trino的介绍和安装使用
前言:
最近在研究大数据的一些组件和数据库,本来是要调研下presto怎么用的,结果发现presto因为facebook的关系,导致presto核心开发成员离开,
重新开始创建了trino,个人感觉trino发展会更好,因为他们也是为了创建一个完全开源的环境才离开facebook,没有那么多商业上的私心,会更加专注和用心经营。
trino基本上和presto一致,毕竟是核心开发是同一帮人,所以就研究下trino的使用看看。trino是2020年才创办的,时间也不是很长,相关的资料和presto相比,要少很多,基本上就是看官网和代码来尝试(不过其实看presto的资料其实也一样)。
简介:
根据官网的自己的描述,他们解释了trino不是什么,是什么,来方便读者了解trino。
- 不是什么:它不是数据库的替代品,也不是为OLAP来设计的
- 是什么:它是一种工具,一种可以提供访问多种数据源,并且可以处理PB,TB级别的工具。并且能进行数据分析,聚合数据,生成报告(通常
这是OLAP的功能)
trino的基本概念:
- server类型:
- coordinator
- 负责解析语句,查询计划和管理worker,是trino的大脑,每个trino集群必须有一个coordinator(出于开发或者测试的目的可以把coordinator和worker设置为同一个)
- coordinator跟踪和协调worker的工作。创建一系列的查询模型,然后转换为给worker的一个个任务
- coordinator和worker之间使用REST API交流
- worker:
- 负责执行任务和处理数据,至少有一个,可以很多个。
- 当一个worker启动时,它会向coordinator发送消息,让coordinator知道有worker可以调用。
- worker之间使用REST API交流
- 数据源
- connector:
- connector让trino有了可以适应不同数据源的能力,它使用的是trino的SPI的实现
- trino包含了几个内置的connector:JMX的connector,提供对系统内置标的访问系统connector,hive的connector,TPCH connector
- 每个catalog和一个指定的connector关联,catalog的配置文件中就有个connector.name的属性,里面写的就是对应的connector的名字。
trino允许对同一个connector配置多个catalog。
- catalog:
- 包含schema并且通过connector连接数据源
- trino中寻找表的时候,以完全限定名来查找表。比如:hive.test_data.test,指定的是catalog是hive,schema是test_data,table是test的表。
- catalog在储存在trino的配置目录中
- schema
- table
注:schema和table就不解释了,用过数据库的基本上都知道是干嘛的,基本上和数据库是一致的,只不过是trino里面的三个层级为:catalog-schema-table
- 查询执行模型
-
statement:
- 基本等同于sql语句,只不过是trino将要执行的sql分为了两个概念,statement是和sql对应的。当执行statement的时候,trino会创建一个query和一个分布式的query plan,
然后将它们分发给一系列的woker去执行
- 基本等同于sql语句,只不过是trino将要执行的sql分为了两个概念,statement是和sql对应的。当执行statement的时候,trino会创建一个query和一个分布式的query plan,
-
query:
- query包含了很多的组件,比如stage, task,split,connector和其他组件
-
stage
- stage本身不在worker上运行,stage是coordinator用来构建分布式query plan的。例如,如果trino需要聚合储存在hive中的10亿条数据,它会创建一个root stage
来聚合其他几个stage的输出,不同的stage是一个查询计划的不同部分。
- stage本身不在worker上运行,stage是coordinator用来构建分布式query plan的。例如,如果trino需要聚合储存在hive中的10亿条数据,它会创建一个root stage
-
task
-
task相当于是stage产生的作业,stage从coordinator被分解为一个个task,然后交给worker去执行task
-
split
- split相当于是一部分的数据集,每个task会去处理对应的split
-
driver
- task包含了一个或者多个并行的driver,driver是一系列operator的实例,每个driver有一个输入和一个输出。
-
operator
- operator使用,转换和生成数据。例如,表扫描从connector获取数据,并生成可供其他operator使用的数据集。
-
exchange
- exchange在不同的节点之间传输数据。task将数据生成到输出的缓冲区,并使用exchange来使用其他task的数据
部署:
部署分两种方式,一个是代码部署,另外一个是docker镜像部署。
- 代码部署
-
首先按照官网指导,从官网上上把trino的代码下载下来了,trino-server-392.tar.gz,现在最新的是392的版本。下载后解压,我本地的路径是/Users/scott/software/trino-server-392
-
官网说DevelopmentServer是server的启动类,于是就按照官网说的下载了jdk17,以前还没用过jdk17,公司用的还是市面上使用最多的jdk8,这里稍微扯几句,
spring 最新的6.0说最低支持jdk17,我感觉这个肯定未来也是趋势,毕竟边编程语言也是不断在发展的,早点使用jdk17可以减少,后续更多的业务代码使用老的特性。
早点用新特性不香嘛。
启动的时候报错,显示最低要17.0.3,然后去官网上又看见推荐使用Azul Zulu的JDK,于是就下载了这个版本,在重新编译执行。
We recommend using Azul Zulu as the JDK for Trino, as Trino is tested against that distribution.
Zulu is also the JDK used by the Trino Docker image.
注:这一步的jdk必须装好,要不然运行trino的时候会报错,我一开始试了用jdk8,trino-cli倒是可以运行起来,但是server启动后在执行命令就狐疑报错
3.配置ulimit,这个官网只是推荐,怕limit用完了,本地测试应该不配置的话也不影响
vim /etc/security/limits.conf
然后写入参数
trino soft nofile 131072
trino hard nofile 131072
4.配置项
以下的配置项都在解压的trino文件夹里面,首先创建一个etc目录,
完整路径是/Users/scott/software/trino-server-392/etc,下面是所有配置都配置完后的目录结构图:
- node配置
- 在etc目录下,创建node.properties,node-id我是直接复制的官网上的,这个可以随便取,只要是唯一的就行。
node.data是储存数据和日志的目录,这要要设置好,里面会有个log文件夹,启动后打印的日志都在里面。
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/trino/data
- jvm配置
- 在etc目录下,创建jvm.config, 注意,只有jvm的后缀是config,其他配置文件基本上都是properties
官方推荐配置:
-server
-Xmx16G
-XX:InitialRAMPercentage=80
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
- config配置
- 在etc目录下,这个是配置当前的trino是什么server类型
coordinator的最小配置:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
discovery.uri=http://example.net:8080
worker的最小配置项:
coordinator=false
http-server.http.port=8080
discovery.uri=http://example.net:8080
单机上,如果coordinator和worker是同一台机器的话,用下面的配置
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
discovery.uri=http://example.net:8080
自己的本地,就把上面的example.net写为localhost或者127.0.0.1就可以了。
- log配置
- 在etc下创建log.properties
设置日志级别, trino的日志级别(日志依次减少):DEBUG, INFO, WARN, ERROR
io.trino=INFO
- catalog配置
- 在etc下创建一个catalog的文件夹,这个里面配置的就是catalog的各个connector和连接的数据源
默认要创建一个etc/catalog/jmx.propertis, 内容如下(JMX是内置的,所以写个connector的名字就可以运行):
connector.name=jmx
举个栗子,我想配置其他的数据源,可以参考https://trino.io/docs/current/connector.html,下面是trino目前支持的所有数据源:
Accumulo
Atop
BigQuery
Black Hole
Cassandra
ClickHouse
Delta Lake
Druid
Elasticsearch
Google Sheets
Hive
Iceberg
JMX
Kafka
Kinesis
Kudu
Local File
MariaDB
Memory
MongoDB
MySQL
Oracle
Phoenix
Pinot
PostgreSQL
Prometheus
Redis
Redshift
SingleStore (MemSQL)
SQL Server
System
Thrift
TPCDS
TPCH
这里我再举一个mysql的配置例子:
创建etc/catalog/mysql.propertis文件,内容如下(如果运行过程中,加入的配置要重启trino才能看见)
connector.name=mysql
connection-url=jdbc:mysql://example.net:3306
connection-user=root
connection-password=secret
- 运行trino
在trino的目录里面有bin目录,进入然后执行./launche start启动成功的话,会显示
Started as xxxx
xxxx是端口号,还可以使用./launche status 查看当前trino的状态。
具体./launche的命令可以查看官网链接
6.使用trino-cli
从官网上下载trino-cli-392-executable.jar, 然后在本地执行
java -jar trino-cli-392-executable.jar --server localhost:8080
这里server后面的地址就是配置第4步里面配置的server的地址,能进入到trino的命令行后就大功告成。
在浏览器输入localhost:8080,输入一个账号(默认是随便输)就可以进入到trino-cli,下面是它的基本界面和执行sql后的界面。

- docker部署
docker部署真的很简单,只要电脑上装了docker,按照官网的命令执行一遍就可以了,
这里是官网的链接。
trino的使用
trino的使用比较简单,使用多个异构数据库也跟使用数据库一样,只要在catalog目录里面配置好了,数据源可以连上。
就可以在trino-cli的命令行里面操作,使用。
查看所有的catalog
show catalogs;
会显示如下的catalogs(mysql和postgresql是我配置的):
trino> show catalogs;
Catalog
------------
jmx
mysql
postgresql
system
查看所有schemas
show schemas from mysql
其他的命令就不多说了,基本上和操作普通的数据库差不多,即使不知道,也可以根据cli里面的help命令,
来查看这些命令怎么使用。这里在举个栗子,是异构数据库联表查询的例子,是将mysql里面的一张表和postgresql里面的
一张表联表查询,这个还是比较厉害的。写法还是跟普通的join差不多,如图:
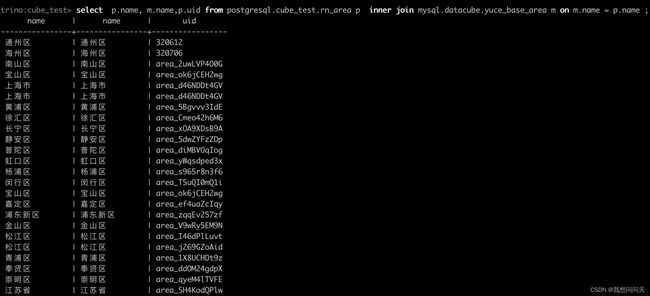
参数资料:
1.trino官网
2.presto官网
3.大数据工具之trino
4.利用docker容器模拟搭建Trino集群