segment-anything使用说明
文章目录
- 一. segment-anything介绍
- 二. 官网Demo使用说明
- 三. 安装教程
- 四. python调用生成掩码教程
- 五. python调用SAM分割后转labelme数据集
一. segment-anything介绍
Segment Anything Model(SAM)根据点或框等输入提示生成高质量的对象遮罩,可用于为图像中的所有对象生成掩膜。

二. 官网Demo使用说明
- 官网Demo地址:https://segment-anything.com/demo
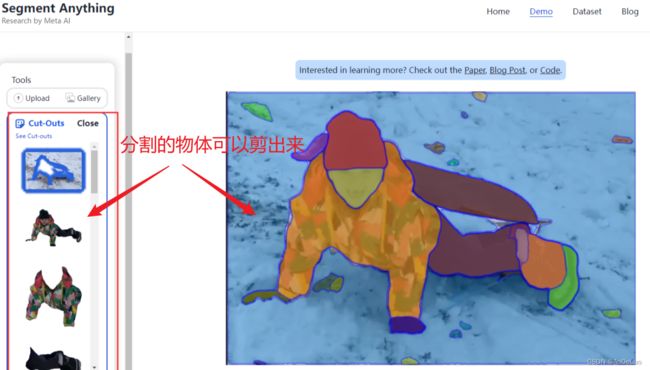
- 载入图像后,可以通过点击图像上一点分割出物体
- 也可以通过框选一个区域进行分割
- 可以一键分割出所有物体
- 可以将分割出来的物体剪出来
三. 安装教程
官网安装说明:https://github.com/facebookresearch/segment-anything
-
anaconda下新建一个环境
conda create -n pytorch python=3.8
-
激活新建的环境
conda activate sam

-
更换conda镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
-
安装pytorch
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3
-
克隆官方代码
git clone [email protected]:facebookresearch/segment-anything.git
-
进入下载好的文件夹,打开cmd,激活安装好的环境,运行以下代码
pip install -e .

-
安装所需python库
pip install opencv-python pycocotools matplotlib onnxruntime onnx -i https://mirrors.aliyun.com/pypi/simple/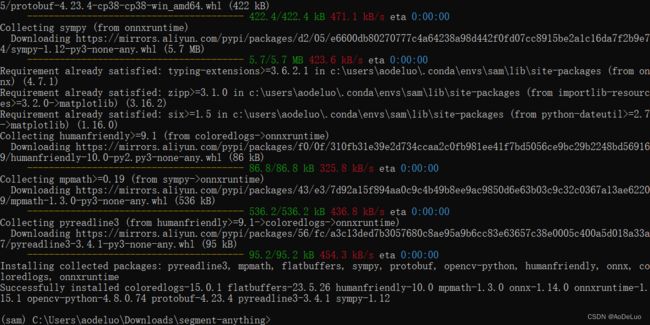
-
从官网下载模型,并复制到源代码下
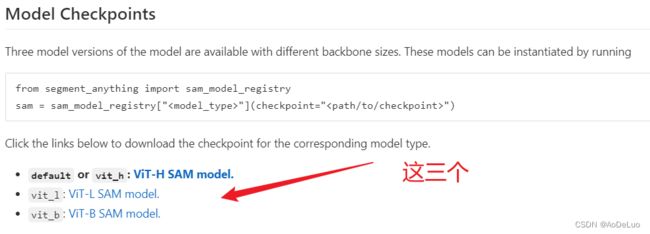

-
运行以下代码
1.png为放置在源代码下的图像python scripts/amg.py --checkpoint sam_vit_b_01ec64.pth --model-type vit_b --input 1.jpg --output result
生成的图像掩码

四. python调用生成掩码教程
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
import sys
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
def show_anns(anns):
if len(anns) == 0:
return
# 对检测结果的字典对象进行排序
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img[:,:,3] = 0
for ann in sorted_anns:
m = ann['segmentation']
color_mask = np.concatenate([np.random.random(3), [0.35]])
img[m] = color_mask
ax.imshow(img)
# 通过opencv图取图像
image = cv2.imread('4.PNG')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 通过plt显示读取的图像
plt.figure(figsize=(20,20))
plt.imshow(image)
plt.axis('off')
plt.show()
# 添加当前系统路径,添加模型文件路径
sys.path.append("..")
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
# 设置运行推理的设备
device = "cuda"
# 创建sam模型推理对象
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
# 将图像送入推理对象进行推理分割,输出结果为一个列表,其中存的每个字典对象内容为:
# segmentation : 分割出来的物体掩膜(与原图像同大小,有物体的地方为1其他地方为0)
# area : 物体掩膜的面积
# bbox : 掩膜的边界框(XYWH)
# predicted_iou : 模型自己对掩模质量的预测
# point_coords : 生成此掩码的采样输入点
# stability_score : 掩模质量的一个附加度量
# crop_box : 用于以XYWH格式生成此遮罩的图像的裁剪
masks = mask_generator.generate(image)
# 打印分割出来的个数以及第一个物体信息
print(len(masks))
print(masks[0].keys())
# 给分割出来的物体上色,显示分割效果
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()
五. python调用SAM分割后转labelme数据集
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
import json
import sys
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
def segment(imgPath):
# 通过opencv图取图像
image = cv2.imread(imgPath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 通过plt显示读取的图像
# plt.figure(figsize=(20,20))
# plt.imshow(image)
# plt.axis('off')
# plt.show()
# 添加当前系统路径,添加模型文件路径
sys.path.append("..")
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
# 设置运行推理的设备
device = "cuda"
# 创建sam模型推理对象
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
# 将图像送入推理对象进行推理分割,输出结果为一个列表,其中存的每个字典对象内容为:
# segmentation : 分割出来的物体掩膜(与原图像同大小,有物体的地方为1其他地方为0)
# area : 物体掩膜的面积
# bbox : 掩膜的边界框(XYWH)
# predicted_iou : 模型自己对掩模质量的预测
# point_coords : 生成此掩码的采样输入点
# stability_score : 掩模质量的一个附加度量
# crop_box : 用于以XYWH格式生成此遮罩的图像的裁剪
masks = mask_generator.generate(image)
# 打印分割出来的个数以及第一个物体信息
print(len(masks))
print(masks[0].keys())
# 给分割出来的物体上色,显示分割效果
# plt.figure(figsize=(20,20))
# plt.imshow(image)
show_anns(masks, imgPath)
# plt.axis('off')
# plt.show()
def show_anns(anns, imgPath):
if len(anns) == 0:
return
# 对检测结果的字典对象进行排序
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img[:,:,3] = 0
shapes = []
for ann in sorted_anns:
# 过滤面积比较小的物体
if ann['area'] >=2500:
# 创建labelme格式
tempData = {"label": "otherheavy",
"points": [],
"group_id": None,
"shape_type": "polygon",
"flags": {}
}
# 获取分割物体掩膜
m = ann['segmentation']
# 找出物体轮廓
objImg = np.zeros((m.shape[0], m.shape[1], 1), np.uint8)
objImg[m] = 255
contours, hierarchy = cv2.findContours(objImg, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 找出轮廓最大的
max_area = 0
maxIndex = 0
for i in range(0, len(contours)):
area = cv2.contourArea(contours[i])
if area >= max_area:
max_area = area
maxIndex = i
# 将每个物体轮廓点数限制在一定范围内
if len(contours[maxIndex]) >=30:
contours = list(contours[maxIndex])
contours = contours[::int(len(contours)/30)]
else:
contours = list(contours[maxIndex])
# 显示图像
# contourImg = np.zeros((m.shape[0], m.shape[1], 3), np.uint8)
# cv2.drawContours(contourImg, contours, -1, (0, 255, 0), -1)
# cv2.imshow("1", contourImg)
# cv2.waitKey(0)
# 向labelme数据格式中添加轮廓点
for point in contours:
tempData["points"].append([int(point[0][0]), int(point[0][1])])
# 添加物体标注信息
shapes.append(tempData)
# 在彩色图像上标出物体
color_mask = np.concatenate([np.random.random(3), [1]])
img[m] = color_mask
jsonPath = imgPath.replace(".png", ".json") # 需要生成的文件路径
print(jsonPath)
# 创建json文件
file_out = open(jsonPath, "w")
# 载入json文件
jsonData = {}
# 8. 写入,修改json文件
jsonData["version"] = "5.2.1"
jsonData["flags"] = {}
jsonData["shapes"] = shapes
jsonData["imagePath"] = imgPath
jsonData["imageData"] = None
jsonData["imageHeight"] = sorted_anns[0]['segmentation'].shape[0]
jsonData["imageWidth"] = sorted_anns[0]['segmentation'].shape[1]
# 保存json文件
file_out.write(json.dumps(jsonData, indent=4)) # 保存文件
# 关闭json文件
file_out.close()
ax.imshow(img)
if __name__ == '__main__':
imgPath = "4.png"
segment(imgPath)