Trino开荒
一. 概述
1.1 Trino历史
Facebook的数据仓库存储在少量大型Hadoop/HDFS集群。Hive是Facebook在几年前专为Hadoop打造的一款数据仓库工具。在以前,Facebook的科学家和分析师一直依靠Hive来做数据分析。但Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。Facebook也调研了其他比Hive更快的工具,但它们要么在功能有所限制要么就太简单,以至于无法操作Facebook庞大的数据仓库。
2012年开始试用的一些外部项目都不合适,他们决定自己开发,这就是Presto。2012年秋季开始开发,目前该项目已经在超过 1000名Facebook雇员中使用,运行超过30000个查询,每日数据在1PB级别。Facebook称Presto的性能比Hive要好上10倍多。2013年Facebook正式宣布开源Presto。
rebranding PrestoSQL as Trino原名PrestoSQL,FB开发的用来和Hive配合的及席查询引擎(竞品:Impala 、Kylin、SparkSQL),随后开源,FB公司对Presto有很强的控制欲,想要控制它的下一步发展方向,甚至空降项目经理,Presto创世人及其团队集体离职,从此Presto分为PrestoSQL(创始人) & PrestoDB(FB控制),随后 Presto被fb注册商标™️了,PrestoSQL无奈只能改为Trino(Dec 27, 2020)
Trino改名至今九个月,社区活跃度有赶超Presto之势 , 并且集齐了绝大多数原Presto人员
1.2 文档对比
从Trino & Presto文档对比来看,也是基本上…
甚至有些讲解就是直接把Presto替换为Trino,
甚至的甚至,图片中的Presto都没来得及换过来
Trino要比Presto更活跃一点。两个社区各自都做了一些重大的更新,同时我们也看到两个社区也不是完全隔离的,一个社区作出了一个号的好的改进另外一个社区会及时的吸收过去,比如Trino对S3的读取速度进行了优化,Presto也Cherry Pick过去了,目前两者都在做Pushdown ,pushdown也是未来的发展方向
二. 架构
2.1 Server types
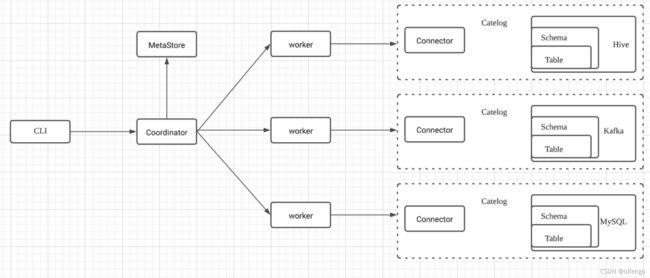
- 查询请求从CLI 提交到Coordinator
- Coordinator解析查询计划 ,然后分发给Worker执行
- Worker通过Connector链接数据源,获取到数据 并 对数据进行加工
- 一个Catelog表示一个数据源,包含 Schema 、Connector
- Schema类似于 库的概念,Table类似于表
- Connector类似JDBC,和各种数据源之间建立统一的适配器
coordinator & worker 进程常驻,设计初衷就不是为批量数据处理设计的 容易OOM
2.2 Query explain
Coordinate 解析…
SELECT count(company_id)
,status ---------Fra0
FROM apaylater_th.atome_afterpay_merchant.company ---------Fra3
where company_id in ( ---------Fra2
select id from
apaylater_th.atome_afterpay_merchant.merchant_brand ---------Fra5
where name = 'Atome Test') ---------Fra4
group by status; ---------Fra1
2.2.1 划分任务
一个查询按照 from(TableScan) 、limit 、join 、 Agg 、Output 划分成不同的 Fragment
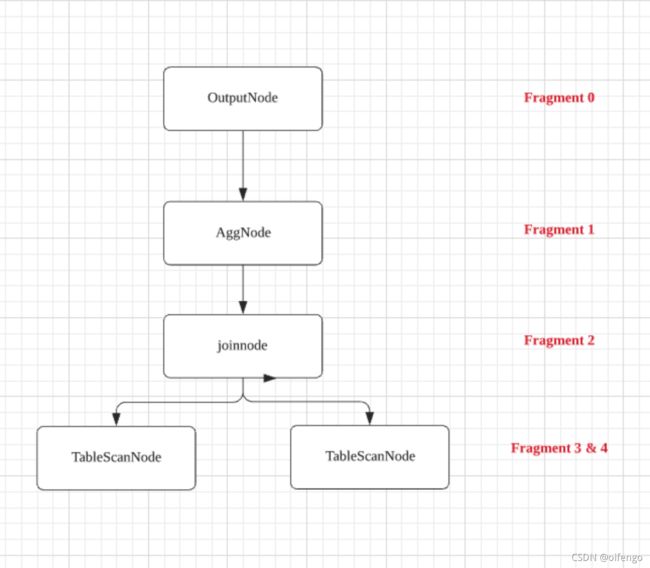
2.2.2 Worker间基于内存流转
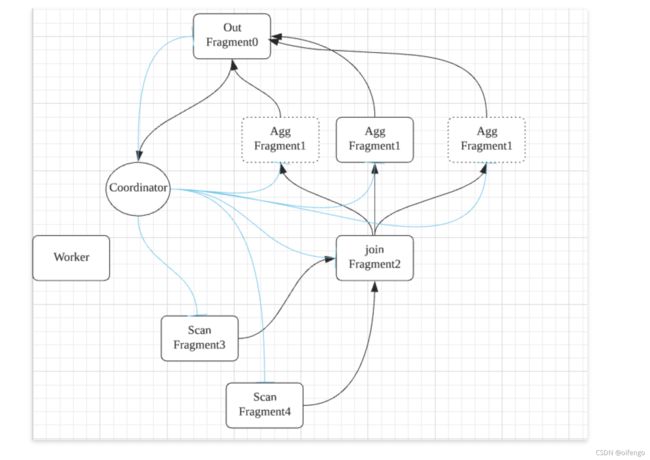
三. SQL使用优化
3.1 只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段
3.2 过滤条件必须加上分区字段
分区表减少磁盘的扫描,Trino能够更快的获取数据
3.3 合理使用Union
尽量在数据源union完后在让Trino处理
避免在同一个数据源中使用Union 操作,比如一个MySQL中两张表,直接在Trino 中union的话会导致数据必须全部加载到内存,可以采用先在MySQL中union好 ,创建View,再使用Trino查询View,这样Trino会分批加载数据
3.4 Order by合理使用
牵扯到全局排序的,数据需要发送到一个worker处理
3.5 Pushdown
Trino官方关于Pushdown的说明
Fragment 0 [SINGLE] -- output
Fragment 1 [SOURCE] -- tableScan
四. SQL差异化
4.1 关键字区分
Trino 保留关键字
https://trino.io/docs/current/language/reserved.html
--order 为Trino关键字,Trino用""区分关键字
from dp.atome_sg_apaylater_mysql_atome_afterpay_core."order" AS o
"level"
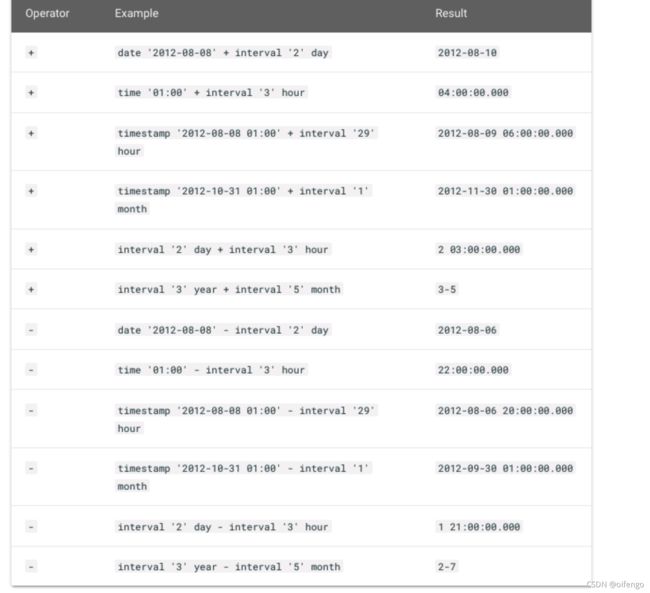
4.2 时间操作
date timestamp等都需要声明类型
Trino date&time 类型
DATE ‘2001-08-22’
TIME ‘01:02:03.456’
TIMESTAMP ‘2020-06-10 15:55:23’
/*SparkSQL的写法*/
SELECT t FROM a WHERE t > “2021-01-01 00:00:00”
/*Presto中的写法*/
SELECT t FROM a WHERE t > timestamp '2021-01-01 00:00:00'
Time Zone
The AT TIME ZONE operator sets the time zone of a timestamp:
SELECT timestamp '2012-10-31 01:00 UTC'; -- 默认是UTC
-- 2012-10-31 01:00:00.000 UTC
SELECT timestamp '2012-10-31 01:00 UTC' AT TIME ZONE 'America/Los_Angeles';
-- 2012-10-30 18:00:00.000 America/Los_Angeles
p : timestamp 的秒的时间精度
current_timestamp(p)
localtimestamp(p)
SELECT current_timestamp(6);
-- 2020-06-24 08:25:31.759993 America/Los_Angeles
date_add
date_add(unit, value, timestamp) → [same as input]
Adds an interval value of type unit to timestamp. Subtraction can be performed by using a negative value:
SELECT date_add('second', 86, TIMESTAMP '2020-03-01 00:00:00');
-- 2020-03-01 00:01:26.000
SELECT date_add('hour', 9, TIMESTAMP '2020-03-01 00:00:00');
-- 2020-03-01 09:00:00.000
SELECT date_add('day', -1, TIMESTAMP '2020-03-01 00:00:00 UTC');
-- 2020-02-29 00:00:00.000 UTC
SELECT date_add('day', -1, date '2020-03-01');
-- 2020-02-29
date_diff
date_diff(unit, timestamp1, timestamp2) → bigint#
Returns timestamp2 - timestamp1 expressed in terms of unit:
SELECT date_diff('second', TIMESTAMP '2020-03-01 00:00:00', TIMESTAMP '2020-03-02 00:00:00');
-- 86400
SELECT date_diff('hour', TIMESTAMP '2020-03-01 00:00:00 UTC', TIMESTAMP '2020-03-02 00:00:00 UTC');
-- 24
SELECT date_diff('day', DATE '2020-03-01', DATE '2020-03-02');
-- 1
SELECT date_diff('second', TIMESTAMP '2020-06-01 12:30:45.000000000', TIMESTAMP '2020-06-02 12:30:45.123456789');
-- 86400
SELECT date_diff('millisecond', TIMESTAMP '2020-06-01 12:30:45.000000000', TIMESTAMP '2020-06-02 12:30:45.123456789');
-- 86400123
https://trino.io/docs/current/functions/datetime.html
4.3 Trino where 过滤
‘’ ‘’ 会被认为是区分关键字,过滤用’ ’
select id from
apaylater_th.atome_afterpay_merchant.merchant_brand
--where name = "Atome Test" Column 'atome test' cannot be resolved
where name = 'Atome Test'
4.4 OLAP不建议使用update insert
分析型处理引擎,对于update insert处理会很慢,虽然现在已经支持了,但还是不建议直接使用
4.5 date 在 Trino & Tableau之间
首先Trino 在时间比较的时候必须指定格式
这里的
AND o.create_time
between date <Parameters.Select Date String>
and (date <Parameters.Select Date String> + interval '1' day)
List of functions
参考文献:
- Trino官方文档 https://trino.io/docs/current/index.html
- PrestoDB和PrestoSQL比较及选择 https://zhuanlan.zhihu.com/p/87621360
- Presto实现原理和美团的使用实践 https://tech.meituan.com/2014/06/16/presto.html