【论文阅读】DISTDET:一种高性价比的分布式网络威胁检测系统(USENIX-2023)
【USENIX-2023】DISTDET: A Cost-Effective Distributed Cyber Threat Detection System
摘要
基于溯源图的攻击检测存在两个基本限制
- 现有方法采用集中式检测体系结构,将所有系统审计日志发送到服务器进行处理,导致数据传输、数据存储和计算的成本难以承受。
- 要么采用无法检测未知威胁的基于规则的技术,要么采用产生大量假警报的异常检测技术,无法在APT检测中实现精度和召回率的平衡。
(召回率:样本中被正确预测的正例与样本总量之比)
因此提出DISTDET:一个分布式检测系统,通过以下方式检测APT攻击:
- 基于客户端构建的主机模型执行轻量级检测
- 基于告警属性的语义过滤虚假警报
- 推导全局模型以补充主机模型的局部偏差
1. 引言
APT攻击相关背景知识不再赘述
摘要提到,基于规则和基于异常的检测无法平衡精度和召回率,主要体现为:
- 基于规则的方法通常依赖通用模式来提高召回率,但可能将良性行为错误地识别为威胁。同时,该方法受到专家知识的严重限制,无法检测未知威胁。
- 基于异常检测的方法能够检测未知威胁,但会产生大量假阳性,且面临警报疲劳问题。
DISTDET协同结合了分布式计算、异常检测和虚警过滤技术,用于检测和调查网络攻击APT攻击,采用了一种新颖的分布式检测架构,将APT检测的一部分转移到客户端,只向服务器发送代表潜在攻击的摘要图,从而最大限度地降低了整体计算成本,大大降低了数据传输和存储的成本。此外,DISTDET协同结合异常检测和虚警过滤,以检测未知威胁(提高召回率)和对抗报警疲劳(提高精度)。通过这些技术的新颖协同作用,DISTDET做到了:
- 以低成本实现了检测APT攻击的高精度
- 比仅报告可疑事件的现有检测工具提供更多上下文信息(摘要图)
- 通过客户端缓存无缝支持基于来源图的分析
1.1. 三个挑战和解决方案
(1)如何确保APT检测所产生的开销不会影响客户的日常业务表现?
虽然无法进行计算密集型的APT检测,但客户端可以根据观察到的正常行为建立一个紧凑而富有表达性的索引进行轻量级检测,并根据索引识别不可见的行为作为告警,服务器端可以对客户端发送的告警进行更昂贵的分析,进一步过滤假警报。这样,客户端不仅可以最大限度地减少计算成本,而且还消除了上传所有观测日志的需求。
基于主机的异常检测:
DISTDET包括分层系统事件树(HST)和告警汇总图(ASG) 的新颖设计。对于每个客户机,DISTDET首先基于学习期间收集的日志构建一个HST作为主机模型。HST是一个紧凑的索引,它使用多层树根据审计事件的属性对其进行分类,基于创建的HST模型,DISTDET将偏离模型的事件作为告警进行检测,对于每条告警生成一条ASG,并将ASG发送给服务器。
ASG是一个汇总图,包括告警中可疑行为的发起进程p,以及p的祖先进程和后代进程发起的事件。由于ASG的大小与原始来源图相比显著减小,因此大大降低了成本。
(2)如何处理DISTDET异常检测中臭名昭著的报警疲劳?
大多数虚警是由罕见的良性行为引起的,在学习期间没有观察到,因此模型无法学习到。通过对大量误报的仔细检查,我们发现误报通常具有一些独特的性质:
- 代表相同行为的报警会在一段时间内重复报告
- 许多误报与语义相似的命令触发的良性行为有关
- 这些警报的上下文通常被认为代表良性行为
虚警过滤:
DISTDET使用三个步骤来克服臭名昭著的警报疲劳问题:警报重复数据删除、语义警报聚合和基于上下文事件的警报排名。DISTDET基于虚假报警的唯一属性,在客户端根据主机模型剔除具有相同属性的报警,从而过滤掉由重复良性行为触发的重复报警。然后在服务器端,DISTDET首先应用计算量更大的算法来聚合属性表现出相似语义的告警。接下来,DISTDET提供了一种新颖的ASG排序算法,通过考虑其上下文事件(即ASG中的祖先进程和后代进程)是否被视为异常以及这些上下文事件在ASG中是否罕见来对告警进行优先级排序。
(3)分布式系统如何克服局部偏差,达到与集中式体系结构相似的检测效果?
由于分布式系统不会将所有事件日志都传输到服务器进行集中分析,因此每台主机在本地建立的模型缺乏全局信息,可能会影响检测效果。而在服务器中构建的全局模型可以观察到各个阶段的行为,并补充局部模型中缺失的观察结果。
全局模型推导:
为了补充在学习期间观察到的缺失行为,DISTDET通过合并客户端定期发送的HST来派生一个全局模型。因此,提供相同类型服务的每个主机将拥有服务行为的全局视图,解决模型中的局部偏差,并实现与集中式体系结构类似的有效性。
2. 系统详细设计
2.1. 基于主机的检测
该组件有两种模式:训练模式和检测模式。在训练模式中,它从每个客户机的系统事件流中训练一个主机模型。检测模式是将偏离模型的事件以告警的形式检测出来,并根据告警产生asg。
训练阶段:
HST模型由四层节点组成:事件类型、操作、过程和属性,其中每一层都关注事件的一组特定属性。事件类型层有三个子模型:进程、文件和网络。对于evt的事件类型t, DISTDET使用事件类型与t匹配的子模型来查找操作层中的节点。然后DISTDET根据evt的操作类型(例如流程事件的启动和退出操作)在操作层中查找或创建节点。之后,DISTDET继续根据启动事件evt的流程在流程层中查找或创建节点。最后,DISTDET在属性层中构建节点,以基于evt的事件类型表示evt的其他属性。例如,流程事件主要使用其命令行属性表示,包括命令选项和参数。同时,DISTDET对每个属性节点执行按需标记化,以提高节点表示的泛化性。例如,某些文件路径,如 / t m p / p r c . 280002378 / /tmp/prc.280002378 / /tmp/prc.280002378/和 / t m p / p r c . 280002379 / / tmp /prc.280002379/ /tmp/prc.280002379/共享相同的前缀 / t m p / p r c /tmp/prc /tmp/prc。因此,通过标记数字字符串,DISTDET可以使用一个节点 / t m p / p r c . x x x / /tmp/prc.xxx/ /tmp/prc.xxx/表示这两个文件路径,并记录其频率,这将被后续的ASG排名使用。
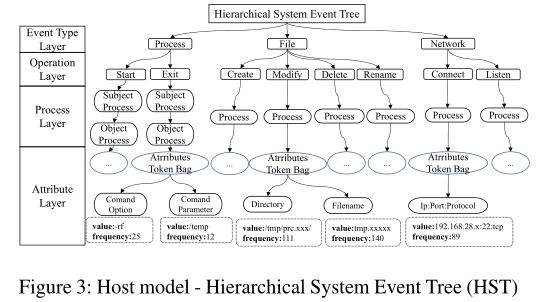
检测阶段:
给定一个系统事件evt , DISTDET搜索HST以查找是否存在与evt 属性匹配的节点。如果未找到,evt '将作为警报报告。也就是说,任何在学习期间没有观察到的事件都被认为是异常。值得注意的是,该方案是优先误报避免漏报的。
ASG生成:
对于告警,DISTDET生成包含异常事件及其上下文事件的ASG。进程生成子进程以共同完成某些系统任务,如文件压缩和web下载。为了捕获此类关键信息,对于警报事件evt中的主题进程p(称为警报进程),DISTDET首先构建p的进程谱系树,并在X代中识别其祖先,在Y代中识别后代。然后DISTDET包含这些已识别节点(即其发起的事件)的每种类型(进程、文件和网络)的前N个出边,以形成一个ASG。
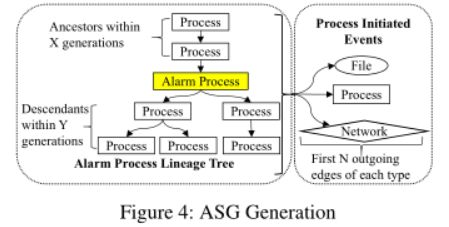
2.2. 虚警过滤
该组件主要通过三个步骤来实现虚警过滤。
(1)重复警报删除
告警重复删除是基于相当多的假告警代表了相同的行为。比如,计划外升级操作会在短时间内重复添加、删除大量文件,造成一系列误报。为了消除此类重复告警,DISTDET为每个告警a维护了一个时间窗口,后续所有与a事件相同的告警将被丢弃。在一个时间窗口结束时,重复的告警事件的频率也会被记录在a的ASG上,这样,突然激增的重复告警只会产生有限的影响。
(2)ASG语义聚合
除了对同一行为的重复报警外,我们还观察到大量的假报警与执行的相似命令有关,只是一些参数或操作对象有所不同。因此,DISTDET聚合语义上相似的告警,以进一步减少报告的告警。具体来说,这个过程包括三个步骤:
- 通过标记命令中的单词来构造命令的语法树。
- 计算两个命令树之间的相似度。两棵树的相似性是通过它们有多少个共同的子片段来衡量的。如果两个命令的相似度超过阈值τs,我们就认为它们是相似的。
- 对具有相似告警事件的ASG进行聚合,并记录聚合ASG的频率。这样可以进一步降低产生的告警asg的冗余度。
简单来说,就是将差异小的ASG合并掉,然后记录频次,既去掉了冗余,又可以通过频次一定程度上衡量警报的威胁性。

(3)ASG排名
前面老提到记录频次,那么这些为了在去掉冗余的同时尽可能保留威胁信息而记录的频次到底怎么用呢?虚警过滤的最后一步是通过考虑告警的稀缺性(频率)以及其上下文事件(即ASG中的祖先进程和后代进程)是否也异常来确定告警的优先级。
对于一个ASG,组成该ASG的事件分为正常事件和告警事件两种。对于告警事件,事件频率是指告警重复删除过程中记录的重复次数。假设一个ASG上有x条告警事件和y条正常事件。对于告警事件,由于告警事件对ASG的异常贡献较大,故异常评分的计算方法如下:
A S ( e v t a ) = ∑ i = 1 x 1 f r e q ( e v t i a ) x AS(evt^a)=\dfrac{\sum_{i=1}^x\frac{1}{freq(evt_i^a)}}{x} AS(evta)=x∑i=1xfreq(evtia)1
对于正常事件,异常评分的计算方法如下: A S ( e v t ) = ∑ j = 1 y e v t j y , e v t j = { 1 f r e q ( e v t j ) < f r e q a v e 0 otherwise AS(ev t)=\dfrac{\sum_{j=1}^y e v t_j}{y},e v t_j=\begin{cases}1&freq(ev t_j)
即当正常事件的频次小于平均水平,则对一个ASG的异常产生贡献。
最终的异常分数计算方法如下: A S ( A S G ) = α A S ( e v t a ) + ( 1 − α ) A S ( e v t ) , α = { 1 − α f x = 1 α f x > 1 A S(A S G)=\alpha A S(e v t^{a})+(1-\alpha)A S(e v t),\alpha={\begin{cases}{1-\alpha_{f}}&{x=1}\\ {\alpha_{f}}&{x>1}\end{cases}} AS(ASG)=αAS(evta)+(1−α)AS(evt),α={1−αfαfx=1x>1 其中 α f α_f αf是权重,根据告警事件的数量有不同的值。当 x = 1 x = 1 x=1时,异常得分主要是利用正常事件获得的;当 x < 1 x<1 x<1时,认为告警事件对整体异常更重要。请注意,对于短时间内发生次数较多的攻击(例如勒索软件和野蛮暴力),我们通过检查可疑行为的频率(例如1秒内100次)来处理,而不依赖于异常分数。
我们对所有的asg进行排序,并计算一个截止阈值来区分假警报和真实的攻击事件。如果ASG的异常评分大于 τ d τ_d τd,则为真告警,否则为假告警。该阈值与当前企业配置有关,如主机数量、系统监控事件等。
2.3. 全局模型推导
在服务器中构建的全局模型可以补充在每个客户端中构建的主机模型,特别是对于提供相同类型服务的客户端,如web服务器或数据库服务器。例如,假设一个mongodb集群包含2个主机 h a h_a ha和 h b h_b hb,它们提供存储服务,并且它们都有相同的每周计划任务集。在训练期间, h a h_a ha在其宿主模型中捕获这些任务,但 h b h_b hb错过了这些任务,因为它们恰好安排在训练期间之外。DISTDET通过从 h a h_a ha和 h b h_b hb派生一个全局模型并分发全局模型以更新 h a h_a ha和 h b h_b hb中的主机模型来解决这种局部偏差。
主要包含以下三个步骤:
(1)DISTDET从每个主机模型中提取特定于服务的进程列表
主机模型中的流程节点分为两类,即系统流程和特定于服务的流程。系统进程随操作系统安装而来,所有操作系统类型相同的主机的系统进程都是相同的,例如Linux的 / i n i t /init /init、 / u s r / b i n /usr/bin /usr/bin。相反,特定于服务的进程是软件应用程序的进程,这些进程的组合可以指示主机提供的服务类型。我们通过汇总不同操作系统的系统进程,得到了系统进程列表。因此,每个模型都可以通过排除系统流程来获得特定于服务的流程列表。
(2)对于主机中提取的特定于服务的进程
DISTDET计算提取的进程名的字嵌入,例如 < p 1 , p 2 , … , p 10 > < p1, p2,…,p10 > <p1,p2,…,p10>。DISTDET使用word2vec(一种流行的预训练词嵌入模型)来计算每个主机的进程名嵌入。
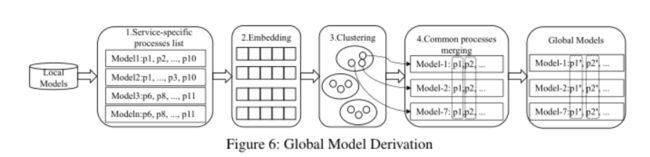
(3)基于模型的嵌入向量使用k-means算法对模型进行聚类
这样可以将提供相同类型服务的主机划分到同一个集群中。k的值是根据当前的企业设置设置的。
(4)合并同一集群中公共进程的行为。
如图6所示,模型-1、模型-2和模型-7在同一个集群中,它们共享共同的进程 p 1 p_1 p1和 p 2 p_2 p2。DISTDET将这三个模型中 p 1 p_1 p1和 p 2 p_2 p2的行为进行合并,得到 p 1 ′ p^{'}_1 p1′和 p 2 ′ p^{'}_2 p2′,然后用 p 1 ′ p^{'}_1 p1′和 p 2 ′ p^{'}_2 p2′替换局部模型中的 p 1 p_1 p1和 p 2 p_2 p2,得到全局模型。然后将全局模型分发到每个主机,以更新主机本地模型。
实验部分就不说了。