【数学建模】--聚类模型
聚类模型的定义:
“物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计,分析或预测;也可以探究不同类之间的相关性和主要差异。
聚类和分类的区别:分类是已知类别的,聚类未知。
K-means聚类算法
流程:
- 指定划分的簇的k值(类的个数)
- 随机选择k个数据作为哦初始聚类中心(不一定是样本点)
- 将其余数据划分到距离较近的聚类中心
- 调整新类,将中心更新为已划分数据的中心
- 重复3,4步检查中心是否收敛(不变),如果收敛或达到迭代次数使停止循环。(一般循迭代次数设置为10次)
- 结束。

图形结合理解:
我们可以登录网站自行体验:Visualizing K-Means Clustering
如果使自己添加类的位置可以选择I‘ll Choose
选择自己喜欢的图形:
选择图形后添加类的位置然后一直点GO/Update Centroids直至不想不再发生变化。
算法流程图: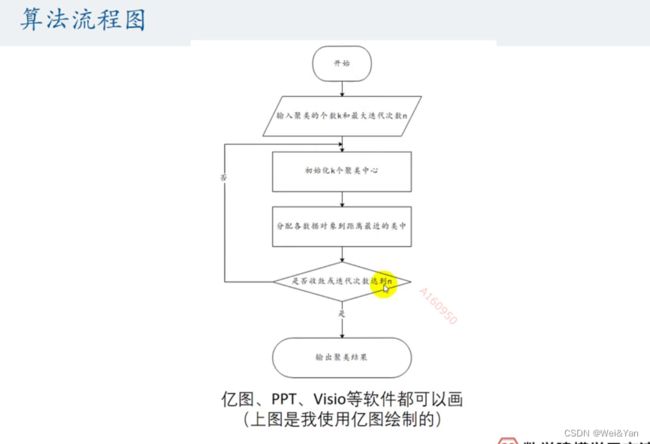
K_means算法的评价:
优点:快,高效率
缺点:需要给出k;对聚类中心敏感,聚类中心的位置不同结果不同;对孤立点敏感,孤立点对中心和其余样本带点的更新影响较大。
K-means算法—Spss操作:
聚类数根据自己想要分类的层次决定。
这里我们分为了高消费,中消费,低消费三类
得出结果

K-means算法的讨论:
需要自己给定k,当变量量纲不同的时候需要去量纲化。
Spss中去量纲化操作:
分析->描述统计->描述->导入需要去量纲化变量->√将标准化值另存为变量。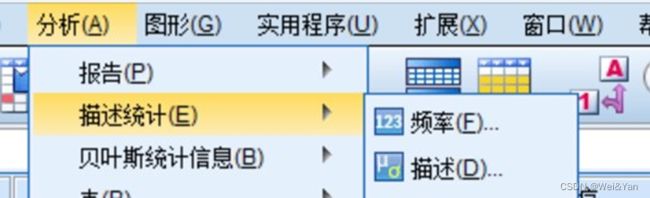

得到去量纲话Z-name
因为本次的例子变量单位相同不需要去量纲化,为了方便就拿此例子的数据去量纲化得到的结果有些轻微差
系统(层次)模型
简介: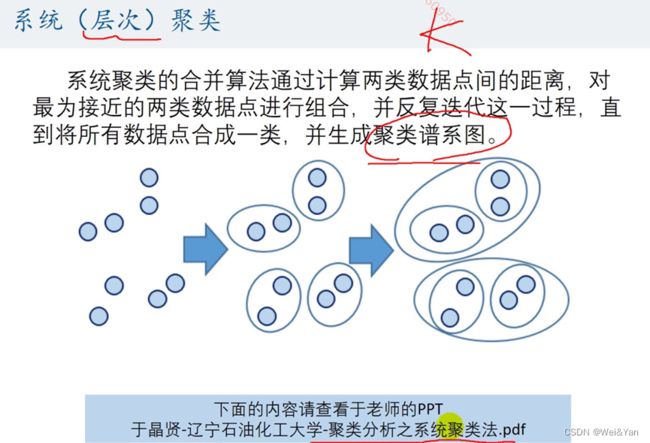
过程及原理简介:

样品与样品之间的常用距离:
指标与指标之间的常用距离:
类与类之间的常用距离以及计算方法:





案例:
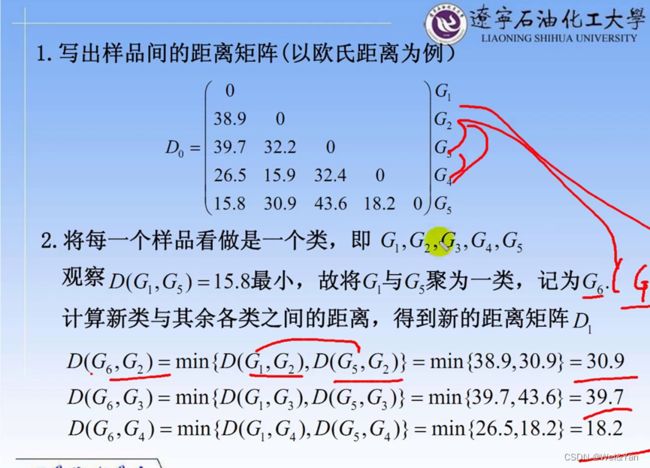

得到聚类的谱系图:
我们想要将数据分成几类通过对谱系图作垂线可得到明显的类组如在G9后面的线作垂线得到G1,2,4,5,6,7,8为一组,G3为一组一共两组。


注意问题:

系统聚类在SPSS中的操作:
分析-分类-系统聚类-导入数据-图-√谱系图
由冰柱图聚类谱系图等。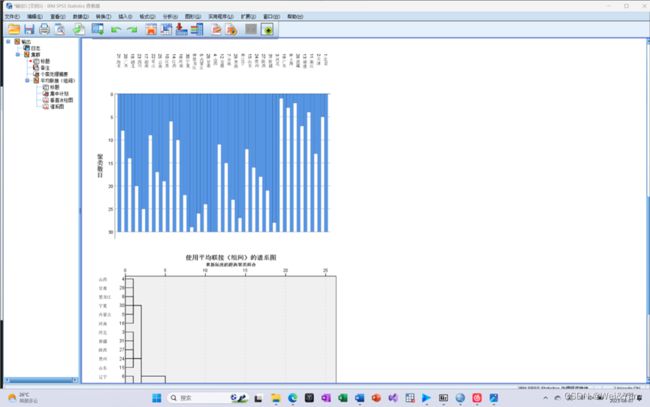
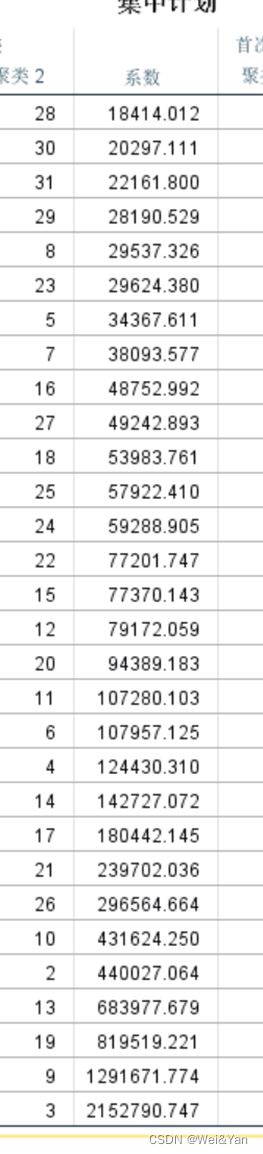
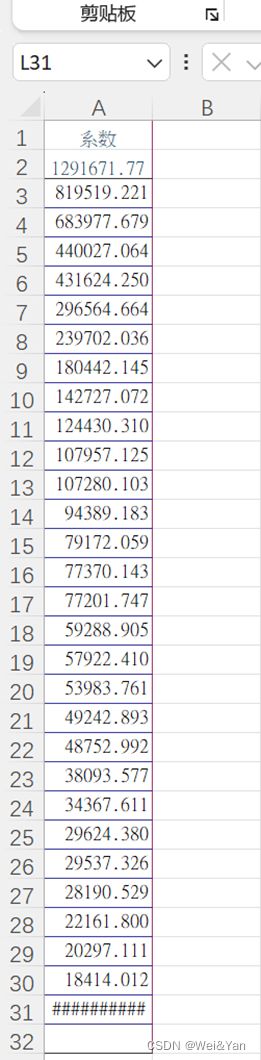
如何确定类的个数:利用Excel中的折线图,在折线趋缓的时候找对应的横坐标即是合适的分类个数。
操作:
1.复制stata中得到的系数-excel-排序-降序
2.插入-推荐的图标-散点图-调整合适的x轴坐标范围
3.观察下降趋势趋缓的地方对应的x可作为分类的个数。
STATA EXCEL


确定K后保存聚类结果并画图
- 通过excel的三点分析确定k
分析-分类-系统聚类-保存-单个解-聚类数
- 作图:
图形-图标构建-散点图/点图-2个指标(第二个)上拖,3个指标(第四个)上拖-输入x轴,y轴-设置颜色(聚类)-组-点id标签(将省份拖入)-修改图的背景,散点等颜色(双击编辑)
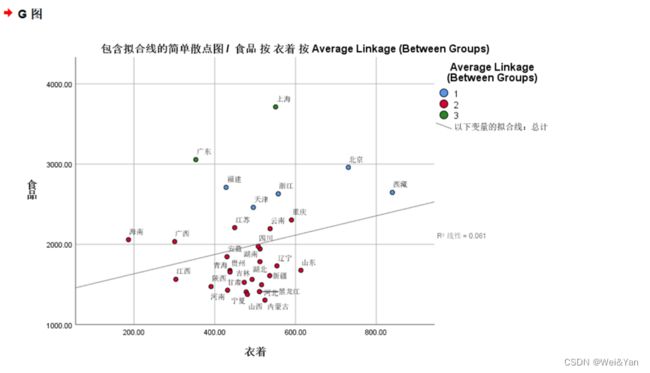
图二是三维的

编辑界面:
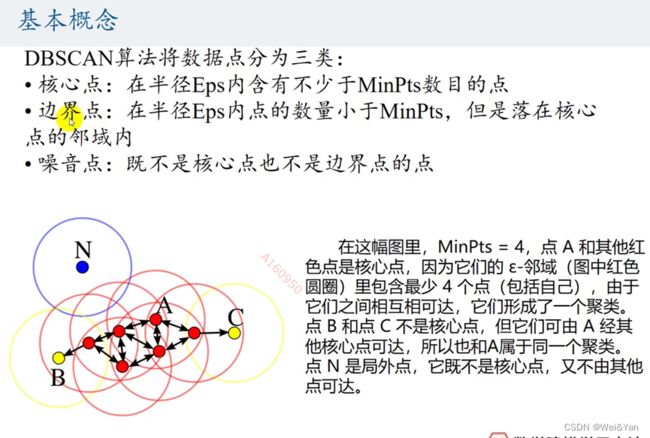
DBSCAN算法
基本概念:
可以理解为流感,按一定的半径不断蔓延传播。
DBSCAN的优缺点:
指标只有很少比如只有两个的时候较为合适,DSCAN的制图对半径,和圆内所能容纳最大聚类个数非常敏感,稍微修改就有很大的显著差异。
DBSACN的制图网站:Visualizing DBSCAN Clustering (naftaliharris.com)
演示:
半径为1.2,最少容纳点为4:
半径为0.8,最少容纳点为4:
DBSACN的伪代码:
Matlab中的DBSACN代码:
IDX中的数据就是每个数据的分类,为0则是孤立点。
旁边则是DBSACN用matlab画出的图形。

Matlab代码:
主函数:
clc;
clear;
close all;
%% Load Data
load mydata;%这里的数据跟随自己需要聚类的数据可以改变,后面的X是博主调试时使用的数据名可以自己改变。
%% Run DBSCAN Clustering Algorithm
epsilon=0.5;
MinPts=10;
IDX=DBSCAN(X,epsilon,MinPts);
%% Plot Results
% 如果只要两个指标的话就可以画图啦
PlotClusterinResult(X, IDX);
title(['DBSCAN Clustering (\epsilon = ' num2str(epsilon) ', MinPts = ' num2str(MinPts) ')']);
DBSCAN函数:
function [IDX, isnoise]=DBSCAN(X,epsilon,MinPts)
C=0;
n=size(X,1);
IDX=zeros(n,1); % 初始化全部为0,即全部为噪音点
D=pdist2(X,X);
visited=false(n,1);
isnoise=false(n,1);
for i=1:n
if ~visited(i)
visited(i)=true;
Neighbors=RegionQuery(i);
if numel(Neighbors)=MinPts
Neighbors=[Neighbors Neighbors2]; %#ok
end
end
if IDX(j)==0
IDX(j)=C;
end
k = k + 1;
if k > numel(Neighbors)
break;
end
end
end
function Neighbors=RegionQuery(i)
Neighbors=find(D(i,:)<=epsilon);
end
end
DBSCAN制图函数:
function PlotClusterinResult(X, IDX)
k=max(IDX);
Colors=hsv(k);
Legends = {};
for i=0:k
Xi=X(IDX==i,:);
if i~=0
Style = 'x';
MarkerSize = 8;
Color = Colors(i,:);
Legends{end+1} = ['Cluster #' num2str(i)];
else
Style = 'o';
MarkerSize = 6;
Color = [0 0 0];
if ~isempty(Xi)
Legends{end+1} = 'Noise';
end
end
if ~isempty(Xi)
plot(Xi(:,1),Xi(:,2),Style,'MarkerSize',MarkerSize,'Color',Color);
end
hold on;
end
hold off;
axis equal;
grid on;
legend(Legends);
legend('Location', 'NorthEastOutside');
end