishSimple(message string) {
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
r.QueueName,
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false (队列持久化)
false,//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,//是否具有排他性
false,//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
nil,//其他的属性,没有则直接诶传入空即可 nil
)
if err != nil {
fmt.Println(err)
}
//2.发送消息到队列当中
r.channel.Publish(
//交换机 simple模式下默认为空 我们在上边已经赋值为空了 虽然为空 但其实也是在用的rabbitmq当中的default交换机运行
r.Exchange,
//队列的名称
r.QueueName,
//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,
//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
false,
//要发送的消息
amqp.Publishing{
//消息内容持久化 这个很重要 (队列里消息持久化)
DeliveryMode:amqp.Persistent,
ContentType:"text/plain",
Body:[]byte(message),
})
}
//简单模式step:3.简单模式下消费者代码
func (r *RabbitMQ) ConsumeSimple() {
//申请队列和生产消息当中是一样一样滴 直接复制即可
//1.申请队列,如果队列不存在,则会自动创建,如果队列存在则跳过创建直接使用 这样的好处保障队列存在,消息能发送到队列当中
_,err := r.channel.QueueDeclare(
r.QueueName,//队列名称
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false (队列里消息持久化)
false,//是否为自动删除 意思是最后一个消费者断开链接以后是否将消息从队列当中删除 默认设置为false不自动删除
false,//是否具有排他性
false,//是否阻塞 发送消息以后是否要等待消费者的响应 消费了下一个才进来 就跟golang里面的无缓冲channle一个道理 默认为非阻塞即可设置为false
nil,//其他的属性,没有则直接诶传入空即可 nil
)
if err != nil {
fmt.Println(err)
}
//消费者流控 防止数据库爆库
//消息的消费需要配合Qos
r.channel.Qos(
//每次队列只消费一个消息 这个消息处理不完服务器不会发送第二个消息过来
//当前消费者一次能接受的最大消息数量
1,
0,//服务器传递的最大容量
false,//如果为true 对channel可用 false则只对当前队列可用
)
//2.接收消息
//建立了链接 就跟socket一样 一直在监听 从未被终止 这也就保证了下边的子协程当中程序的无线循环的成立
msgs,err := r.channel.Consume(
r.QueueName,//队列名称
"",//用来区分多个消费者
false,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//3.消费消息
forever := make(chan bool)
//启用协程处理消息
go func() {
//子协程不会结束 因为msgs有监听 会不断的有值进来 就算没值也在监听 就跟socket服务一样一直在监听从未被中断!
for d:=range msgs {
//实现我们要处理的逻辑函数
log.Printf("Recieved a message : %s",d.Body)
d.Ack(false)
//fmt.Println(d.Body)
}
}()
log.Printf("[*] Waiting for message,To exit press CTRL+C")
//最后我们来阻塞一下 这样主程序就不会死掉
<-forever
}
//Publish订阅模式step1:创建rabbitmq实例
func NewRabbitMQPubSub(exchangeName string) *RabbitMQ {
//创建RabbitMQ实例
return NewRabbitMQ("",exchangeName,"")
}
//订阅模式step2:生产者
func (r *RabbitMQ) PublishPub(message string) {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//直接false即可 也不知道干啥滴
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
"",
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//订阅模式step3:消费者
func (r *RabbitMQ) RecieveSub() {
//这一步和 订阅模式step2:生产者 里面的代码是一样一样滴
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"fanout",//广播类型 订阅模式下我们需要将类型设置为广播类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写
q,err := r.channel.QueueDeclare(
//随机生产队列名称 这个地方一定要留空
"",
false,
false,
true,//具有排他性 即队列只为当前链接服务 链接断开 队列被删除 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,
//在pub/sub模式下,这里的key要为空
"",
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
r.QueueName,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//路由模式step1:创建RabbitMQ实例
func NewRabbitMQRouting(exchangeName string,routingKey string) *RabbitMQ {
return NewRabbitMQ("",exchangeName,routingKey)
}
//路由模式step2:发送消息
func (r *RabbitMQ) PublishRouting(message string) {
//1.尝试创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct这个和在订阅模式下是不一样的
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
r.Key,//除了设置交换机这也要设置绑定的key值
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//路由模式step3:消费者
func (r *RabbitMQ) RecieveRouting() {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//路由模式step3:消费者
func (r *RabbitMQ) RecieveRoutingSleep() {
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"direct",//类型 路由模式下我们需要将类型设置为direct类型
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 false表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
fmt.Println("绑定队列到exchange中")
time.Sleep(20 * time.Second)//Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
fmt.Println("接收队列消息,开始消费")
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
true,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}
//topic主题模式step1:创建RabbitMQ实例
func NewRabbitMQTopic(exchange string,routingkey string) *RabbitMQ {
//创建RabbitMQ实例
return NewRabbitMQ("",exchange,routingkey)
}
//topic主题模式step2:发送消息
func (r *RabbitMQ) PublishTopic(message string){
//1.尝试创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"topic",//类型 topic主题模式下我们需要将类型设置为topic
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除 这里解释的会更加清楚:https://blog.csdn.net/weixin_30646315/article/details/96224842?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.发送消息
err = r.channel.Publish(
r.Exchange,
r.Key,//除了设置交换机这也要设置绑定的key值
false,//如果为true 会根据exchange类型和routkey规则,如果无法找到符合条件的队列那么会把发送的消息返还给发送者
false,//如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(message),//发送的内容一定要转换成字节的形式
})
}
//topic主题模式step2:消费者
//要注意key 规则
//其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
//匹配 huxiaobai.* 表示匹配 huxiaobai.hello 但是huxiaobai.one.two 需要用huxiaobai.# 才能匹配到
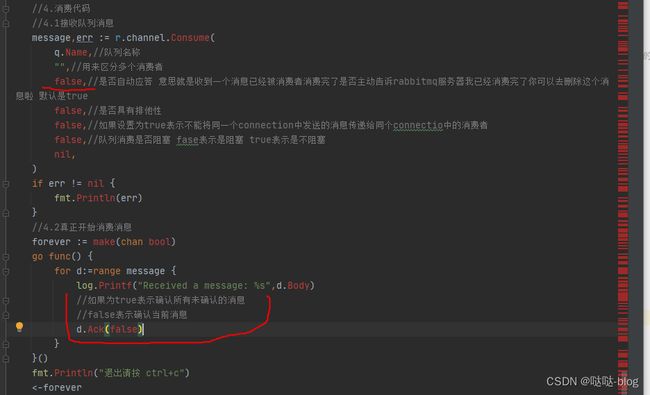
func (r *RabbitMQ) RecieveTopic(){
//1.尝试创建交换机exchange 如果交换机存在就不用管他,如果不存在则会创建交换机
err := r.channel.ExchangeDeclare(
r.Exchange,//交换机名称
"topic",//类型 topic主题模式下我们需要将类型设置为topic
true,//进入的消息是否持久化 进入队列如果不消费那么消息就在队列里面 如果重启服务器那么这个消息就没啦 通常设置为false
false,//是否为自动删除
false,//true表示这个exchange不可以被客户端用来推送消息,仅仅是用来进行exchange和exchange之间的绑定
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
r.failOnErr(err,"Failed to declare an excha " + "nge")
//2.试探性创建队列,这里注意队列名称不要写哦
q,err := r.channel.QueueDeclare(
"",//随机生产队列名称 这个地方一定要留空
false,
false,
true,//具有排他性 排他性的理解 这篇文章还是比较好的:https://www.jianshu.com/p/94d6d5d98c3d
false,
nil,
)
r.failOnErr(err,"Failed to declare a queue")
//3.绑定队列到exchange中去
err = r.channel.QueueBind(
q.Name,//队列的名称 通过key去找绑定好的队列
r.Key,//在路由模式下,这里的key要填写
r.Exchange,
false,
nil,
)
//4.消费代码
//4.1接收队列消息
message,err := r.channel.Consume(
q.Name,//队列名称
"",//用来区分多个消费者
false,//是否自动应答 意思就是收到一个消息已经被消费者消费完了是否主动告诉rabbitmq服务器我已经消费完了你可以去删除这个消息啦 默认是true
false,//是否具有排他性
false,//如果设置为true表示不能将同一个connection中发送的消息传递给同个connectio中的消费者
false,//队列消费是否阻塞 fase表示是阻塞 true表示是不阻塞
nil,
)
if err != nil {
fmt.Println(err)
}
//4.2真正开始消费消息
forever := make(chan bool)
go func() {
for d:=range message {
log.Printf("Received a message: %s",d.Body)
//如果为true表示确认所有未确认的消息
//false表示确认当前消息
d.Ack(false)
}
}()
fmt.Println("退出请按 ctrl+c")
<-forever
}