对鸢尾花数据集使用随机森林分类模型,输出评价指标
一、鸢尾花数据集
鸢尾花数据集是机器学习和数据挖掘中常用的数据集之一, 该数据集共包含150个样本,其中每个样本代表了一朵鸢尾花,分别属于三个不同的品种:Setosa、Versicolor 和 Virginica。 对于每个样本,都测量了四个特征: 萼片长度(Sepal Length)萼片宽度(Sepal Width) 花瓣长度(Petal Length) 花瓣宽度(Petal Width) 这些特征是以厘米为单位测量的。使用这些特征,任务是在新样本中准确地预测鸢尾花所属的品种。 鸢尾花数据集是一个经典的分类问题,被广泛用于机器学习中的训练和测试,同时也是许多分类算法的实用案例(本例使用随机森林进行分类对7种评价指标进行输出展示)。
二、分类模型的评价指标
分类问题的评价指标通常包括以下几种:
1. 准确率(Accuracy):分类正确的样本数占总样本数的比例。
2. 精确率(Precision):真正例(True Positive)占所有被预测为正例(Positive)的样本数的比例。
3. 召回率(Recall):真正例占所有真实为正例的样本数的比例。
4. F1 Score(F1得分):精确率和召回率的调和平均数。F1得分越高,代表综合评价表现越好。
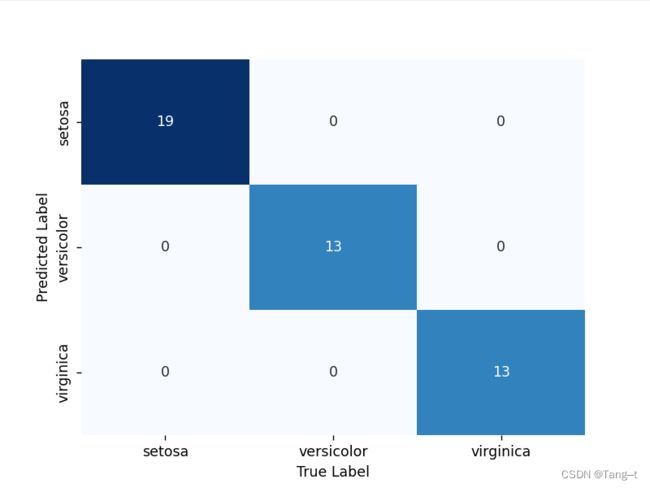
5. 混淆矩阵(Confusion Matrix):展示真实类别和预测类别之间的对应情况,是评价分类模型的基础。
6. ROC曲线(ROC Curve):绘制真正例率(TPR)和假正例率(FPR)之间的关系图。通常用来衡量模型在不同阈值下的分类效果。
7. AUC(Area Under Curve):ROC曲线下方的面积值,接近1的模型性能更好。如果在0.5或附加是最坏的情况,相当于随机分类,没有意义。如果是非常接近于0,相当于正类和负类预测反了,只需把结果反过来分类效果也是好的。
不同的指标适用于不同的情况,应该根据具体的分类问题选择对应的评价指标,并综合考虑多个指标综合评价模型性能。
三、代码实现
1代码
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_curve, auc
# 加载数据集
iris_dataset = load_iris()
# 将数据转换成数据框
iris_df = pd.DataFrame(data=iris_dataset.data, columns=iris_dataset.feature_names)
# 添加目标变量列
iris_df['species'] = iris_dataset.target_names[iris_dataset.target]
# 查看目标变量有那几类
l = np.unique(iris_df['species'])
# 将目标变量的类别改写成从0开始
iris_df['species']=iris_df['species'].map({'setosa':0,'versicolor':1,'virginica':2})
X = iris_df.iloc[:, :-1].values # 获取样本特征(除最后一列)
y = iris_df.iloc[:, -1].values.ravel() # 获取样本结果标签(取最后一列)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 建立随机森林模型
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# 在测试集上预测结果
y_pred = clf.predict(X_test)
y_score = clf.predict_proba(X_test)
# 输出评价指标
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Precision:", precision_score(y_test, y_pred, average='macro'))
print("Recall:", recall_score(y_test, y_pred, average='macro'))
print("F1 Score:", f1_score(y_test, y_pred, average='macro'))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
# 绘制混淆矩阵的热力图
cm = confusion_matrix(y_test, y_pred)
cm = pd.DataFrame(cm, index=['setosa', 'versicolor', 'virginica'], columns=['setosa', 'versicolor', 'virginica'])
ax = sns.heatmap(cm, annot=True, cmap='Blues', cbar=False)
ax.set_xlabel('True Label')
ax.set_ylabel('Predicted Label')
plt.show()
# 计算 ROC 曲线和 AUC 值
fpr = dict()
tpr = dict()
roc_auc = dict()
n = len(l)
for i in range(n):
fpr[i], tpr[i], _ = roc_curve((y_test == i).astype('int'), y_score[:,i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制 ROC 曲线
plt.figure()
lw = 2
for i in range(n):
plt.plot(fpr[i], tpr[i], lw=lw,
label='ROC curve of class {0} (AUC = {1:0.2f})'.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], linestyle='--', lw=lw, color='k',
label='Luck')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
# 打印 AUC 值
print("AUC (area under ROC curve):")
for i in range(n):
print("\tClass {}: {:0.2f}".format(i, roc_auc[i]))
2输出结果
Accuracy: 1.0
Precision: 1.0
Recall: 1.0
F1 Score: 1.0
Confusion Matrix:
[[19 0 0]
[ 0 13 0]
[ 0 0 13]]
AUC (area under ROC curve):
Class 0: 1.00
Class 1: 1.00
Class 2: 1.00混淆矩阵热力图
ROC曲线
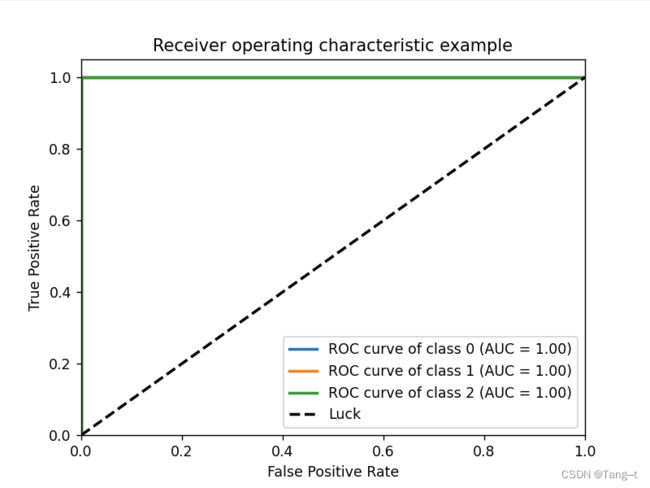 可以看到模型分类效果各种指标的准确率都达到百分百,这里需要看看是不是存在过拟合,本例主要是对分类指标的展示,并未做过多处理。
可以看到模型分类效果各种指标的准确率都达到百分百,这里需要看看是不是存在过拟合,本例主要是对分类指标的展示,并未做过多处理。