力扣刷题集锦
力扣刷题
- 二、剑指offer
-
- (一)栈与队列
-
- 1.用两个栈实现队列
- 2.包含min函数的栈
- (二)链表
-
- 1.从尾到头打印链表
- 2.反转链表
- 3.复杂链表的复制
- (三)字符串
-
- 1.替换空格
- 2.翻转单词顺序
- (四)查找算法
-
- 1.数组中重复的数字
- 2.在排序数组中查找数字
- 3.0~1中缺失的数字
- 4.第一次只出现一次的字符
- 5.旋转数组的最小数字
- 6.二维数组中的查找
- (五)搜索与回溯算法
-
- 1. 从上到下打印二叉树I
- 2. 从上到下打印二叉树Ⅱ
- 3.从上到下打印二叉树Ⅲ
- 4.树的子结构
- 5.二叉树的镜像
- 6.对称的二叉树
- 7.矩阵中的路径
- 8.机器人的运动范围
- 9.二叉树中和为某一值的路径
- 10.二叉搜索树与双向链表
- 11.二叉搜索树的第K大节点
- (六)动态规划
-
- 1.斐波那契数列
- 2.青蛙跳台阶问题
- 3.股票的最大利润
- 4.连续子数组的最大和
- 5.礼物的最大价值
- 6.最长不含重复字符的子字符串
- 7.把数字翻译成字符串
- (七)双指针
-
- 1.删除链表的节点
- 2.链表中倒数第k个节点
- 3.合并两个排序的链表
- 4.两个链表的第一个公共节点
- 5.调整数组顺序使奇数位于偶数前面
- 6.和为s的两个数字
- 7.和为s的连续正数序列
- (八)排序
-
- 1.把数组排成最小的数
- 2.扑克牌中的顺子
- 3.最小的k个数
- (九)数学
-
- 1.数组中数字超过一半的数字 10.27
- 2.求解数组中出现次数超过1/3的那个数
- 重复想到使用set((四)-1)
- **有序数组搜索题一般是二分查找或者双指针 ((四)-2) ((七)-6)**
- 倒序想到堆栈((二)-1)
二、剑指offer
(一)栈与队列
1.用两个栈实现队列

思想:
堆栈是后入先出,队列是先入先出。使用两个栈模拟队列的话,第一个栈用来存储进队的元素,由于进队的较早元素处于第一个栈的栈底,所以当遇到出队的命令时,需要将第一个栈的元素都pop到第二个栈,这样进行元素顺序反转,这样第二个栈的栈顶元素就是出队的顺序元素。
注意的是:
- 第一个栈吐元素给第二个栈时,条件是:出队命令&&第二栈空。
- 当两个栈都空的时候代表队列没有元素。
class CQueue {
//存放入队数据
private Deque<Integer> stack1;
//存放出队数据
private Deque<Integer> stack2;
//初始化
public CQueue() {
stack1 = new LinkedList<>();
stack2 = new LinkedList<>();
}
//元素入队
public void appendTail(int value) {
stack1.offerFirst(value);
}
//元素出队
public int deleteHead() {
//stack2为空->队头的元素在stack1的栈底
if (stack2.isEmpty()) {
//stack1和2都为空->队列为空
if (stack1.isEmpty()) {
return -1;
}
//出队时将数据顺序扭转存入出队栈,准备出栈
while (!stack1.isEmpty()) {
stack2.offerFirst(stack1.pollFirst());
}
}
//出栈
return stack2.pollFirst();
}
}
/**
* Your CQueue object will be instantiated and called as such:
* CQueue obj = new CQueue();
* obj.appendTail(value);
* int param_2 = obj.deleteHead();
*/
时间复杂度:O(N)
空间复杂度:O(N)
2.包含min函数的栈

思想:
主要是min函数的实现。
可以通过一个单调栈去维护整个堆栈的最小值:
- push时,只有单调栈为空 || 单调栈栈顶元素大于等于x的时候,单调栈才会插入
- pop时,原栈弹出元素的时候要考虑单调栈栈顶元素,如果是同一个元素需要都弹出
注意:push等于栈顶元素的时候是需要压栈的
class MinStack {
//存放元素的栈
private Deque<Integer> stack;
//维持单调栈,栈顶是最小元素
private Deque<Integer> deque;
/** initialize your data structure here. */
public MinStack() {
stack = new LinkedList<>();
deque = new LinkedList<>();
}
public void push(int x) {
stack.offerFirst(x);
//当单调栈为空或者x小于等于栈顶元素的时候才会压入
if (deque.isEmpty() || (deque.peekFirst() >= x)) {
deque.offerFirst(x);
}
}
public void pop() {
Integer popNum = stack.pollFirst();
//当出栈元素是单调栈栈顶元素,同时弹出
if (Objects.equals(popNum, deque.peekFirst())) {
deque.pollFirst();
}
}
public int top() {
return stack.peekFirst();
}
public int min() {
return deque.peekFirst();
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(x);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.min();
*/
时间复杂度:O(1)
空间复杂度:O(N),当共有N 个待入栈元素时,辅助栈最差情况下存储N 个元素。
最开始这样写的,错误思想:
push元素到单调栈的时候,从队尾入队,并且会将比它大的元素都弹出。这样的话,会出现原栈元素还没有pop完,但是单调栈的元素已经空了,会在min函数出现空指针异常。
class MinStack {
//存放元素的栈
private Deque<Integer> stack;
//维持单调栈,栈顶是最小元素
private Deque<Integer> deque;
/** initialize your data structure here. */
public MinStack() {
stack = new LinkedList<>();
deque = new LinkedList<>();
}
public void push(int x) {
stack.offerFirst(x);
//当单调栈不空时,从栈底弹出比x大的元素(等于的不能弹出)
while (!deque.isEmpty() && (deque.peekLast() > x)) {
deque.pollLast();
}
deque.offerFirst(x);
}
public void pop() {
Integer popNum = stack.pollFirst();
//当出栈元素是单调栈栈顶元素,同时弹出
if (Objects.equals(popNum, deque.peekFirst())) {
deque.pollFirst();
}
}
public int top() {
return stack.peekFirst();
}
public int min() {
return deque.peekFirst();
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(x);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.min();
*/
(二)链表
1.从尾到头打印链表

思想:
- 倒序使用堆栈后入先出
- 倒序使用递归
方法一:堆栈
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public int[] reversePrint(ListNode head) {
//特殊情况
if (head == null) {
return new int[0];
}
Deque<Integer> stack = new LinkedList<>();
//反序存储
while (head != null) {
stack.offerFirst(head.val);
head = head.next;
}
int[] result = new int[stack.size()];
int i = 0;
//正序释放
while (!stack.isEmpty()) {
result[i++] = stack.pollFirst();
}
return result;
}
}
时间复杂度:O(N)
空间复杂度:O(N)
方法二:递归
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
//记录倒序数组
private ArrayList<Integer> list;
public int[] reversePrint(ListNode head) {
list = new ArrayList<>();
//递归到数组末尾返回
dfs(head);
//构造结果数组
int[] result = new int[list.size()];
int index = 0;
while (index < list.size()) {
result[index] = list.get(index);
index++;
}
return result;
}
public void dfs(ListNode head) {
if (head == null) {
return;
}
dfs(head.next);
//返回的时候塞入当前节点的值(倒序)
list.add(head.val);
}
}
时间复杂度:O(N)
空间复杂度:O(N)
注意:arrayList使用toArray()方法转换为数组,在字符串情况下可以。
int[], Integer[], List, List 互相转换
2.反转链表
思想:
- 栈
- 原地修改指针指向:遍历链表,生成一个ansNode节点,始终指向原链表的前一个节点,在每一个节点处更新当前节点的指向(当前节点指向前驱节点)和前驱节点指向。注意:要提前记录后继节点
- 递归:深度遍历到尾节点,此时的head节点就是上一层节点,更新指向(前驱节点和后继节点)
方法一:原地方法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
if (head == null) {
return null;
}
ListNode curNode = head;
ListNode ansNode = null;
while (curNode != null) {
ListNode nextNode = curNode.next;
curNode.next = ansNode;
ansNode = curNode;
curNode = nextNode;
}
return ansNode;
}
}
时间复杂度:O(N)
空间复杂度:O(1)
方法二:递归
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
//head == null:初始链表为空
//head.next == null:到尾节点返回
if (head == null || head.next == null) {
return head;
}
//一直是尾节点(新的头结点)
ListNode newHead = reverseList(head.next);
head.next.next = head;
head.next = null;
return newHead;
}
}
时间复杂度:O(N)
空间复杂度:O(N)
3.复杂链表的复制

思想:
这题如果没有random指针,复制链表会很方便,直接逐节点遍历新建节点就行,因为旧链表的遍历顺序就是新链表的节点顺序。
有random指针的时候,需要当前节点的random指向所在链表的节点而不是新建的节点,这样就需要使用某种方法去记录所有节点,以备后续节点的random指向,所以这是难点。
- 哈希表对新旧节点进行存储,后续再遍历拼接
- 合并链表,添加各节点的random指向,再拆分(很巧妙)
最开始我是这样写的:
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
if (head == null) {
return null;
}
Node newHead = new Node(head.val);
Node dummy = new Node(-1);
dummy.next = newHead;
Node curNode = head;
while (curNode != null) {
Node postNode = curNode.next;
Node randomNode = curNode.random;
Node newPostNode = postNode == null ? null : new Node(postNode.val);
Node newRandomNode = randomNode == null ? null : new Node(randomNode.val);
newHead.next = newPostNode;
newHead.random = newRandomNode;
newHead = newHead.next;
curNode = curNode.next;
}
return dummy.next;
}
}
控制台输出:

因为这样写的话,random指向的都是新的节点,而不是链表中的节点。
方法一:哈希表
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
//特殊条件判断
if (head == null) {
return null;
}
Map<Node, Node> map = new HashMap<>();
Node curNode = head;
//遍历映射新老链表节点
while (curNode != null) {
map.put(curNode, new Node(curNode.val));
curNode = curNode.next;
}
curNode = head;
//遍历确定新链表的指向
while (curNode != null) {
map.get(curNode).next = map.get(curNode.next);
map.get(curNode).random = map.get(curNode.random);
curNode = curNode.next;
}
return map.get(head);
}
}
时间复杂度:O(N)
空间复杂度:O(N)
方法二:拼接+合并
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
//特殊条件处理
if (head == null) {
return null;
}
Node curNode = head;//旧链表
//合并新老链表,记录各节点的地址
while (curNode != null) {
//新建当前节点值的节点
Node node = new Node(curNode.val);
//插入node
node.next = curNode.next;
curNode.next = node;
//更新当前节点
curNode = node.next;
}
curNode = head;//旧链表
//构建新链表的random指向
while (curNode != null) {
if (curNode.random != null) {
curNode.next.random = curNode.random.next;
}
curNode = curNode.next.next;
}
curNode = head.next;//新链表
Node pre = head;//旧链表
Node resNode = head.next;//新链表头结点
//拆分新旧链表
while (curNode.next != null) {
pre.next = pre.next.next;
curNode.next = curNode.next.next;
pre = pre.next;
curNode = curNode.next;
}
//更新旧链表尾节点指向
pre.next = null;
return resNode;
}
}
时间复杂度:O(N)
空间复杂度:O(1):结果不算在空间复杂度中,且只有常数级的引用占用空间
(三)字符串
1.替换空格

思想:
总而言之,就是模式识别进行替换
- 在遍历原字符串时,以可变的StringBuilder分两种情况进行添加字符
- 以字符数组进行识别替换
方法一:字符数组
class Solution {
public String replaceSpace(String s) {
int len = s.length();
char[] chs = s.toCharArray();
char[] result = new char[len*3];
int size = 0;
for (int i = 0; i < len; i++) {
if (chs[i] == ' ') {
result[size++] = '%';
result[size++] = '2';
result[size++] = '0';
} else {
result[size++] = chs[i];
}
}
return new String(result, 0, size);
}
}
时间复杂度:O(N)
空间复杂度:O(N)
方法二:Stringbuilder
class Solution {
public String replaceSpace(String s) {
int len = s.length();
StringBuilder result = new StringBuilder();
for (int i = 0; i < len; i++) {
char ch = s.charAt(i);
if (ch == ' ') {
result.append("%20");
} else {
result.append(ch);
}
}
return result.toString();
}
}
时间复杂度:O(N)
空间复杂度:O(N)
2.翻转单词顺序
思想:通过空格来识别单词,同步地将单词加入到结果中。
- 双指针:通过双指针的移动来标识单词的开头和结尾位置
- 分割成字符串数组进行识别
注意:字符串边缘的空格要提前去除(trim)
方法一:双指针
class Solution {
public String reverseWords(String s) {
//特殊情况
if (s.length() == 0) {
return "";
}
//去除两边空格
String strs = s.trim();
int len = strs.length();
//字符串题目可以考虑用额外的字符串去存储结果,而不一定需要在本身上修改
StringBuilder result = new StringBuilder();
//前指针
int i = len - 1;
//后指针
int j = i;
while (i >= 0) {
//从单词的末尾找到第一个空格
//这里(i >= 0)是必须的,因为当添加过原字符串的第一个单词之后,下面的循环不起作用,i==0,然后下轮循环继续,如果没有这个条件,那i就会为-1,越界
//大while的条件并不能阻挡
while ((i >= 0) && strs.charAt(i) != ' ') {
i--;
}
//添加子字符串
result.append(strs.substring(i+1,j+1) + " ");
//跳过空格
while ((i >= 0) && strs.charAt(i) == ' ') {
i--;
}
//更新后指针,此时两个指针都位于新单词的末尾
j = i;
}
//trim是因为最后一个单词会有空格
return result.toString().trim();
}
}
时间复杂度:O(N)
空间复杂度:O(N)
方法二:字符串数组
class Solution {
public String reverseWords(String s) {
if (s.length() == 0) {
return "";
}
//去除边缘的多余空格
String ss = s.trim();
//根据空格分割,strs只会存在单词和""两种元素
String[] strs = ss.split(" ");
StringBuilder result = new StringBuilder();
//识别,添加到结果
for (int i = strs.length-1; i >= 0; i--) {
if (!Objects.equals(strs[i], "")) {
result.append(strs[i] + " ");
}
}
//trim()因为最后一个单词会有个空格
return result.toString().trim();
}
}
时间复杂度:O(N)
空间复杂度:O(N)
(四)查找算法
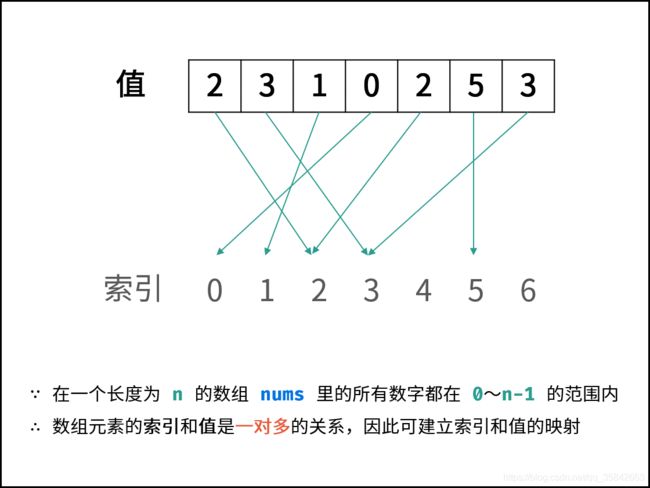
1.数组中重复的数字

思想:
哈希和排序就不说了
- 利用Set不可存储重复元素的特性进行解题 ->重复想到使用set
- 原地交换:注意题目中的条件,说明索引和数值是一对多的关系
方法一:set
class Solution {
public int findRepeatNumber(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int num : nums) {
if (!set.add(num)) {
return num;
}
}
return -1;
}
}
时间复杂度:O(N)
空间复杂度:O(N)
方法二:原地交换
class Solution {
public int findRepeatNumber(int[] nums) {
int len = nums.length;
for (int i = 0; i < len; i++) {
//这个条件很重要,当前元素不匹配就不停地交换,这样可以避免漏掉重复元素,见下例
while (nums[i] != i) {
//重复元素
if (nums[i] == nums[nums[i]]) {
return nums[i];
}
//元素交换使得索引和元素匹配
int tmp = nums[i];
nums[i] = nums[tmp];
nums[tmp] = tmp;
}
}
return -1;
}
}
时间复杂度:O(N)
空间复杂度:O(1)
补充例子:
[3,4,2,0,0,1]
如果没有循环:
- 042301
- 002341
- 002341(此时就会返回)
2.在排序数组中查找数字

思想:
归根结底就是查找数组中有多少个target。
- 遍历:可以暴力遍历统计或者双指针停在target处
- 二分查找:由于排序好的数组,所以想到二分查找,查找左右边界
方法一:暴力统计
class Solution {
public int search(int[] nums, int target) {
if (nums.length == 0)
return 0;
int cnt = 0;
for (int i = 0; i < nums.length; i++){
//数组中没有target,提前返回
if (cnt == 0 && nums[i] > target)
break;
if (nums[i] == target){
cnt++;
}
}
return cnt;
}
}
时间复杂度:O(N)
空间复杂度:O(1)
方法二:双指针
class Solution {
public int search(int[] nums, int target) {
int len = nums.length;
if (len == 0) {
return 0;
}
//前后指针
int left = 0;
int right = len - 1;
//左指针停在等于或者大于target的位置
while ((left <= (len-1)) && nums[left] < target) {
left++;
}
//右指针停在等于或者小于target的位置
while ((right >= 0) && nums[right] > target) {
right--;
}
//1.left > right:要找的target不存在
//2.(left > (len-1)) || (right < 0):target大于数组所有元素||小于数组所有元素
if (left > right || (left > (len-1)) || (right < 0)) {
return 0;
}
return right-left+1;
}
}
时间复杂度:O(N)
空间复杂度:O(1)
如果target存在的话,left和right都会停在target处
不存的话,left大于target索引,right小于target索引,所以会被if捕获
方法三:左右边界
class Solution {
public int search(int[] nums, int target) {
int len = nums.length;
if (len == 0) {
return 0;
}
int i = 0;
int j = len-1;
//寻找右边界:找到和target最接近的大数
while (i <= j) {
int mid = i + (j - i) / 2;
//移动右边界->减小nums[mid]
if (nums[mid] > target) {
j = mid - 1;
//移动左边界->增大nums[mid]
} else if (nums[mid] < target) {
i = mid + 1;
//相等的时候,我们要找大于target的索引,所以移动左边界
} else if (nums[mid] == target) {
i = mid + 1;
}
}
//循环结束时,left > right, left位于右边界,right位于target
int right = i;
//target不存在就提前返回
//j >= 0是因为有可能第一个数
if (j >= 0 && nums[j] != target) {
return 0;
}
i = 0;
//j不要这样设置,可以缩小下面二分查找的区间
//j = len - 1;
//寻找左边界:找到和target最接近的小数
while (i <= j) {
int mid = i + (j - i) / 2;
//移动右边界->减小nums[mid]
if (nums[mid] > target) {
j = mid - 1;
//移动左边界->增大nums[mid]
} else if (nums[mid] < target) {
i = mid + 1;
//相等的时候,我们要找小于target的索引,所以移动右边界
} else if (nums[mid] == target) {
j = mid - 1;
}
}
int left = j;
return right - left - 1;
}
}
时间复杂度:O(logN)
空间复杂度:O(1)
这里要注意的几点是:
- 当target小于或者大于数组中的全部元素时,第二次二分查找后的i,j的位置和第一次一样,且右边界或者左边界会超界,算出来为0(没有提前判断返回)
- 找完右边界之后的if中的j>=0是要保证索引合法,因为正如上述所说,左边界可能会越界,如果j==-1,那么nums[-1]会抛出异常
- 两个边界查找的区别在于,当中位数和target的处理:
(1)查找右边界时,我们要找较大数,所以通过移动左边界进行扩大中位数
(2)查找左边界时,我们要找较小数,所以通过移动右边界进行减小中位数
方法四:二分查找(改进)
可以通过复用查找右边界的代码去查找target-1的右边界
class Solution {
public int search(int[] nums, int target) {
if (nums.length == 0) {
return 0;
}
return helper(nums, target) - helper(nums, target-1);
}
public int helper(int[] nums, int target) {
int i = 0;
int j = nums.length - 1;
while (i <= j) {
int mid = i + (j - i) / 2;
if (nums[mid] > target) {
j = mid - 1;
} else if (nums[mid] < target) {
i = mid + 1;
} else if (nums[mid] == target) {
i = mid + 1;
}
}
return i;
}
}
时间复杂度:O(logN)
空间复杂度:O(1)
3.0~1中缺失的数字

思想:
二分查找右边界
class Solution {
public int missingNumber(int[] nums) {
int len = nums.length;
int left = 0;
int right = len - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
//说明当前索引及其之前的索引都是匹配的,所以移动左边界
if (mid == nums[mid]) {
left = mid + 1;
//当前值大于索引,说明出错在左边,所以移动小右边界
} else if (mid < nums[mid]){
right = mid - 1;
}
}
//因为类似于找右边界,left最后停在较大处
return left;
}
}
注意:不存在mid > nums[mid]的情况
时间复杂度:O(logN)
空间复杂度:O(1)
4.第一次只出现一次的字符
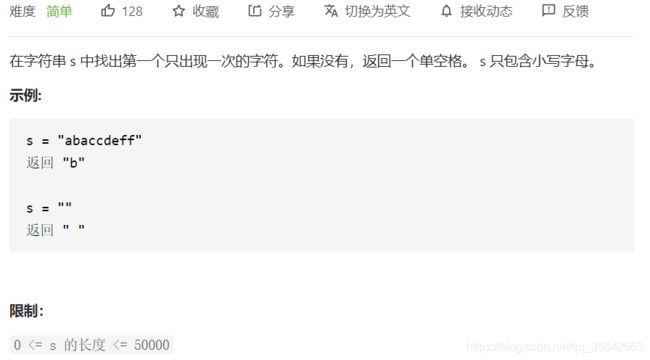
思想:
哈希统计就不说了。
可以通过ASCII值对int数组的累积值进行判断,遇到一次相应字符索引位的值就加一,最后遍历字符串,最先出现1的字符就是结果。
class Solution {
public char firstUniqChar(String s) {
if (s.length() == 0) {
return ' ';
}
int[] arr = new int[26];
char[] chs = s.toCharArray();
for (char ch : chs) {
arr[ch - 'a'] ++;
}
for (char ch : chs) {
if(arr[ch - 'a'] == 1) {
return ch;
}
}
return ' ';
}
}
注意题目要求的是第一次出现,也就是要求顺序性,int[]不能保证顺序性,所以第二次遍历不能使用int[].
时间复杂度:O(N)
空间复杂度:O(1)
5.旋转数组的最小数字

思想:
- 基本思想就是遍历,也可以通过题意发现第一个下降点就是最小值
- 二分法:
(1)num[mid] > num[right]时,说明最小值在mid右边,所以left=mid+1
(2)num[mid] < nums[right]时,说明最小值在mid左边,但要注意,nuns[right]肯定是大于等于最小值的,所以num[mid] 也可能是最小值,不能再区间中去除mid这个点,所以right=mid
(3)num[mid] = nums[right]时,不确定最小值的位置,最小值肯定是比右端点小的,所以进行右边界缩小。
方法一:遍历
class Solution {
public int minArray(int[] numbers) {
int min = Integer.MAX_VALUE;
for (int number : numbers) {
if (number < min) {
min = number;
}
}
return min;
}
}
时间复杂度:O(N)
空间复杂度:O(1)
方法二:数学规律
class Solution {
public int minArray(int[] numbers) {
for (int i = 1; i < numbers.length; i++){
if (numbers[i] < numbers[i-1])
return numbers[i];
}
//数组未旋转
return numbers[0];
}
}
时间复杂度:O(N)
空间复杂度:O(1)
方法三:二分法
class Solution {
public int minArray(int[] numbers) {
int len = numbers.length;
int left = 0;
int right = len-1;
while (left < right) {
int mid = left + (right - left) / 2;
if (numbers[mid] > numbers[right]) {
left = mid + 1;
} else if (numbers[mid] < numbers[right]) {
right = mid;
} else if (numbers[mid] == numbers[right]) {
right--;
}
}
return numbers[right];
}
}
时间复杂度:O(logN)
空间复杂度:O(1)
6.二维数组中的查找

思想:

class Solution {
public boolean findNumberIn2DArray(int[][] matrix, int target) {
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return false;
}
int rows = matrix.length;
int cols = matrix[0].length;
int row = 0;
int col = cols - 1;
while (row < rows && col >= 0) {
if (matrix[row][col] == target) {
return true;
} else if (matrix[row][col] > target) {
col--;
} else if (matrix[row][col] < target) {
row++;
}
}
return false;
}
}
时间复杂度:O(m+n)
空间复杂度:O(1)
(五)搜索与回溯算法
1. 从上到下打印二叉树I

层序遍历:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int[] levelOrder(TreeNode root) {
if (root == null) {
return new int[0];
}
Queue<TreeNode> queue = new LinkedList<>();
List<Integer> list = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
int size = list.size();
int[] result = new int[size];
for (int i = 0; i < size; i++) {
result[i] = list.get(i);
}
return result;
}
}
时间复杂度 O(N) : N为二叉树的节点数量,即 BFS 需循环 N次。
空间复杂度 O(N): 最差情况下,即当树为平衡二叉树时,最多有N/2 个树节点同时在 queue 中,使用O(N)大小的额外空间。
2. 从上到下打印二叉树Ⅱ

层序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<List<Integer>>();
if (root == null) {
return result;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
List<Integer> list = new ArrayList<>();
int size = queue.size();
while ((size--) > 0) {
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
result.add(list);
}
return result;
}
}
时间复杂度 O(N) : NN 为二叉树的节点数量,即 BFS 需循环 N次。
空间复杂度 O(N): 最差情况下,即当树为平衡二叉树时,最多有N/2 个树节点同时在 queue 中,使用O(N)大小的额外空间。
3.从上到下打印二叉树Ⅲ

层序遍历:
主要是要通过判断层数去进行集合翻转,可以自己定义level变量也可以使用结果集合中的元素个数作为隐藏层数条件。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<List<Integer>>();
if (root == null) {
return result;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
List<Integer> list = new ArrayList<>();
int size = queue.size();
while ((size--) > 0) {
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
//result已经隐含了层数
if ((result.size() & 1) == 1) {
Collections.reverse(list);
}
result.add(list);
}
return result;
}
}
时间复杂度 O(N) : NN 为二叉树的节点数量,即 BFS 需循环 N次。
空间复杂度 O(N): 最差情况下,即当树为平衡二叉树时,最多有N/2 个树节点同时在 queue 中,使用O(N)大小的额外空间。
4.树的子结构
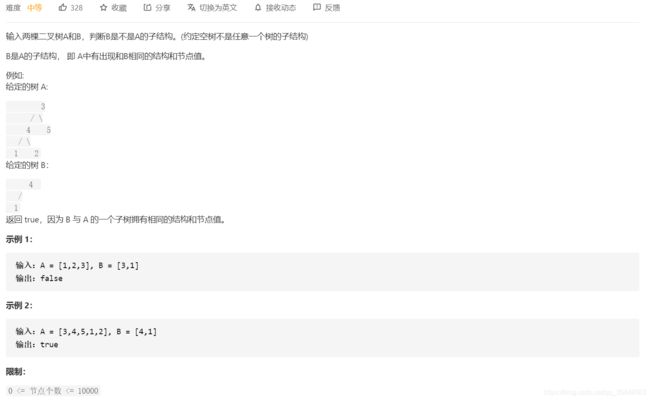
思想:
遍历A树的每个节点,与B的节点进行节点对应比较,只有完全相等的时候才会返回true
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
//特殊情况处理
if (A == null || B == null) {
return false;
}
//subTree(A, B)判断各节点的值是否严格相等
//isSubStructure(A.left, B)先序遍历A树
return subTree(A, B) || isSubStructure(A.left, B) || isSubStructure(A.right, B);
}
public boolean subTree(TreeNode A, TreeNode B) {
//递归运行到B的叶子节点说明遍历的节点都相等
if (B == null) {
return true;
}
//A树已经到叶子节点,B树没有到 || 等价节点不相等
if (A == null || A.val != B.val) {
return false;
}
//递归遍历两棵树剩下的等价节点
return subTree(A.left, B.left) && subTree(A.right, B.right);
}
}
时间复杂度 O(N)
空间复杂度 O(N)
5.二叉树的镜像

方法一:递归:
刚开始我是这样写的
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if (root == null)
return null;
root.left = mirrorTree(root.right);
root.right = mirrorTree(root.left);
return root;
}
}
但是不对,因为第一个递归执行返回的时候,运行当前层第二个递归的时候,root.left已经不是运来的left了。比如,7节点的时候,它的left在第一个递归结束之后变成了9,后来运行第二个递归,此时root.left不是原来的6了,而是9,所以不对,可以在每一层将left节点存储下来。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if (root == null)
return null;
TreeNode tmp = root.left;
root.left = mirrorTree(root.right);
root.right = mirrorTree(tmp);
return root;
}
}
更通俗易懂的就是:
public TreeNode mirrorTree(TreeNode root) {
if (root == null) {
return null;
}
TreeNode leftRoot = mirrorTree(root.right);
TreeNode rightRoot = mirrorTree(root.left);
root.left = leftRoot;
root.right = rightRoot;
return root;
}
时间复杂度:O(n)
空间复杂度:O(n)
方法二:辅助队列
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if (root == null)
return null;
Deque<TreeNode> stack = new LinkedList<>();
stack.offerFirst(root);
while (!stack.isEmpty()){
TreeNode node = stack.pollFirst();
if (node.left != null){
stack.offerFirst(node.left);
}
if (node.right != null){
stack.offerFirst(node.right);
}
TreeNode tmp = node.left;
node.left = node.right;
node.right = tmp;
}
return root;
}
}
时间复杂度:O(n)
空间复杂度:O(n)
6.对称的二叉树

思想:
链接
对称二叉树定义: 对于树中 任意两个对称节点 L和 R,一定有:
L.val = R.val,L.val=R.val :即此两对称节点值相等。
L.left.val = R.right.val:即 L的 左子节点 和 R的 右子节点 对称;
L.right.val = R.left.val:即 L的 右子节点 和 R的 左子节点 对称。
根据以上规律,考虑从顶至底递归,判断每对节点是否对称,从而判断树是否为对称二叉树。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSymmetric(TreeNode root) {
//根节点为空即为true
if (root == null) {
return true;
}
return recur(root.left, root.right);
}
public boolean recur(TreeNode L, TreeNode R) {
//两棵子树同时越过叶子节点
if (L == null && R == null) {
return true;
}
//只有一棵子树越过叶子节点或者当前对称节点不相等
if (L == null || R == null || L.val != R.val) {
return false;
}
//递归遍历对称节点
return recur(L.left, R.right) && recur(L.right, R.left);
}
}
时间复杂度 O(N) : 其中 N为二叉树的节点数量,每次执行 recur() 可以判断一对节点是否对称,因此最多调用 N/2次recur() 方法。
空间复杂度 O(N) : 最差情况下,二叉树退化为链表,系统使用 O(N)大小的栈空间。
7.矩阵中的路径


思想:
深度优先搜索:暴力遍历矩阵中所有字符串可能性。
DFS 通过递归,先朝一个方向搜到底,再回溯至上个节点,沿另一个方向搜索,以此类推。
class Solution {
public boolean exist(char[][] board, String word) {
char[] chs = word.toCharArray();
int rows = board.length;
int cols = board[0].length;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (dfs(board, chs, i, j, 0)) {
return true;
}
}
}
return false;
}
public boolean dfs(char[][] board, char[] chs, int row, int col, int num) {
if (row < 0 || row >= board.length || col < 0 || col >= board[0].length || board[row][col] != chs[num]) {
return false;
}
if (num == chs.length - 1) {
return true;
}
board[row][col] = '\0';
boolean res = dfs(board, chs, row+1, col, num+1) || dfs(board, chs, row, col+1, num+1) ||
dfs(board, chs, row-1, col, num+1) || dfs(board, chs, row, col-1, num+1);
board[row][col] = chs[num];
return res;
}
}

8.机器人的运动范围

思想:
广度优先搜索,期间使用一个二维数组记录路径进行剪枝,并且只需要进行右下两个方向的搜索即可。
class Solution {
public int movingCount(int m, int n, int k) {
if (k == 0) {
return 1;
}
//广度优先遍历的队列
Queue<int[]> queue = new LinkedList<>();
//记录遍历过的位置的矩阵
boolean[][] visited = new boolean[m][n];
//向右、向下遍历的增量数组
int[] dx = new int[]{1,0};
int[] dy = new int[]{0,1};
//初始化添加原点
queue.offer(new int[]{0,0});
visited[0][0] = true;
//结果:为1是因为原点是ok的
int result = 1;
while (!queue.isEmpty()) {
//取出要移动的节点信息
int[] tmp = queue.poll();
//右、下两个方向遍历
for (int i = 0; i < 2; i++) {
int tx = tmp[0] + dx[i];
int ty = tmp[1] + dy[i];
//非法条件进入下一个节点
if (tx < 0 || tx >= m || ty < 0 || ty >= n || visited[tx][ty] == true || getValue(tx) + getValue(ty) > k) {
continue;
}
//该节点合法
result++;
visited[tx][ty] = true;
queue.offer(new int[]{tx, ty});
}
}
return result;
}
public int getValue(int x) {
int res = 0;
while (x > 0) {
res += x % 10;
x = x / 10;
}
return res;
}
}
时间复杂度:O(mn)
空间复杂度:O(mn)
9.二叉树中和为某一值的路径

思想:
深度优先遍历:枚举每一条从根节点到叶子节点的路径。当我们遍历到叶子节点,且此时路径和恰为目标和时,我们就找到了一条满足条件的路径 -> 前序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
//结果集合
private List<List<Integer>> result = new ArrayList<List<Integer>>();
//路径集合
private List<Integer> path = new ArrayList<>();
public List<List<Integer>> pathSum(TreeNode root, int target) {
//深度优先搜索
dfs(root, target);
return result;
}
public void dfs(TreeNode root, int target) {
if (root == null) {
return;
}
//更新target和路径信息
target -= root.val;
path.add(root.val);
//到达叶子节点且target==0成功
if (root.left == null && root.right == null && target == 0) {
result.add(new ArrayList<Integer>(path));
}
//前序遍历
dfs(root.left, target);
dfs(root.right, target);
//返回上一个节点时,删除当前路径中的本节点
path.remove(path.size()-1);
}
}
时间复杂度:O(N)
空间复杂度:O(N)
10.二叉搜索树与双向链表


思想:
排序的话,二叉搜索树进行中序遍历,在遍历中更改指针
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val,Node _left,Node _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
//结果链表的哑节点
private Node head;
public Node treeToDoublyList(Node root) {
if (root == null) {
return null;
}
head = new Node(-1, null, null);
Node dummy = head;
//中序遍历
dfs(root);
//更改头尾节点指针
dummy.right.left = head;
head.right = dummy.right;
return dummy.right;
}
public void dfs(Node root) {
if (root == null) {
return;
}
dfs(root.left);
//更改节点指向
head.right = root;
root.left = head;
head = root;
dfs(root.right);
}
}
时间复杂度:O(N)
空间复杂度:O(N)
11.二叉搜索树的第K大节点
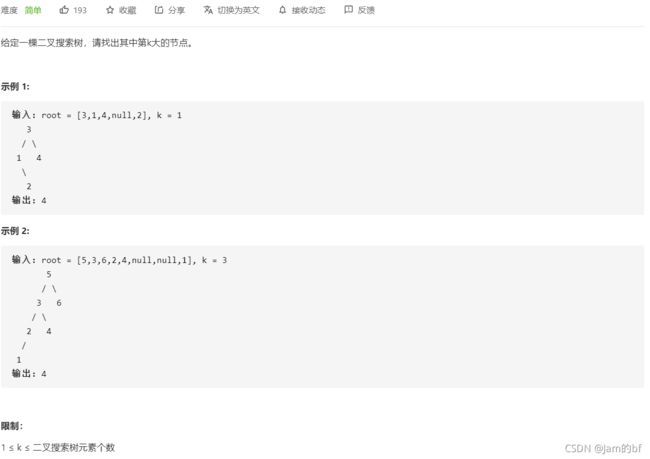
思想:
中序遍历进行倒序遍历,记录k的变化进行封装结果
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int result;
private int cnt;
public int kthLargest(TreeNode root, int k) {
cnt = k;
dfs(root);
return result;
}
public void dfs(TreeNode root) {
if (root == null) {
return;
}
dfs(root.right);
if ((--cnt) == 0) {
result = root.val;
}
dfs(root.left);
}
}
时间复杂度:O(N)
空间复杂度:O(N)
(六)动态规划
1.斐波那契数列

思想:
可以根据递推式进行递归或者DP
方法一:递归(超时)
class Solution {
public int fib(int n) {
if (n == 0 || n == 1) {
return n;
}
return (fib(n-1) + fib(n-2)) % 1000000007;
}
}
方法二:DP
class Solution {
public int fib(int n) {
if (n < 2) {
return n;
}
int[] dp = new int[n+1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = (dp[i-1] + dp[i-2]) % 1000000007;
}
return dp[n];
}
}
方法三:滚动数组(优化DP)
class Solution {
public int fib(int n) {
if (n < 2) {
return n;
}
int a = 0;
int b = 1;
int c = 1;
for (int i = 2; i <= n; i++) {
c = (a + b) % 1000000007;
a = b;
b = c;
}
return c;
}
}
2.青蛙跳台阶问题
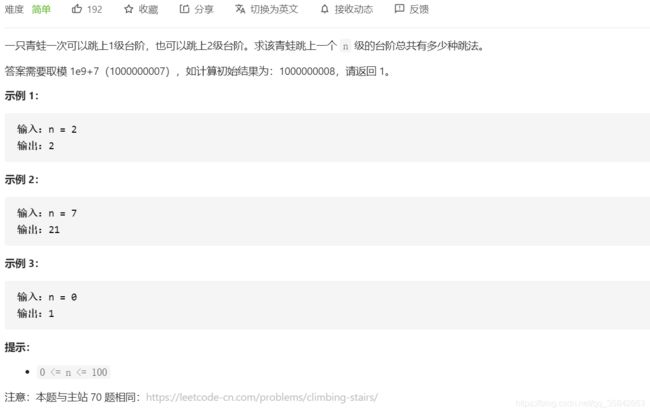
方法一:DP
class Solution {
public int numWays(int n) {
if (n < 2) {
return 1;
}
int[] dp = new int[n+1];
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = (dp[i-1] + dp[i-2]) % 1000000007;
}
return dp[n];
}
}
方法二:滚动数组
class Solution {
public int numWays(int n) {
if (n < 2) {
return 1;
}
int a = 1;
int b = 1;
int c = 1;
for (int i = 2; i <= n; i++) {
c = (a + b) % 1000000007;
a = b;
b = c;
}
return c;
}
}
3.股票的最大利润

思想:
最大利润从较小值之后的最大值与之相减之后得到。
所以需要找到最小值,然后在最小值的基础上判断更新最大利润。
方法一:一次遍历
class Solution {
public int maxProfit(int[] prices) {
if (prices.length == 0) {
return 0;
}
//记录最小价格
int minPrice = Integer.MAX_VALUE;
//记录最大利润
int maxProfit = Integer.MIN_VALUE;
for (int price : prices) {
//寻找最小价格
if (price < minPrice) {
minPrice = price;
}
//实时更新最大利润
if ((price - minPrice) > maxProfit) {
maxProfit = price - minPrice;
}
}
return maxProfit;
}
}
时间复杂度 (N)
空间复杂度: O(1)
方法二:DP
dp[i]代表索引i处的最大利润,是由前一个最大利润和目前的利润值取较大
class Solution {
public int maxProfit(int[] prices) {
int len = prices.length;
if (len == 0) {
return 0;
}
int[] dp = new int[len];
dp[0] = 0;
//注意最小值不能时Integer.MAX_VALUE,因为下面的循环从索引1开始,最小值中没有考虑索引0的值
int min = prices[0];
for (int i = 1; i < len; i++) {
if (min > prices[i]) {
min = prices[i];
}
dp[i] = Math.max(dp[i-1], prices[i] - min);
}
return dp[len-1];
}
}
时间复杂度: O(N)
空间复杂度: O(N)
4.连续子数组的最大和

思想:

方法一:DP
(1)
class Solution {
public int maxSubArray(int[] nums) {
int len = nums.length;
int[] dp = new int[len];
dp[0] = nums[0];
//最大值要考虑首位元素
int maxValue = nums[0];
for (int i = 1; i < len; i++) {
//前一个索引的和小于0就不能给后面带来正面效应,所以不考虑
int tmp = dp[i-1] < 0 ? 0 : dp[i-1];
//计算当前索引位的和
dp[i] = tmp + nums[i];
//更新最大值
maxValue = Math.max(maxValue, dp[i]);
}
return maxValue;
}
}
时间复杂度: O(N)
空间复杂度: O(N)
(2)
class Solution {
public int maxSubArray(int[] nums) {
int len = nums.length;
int[] dp = new int[len];
dp[0] = nums[0];
//最大值要考虑首位元素
int maxValue = nums[0];
for (int i = 1; i < len; i++) {
//计算当前索引位的和
dp[i] = Math.max(dp[i-1] + nums[i], nums[i]);
//更新最大值
maxValue = Math.max(maxValue, dp[i]);
}
return maxValue;
}
}
时间复杂度: O(N)
空间复杂度: O(N)
方法二:滚动数组
class Solution {
public int maxSubArray(int[] nums) {
int len = nums.length;
int a = nums[0];
int b = nums[0];
//最大值要考虑首位元素
int maxValue = nums[0];
for (int i = 1; i < len; i++) {
//计算当前索引位的和
b = Math.max(a + nums[i], nums[i]);
a = b;
//更新最大值
maxValue = Math.max(maxValue, b);
}
return maxValue;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
方法三:原地计算
class Solution {
public int maxSubArray(int[] nums) {
int len = nums.length;
//最大值要考虑首位元素
int maxValue = nums[0];
for (int i = 1; i < len; i++) {
//计算当前索引位的和
nums[i] = Math.max(nums[i-1] + nums[i], nums[i]);
//nums[i] += Math.max(nums[i-1],0);
//更新最大值
maxValue = Math.max(maxValue, nums[i]);
}
return maxValue;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
5.礼物的最大价值
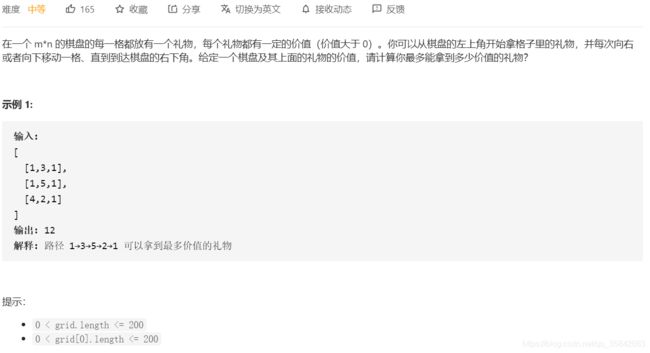
思想:

新建DP数组:
class Solution {
public int maxValue(int[][] grid) {
if (grid == null || grid.length == 0 || grid[0].length == 0) {
return 0;
}
int rows = grid.length;
int cols = grid[0].length;
int[][] dp = new int[rows][cols];
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
//初始化第一个元素
if (row == 0 && col == 0) {
dp[row][col] = grid[row][col];
//第一行
}else if(row == 0) {
dp[row][col] = dp[row][col-1] + grid[row][col];
//第一列
}else if(col == 0) {
dp[row][col] = dp[row-1][col] + grid[row][col];
//其他元素
}else{
dp[row][col] = Math.max(dp[row-1][col], dp[row][col-1]) + grid[row][col];
}
}
}
return dp[rows-1][cols-1];
}
}
时间复杂度: O(MN)
空间复杂度: O(MN)
数组原地修改:
class Solution {
public int maxValue(int[][] grid) {
if (grid == null || grid.length == 0 || grid[0].length == 0) {
return 0;
}
int rows = grid.length;
int cols = grid[0].length;
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
//初始化第一个元素
if (row == 0 && col == 0) {
continue;
//第一行
}else if(row == 0) {
grid[row][col] = grid[row][col-1] + grid[row][col];
//第一列
}else if(col == 0) {
grid[row][col] = grid[row-1][col] + grid[row][col];
//其他元素
}else{
grid[row][col] = Math.max(grid[row-1][col], grid[row][col-1]) + grid[row][col];
}
}
}
return grid[rows-1][cols-1];
}
}
时间复杂度: O(M*N)
空间复杂度: O(1)
当 grid矩阵很大时, i=0 或 j=0 的情况仅占极少数,相当循环每轮都冗余了一次判断。因此,可先初始化矩阵第一行和第一列,再开始遍历递推。
class Solution {
public int maxValue(int[][] grid) {
if (grid == null || grid.length == 0 || grid[0].length == 0) {
return 0;
}
int rows = grid.length;
int cols = grid[0].length;
//先单独处理行
for (int col = 1; col < cols; col++) {
grid[0][col] += grid[0][col - 1];
}
//先单独处理列
for (int row = 1; row < rows; row++) {
grid[row][0] += grid[row-1][0];
}
//处理其他元素
for (int row = 1; row < rows; row++) {
for (int col = 1; col < cols; col++) {
grid[row][col] += Math.max(grid[row-1][col], grid[row][col-1]);
}
}
return grid[rows-1][cols-1];
}
}
时间复杂度: O(M*N)
空间复杂度: O(1)
也可以生成一个多一行多一列的矩阵来简化代码
总体看,每个格子的值都是当前值加上上和右的较大值,因为原数组在边界上没有上或右,所以需要额外讨论。而如果扩充数组,且边界为0,对结果也不影响
class Solution {
public int maxValue(int[][] grid) {
int rows = grid.length;
int cols = grid[0].length;
//dp[i][j]是到grid[i-1][j-1]的最大值
int[][] dp = new int[rows+1][cols+1];
for (int i = 1; i <= rows; i++){//注意等于
for (int j = 1; j <= cols; j++){//注意等于
dp[i][j] = Math.max(dp[i][j-1],dp[i-1][j]) + grid[i-1][j-1];
}
}
return dp[rows][cols];
}
}
时间复杂度: O(MN)
空间复杂度: O(MN)
6.最长不含重复字符的子字符串
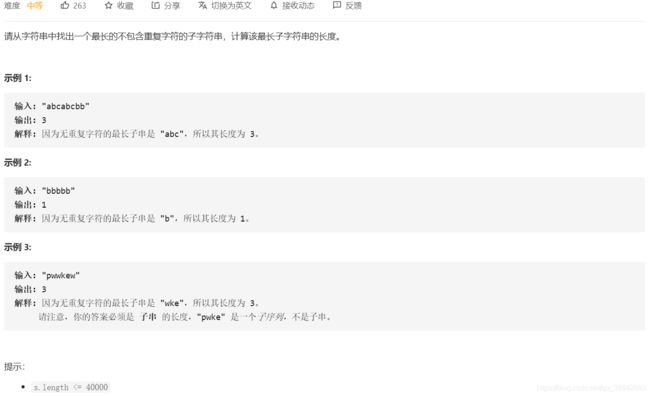
思想:
方法一:DP+哈希表
class Solution {
public int lengthOfLongestSubstring(String s) {
int len = s.length();
//特殊情况处理
if (len == 0) {
return 0;
}
//dp[i]:以i结尾的最长不包含重复字符的子字符串长度
int[] dp = new int[len];
//最短长度为1
dp[0] = 1;
//最短长度为1
int max = 1;
//记录字符索引
Map<Character, Integer> indexMap = new HashMap<>();
char[] chs = s.toCharArray();
//初始塞值
indexMap.put(chs[0], 0);
for (int i = 1; i < len; i++) {
char ch = chs[i];
//获取当前字符历史最新索引,不存在就是-1
int index = indexMap.getOrDefault(ch, -1);
//更新当前字符索引值
indexMap.put(ch, i);
//计算当前字符的距离
int distance = i - index;
//当前字符在区间外
if (dp[i-1] < distance) {
dp[i] = dp[i-1] + 1;
//当前字符在区间中,最长长度由左边界决定
} else if (dp[i-1] >= distance) {
dp[i] = distance;
}
//更新最大值
max = Math.max(max, dp[i]);
}
return max;
}
}
时间复杂度: O(N)
空间复杂度: O(N) :O(N+N)
方法二:滚动数组+哈希表
可以省去初始dp元素的初始化,因为循环从0开始包含了初始化这一步
class Solution {
public int lengthOfLongestSubstring(String s) {
int len = s.length();
int result = 0;
int dpValue = 0;
Map<Character, Integer> indexMap = new HashMap<>();
char[] chs = s.toCharArray();
for (int i = 0; i < len; i++) {
char ch = chs[i];
//获取当前字符历史最新索引,不存在就是-1
int index = indexMap.getOrDefault(ch, -1);
//更新当前字符索引值
indexMap.put(ch, i);
//计算当前字符的距离
int distance = i - index;
//当前字符在区间外
if (dpValue < distance) {
dpValue = dpValue + 1;
//当前字符在区间中,最长长度由左边界决定
} else if (dpValue >= distance) {
dpValue = distance;
}
//更新最大值
result = Math.max(result, dpValue);
}
return result;
}
}
时间复杂度: O(N)
空间复杂度: O(N) (N)
方法三:滚动数组+线性遍历
class Solution {
public int lengthOfLongestSubstring(String s) {
int len = s.length();
int result = 0;
int dpValue = 0;
char[] chs = s.toCharArray();
for (int i = 0; i < len; i++) {
char ch = chs[i];
//获取当前字符历史最新索引,不存在就是-1
int index = i - 1;
while ((index >= 0) && chs[index] != ch) {
index--;
}
//计算当前字符的距离
int distance = i - index;
//当前字符在区间外
if (dpValue < distance) {
dpValue = dpValue + 1;
//当前字符在区间中,最长长度由左边界决定
} else if (dpValue >= distance) {
dpValue = distance;
}
//更新最大值
result = Math.max(result, dpValue);
}
return result;
}
}
时间复杂度: O(N^2)
空间复杂度: O(N)
7.把数字翻译成字符串

思想:

方法一:DP
class Solution {
public int translateNum(int num) {
String s = String.valueOf(num);
int len = s.length();
//dp[i]为到第i位时的翻译数
int[] dp = new int[len+1];
//第0个数
dp[0] = 1;
//第1个数
dp[1] = 1;
for (int i = 2; i <= len; i++) {
String tmp = s.substring(i-2,i);
if (tmp.compareTo("10") >= 0 && tmp.compareTo("25") <= 0) {
dp[i] = dp[i-1] + dp[i-2];
} else {
dp[i] = dp[i-1];
}
}
return dp[len];
}
}
时间复杂度: O(N)
空间复杂度: O(N)
方法二:滚动数组
class Solution {
public int translateNum(int num) {
String s = String.valueOf(num);
int len = s.length();
int a = 1, b = 1, c = 1;
for (int i = 2; i <= len; i++) {
String tmp = s.substring(i-2,i);
if (tmp.compareTo("10") >= 0 && tmp.compareTo("25") <= 0) {
c = a + b;
} else {
c = b;
}
a = b;
b = c;
}
return c;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
(七)双指针
1.删除链表的节点

思想:
主要就是找到要删除节点的前驱节点,然后更新next指向
方法一:迭代
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode deleteNode(ListNode head, int val) {
if (head == null) {
return null;
}
//哨兵,不需要特地讨论头节点
ListNode dummy = new ListNode(-1);
dummy.next = head;
//记录跟踪要删除节点的前驱节点
ListNode preNode = dummy;
while (preNode.next != null) {
ListNode curNode = preNode.next;
if (curNode.val == val) {
preNode.next = curNode.next;
//提前退出
break;
}
preNode = preNode.next;
}
return dummy.next;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
方法二:递归
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode deleteNode(ListNode head, int val) {
if (head == null) {
return null;
}
if (head.val == val) {
return head.next;
}
head.next = deleteNode(head.next, val);
return head;
}
}
时间复杂度: O(N)
空间复杂度: O(N)
2.链表中倒数第k个节点

思想:
找到结果节点或者他的前驱节点
方法一:迭代
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode getKthFromEnd(ListNode head, int k) {
if (head == null) {
return null;
}
ListNode slow = head;
ListNode fast = head;
while ((k--) > 0) {
fast = fast.next;
}
while (fast != null) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
方法二:递归
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
private int index = 0;
public ListNode getKthFromEnd(ListNode head, int k) {
if (head == null) {
return null;
}
ListNode node = getKthFromEnd(head.next, k);
if ((++index) == k) {
return head;
}
return node;
}
}
时间复杂度: O(N)
空间复杂度: O(N)
3.合并两个排序的链表
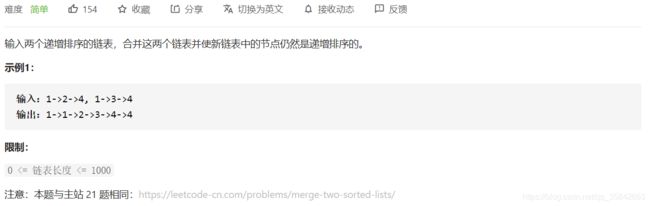
方法一:迭代
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if (l1 == null && l2 == null) {
return null;
}
ListNode dummy = new ListNode(-1);
ListNode newHead = dummy;
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
newHead.next = l1;
l1 = l1.next;
} else{
newHead.next = l2;
l2 = l2.next;
}
newHead = newHead.next;
}
newHead.next = l1 == null ? l2 : l1;
return dummy.next;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
方法二:递归
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if (l1 == null) {
return l2;
} else if (l2 == null) {
return l1;
} else if (l1.val <= l2.val) {
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
}
}
时间复杂度: O(N)
空间复杂度: O(N)
4.两个链表的第一个公共节点
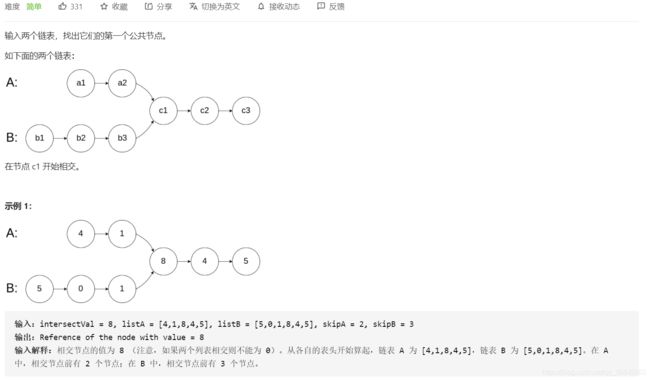


思想:a+b = b + a
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode firstNode = headA;
ListNode secondNode = headB;
while (firstNode != secondNode) {
firstNode = firstNode == null ? headB : firstNode.next;
secondNode = secondNode == null ? headA : secondNode.next;
}
return firstNode;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
5.调整数组顺序使奇数位于偶数前面

思想:
- 定义头指针 left ,尾指针right .
- left一直往右移,直到它指向的值为偶数
- right 一直往左移, 直到它指向的值为奇数
- 交换nums[left] 和nums[right] .
- 重复上述操作,直到left==right .
class Solution {
public int[] exchange(int[] nums) {
int len = nums.length;
if (len == 0) {
return new int[0];
}
int left = 0;
int right = len - 1;
while (left < right) {
//left寻找偶数
while (left < right && ((nums[left] & 1) != 0)) {
left++;
}
//right寻找奇数
while (left < right && ((nums[right] & 1) != 1)) {
right--;
}
// if (left < right) {
swap(nums, left, right);
//交换完之后left肯定在奇数位,right肯定在偶数位
//所以直接更新索引,而不需要到下一次的循环判断
left++;
right--;
// }
}
return nums;
}
public void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
时间复杂度: O(N)
空间复杂度: O(1)
6.和为s的两个数字
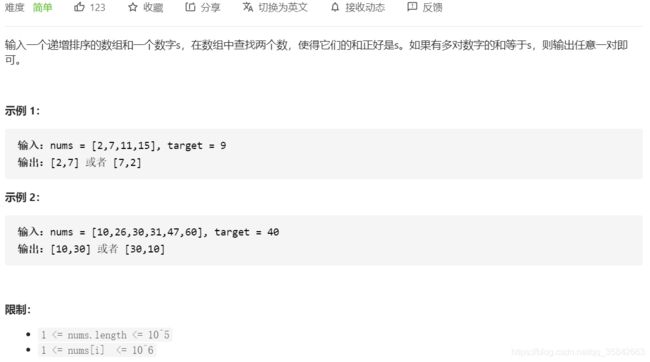
方法一:set
class Solution {
public int[] twoSum(int[] nums, int target) {
Set<Integer> set = new HashSet<>();
for (int num : nums) {
if (set.contains(target - num)) {
return new int[]{num, target - num};
}
set.add(num);
}
return new int[0];
}
}
时间复杂度: O(N)
空间复杂度: O(N)
方法二:双指针
class Solution {
public int[] twoSum(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
while (left < right) {
if (nums[left] + nums[right] > target) {
right--;
} else if (nums[left] + nums[right] < target) {
left++;
} else {
return new int[]{nums[left], nums[right]};
}
}
return new int[0];
}
}
时间复杂度: O(N)
空间复杂度: O(1)
7.和为s的连续正数序列

class Solution {
public int[][] findContinuousSequence(int target) {
List<int[]> res = new ArrayList<>();
//初始区间
int left = 1, right = 2;
while (left < right) {
//区间求和
int sum = (left + right) * (right - left + 1) / 2;
//以当前left起始的区间过大,右移左边界减少数字个数降低区间和
if (sum > target) {
left++;
//.......
} else if (sum < target) {
right++;
} else {
int[] a = new int[right - left + 1];
for (int k = left; k <= right; k++) {
a[k-left] = k;
}
res.add(a);
//换下一个起点
left++;
}
}
return res.toArray(new int[res.size()][]);
}
}
时间复杂度: O(N)
空间复杂度: O(1)
(八)排序
1.把数组排成最小的数

思想:
自定义大小比较:
任意两数字的字符串为 x和y ,则规定排序判断规则为:
若拼接字符串 x + y > y + x,则 x‘’大于‘’ y ;
反之,若 x + y < y + x,则 x“小于” y;
使用快排
class Solution {
public String minNumber(int[] nums) {
int len = nums.length;
String[] strs = new String[len];
for (int i = 0; i < len; i++) {
strs[i] = String.valueOf(nums[i]);
}
quickSort(strs, 0, len - 1);
StringBuilder result = new StringBuilder();
for(String str : strs) {
result.append(str);
}
return result.toString();
}
public void quickSort(String[] strs, int low, int high) {
if (low >= high) {
return;
}
String tmp = strs[low];
int i = low;
int j = high;
while (i < j) {
while (i < j && (strs[j] + tmp).compareTo(tmp + strs[j]) >=0) {
j--;
}
while (i < j && (strs[i] + tmp).compareTo(tmp + strs[i]) <= 0) {
i++;
}
if (i < j) {
String t = strs[i];
strs[i] = strs[j];
strs[j] = t;
}
}
strs[low] = strs[i];
strs[i] = tmp;
quickSort(strs, low, i-1);
quickSort(strs, i+1, high);
}
}
时间复杂度:O(NLogN)
空间复杂度:O(N)
2.扑克牌中的顺子

思想:
遍历五个元素,如果可以形成顺子的话,最大最小值的差小于5
其中,如果有重复元素直接false。
方法一:Set
非排序的话,使用set辅助判断重复元素,遍历过程统计最大最小值
class Solution {
public boolean isStraight(int[] nums) {
Set<Integer> repeat = new HashSet<>();
int max = 0, min = 14;
for(int num : nums) {
if(num == 0) continue; // 跳过大小王
if (!set.add(num))
return false;
max = Math.max(max, num); // 最大牌
min = Math.min(min, num); // 最小牌
}
return max - min < 5; // 最大牌 - 最小牌 < 5 则可构成顺子
}
}
时间复杂度:O(N)
空间复杂度:O(N)
方法二:排序
前后元素判断,大小王的下一个元素就是最小元素
class Solution {
public boolean isStraight(int[] nums) {
Arrays.sort(nums);
int joker = 0;
for (int i = 0; i < 4; i++){
if (nums[i] == 0){
joker++;
continue;
}
if (nums[i] == nums[i+1])
return false;
}
return nums[4] - nums[joker] < 5;
}
}
时间复杂度:O(NLogN)
空间复杂度:O(1)
3.最小的k个数

方法一维护最大堆
优先队列,先构造大根堆,然后前k个数加入队列,后面的数只有小于堆顶就加进队列,最后的队列就是最小的5个数
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
int[] res = new int[k];
if (k == 0)
return res;
PriorityQueue<Integer> priqueue = new PriorityQueue<Integer>(new Comparator<Integer>(){
public int compare(Integer num1, Integer num2){
return num2 - num1;//降序排序
}
});
for (int i = 0; i < k; i++){
priqueue.offer(arr[i]);
}
for (int i = k; i < arr.length; i++){
if (priqueue.peek() > arr[i]){
priqueue.poll();
priqueue.offer(arr[i]);//只有小于的时候再加入
}
}
for (int i = 0; i < k; i++){
res[i] = priqueue.poll();
}
return res;
}
}
时间复杂度:O(nlogk),其中n是数组 arr 的长度。由于大根堆实时维护前 k小值,所以插入删除都是O(logk) 的时间复杂度,最坏情况下数组里 n个数都会插入,所以一共需要O(nlogk) 的时间复杂度。
空间复杂度:O(k),因为大根堆里最多 k个数。
方法二:快排
快排的划分函数每次执行完后都能将数组分成两个部分,小于等于分界值 pivot 的元素的都会被放到数组的左边,大于的都会被放到数组的右边,然后返回分界值的下标。
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
quickSortPost(arr, 0, arr.length - 1, k);
int[] res = new int[k];
for (int i = 0; i < k; i++){
res[i] = arr[i];
}
return res;
}
public void quickSortPost(int[] arr, int low, int high, int k){
if (low >= high)
return;
int position = getIndex(arr,low,high);
int num = position - low + 1;//基准现在是第num大小
if (k == num)
return;
else if (k < num){//第k大数在左边
quickSortPost(arr,low,position-1,k);//在右边找第k大
}
else if (k > num){//第k大数在右边
quickSortPost(arr,position+1, high, k-num);//在右边找第k-num大
}
}
public int getIndex(int[] arr, int low, int high){
int i = low;
int j = high;
int temp = arr[low];
while (i < j){
while (i < j && arr[j] >= temp)
j--;
while (i < j && arr[i] <= temp)
i++;
if (i < j){
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
}
arr[low] = arr[i];
arr[i] = temp;
return i;
}
}
时间复杂度 O(N)
空间复杂度 O(logN)
(九)数学
1.数组中数字超过一半的数字 10.27
摩尔投票法:
class Solution {
public int majorityElement(int[] nums) {
int res = Integer.MAX_VALUE;
int vote = 0;
for (int num : nums) {
if (vote == 0) {
res = num;
}
vote += res == num ? 1 : -1;
}
return res;
}
}
2.求解数组中出现次数超过1/3的那个数
https://zhuanlan.zhihu.com/p/125232442
https://blog.csdn.net/weixin_42970433/article/details/111504896
测试用例:
1 1 1 1 1 2 2 3 3 4 4 5
输入:
[1,1,1,3,3,2,2,2]
输出:
[1,2]
如果存在某个数超过 1/3 ,那我们每次删掉三个不同的数,直到最后没法删,最后剩下的数一定有这个超过 1/3 的数。原因很简单,因为每删一次最多删掉一个这个数,而删除最多 1/3 数组长度次之后所有数都被删光了,但是这个数还剩下一点。
所以我们用两个变量 cand1 和 cand2 表示两个候选人,cnt1 和 cnt2 表示两个候选人数量。那么如果两个候选人有一个和当前数 x 相同,对应的数量就加一。否则的话如果如果有某个候选人为空,就让 x 顶替成为新的候选人。否则的话就说明两个候选人都有,并且 x 和它俩都不相同,那么就同时删除三个不同的数,也就是两个候选人数量各减一,同时删去 x 。
最后判断两个候选人数量是否超过了 1/3 就行了。
public List<Integer> numsSelect(int[] nums) {
List<Integer> res = new ArrayList<>();
int a = nums[0];
int b = nums[0];
int votea = 0;
int voteb = 0;
for (int num : nums) {
if (num == a) {
votea++;
continue;
}
if (num == b) {
voteb++;
continue;
}
if (votea == 0) {
a = num;
votea++;
continue;
}
if (voteb == 0) {
b = num;
voteb++;
continue;
}
votea--;
voteb--;
}
votea = 0;
voteb = 0;
for (int num : nums) {
if (num == a) {
votea++;
} else if (num == b) {
voteb--;
}
}
if (votea > nums.length / 3) {
res.add(a);
}
if (voteb > nums.length / 3) {
res.add(b);
}
return res;
}
public int numDecodings(String s) {
int len = s.length();
int[] dp = new int[len];
if ((s.charAt(0) - '0') < 1) {
dp[0] = 0;
} else {
dp[0] = 1;
}
for (int i = 1; i < len; i++) {
String ss = s.substring(i - 1, i + 1);
int num = Integer.parseInt(ss);
if (num > 10 && num <= 26) {
dp[i] = dp[i - 1] + 1;
} else {
dp[i] = dp[i - 1];
}
if ((num == 10 || num == 20) && i >= 2 && Integer.parseInt(s.substring(i - 2, i)) > 10 && Integer.parseInt(s.substring(i - 2, i)) <= 26) {
dp[i]--;
}
}
return dp[len - 1];
}