ElasticSearch
ElasticSearch全文搜索引擎
- 全文搜索Lucene入门
- ElasticSearch概述和安装
- ElasticSearch的基本使用
- ElasticSearch在Java中使用
一. 全文搜索Lucene入门
1. 全文搜索概述
1.1. 什么是全文检索
在互联网中查询的信息主要包括文本,视频,图片等,这些其实都是数据。全文检索主要针对文本数据的搜索
按照数据的格式,数据可分为**"结构化"数据(关系数据库表形式管理的数据 - 方便管理和查询,还可以优化查询),“半结构化"数据(XML文档、JSON文档 - 内容和结构融合在一起,查询不是很方便),和"非结构化”**数据(WORD、PDF等 - 存储和查询成本比较高)。通常而言在结构化的数据中搜索性能是比较高的,全文搜索就是把非结构化的数据变成有结构化的数据进行搜索,从而提高搜索效率。
全文搜索 : 就是把没有结构的数据,转换为有结构的数据,来加快对文本的快速搜索。通常而言,有结构的数据的查询是很快的,因为可以通过算法查询。比如: 有序数组 , 红黑树
1.2. 全文搜索优势或特征
- 搜索效率高,是like无法比拟的 productName like ‘%#{}%’
- 相关度最高的排在最前面,官网中相关的网页排在最前面; java - 命中率
- 关键词的高亮
- 只处理文本,不处理语义。 以单词方式进行搜索,比如在输入框中输入“中国的首都在哪里”,搜索引擎不会以对话的形式告诉你“在北京”,而仅仅是列出包含了搜索关键字的网页
1.3. 常见的全文搜索工具
-
全文搜索工具包:Lucene(核心)–Java做的,一堆jar包
-
全文搜索服务器:Elastic Search(ES-可伸缩/灵活的查询) / Solr等封装了lucene并扩展
2. Lucene概述
2.1. 什么是Lucene
Lucene是apache下的一个开源的全文检索引擎工具包(一堆jar包)。它为软件开发人员提供一个简单易用的工具包(类库),以方便的在小型目标系统中实现全文检索的功能。Lucene适用于中小型项目 ,ES适用于中大型项目(它底层是基于lucene实现的)
2.2. Lucene索引原理(重点)
任何技术都有一些核心,Lucene也有核心,而它的核心分为:索引创建,索引搜索。接下来我们就一一的来看:
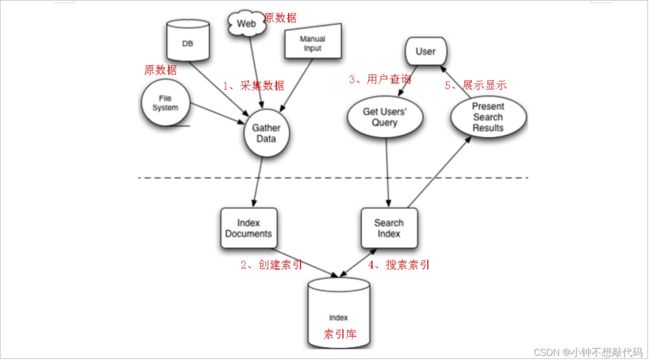
2.2.1. 索引的创建
将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。那么索引里面究竟存的什么,以及如何创建索引呢?在这通过下面的例子来解答这个问题。首先构造三个不同的句子,有长有短:

在①处分别为3个句子加上编号,然后进行分词,把被一个单词分解出来与编号对应放在②处;在搜索的过程总,对于搜索的过程中大写和小写指的都是同一个单词,在这就没有区分的必要,按规则统一变为小写放在③处;要加快搜索速度,就必须保证这些单词的排列时有一定规则,这里按照字母顺序排列后放在④处;最后再简化索引,合并相同的单词,就得到如下结果:倒排索引文档
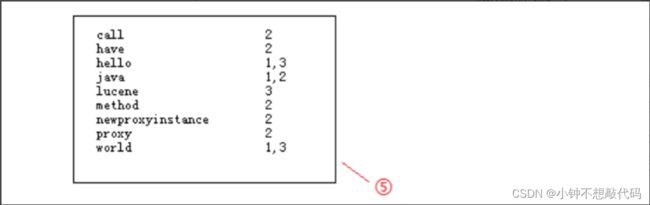
通常在数据库中我们都是根据文档找到内容,而这里是通过词,能够快速找到包含他的文档,这就是文档倒排链表或倒排索引。以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二元搜索算法(二分查找算法)快速定位关键词。
倒排索引创建 = 分词 => 词态转换大小写转换 => 排序 => 合并
2.2.2. 索引的搜索
数据存储包括两个部分:索引区(倒排索引文档) + 数据区(原始数据)
索引搜索:对搜索关键字进行分词 => 搜索倒排索引 => 然后返回索引匹配的内容
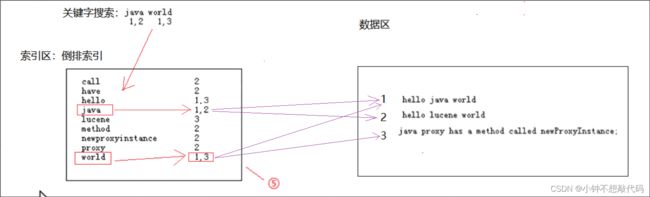
检索java world两个关键词,符合java的有1,2两个文档,符合world的有1,3两个文档,在搜索引擎中直接这样排列两个词他们之间是OR的关系,出现其中一个都可以被找到,所以这里3个都会出来。全文检索中是有相关性排序的,那么结果在是怎么排列的呢?hello java world中包含两个关键字排在第一,另两个都包含一个关键字,得到结果,hello lucene world排在第二,java在最长的句子中占的权重最低排在结果集的第三。从这里可以看出相关度排序还是有一定规则的
二. ElasticSearch相关概念
1. ElasticSearch介绍
1.1. 为什么要使用ElasticSearch
在全文搜索领域,Lucene可以被认为是迄今为止性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
1.2. 什么是ElasticSearch
ElasticSearch简称ES,ES是一个分布式的全文搜索引擎,为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能。它的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
案例:添加数据
PUT /pethome/pet/1
{
"id":1,
"name":"金毛"
}
获取
GET /pethome/pet/1
总的来说ElasticSearch简化了全文检索lucene的使用,同时增加了分布式的特性,使得构建大规模分布式全文检索变得非常容易。
1.3. ES的特点
-
分布式的近实时文件存储。Mysql是实时的
-
能在分布式项目/集群中使用
-
本身支持集群扩展,可以扩展到上百台服务器
-
处理PB级结构化或非结构化数据
-
简单的 RESTful API通信方式
-
支持各种语言的客户端:java,js
-
基于Lucene封装,使操作简单
1.4. ES和lucene的区别
- Lucene只支持Java,ES支持多种语言
- Lucene非分布式,ES支持分布式
- Lucene非分布式的,索引目录只能在项目本地 , ES的索引库可以跨多个服务分片存储
- Lucene使用非常复杂 , ES屏蔽了Lucene的使用细节,操作更方便
- 单体/小项目使用Lucene ,大项目或分布式项目使用ES
2. ES的使用案例
- Github(美国)使用Elasticsearch搜索20TB的数据,包括13亿的文件和1300亿行的代码
- Foursquare实时搜索5千万地点信息?Foursquare每天都用Elasticsearch做这样的事
- 德国SoundCloud使用Elasticsearch来为1.8亿用户提供即时精准的音乐搜索服务
- Mozilla公司以火狐著名,它目前使用 WarOnOrange 这个项目来进行单元或功能测试,测试的结果以 json的方式索引到elasticsearch中,开发人员可以非常方便的查找 bug
- Sony公司使用elasticsearch 作为信息搜索引擎
- 国内:百度、新浪 、阿里巴巴、腾讯等公司均有对ES的使用
3. 其他全文搜索引擎
3.1. Solr(重量级对手)
Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持。
Solr和ES比较:
Solr 利用 Zookeeper(注册中心) 进行分布式管理,支持更多格式的数据(HTML/PDF/CSV),官方提供的功能更多在传统的搜索应用中表现好于 ES,但实时搜索效率低。
ES自身带有分布式协调管理功能,但仅支持json文件格式,本身更注重于核心功能,高级功能多有第三方插件提供,在处理实时搜索应用时效率明显高于 Solr。
3.2. Katta
基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。
优点:开箱即用,可以与 Hadoop (大数据)配合实现分布式。具备扩展和容错机制。
缺点:只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。
3.3. HadoopContrib
大数据相关的东西 (大数据工程师)
Map/Reduce 模式(云计算)的,分布式建索引方案,可以跟 Katta 配合使用。
优点:分布式建索引,具备可扩展性。
缺点:只是建索引方案,不包括搜索实现。工作在批处理模式,对实时搜索的支持不佳。
三. ES下载和安装
ES的安装比较简单,只需要官方下载ES的运行包,然后启动ES服务即可。ES的使用主要是通过能够发起HTTP请求的终端来接入,比如Poster插件、CURL、kibana5等
1. ElasticSearch安装
ES服务只依赖于JDK,推荐使用JDK1.8+。本课程以在window环境下,ES 6.8.6版本为例,下载对应的ZIP文件
1.1. 下载ElasticSearch
下载地址:https://www.elastic.co/downloads/elasticsearch
本课程以在window环境下,ES 6.8.6版本为例,下载对应的ZIP文件
1.2. 安装与启动
解压即可,双击安装目录 bin/elasticsearch.bat即可启动
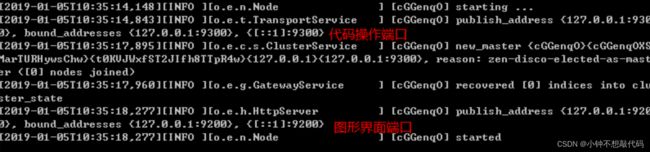
1.3. ElasticSearch测试
使用浏览器访问:http://localhost:9200

看到上图信息,恭喜你,你的ES集群已经启动并且正常运行.
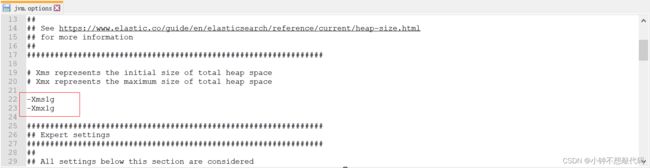
1.4. ES内存配置
如果ES启动占用的内存比较大可以通过修改 jvm.options 文件来修改内存
2. Kibana安装
2.1. 下载Kibana
下载地址:https://www.elastic.co/downloads/kibana
2.2. 安装与启动
解压即可安装 , 执行bin\kibana.bat 即可启动Kibana
2.3. Kinbana连接ES配置
解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
默认情况下,Kibana会链接本地的默认ES http://localhost:9200 ,如果需要修改链接的ES服务器,通过修改安装目录下 config/kibana.yml,将配置项 #elasticsearch.url: "http://localhost:9200" 取消注释即可修改连接的ES服务器地址。
2.4. 测试Kibana
浏览器访问 http://localhost:5601 Kibana默认地址
Kibana组件详细说明:https://www.cnblogs.com/hunttown/p/6768864.html
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
四. ElasticSearch基础
1. 几个基本概念
1.1. Near Realtime(NRT)
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
1.2. Index:索引库
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
1.3. Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,·`一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
注意:ES6.X中一个index下只能包含一个type。ES7版本之后没有Type了,操作不一样了。所以暂时不要安装最新的版本的ES
1.4. Document&field
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
| ElastciSearch全文搜索 | Mysql关系型数据库 |
|---|---|
| 索引库(index) | 数据库(database) |
| 文档类型(Type) | 数据表(Table) |
| 文档(Document) | 一行数据(Row) |
| 字段(field) | 一个列(column) |
| 文档ID | 主键ID |
| 查询(Query DSL) | 查询(SQL) |
| GET http://… | SELECT * FROM … |
| PUT http:// | UPDATE table set… |
1.5. 其他
查询出的结果如下:
{
"took" : 2, #查询耗时
"timed_out" : false, #是否超时,false表示没有
"_shards" : { #分片信息,一般不用管
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : { #查询结果:hit表示命中
"total" : 2, #本次搜索,返回了几条结果
"max_score" : 1.0, #document对于search的相关度的匹配分数,越相关,就越匹配,分数也高
"hits" : [ #结果集
{
"_index" : "pethome", #查询了哪一个索引库idnex - 相当于mysql的哪一个数据库
"_type" : "pet", #查询了哪一个类型type - 相当于mysql的哪一张表
"_id" : "2", #文档id,返回哪一个文档document - 相当于mysql中的那一条数据,id为2
"_score" : 1.0, #匹配度/相关度分数score
"_source" : { #源数据source
"id" : 2, #字段filed - id
"name" : "皮蛋", #字段filed - name
"age" : 3 #字段filed - age
}
},
{
"_index" : "pethome",
"_type" : "pet",
"_id" : "1",
"_score" : 0.5,
"_source" : {
"id" : 1,
"name" : "小七",
"age" : 2
}
}
]
}
}
2. 索引库CRUD
2.1. 增加索引库
- 创建一个名字为
pethome的索引库,5个Master Shard分片,每个Master Shard分片有1个Replica Shard从分片
PUT pethome
{
"settings":{
"number_of_shards":5, #分片数:将数据分布在几个集群节点中
#副本:一个分片有几个备份,对于查询压力比较的的index,可以考虑提高副本数,通过多个副本均摊压力
"number_of_replicas":1
}
}
PUT /pethome #效果同上 - 默认分片数5,默认备份数1
PUT pethome #效果同上 - 默认分片数5,默认备份数1
- 这里不能用POST
POST /pethome #如果使用POST创建索引,会报以下错误
{
"error": "Incorrect HTTP method for uri [/pethome?pretty] and method [POST], allowed: [DELETE, GET, HEAD, PUT]",
"status": 405
}
- 添加文档会自动创建索引库index,名称为pethome
PUT /pethome/pet/1
{
"id":1,
"name":"小七",
"age":1
}
2.2. 查询索引库
查询所有索引库
GET _cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open stumanager ZggatfU2QNmxYT3x-78i7g 5 1 0 0 1.2kb 1.2kb
green open .kibana_1 ze4p7fm2SdunQe3sT4mkBg 1 0 4 1 19.7kb 19.7kb
yellow open pethome Vl8rBt9LQWmwNcEYmz_55A 5 1 11 1 37.8kb 37.8kb
green open .kibana_task_manager f9J4c0Q4TKOULji8mTb1bQ 1 0 2 0 12.5kb 12.5kb
yellow open cms v805r-ugREmrUQRKi595BQ 5 1 0 0 1.2kb 1.2kb
查询指定索引库
GET _cat/indices/pethome
yellow open pethome Vl8rBt9LQWmwNcEYmz_55A 5 1 11 1 37.8kb 37.8kb
查看指定索引库:包括映射信息mappings和设置信息settings
GET /pethome
{
"pethome" : {
"aliases" : { },
"mappings" : {
"pet" : {
"properties" : {
"age" : {
"type" : "long"
},
"id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"query" : {
"properties" : {
"match_all" : {
"type" : "object"
}
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1676266422140",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "Vl8rBt9LQWmwNcEYmz_55A",
"version" : {
"created" : "6080699"
},
"provided_name" : "pethome"
}
}
}
}
2.3. 删除索引库
DELETE 索引库名
2.4. 修改索引库
删除再添加
3. 文档的CRUD(重点)
3.1. 添加文档
我们以员工对象为例,我们首先要做的是存储员工数据,每个文档代表一个员工。在ES中数据存储在索引库中(index),文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以简单的对比传统数据库和ES的对应关系:
| ES | Mysql |
|---|---|
| index(索引库) | 数据库 |
| type(文档类型) | 表 |
| document(文档对象) | 一行数据 |
| id(文档ID) | 主键ID |
| field(字段) | 列 |
ES集群可以包含多个索引(indices - 数据库),ES6.X每一个索引库中只包含一个类型(type - 表),每一个类型包含多个文档(documents - 行),然后每个文档包含多个字段(Field - 列)
- 指定ID创建索引文档
PUT/POST index/type/id
{
JSON,文档内容
}
--解释---------------------------------------
PUT/POST 索引库/文档类型/文档id
{
JSON格式,文档原始数据
}
PUT /cms/emp/1
{
"id":1,
"username":"jack zhang",
"age":20,
"address":"四川成都武侯区",
"birthday":"2019-01-03"
}
POST /cms/emp/2
{
"id":2,
"username":"rose li",
"age":18,
"address":"重庆万州",
"birthday":"2009-05-25"
}
- 不指定ID创建索引文档
POST /cms/emp
{
"id":3,
"username":"tom yang",
"age":30,
"address":"湖北武汉",
"birthday":"2010-05-30"
}
注意1:如果不指定文档的id,ES会自动生成文档id。但是这种方式不能使用PUT,要使用POST,否则报错
{
"error": "Incorrect HTTP method for uri [/cms/emp?pretty] and method [PUT], allowed: [POST]",
"status": 405
}
注意2:ES6.X每一个索引库中只包含一个类型
PUT cms/user/1
{
"id":1
}
#上面已经在cms下新建type类型emp,现在又添加了一个user类型,会报错
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Rejecting mapping update to [cms] as the final mapping would have more than 1 type: [emp, user]"
}
],
"type": "illegal_argument_exception",
"reason": "Rejecting mapping update to [cms] as the final mapping would have more than 1 type: [emp, user]"
},
"status": 400
}
3.2. 获取文档
- 查询所有库的数据
GET _search
如果显示不完全,可以添加size,因为默认只显示10条数据
GET _search
{
"size": 20
}
- 查询指定索引库数据
GET cms/_search
- 查询指定库中指定类型数据(即查询哪一个数据库中的哪一个表的所有数据),结果同上(因为ES6.x一个index下最多就一个type)
GET cms/emp/_search
- 查询指定文档
GET 索引库/类型/文档ID
GET cms/emp/1
- 指定返回的列
GET cms/emp/1?_source=id,username,age
{
"_index" : "cms",
"_type" : "emp",
"_id" : "1",
"_version" : 4,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 1,
"age" : 20,
"username" : "jack zhang"
}
}
3.3. 修改文档
-
全量修改
全量修改的语法跟添加文档语法一样,如果文档已经存在就是添加,否则就是修改,
文档修改过程:1.标记删除旧文档,2.添加新文档
PUT /cms/emp/2
{
"username":"rose li",
"address":"重庆万州",
"birthday":"2009-05-25"
}
POST /cms/emp/2
{
"username":"rose li",
"address":"重庆万州",
"birthday":"2009-05-25"
}
注意:上面的修改都会把ES中的数据全部覆盖,即除了id和age字段会被删除
- 局部修改
POST /cms/emp/2/_update
{
"doc": {
"id":2,
"age":30,
"username":"james wang"
}
}
{
"_index" : "cms",
"_type" : "emp",
"_id" : "3",
"_version" : 4,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"username" : "james wang",
"address" : "重庆万州",
"birthday" : "2009-05-25",
"id" : 2,
"age" : 30
}
}
注意:上面的修改中会把以前文档中没有的字段如id和age会添加到文档,以前有的字段username会修改其内容,以前有的字段address和birthday不会做任何改变。局部修改只能用POST,如果用PUT会报错:
{
"error": "Incorrect HTTP method for uri [/cms/emp/2/_update?pretty] and method [PUT], allowed: [POST]",
"status": 405
}
3.4. 删除文档
DELETE index/type/id
五. 文档查询
1. 字符串查询
字符串查询即将条件在请求路径中。这种方式其实就是在url后面以字符串的方式拼接各种查询条件,这种方式不推荐,因为条件过多,拼接起来比较麻烦 。而且q后面条件是中文,容易出现问题。
GET cms/emp/_search?q=age:17&size=2&from=2&sort=id:desc&_source=id,username
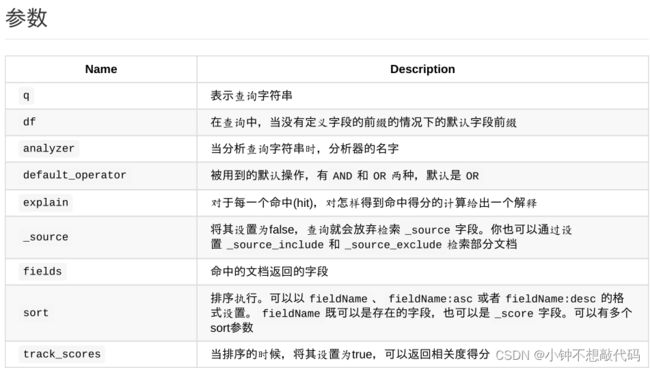
路径后携带的参数如下:

2. DSL查询语言
对于简单查询,使用字符串查询(条件在请求路径中)没有问题。但是对于复杂查询,由于条件多,逻辑嵌套复杂,查询字符串不易组织与表达,且容易出错。因此推荐通过DSL查询语言,即将查询条件使用JSON内容格式写在请求体中进行查询。
DSL查询语言是由ES提供的丰富且灵活的查询语言,它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。DSL有两部分组成:查询DSL(query DSL)和过滤DSL(filter DSL),都可以用来做文档查询,但是两者却有不同:

查询DSL:会计算相关性/匹配度/分数,并进行排序,所以更耗时,且不缓存。通常用来做全文查询
过滤DSL:强调是还是不是,不计算相关性也不排序,所以更快,且过滤结果可以缓存并应用到后续查询请求。通常用来做精确查询,范围查询,存在或不存在
3. 查询方式
ES中有很多查询方式,在不同的场景中我们需要根据情况进行合理的选择,首先我们准备一些基础数据
DELETE /pethome
PUT /pethome/pet/1
{
"id":1,
"name":"小七",
"age":1
}
PUT /pethome/pet/2
{
"id":2,
"name":"皮蛋",
"age":2
}
PUT /pethome/pet/3
{
"id":3,
"name":"七七",
"age":3
}
PUT /pethome/pet/4
{
"id":4,
"name":"花花",
"age":4
}
PUT /pethome/pet/5
{
"id":5,
"name":"可乐",
"age":5
}
PUT /pethome/pet/6
{
"id":6,
"name":"地主",
"age":6
}
PUT /pethome/pet/7
{
"id":7,
"name":"hello small cat",
"age":7
}
PUT /pethome/pet/8
{
"id":8,
"name":"big cat",
"age":8
}
PUT /pethome/pet/9
{
"id":9,
"name":"hello cat",
"age":9
}
PUT /pethome/pet/10
{
"id":10,
"name":"small cat",
"age":10
}
PUT /pethome/pet/11
{
"id":11,
"name":"cat",
"age":11
}
注意:将数据添加到ES的索引库中会采用默认的分词规则,即数据在索引库是分了词的
#默认分词器分词:hello,small,cat - 英文按空格来分
POST _analyze
{
"text":"hello small cat"
}
#默认分词器分词:小,猫,咪 - 中文按空字符串分。对中文不是很友好,后面会采用ik分词器按照中文习惯来分
POST _analyze
{
"text":"小猫咪"
}
3.1. 全匹配match_all
匹配所有文档即查询所有,等价于GET /pethome/pet/_search
GET /pethome/pet/_search
{
"query": {
"match_all": {}
}
}
注:kibana中查询的数据默认只显示10条。假如总数量有11条,但只显示10条。可以通过以下方式处理
GET /pethome/pet/_search
{
"size": 20
}
#可以通过设置size显示11条数数据
3.2. 查询指定字段_source
GET pethome/pet/_search
{
"query": {
"match_all": {}
},
"_source": ["name","age"]
}
#查询出的文档或数据只显示name和age两个字段的值,id字段不会被查询出来
3.3. 分页查询from和size
size:每页条数
form:从多少条数据开始查,从0开始,表示第一条数据
GET pethome/pet/_search
{
"from": 0,
"size": 4
}
#查询第一页,每页显示4条的数据
3.4. 排序sort
GET pethome/pet/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
GET pethome/pet/_search
{
"sort": [
{
"age": "desc",
"id": {
"order": "asc"
}
}
]
}
GET pethome/pet/_search
{
"sort": [{"id": "desc"}] #这里只有一个排序条件,可以省略[]
}
注意:只有排序是不会计算相关分数的,所以结果中 “max_score” : null
3.5. 标准查询match和multi_match
标准查询,可以理解为分词查询。会对查询的内容进行分词后,得到多个单词,分别带着多个单词去检索ES库,只要有一个单词能查出结果,整个查询就有结果。不管你需要全文本查询还是精确查询基本上都要用到它
如下面的搜索会对hello cat分词,并找到包含hello或cat的文档,然后给出匹配分值
GET pethome/pet/_search
{
"query": {
"match": {
"name": "hello cat"
}
}
}
注意:上面效果如同 where name="hello" or name="cat"
提示:match一般只用于全文匹配和查询,一般不用于过滤
multi_match查询允许你做match查询的基础上同时搜索多个字段:
{
"query": {
"multi_match": {
"query": "hello cat",
"fields": ["name", "address"]
}
}
}
注意:上面的搜索同时在name和address字段中匹配。
如同:where name=“hello” or name=“cat” or address=“hello” or address=“cat”
3.6. 词元查询term和terms
词元查询,可以理解为等值查询,字符串,数字等都可以使用它,把查询的内容看成一个整体去检索ES库
GET pethome/pet/_search
{
"query": {
"term": {
"name": "hello cat"
}
}
}
相当于:where name="hello cat"
提示:上面的"hello cat"会被当成一个整体去检索ES库,它跟match不同的地方在于match会把"hello cat"分成"hello"和"cat"分别去name中查询
terms支持多个字段查询
GET pethome/pet/_search
{
"query": {
"terms": {
"name": [
"hello",
"cat",
"small"
],
"minimum_match": 1
}
}
}
提示:minimum_match:至少匹配个数,默认为1
如同:where name in (“hello”, “cat” , “small”)
- match和term区别
GET /pethome/pet/_search
{
"query" : {
"match" : {
"name" : "hello java"
}
}
}
区别1:match指的是"标准查询",该查询方式会对查询的内容进行分词。term是"词元查询" ,不会对查询的内容进行分词。
match如同:where name=“hello” or name =“java”
term如同:where name= “hello java”
注意:添加的ES索引库index中的数据默认text类型,是进行了分词的,例如添加"hello world java"到ES索引库的name字段中,实际上在ES中已经变成三个单词了:hello,world,java
用法:match一般用于全文查询,term一般用于过滤查询
3.7. 范围查询range
range过滤允许我们按照指定范围查找一批数据
GET pethome/pet/_search
{
"query": {
"range": {
"age": {
"gte": 5,
"lt":10
}
}
}
}
上例中查询年龄大于等于5并且小于10的数据
gt:> gte:>= lt:< lte:<=
3.8. 批量查询mget
- 同索引库同类型
GET pethome/pet/_mget
{
"ids" : [ "2", "1" ]
}
- 不同索引库查询
GET _mget
{
"docs" : [
{
"_index" : "cms01",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "cms02",
"_type" : "employee",
"_id" : 1,
"_source": "email,age"
}
]
}
3.9. 存在和缺失exists和missing
{
"query": {
"bool": {
"must": [
{
"match_all": {
}
}
],
"filter": {
"exists": {
"field": "name" #查询出有name字段的文档数据
}
}
}
}
}
提示:exists和missing只能用于过滤结果
3.10. 前缀匹配prefix
前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%’
{
"query": {
"prefix": {
"name": "小"
}
}
}
提示:上例即查询name以小开头的数据
3.11. 通配符查询wildcard
使用*代表0~N个,使用?代表1个
{
"query": {
"wildcard": {
"name": "元*"
}
}
}
3.12. 组合条件bool
组合搜索bool可以组合多个查询条件为一个查询对象,查询条件包括must、should和must_not
例如:查询喜欢游戏或运动的女性,且出生于1990-06-30及之后的人
GET /aigou/product/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"sex": 0
}
}
],
"should": [
{
"term": {
"hobby": "游戏"
}
},
{
"term": {
"hobby": "运动"
}
}
],
"must_not": [
{
"range": {
"birth_date": {
"lt": "1990-06-30" #less than = lt
}
}
}
],
"filter": [
...
]
}
}
}
上面案例如同:sex=0 and (hobby=游戏 or hobby=运动) and birth_date >= 1990-06-30
- query : 查询,所有的查询条件在query里面
- bool : 组合搜索bool可以组合多个查询条件为一个查询对象,这里包含了DSL查询和DSL过滤的条件
- must : 必须匹配 :与(must - and) 或(should - or) 非(must_not - !)
- match:分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
- term:词元查询,不会对查询条件分词
- range:范围查询
- filter: 过滤条件,结果会缓存,但不计算相关性/匹配度
- match:分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
- term:词元查询,不会对查询条件分词
- range:范围查询
- from,size :分页
- _source :查询结果中需要哪些列
- sort:排序
综合案例:查询名称name中有"cat",年龄age在5-10之间,按照年龄age倒排序,查询第1页,每页5条 ,查询结果中只需要 name,age字段
GET /aigou/product/_search
{
"query":{
"bool": {
"must": [{
"match": {
"name": "cat"
}
}],
"filter": [
{
"range":{ //范围查询
"age":{
"gte":5,
"lte":10
}
}
}
]
}
},
"from": 0,
"size": 5,
"_source": ["name", "age"],
"sort": [{
"age": "desc"
}]
}
提示: 如果 bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有must子句,那么没有 should子句也可以进行查询
六. 分词器安装和使用
1. 基本概念
1.1. 什么是分词
在全文检索理论中,文档的查询是通过关键字查询文档索引来进行匹配,因此将文本拆分为有意义的单词,对于搜索结果的准确性至关重要,因此,在建立索引的过程中和分析搜索语句的过程中都需要对文本串分词。ES的倒排索引是分词的结果。
1.2. 理解分词的作用
分词器的作用至关重要,数据的查询结果是否精准跟分词器有很大的关系
为了方便理解,我们用一个模拟图跟踪一下ES创建倒排索引的过程,如有原始数据:
| ID | username | intro |
|---|---|---|
| 1 | zs | my name is zs |
| 2 | ls | my name is ls |
如果对intro进行倒排索引,ES会根据分词器进行分词 , 语义转换,排序, 分组等操作最终倒排索引如下:
| 词元 | ID倒排 |
|---|---|
| is | 1 -> 2 |
| ls | 2 |
| my | 1 -> 2 |
| name | 1 -> 2 |
| zs | 1 |
当ES进行关键字查询的时候,如需要查询“my” ,那么ES可以根据二分查找更快的定位到 my | 1 -> 2 , 根据ID值1 ,2直接取出结果。
2. IK分词器
2.1. 为什么用IK分词器
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器 - 大家都在用IK
2.2. 安装IK分词器
- 下载ES的IK分词器
插件源码地址:https://github.com/medcl/elasticsearch-analysis-ik
- 解压elasticsearch-analysis-ik-5.2.2.zip文件
并将解压后的内容放置于ES根目录/plugins/ik
- IK分词器配置
在ik/config 目录可以对分词器进行配置,如停词 , 自定义字典等。
- IK分词测试
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
提示:IK分词器指定:ik_smart ; ik_max_word , ik_max_word 相比 ik_smart 来说会将文本做最细粒度的拆分。
七. 文档映射
分词器如何使用呢?我们需要学习文档映射,相当于在Mysql中创建表时指定字段的类型,大小等
1. 什么是文档映射
ES的文档映射(mapping)机制用于文档字段的设置。例如设置字段为一种确定的数据类型,还可以设置当前字段使用哪种分词器。
查看文档映射配置
GET _mapping #查看每个索引库下的文档映射配置
GET crm/_mapping #查看指定索引库下的文档映射配置
GET crm/user/_mapping #查看指定索引库下指定类型的文档映射配置 - 效果同上,一个index中一个type
1.1. 文档字段属性
文档的字段可以指定以下属性,常用的有:type类型,analyzer分词器
| type | integer,long,date,boolean,keyword,text… |
|---|---|
| enable | 是否启用:默认为true。 false:不能索引、不能搜索过滤,仅在_source中存储 |
| boost | 权重提升倍数:用于查询时加权计算最终的得分 |
| format | 格式:一般用于指定日期格式,如 yyyy-MM-dd HH:mm:ss.SSS |
| ignore_above | 长度限制:长度大于该值的字符串将不会被索引和存储 |
| ignore_malformed | 转换错误忽略:true代表当格式转换错误时,忽略该值,被忽略后不会被存储和索引 |
| include_in_all | 是否将该字段值组合到_all中。 |
| null_value | 默认控制替换值。如空字符串替换为”NULL”,空数字替换为-1 |
| store | 是否存储:默认为false。true意义不大,因为_source中已有数据 |
| index | 索引模式:analyzed (索引并分词,text默认模式), not_analyzed (索引不分词,keyword默认模式),no(不索引) |
| analyzer | 索引分词器:索引创建时使用的分词器,如ik_smart,ik_max_word,standard |
| search_analyzer | 搜索分词器:搜索该字段的值时,传入的查询内容的分词器 |
1.2. 文档字段类型
- 基本字段类型
字符串:text(分词),keyword(不分词),StringField(不分词文本),TextFiled(要分词文本)
数值:long,integer,short,double,float
日期:date
逻辑:boolean
- 复杂字段类型
对象类型:object
数组类型:array
地理位置:geo_point,geo_shape
- 默认文档映射
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映射关系
| 内容 | 默认映射类型 |
|---|---|
| true,false | boolean |
| 123 | long |
| 123.45 | double |
| “2014-09-15” | date |
| “foo bar” | text |
2. 添加文档映射
注意:如果索引库已经有数据了,就不能再添加映射了
- 创建索引库
put crm
- 创建文档映射
put crm/user/_mapping
{
"user": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
解释:给crm索引库中的是user类型创建文档映射 ,id指定为long类型 , name指定为text类型(要分词),analyzer分词使用ik,查询分词器也使用ik
注意:一个index索引库只能添加一个映射_mapping
3. 其他文档类型映射
基本类型字段映射非常简单,直接配置对应的类型即可,但是数组和对象如何指定类型呢?
3.1. 对象映射
{
"id" : 1,
"girl" : {
"name" : "王小花",
"age" : 22
}
}
文档映射
{
"properties": {
"id": {"type": "long"},
"girl": {
"properties":{
"name": {"type": "keyword"},
"age": {"type": "integer"}
}
}
}
}
3.2. 数组映射
{
"id" : 1,
"hobby" : ["王小花","林志玲"]
}
文档映射
{
"properties": {
"id": {"type": "long"},
"hobby": {"type": "keyword"}
}
}
解释:数组的映射只需要映射一个元素即可,因为数组中的元素类型是一样的。
3.3. 对象数组
{
"id" : 1,
"girl":[{"name":"林志玲","age":32},{"name":"赵丽颖","age":22}]
}
文档映射
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties": {
"age": { "type": "long" },
"name": { "type": "text" }
}
}
}
八. JavaApi操作ES
1. 集成ES
官方文档API:https://www.elastic.co/guide/en/elasticsearch/client/java-api/index.html
选择6.8 - Javadoc - Document APIs/Search API/Query DSL ->
在Document APIs下有:
Index API
Get API
Delete API
Update API
Java操作ES - Spring操作ES - SpringBoot操作ES
1.1. 导入依赖
下面采用ES提供的Jar进行ES操作
<dependencies>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>6.8.6version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>compilescope>
dependency>
dependencies>
1.2. 连接ElasticSearch
编写工具:
public class ESClientUtil {
public static TransportClient getClient(){
TransportClient client = null;
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch").build();
try {
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
} catch (UnknownHostException e) {
e.printStackTrace();
}
return client;
}
}
注意:Java操作ES的Client有两种:TransportClient和Rest Client。但是Elasticsearch 7.0中开始弃用TransportClient,在8.0中完全删除它
2. 文档CRUD
2.1. 添加文档
//添加
@Test
public void add() throws Exception{
//添加数据
/*
IndexRequestBuilder builder1 = es.prepareIndex("pethome", "pet", "12");
Map map = new HashMap<>();
map.put("id",12);
map.put("name","皮卡丘");
map.put("age",12);
IndexRequestBuilder builder2 = builder1.setSource(map);
System.out.println(builder2.get());
*/
//简写
Map<String,Object> map = new HashMap<>();
map.put("id",12);
map.put("name","皮卡丘");
map.put("age",12);
System.out.println(es.prepareIndex("pethome", "pet", "12").setSource(map).get());
//查询数据
System.out.println(es.prepareGet("pethome", "pet", "12").get().getSource());
}
2.2. 更新文档
//修改
@Test
public void updata() throws Exception{
Map<String,Object> map = new HashMap<>();
map.put("name","皮卡丘-update");
System.out.println(es.prepareUpdate("pethome", "pet", "12").setDoc(map).get());
//查询数据
System.out.println(es.prepareGet("pethome", "pet", "12").get().getSource());
}
2.3. 删除文档
//删除
@Test
public void delete() throws Exception{
System.out.println(es.prepareDelete("pethome", "pet", "12").get());
//查询数据
System.out.println(es.prepareGet("pethome", "pet", "12").get().getSource());//null
}
2.4. 查询操作
//查询单个数据
@Test
public void findOne() throws Exception{
// GetRequestBuilder builder = es.prepareGet("pethome", "pet", "1");
// GetResponse response = builder.get();
// Map map = response.getSource();
// System.out.println(map);
System.out.println(es.prepareGet("pethome", "pet", "1").get().getSource());
}
//同时查询多条数据
@Test
public void findMany() throws Exception{
MultiGetRequestBuilder builder = es.prepareMultiGet().add("pethome", "pet", "1", "2", "3");
MultiGetResponse responses = builder.get();
MultiGetItemResponse[] items = responses.getResponses();
for (MultiGetItemResponse item : items) {
System.out.println(item.getResponse().getSource());
}
}
//查询
@Test
public void findQuery() throws Exception{
//1.term词元查询 - 不分词
QueryBuilder builder2 = QueryBuilders.termQuery("","");
//2.match标准查询 - 分词
MatchQueryBuilder builder3 = QueryBuilders.matchQuery("", "");
//3.查询所有数据
MatchAllQueryBuilder builder4 = QueryBuilders.matchAllQuery();
//4.是否存在
ExistsQueryBuilder builder5 = QueryBuilders.existsQuery("");
//5.范围查询
RangeQueryBuilder builder6 = QueryBuilders.rangeQuery("").gt("").lt("");
SearchRequestBuilder builder7 = es.prepareSearch("pethome").setQuery(builder2);
//6.分页查询
SearchRequestBuilder builder8 = es.prepareSearch("pethome").setFrom(0).setSize(2);
//最后:获取SearchRequestBuilder中的数据
SearchResponse response = builder8.get();
SearchHits hits = response.getHits();
SearchHit[] hits1 = hits.getHits();
for (SearchHit hit : hits1) {
System.out.println(hit.getSourceAsMap());
}
}
//组合查询:查询名称name中有"cat",年龄age在5-10之间,按照年龄age倒排序,查询第1页,每页5条 ,查询结果中只需要 name,age字段
@Test
public void boolQuery() throws Exception{
BoolQueryBuilder builder = new BoolQueryBuilder();
builder.must().add(QueryBuilders.matchQuery("name","cat"));
builder.must().add(QueryBuilders.rangeQuery("age").gte(5).lte(10));
//按照年龄age倒排序
FieldSortBuilder sortBuilder = SortBuilders.fieldSort("age").order(SortOrder.DESC);
//查询结果中只需要 name,age字段
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
String[] fileds = {"name","age"};
SearchSourceBuilder filedsBuilder = sourceBuilder.fetchSource(fileds, null);
SearchRequestBuilder resultBuilder = es.prepareSearch("pethome")
.setSource(filedsBuilder) //这个要放在setQuery前
.setQuery(builder)
.setFrom(0).setSize(10)
.addSort(sortBuilder);
SearchResponse response = resultBuilder.get();
SearchHits hits = response.getHits();
SearchHit[] hits1 = hits.getHits();
for (SearchHit hit : hits1) {
System.out.println(hit.getSourceAsMap());
}
}
九. 课程总结
1. 重点内容
1. 文档的CRUD
2. DSL查询和过滤
3. 文档映射
4. Java操作ES
2. 面试问题
1. 数据库,表,列 在ES分别怎么对应的?
2. ES用到了什么数据结构
3. ES为什么比like快
4. ES的优势是什么
5. ES怎么做查询分页排序
6. Keyword和text的区别
7. 索引创建原理
8. Lucene和ES区别
十. 扩展知识
1. 高可用(High availability,缩写为 HA)
是指系统无中断地执行其功能的能力,代表系统 的可用性程度。 高可用的主要目的是为了保障“业务的连续性”,即在用户眼里,业务永远是正常对外 提供服务的
2. kibana查询上下文结果字段解析:
took:耗费了几毫秒
timed_out:是否超时,false是没有,默认无timeout
_shards:分片信息。shards fail的条件(primary和replica全部挂掉),不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
hits.total:本次搜索,返回了几条结果
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据,默认查询前10条数据,按_score降序排序
3. ES中操作文档POT与POST区别:
共同点:ES中的put和post同样都具备创建和更新的功能
不同点:
put需要精确到某一个资源文件,这样才能进行对数据的更新和创建操作
post能对整个资源集合进行操作,如果没有指定具体修改的文件id,那么post指令会自动生成一个唯一的id进行文件的创建,并将数据写入该文件中。如果指定了文件id,那么就会根据填写的参数对数据进行创建和更新操作
4. 幂等性与非幂等性:
PUT、GET、DELETE是幂等的,由于同一条这样的指令,执行多次结果都一样。比如 PUT /uri/xxx 多次,那么结果和这条指令执行一次效果一样。
而POST是非幂等的,执行多次更改多次服务器状态。比如POST /uri 多次,那么生成多个UUID的document,执行多次效果当然和执行一次不一样了
PUT是幂等方法,POST不是。所以PUT用于更新、POST用于新增比较合适。
PUT,DELETE操作是幂等的。所谓幂等是指不管进行多少次操作,结果都一样。比如我用PUT修改一篇文章,然后在做同样的操作,每次操作后的结果并没有不同,DELETE也是一样。
POST操作不是幂等的,比如常见的POST重复加载问题:当我们多次发出同样的POST请求后,其结果是创建出了若干的资源
5. 正排索引/正向索引
id content
1 my name is zhang san
2 my name is li si
为了提高查询效率,我们可以将id设置为主键,同时生成主键索引。通过主键索引快速关联上内容信息
但是如果想要查询内容中包含name或zhang的时候,就麻烦了,要做模糊查询,效率很低。而且要去遍历每条数据,性能会差很多
而且大小写还会影响查询结果Zhang
------------------------------------------------
keywork id
name 1,2
zhang 1
现在是通过关键字查询主键id,然后关联我们的文章内容。以前是通过主键id关联文章内容,再去找它的关键字 - 相反的
倒排索引中强调的是关键字和主键的关联,并没有体现表的作用。所以type被弱化甚至到后来被删除了