Focal and Global Knowledge Distillation for Detectors(CVPR 2022)原理与代码解析
paper:Focal and Global Knowledge Distillation for Detectors
official implementation:https://github.com/yzd-v/FGD
存在的问题
如图1所示,前景区域教师和学生注意力之间的差异非常大,背景区域则相对较小。此外通道注意力的差异也非常明显。

作者还设计了实验解耦了蒸馏过程中的前景和背景,结果如表1所示,令人惊讶的是,前景背景一起进行蒸馏的效果是最差的,比单独蒸馏前景或背景还差。
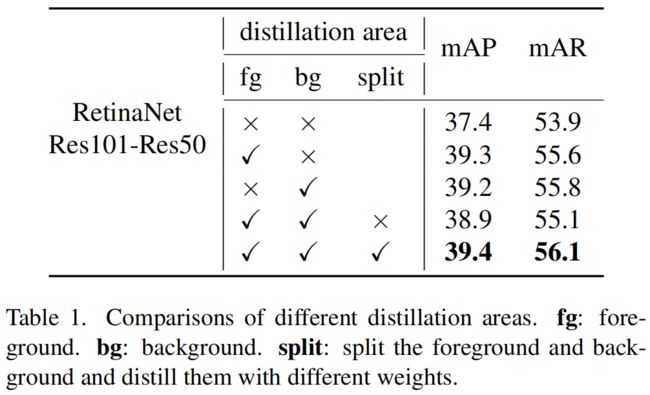
上述结果表明,特征图中的不均匀差异会对蒸馏产生负面效果。这种不均匀差异不仅存在于前背景之间,也存在于不同像素位置和通道之间。
本文的创新点
针对前背景、空间位置、通道之间的差异,本文提出了focal distillation,在分离前背景的同时,还计算了教师特征不同空间位置和通道的注意力,使得学生专注于学习教师的关键像素和通道。
但是只关注关键信息还不够,在检测任务中全局语义信息也很重要。为了弥补focal蒸馏中缺失的全局信息,作者还提出了global distillation,其中利用GcBlock来提取不同像素之间的关系,然后传递给学生。
方法介绍
Focal Distillation
首先用一个binary mask \(M\) 来分离前背景
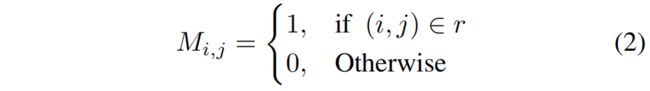
其中 \(r\) 是ground truth box,\(i,j\) 表示像素位置的坐标。
为了消除不同大小的gt box的尺度的影响和不同图片中前背景比例的差异,作者又设置了一个scale mask \(S\)
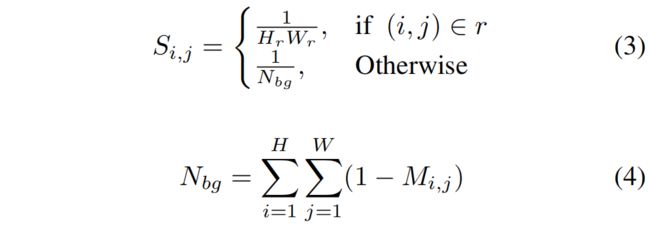
其中 \(H_{r},W_{r}\) 表示gt box \(r\) 的高和宽,如果一个像素属于不同的target,选择最小的box来计算 \(S\)。
接着作者借鉴SENet和CBAM的方法提取通道注意力和空间注意力

\(G^{S},G^{C}\) 分别表示空间和通道attention map,然后attention mask按下式计算

其中 \(T\) 是温度系数。
利用binary mask \(M\)、scale mask \(S\)、attention mask \(A^{S},A^{C}\),特征损失 \(L_{fea}\) 如下
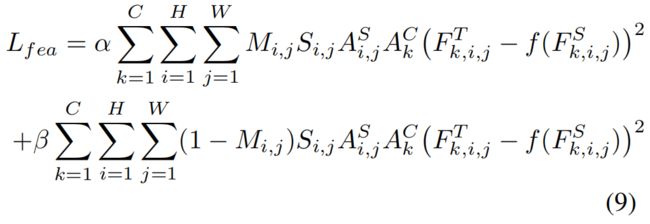
其中 \(A^{S},A^{C}\) 表示教师的空间和通道attention mask,\(F^{T},F^{S}\) 分别表示教师和学生的feature map,\(\alpha, \beta\) 是balance超参。
此外作者还提出了注意力损失 \(L_{at}\) 让学生模仿教师的attention mask
![]()
\(l\) 表示L1损失。
完整的focal损失就是特征损失和注意力损失的和
![]()
Global Distillation
如图4所示,作者用GcBlock来提取全局关系信息,关于GcBlock的详细介绍可以参考GCNet: Global Context Network(ICCV 2019)原理与代码解析

全局损失 \(L_{global}\) 如下
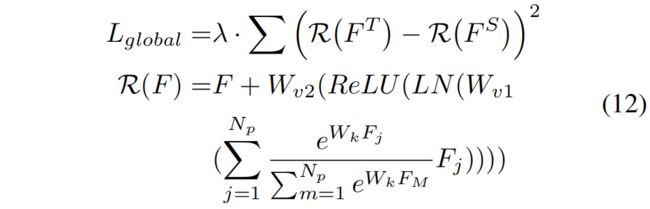
\(W_{k},W_{v1},W_{v2}\) 是卷积层,\(LN\) 表示layer normalization,\(N_{p}\) 是特征中所有像素个数,\(\lambda\) 是balance超参。
Overall loss
完整的损失函数如下,包括原本的训练损失和蒸馏损失,蒸馏损失又包括focal损失和global损失
![]()
实验结果
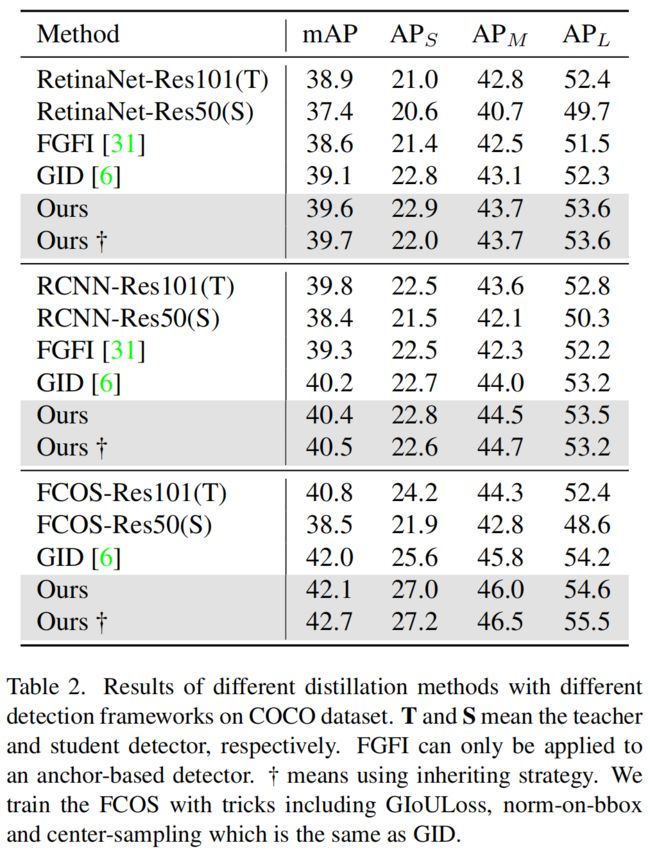

其中inheriting strategry是《Instance-conditional knowledge distillation for object detection》这篇文章中提出的用教师的neck和head参数初始化学生网络,可以得到更好的效果。
代码解析
主要实现在mmdet/distillation/losses/fgd.py中,函数forward中,首先教师和学生的attention mask,即文中的式(5)~(8)
S_attention_t, C_attention_t = self.get_attention(preds_T, self.temp) # (N,H,W),(N,C)
S_attention_s, C_attention_s = self.get_attention(preds_S, self.temp)def get_attention(self, preds, temp):
""" preds: Bs*C*W*H """
N, C, H, W = preds.shape
value = torch.abs(preds)
# Bs*W*H
fea_map = value.mean(axis=1, keepdim=True)
S_attention = (H * W * F.softmax((fea_map / temp).view(N, -1), dim=1)).view(N, H, W)
# Bs*C
channel_map = value.mean(axis=2, keepdim=False).mean(axis=2, keepdim=False)
C_attention = C * F.softmax(channel_map / temp, dim=1)
return S_attention, C_attention接下来为了减小不同target尺度和前背景比例的影响,计算scale mask,即文中的式(2)~式(4)。其中内层的for循环是当一个像素属于不同的target时,选择最小的box来计算。
Mask_fg = torch.zeros_like(S_attention_t)
Mask_bg = torch.ones_like(S_attention_t)
wmin, wmax, hmin, hmax = [], [], [], []
for i in range(N):
new_boxxes = torch.ones_like(gt_bboxes[i])
new_boxxes[:, 0] = gt_bboxes[i][:, 0] / img_metas[i]['img_shape'][1] * W
new_boxxes[:, 2] = gt_bboxes[i][:, 2] / img_metas[i]['img_shape'][1] * W
new_boxxes[:, 1] = gt_bboxes[i][:, 1] / img_metas[i]['img_shape'][0] * H
new_boxxes[:, 3] = gt_bboxes[i][:, 3] / img_metas[i]['img_shape'][0] * H
wmin.append(torch.floor(new_boxxes[:, 0]).int())
wmax.append(torch.ceil(new_boxxes[:, 2]).int())
hmin.append(torch.floor(new_boxxes[:, 1]).int())
hmax.append(torch.ceil(new_boxxes[:, 3]).int())
area = 1.0 / (hmax[i].view(1, -1) + 1 - hmin[i].view(1, -1)) / (wmax[i].view(1, -1) + 1 - wmin[i].view(1, -1))
for j in range(len(gt_bboxes[i])):
Mask_fg[i][hmin[i][j]:hmax[i][j] + 1, wmin[i][j]:wmax[i][j] + 1] = \
torch.maximum(Mask_fg[i][hmin[i][j]:hmax[i][j] + 1, wmin[i][j]:wmax[i][j] + 1], area[0][j])
Mask_bg[i] = torch.where(Mask_fg[i] > 0, 0, 1)
if torch.sum(Mask_bg[i]):
Mask_bg[i] /= torch.sum(Mask_bg[i])接着就是完整的feature损失,即文中的式(9)
fg_loss, bg_loss = self.get_fea_loss(preds_S, preds_T, Mask_fg, Mask_bg,
C_attention_s, C_attention_t, S_attention_s, S_attention_t)def get_fea_loss(self, preds_S, preds_T, Mask_fg, Mask_bg, C_s, C_t, S_s, S_t):
loss_mse = nn.MSELoss(reduction='sum')
Mask_fg = Mask_fg.unsqueeze(dim=1)
Mask_bg = Mask_bg.unsqueeze(dim=1)
C_t = C_t.unsqueeze(dim=-1)
C_t = C_t.unsqueeze(dim=-1)
S_t = S_t.unsqueeze(dim=1)
fea_t = torch.mul(preds_T, torch.sqrt(S_t))
fea_t = torch.mul(fea_t, torch.sqrt(C_t))
fg_fea_t = torch.mul(fea_t, torch.sqrt(Mask_fg))
bg_fea_t = torch.mul(fea_t, torch.sqrt(Mask_bg))
fea_s = torch.mul(preds_S, torch.sqrt(S_t))
fea_s = torch.mul(fea_s, torch.sqrt(C_t))
fg_fea_s = torch.mul(fea_s, torch.sqrt(Mask_fg))
bg_fea_s = torch.mul(fea_s, torch.sqrt(Mask_bg))
fg_loss = loss_mse(fg_fea_s, fg_fea_t) / len(Mask_fg)
bg_loss = loss_mse(bg_fea_s, bg_fea_t) / len(Mask_bg)
return fg_loss, bg_loss文中作者还提出了用L1 loss的attention损失,即式(10)
mask_loss = self.get_mask_loss(C_attention_s, C_attention_t, S_attention_s, S_attention_t)def get_mask_loss(self, C_s, C_t, S_s, S_t):
mask_loss = torch.sum(torch.abs((C_s - C_t))) / len(C_s) + torch.sum(torch.abs((S_s - S_t))) / len(S_s)
return mask_lossfeature loss和attention loss一起组成的focal loss,为了弥补全局语义信息的缺失,作者又引入了全局蒸馏损失,其中用到了GcBlock,即式(12)
rela_loss = self.get_rela_loss(preds_S, preds_T)def get_rela_loss(self, preds_S, preds_T):
loss_mse = nn.MSELoss(reduction='sum')
context_s = self.spatial_pool(preds_S, 0)
context_t = self.spatial_pool(preds_T, 1)
out_s = preds_S
out_t = preds_T
channel_add_s = self.channel_add_conv_s(context_s)
out_s = out_s + channel_add_s
channel_add_t = self.channel_add_conv_t(context_t)
out_t = out_t + channel_add_t
rela_loss = loss_mse(out_s, out_t) / len(out_s)
return rela_lossdef spatial_pool(self, x, in_type):
batch, channel, width, height = x.size()
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
if in_type == 0:
context_mask = self.conv_mask_s(x)
else:
context_mask = self.conv_mask_t(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = F.softmax(context_mask, dim=2)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
return context
self.channel_add_conv_s = nn.Sequential(
nn.Conv2d(teacher_channels, teacher_channels//2, kernel_size=1),
nn.LayerNorm([teacher_channels//2, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(teacher_channels//2, teacher_channels, kernel_size=1))
self.channel_add_conv_t = nn.Sequential(
nn.Conv2d(teacher_channels, teacher_channels//2, kernel_size=1),
nn.LayerNorm([teacher_channels//2, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(teacher_channels//2, teacher_channels, kernel_size=1))