Sentinel的简单使用
本文来说下关于sentinel是几个问题
文章目录
- 什么是Sentinel
-
- Sentinel 具有以下特征
- Sentinel主要特性
- 概念小贴士
-
- 响应时间(RT)
- 吞吐量(Throughput)
- 并发用户数
- QPS每秒查询率(Query Per Second)
- Sentinel 的简单使用之Hello World
- 使用Sentinel的方式
-
- 抛出异常的方式
- 返回布尔值的方式
- 注解的方式
- 熔断降级
- 管理控制台
-
- 客户端接入控制台
- 动态规则
-
- 拉模式
- 推模式
- 本文小结
什么是Sentinel
Sentinel是阿里开源的项目,提供了流量控制、熔断降级、系统负载保护等多个维度来保障服务之间的稳定性。2012年,Sentinel诞生于阿里巴巴,其主要目标是流量控制。2013-2017年,Sentinel迅速发展,并成为阿里巴巴所有微服务的基本组成部分。 它已在6000多个应用程序中使用,涵盖了几乎所有核心电子商务场景。2018年,Sentinel演变为一个开源项目。2020年,Sentinel Golang发布。
官网:https://github.com/alibaba/sentinel/wiki/%E4%B8%BB%E9%A1%B5

Sentinel 具有以下特征
丰富的应用场景 :Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控 :Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态 :Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入Sentinel。
完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel的生态圈
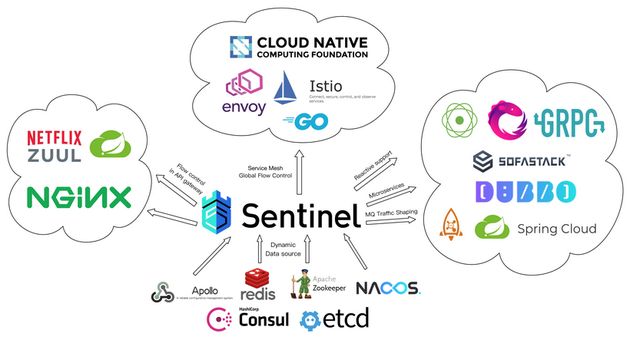
Sentinel主要特性

概念小贴士
开发的原因,需要对吞吐量(TPS)、QPS、并发数、响应时间(RT)几个概念做下了解,查自百度百科,记录如下:
响应时间(RT)
响应时间是指系统对请求作出响应的时间。直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。当然,往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。
对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的。
吞吐量(Throughput)
吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。前面已经说过,对于单用户的系统,响应时间(或者系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统,通常需要用吞吐量作为性能指标。
对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t,当有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n×t小很多(当然,在某些特殊情况下也可能比n×t大,甚至大很多)。这是因为处理每个请求需要用到很多资源,由于每个请求的处理过程中有许多不走难以并发执行,这导致在具体的一个时间点,所占资源往往并不多。也就是说在处理单个请求时,在每个时间点都可能有许多资源被闲置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应时间并不随用户数的增加而线性增加。实际上,不同系统的平均响应时间随用户数增加而增长的速度也不大相同,这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致。
并发用户数
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。一网站系统为例,假设用户只有注册后才能使用,但注册用户并不是每时每刻都在使用该网站,因此具体一个时刻只有部分注册用户同时在线,在线用户就在浏览网站时会花很多时间阅读网站上的信息,因而具体一个时刻只有部分在线用户同时向系统发出请求。这样,对于网站系统我们会有三个关于用户数的统计数字:注册用户数、在线用户数和同时发请求用户数。由于注册用户可能长时间不登陆网站,使用注册用户数作为性能指标会造成很大的误差。而在线用户数和同事发请求用户数都可以作为性能指标。相比而言,以在线用户作为性能指标更直观些,而以同时发请求用户数作为性能指标更准确些。
QPS每秒查询率(Query Per Second)
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 (看来是类似于TPS,只是应用于特定场景的吞吐量)。
Sentinel 的简单使用之Hello World
Sentinel 的使用可以分为两个部分:
- 控制台(Dashboard):控制台主要负责管理推送规则、监控、集群限流分配管理、机器发现等。
- 核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 7 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
一般要学一种没接触过的技术框架,肯定要先做个Hello World熟悉一下。
引入Maven依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-coreartifactId>
<version>1.8.1version>
dependency>
需要提醒一下,Sentinel仅支持JDK 1.8或者以上的版本
定义规则
通过定义规则来控制该资源每秒允许通过的请求次数,例如下面的代码定义了资源 HelloWorld 每秒最多只能通过 20 个请求。
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
编写Hello World代码
其实代码编写很简单,首先需要定义一个资源entry,然后用SphU.entry(“HelloWorld”)和entry.exit()把需要流量控制的代码包围起来。代码如下:
public static void main(String[] args) throws Exception {
initFlowRules();
while (true) {
Entry entry = null;
try {
entry = SphU.entry("HelloWorld");
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
System.out.println("block!");
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
}
运行结果如下:

我们根据目录查看日志,文件名格式为${appName}-metrics.log.xxx:
|--timestamp-|------date time----|-resource-|p |block|s |e|rt
1616607101000|2021-03-25 01:31:41|HelloWorld|20|11373|20|0|1|0|0|0
1616607102000|2021-03-25 01:31:42|HelloWorld|20|24236|20|0|0|0|0|0
p 代表通过的请求。
block 代表被阻止的请求。
s 代表成功执行完成的请求个数。
e 代表用户自定义的异常。
rt 代表平均响应时长。
使用Sentinel的方式
下面结合实际案例,写一个Controller接口进行示范练习。
@RestController
@RequestMapping("/user")
public class UserController {
@Resource
private UserService userService;
@RequestMapping("/list")
public List<User> getUserList() {
return userService.getList();
}
}
@Service
public class UserServiceImpl implements UserService {
//模拟查询数据库数据,返回结果
@Override
public List<User> getList() {
List<User> userList = new ArrayList<>();
userList.add(new User("1", "周慧敏", 18));
userList.add(new User("2", "关之琳", 20));
userList.add(new User("3", "王祖贤", 21));
return userList;
}
}
假设我们要让这个查询接口限流,怎么做呢?
抛出异常的方式
SphU 包含了 try-catch 风格的 API。用这种方式,当资源发生了限流之后会抛出 BlockException。这个时候可以捕捉异常,进行限流之后的逻辑处理。
@RestController
@RequestMapping("/user")
public class UserController {
//资源名称
public static final String RESOURCE_NAME = "userList";
@Resource
private UserService userService;
@RequestMapping("/list")
public List<User> getUserList() {
List<User> userList = null;
Entry entry = null;
try {
// 被保护的业务逻辑
entry = SphU.entry(RESOURCE_NAME);
userList = userService.getList();
} catch (BlockException e) {
// 资源访问阻止,被限流或被降级
return Collections.singletonList(new User("xxx", "资源访问被限流", 0));
} catch (Exception e) {
// 若需要配置降级规则,需要通过这种方式记录业务异常
Tracer.traceEntry(e, entry);
} finally {
// 务必保证 exit,务必保证每个 entry 与 exit 配对
if (entry != null) {
entry.exit();
}
}
return userList;
}
}
实际上还没写完,还要定义限流的规则。
@SpringBootApplication
public class SpringmvcApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(SpringmvcApplication.class, args);
//初始化限流规则
initFlowQpsRule();
}
//定义了每秒最多接收2个请求
private static void initFlowQpsRule() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule(UserController.RESOURCE_NAME);
// set limit qps to 2
rule.setCount(2);
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setLimitApp("default");
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
然后启动项目,测试。快速刷新几次,我们就看到触发限流的逻辑了。

返回布尔值的方式
抛出异常的方式是当被限流时以抛出异常的形式感知,我们通过捕获异常进行限流的处理,这种方式跟上面不同的在于不抛出异常,而是返回一个布尔值,我们通过判断布尔值来进行限流逻辑的处理。这样我们就可以很容易写出if-else结构的代码。
public static final String RESOURCE_NAME_QUERY_USER_BY_ID = "queryUserById";
@RequestMapping("/get/{id}")
public String queryUserById(@PathVariable("id") String id) {
if (SphO.entry(RESOURCE_NAME_QUERY_USER_BY_ID)) {
try {
//被保护的逻辑
//模拟数据库查询数据
return JSONObject.toJSONString(new User(id, "Tom", 25));
} finally {
//关闭资源
SphO.exit();
}
} else {
//资源访问阻止,被限流或被降级
return "Resource is Block!!!";
}
}
添加规则的代码跟前面的例子一样,我就不写了,然后启动项目,测试。

注解的方式
看了上面两种方式,肯定有人会说,代码侵入性太强了,如果原来旧的系统要接入的话,要改原来的代码。众所周知,旧代码是不能动的,否则后果很严重。
那么注解的方式就很好地解决了这个问题。注解式怎么写呢?
@Service
public class UserServiceImpl implements UserService {
//资源名称
public static final String RESOURCE_NAME_QUERY_USER_BY_NAME = "queryUserByUserName";
//value是资源名称,是必填项。blockHandler填限流处理的方法名称
@Override
@SentinelResource(value = RESOURCE_NAME_QUERY_USER_BY_NAME, blockHandler = "queryUserByUserNameBlock")
public User queryByUserName(String userName) {
return new User("0", userName, 18);
}
//注意细节,一定要跟原函数的返回值和形参一致,并且形参最后要加个BlockException参数
//否则会报错,FlowException: null
public User queryUserByUserNameBlock(String userName, BlockException ex) {
//打印异常
ex.printStackTrace();
return new User("xxx", "用户名称:{" + userName + "},资源访问被限流", 0);
}
}
写完这个核心代码后,还要加个配置,否则不生效。
引入sentinel-annotation-aspectj的Maven依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-annotation-aspectjartifactId>
<version>1.8.1version>
dependency>
然后将SentinelResourceAspect注册为一个Bean
@Configuration
public class SentinelAspectConfiguration {
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}
别忘了添加规则,可以参考第一个例子,这里就不写了。
最后启动项目,测试,刷新多几次接口后,出发限流,可以看到以下结果。

熔断降级
除了可以对接口进行限流之外,当接口出现异常时,Sentinel也可以提供熔断降级的功能。
在@SentinelResource注解中有一个属性fallback,当抛出非BlockException的异常时,就会进入到fallback方法中,实现熔断机制,这有点类似于Hystrix的FallBack。
我们拿上面的例子做示范,如果userName为空则抛出RuntimeException。然后我们设置fallback属性的属性值,也就是fallback的方法,返回系统异常。
@Override
@SentinelResource(value = RESOURCE_NAME_QUERY_USER_BY_NAME, blockHandler = "queryUserByUserNameBlock", fallback = "queryUserByUserNameFallBack")
public User queryByUserName(String userName) {
if (userName == null || "".equals(userName)) {
//抛出异常
throw new RuntimeException("queryByUserName() command failed, userName is null");
}
return new User("0", userName, 18);
}
public User queryUserByUserNameFallBack(String userName, Throwable ex) {
//打印日志
ex.printStackTrace();
return new User("-1", "用户名称:{" + userName + "},系统异常,请稍后重试", 0);
}
然后启动项目,故意不传userName,进行测试,可以看到走了fallback的方法逻辑。

管理控制台
上面讲完了Sentinel的基本用法,实际上重头戏在Sentinel的管理控制台,管理控制台提供了很多实用的功能。下面我们看看怎么使用。
首先下载控制台的jar包,当然你也可以通过下载源码编译得到。
//下载页面地址
https://github.com/alibaba/Sentinel/releases
然后使用以下命令启动:
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=
localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.1.jar
启动成功后,访问http://localhost:8080,默认登录的用户名和密码都是sentinel。

登录进去之后,可以看到主页面,有许多功能菜单,这里就不一一介绍了。

客户端接入控制台
那么我们自己的应用怎么接入到控制台,使用控制台对应用的流量进行监控呢,诸位客官,请继续往下看。
首先添加maven依赖,客户端需要引入 Transport 模块来与 Sentinel 控制台进行通信。
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-transport-simple-httpartifactId>
<version>1.8.1version>
dependency>
配置filter,把所有访问的 Web URL 自动统计为 Sentinel 的资源。
@Configuration
public class FilterConfig {
@Bean
public FilterRegistrationBean sentinelFilterRegistration() {
FilterRegistrationBean<Filter> registration = new FilterRegistrationBean<>();
registration.setFilter(new CommonFilter());
registration.addUrlPatterns("/*");
registration.setName("sentinelFilter");
registration.setOrder(1);
return registration;
}
}
在启动命令中加入以下配置,-Dcsp.sentinel.dashboard.server=consoleIp:port 指定控制台地址和端口,-Dcsp.sentinel.api.port=xxxx 指定客户端监控 API 的端口(默认是8019,因为控制台已经使用了8719,应用端为了防止冲突就使用8720):
-Dserver.port=8888 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dcsp.sentinel.api.port=
8720 -Dproject.name=sentinelDemo

启动项目,我们可以看到多了一个应用名称sentinelDemo,点击机器列表,查看健康状况。

请求/user/list接口,然后我们可以看到实时监控的接口的QPS情况。

这样就代表客户端接入控制台成功了!
动态规则
Sentinel 的理念是开发者只需要关注资源的定义,当资源定义成功后可以动态增加各种流控降级规则。Sentinel 提供两种方式修改规则:
- 通过 API 直接修改 (loadRules)
- 通过 DataSource 适配不同数据源修改
手动通过API定义规则,前面Hello World的例子已经写过,是一种硬编码的形式,因为不够灵活,所以肯定不能应用于生产环境。
所以要引入DataSource,规则设置可以存储在数据源中,通过更新数据源中存储的规则,推送到Sentinel规则中心,客户端就可以实时获取最新的规则,根据最新的规则进行限流、降级。
一般DataSource拓展常见的实现方式有:
- 拉模式:客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是SQL、文件等。优点是比较简单,缺点是无法及时获取变更。
- 推模式:规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用Nacos、Zookeeper 等配置中心。这种方式有更好的实时性和一致性保证,比较推荐使用这种方式。
拉模式
pull模式的数据源一般是可写入的(比如本地文件)。首先要在客户端注册数据源,将对应的读数据源注册至对应的 RuleManager;然后将写数据源注册至 transport 的 WritableDataSourceRegistry 中。
由此看出这是一个双向读写的过程,我们既可以在应用本地直接修改文件来更新规则,也可以通过 Sentinel 控制台推送规则。下图为控制台推送规则的流程图。

首先引入maven依赖。
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-datasource-extensionartifactId>
<version>1.8.1version>
dependency>
使用SPI机制进行扩展,创建一个实现类,实现InitFunc接口的init()方法。
public class FileDataSourceInit implements InitFunc {
public FileDataSourceInit() {
}
@Override
public void init() throws Exception {
String filePath = System.getProperty("user.home") + "\\sentinel\\rules\\sentinel.json";
ReadableDataSource<String, List<FlowRule>> ds = new FileRefreshableDataSource<>(
filePath, source -> JSON.parseObject(source, new TypeReference<List<FlowRule>>() {
})
);
// 将可读数据源注册至 FlowRuleManager.
FlowRuleManager.register2Property(ds.getProperty());
WritableDataSource<List<FlowRule>> wds = new FileWritableDataSource<>(filePath, this::encodeJson);
// 将可写数据源注册至 transport 模块的 WritableDataSourceRegistry 中.
// 这样收到控制台推送的规则时,Sentinel 会先更新到内存,然后将规则写入到文件中.
WritableDataSourceRegistry.registerFlowDataSource(wds);
}
private <T> String encodeJson(T t) {
return JSON.toJSONString(t);
}
}
在项目的 resources/META-INF/services 目录下创建文件,名为com.alibaba.csp.sentinel.init.InitFunc ,内容则是FileDataSourceInit的全限定名称:
io.github.yehongzhi.springmvc.config.FileDataSourceInit

接着在${home}目录下,创建\sentinel\rules目录,再创建sentinel.json文件。

然后启动项目,发送请求,当客户端接收到请求后就会触发初始化操作。初始化完成后我们到控制台,然后设置流量限流规则。

新增后,本地文件sentinel.json同时也保存了规则内容(压缩成一行的json)。
[{"clusterConfig":{"acquireRefuseStrategy":0,"clientOfflineTime":2000,"fallbackToLocalWhenFail":true,"resourceTimeout":2000,"resourceTimeoutStrategy":0,"sampleCount":10,"strategy":0,"thresholdType":0,"windowIntervalMs":1000},"clusterMode":false,"controlBehavior":0,"count":3.0,"grade":1,"limitApp":"default","maxQueueingTimeMs":500,"resource":"userList","strategy":0,"warmUpPeriodSec":10}]
我们可以通过修改文件来更新规则内容,也可以通过控制台推送规则到文件中,这就是拉模式。缺点是不保证一致性,实时性不保证,拉取过于频繁也可能会有性能问题。
推模式
刚刚说了拉模式实时性不能保证,推模式就解决了这个问题。除此之外还可以持久化,也就是数据保存在数据源中,即使重启也不会丢失之前的配置,这也解决了原始模式存在内存中不能持久化的问题。
可以和Sentinel配合使用的数据源有很多种,比如ZooKeeper,Nacos,Apollo等等。这里介绍使用Nacos的方式。
首先要启动Nacos服务器,然后登录到Nacos控制台,添加一个命名空间,添加配置。

接着我们就要改造Sentinel的源码。因为官网提供的Sentinel的jar是原始模式的,所以需要改造,所以我们需要拉取源码下来改造一下,然后自己编译jar包。
源码地址:https://github.com/alibaba/Sentinel
拉取下来之后,导入到IDEA中,然后我们可以看到以下目录结构。

首先修改sentinel-dashboard的pom.xml文件:

第二步,把test目录下的四个关于Nacos关联的类,移到rule目录下。

FlowRuleNacosProvider和FlowRuleNacosPublisher不需要怎么改造,本人不太喜欢名称后缀,所以去掉了后面的后缀。

接着NacosConfig添加Nacos的地址配置。

最关键的是FlowControllerV1的改造,这是规则配置的增删改查的一些接口。
把移动到rule目录下的两个服务,添加到FlowControllerV1类中。
@Autowired
@Qualifier("flowRuleNacosProvider")
private DynamicRuleProvider<List<FlowRuleEntity>> ruleProvider;
@Autowired
@Qualifier("flowRuleNacosPublisher")
private DynamicRulePublisher<List<FlowRuleEntity>> rulePublisher;
添加私有方法publishRules(),用于推送配置:
private void publishRules(/*@NonNull*/ String app) throws Exception {
List<FlowRuleEntity> rules = repository.findAllByApp(app);
rulePublisher.publish(app, rules);
}
修改apiQueryMachineRules()方法。

修改apiAddFlowRule()方法。

修改apiUpdateFlowRule()方法。

修改apiDeleteFlowRule()方法。

Sentinel控制台的项目就改造完成了,用于生产环境就编译成jar包运行,如果是学习可以直接在IDEA运行。
我们在前面创建的HelloWord工程的pom.xml文件加上依赖。
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-datasource-nacosartifactId>
<version>1.8.1version>
dependency>
然后在application.yml文件加上以下配置:
spring:
cloud:
sentinel:
datasource:
flow:
nacos:
server-addr: localhost:8848
namespace: 05f447bc-8a0b-4686-9c34-344d7206ea94
dataId: springmvc-sentinel-flow-rules
groupId: SENTINEL_GROUP
# 规则类型,取值见:
# org.springframework.cloud.alibaba.sentinel.datasource.RuleType
rule-type: flow
data-type: json
application:
name: springmvc-sentinel-flow-rules
以上就完成了全部的配置和改造,启动Sentinel控制台,还有Java应用。
打开Nacos控制台,我们添加限流配置如下:

配置内容如下:
[{"app":"springmvc-sentinel-flow-rules","clusterConfig":{"acquireRefuseStrategy":0,"clientOfflineTime":2000,"fallbackToLocalWhenFail":true,"resourceTimeout":2000,"resourceTimeoutStrategy":0,"sampleCount":10,"strategy":0,"thresholdType":0,"windowIntervalMs":1000},"clusterMode":false,"controlBehavior":0,"count":1.0,"grade":1,"limitApp":"default","maxQueueingTimeMs":500,"resource":"userList","strategy":0,"warmUpPeriodSec":10},{"app":"springmvc-sentinel-flow-rules","clusterConfig":{"acquireRefuseStrategy":0,"clientOfflineTime":2000,"fallbackToLocalWhenFail":true,"resourceTimeout":2000,"resourceTimeoutStrategy":0,"sampleCount":10,"strategy":0,"thresholdType":0,"windowIntervalMs":1000},"clusterMode":false,"controlBehavior":0,"count":3.0,"grade":1,"limitApp":"default","maxQueueingTimeMs":500,"resource":"queryUserByUserName","strategy":0,"warmUpPeriodSec":10}]
然后我们打开Sentinel控制台,能看到配置,证明Nacos的配置推送成功了。

我们尝试调用Java应用的接口,测试是否生效。

可以看到限流是生效的,再看看Sentinel监控的QPS情况。

从QPS监控的情况看,最高的QPS只有3,其他请求都被拒绝了,证明限流配置是实时生效的。

配置信息也被持久化到Nacos相关的配置表中。
这时候,再回头看Sentinel官网上关于推模式的架构图就比较清楚了。

本文小结
本篇文章主要介绍了Sentinel的基本用法,还有动态规则的两种方式,除此之外当然还有许多功能,这里由于篇幅问题就不一一介绍了,有兴趣的朋友可以自己探索一下。我个人觉得Sentinel是一个非常优秀的组件,比原来用的Hystrix的确有着非常大的改进,值得推荐。