ELK使用教程
ELK使用教程
华为云的镜像下载
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D以下版本以7.6.1为主
Elasticsearch
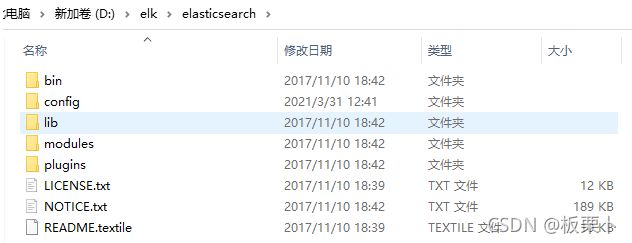
目录
bin: 启动文件
config:配置文件
log4j2:日志配置文件
jvm:虚拟机相关配置
elasticsearch.yml:es配置文件 :默认9200端口
lib:相关jar包
modules:功能模块
plugins: 插件(ik分词器)
安装
-
环境需求(java环境–jdk安装。path配置)
-
安装jdk
-
环境变量–新建系统变量:JAVA_HOME:C:\Program Files\Java\jdk1.8.0_212
环境变量—新增path:%JAVA_HOME%\bin
配置(elasticsearch.yml)
-
跨域配置:
http.cors.enabled: true
http.cors.allow-origin: “*”
-
外网访问配置:
network.host: 0.0.0.0 (监听任意ip发送的请求数据)
cluster.initial_master_nodes: [“192.168.11.12”] (绑定本机ip)
启动
- 双击bin目录下的elasticsearch.bat文件
- 访问:http://127.0.0.1:9200/

elasticsearch-head-master
安装
环境需求:node.js
插件:elasticsearch-head-master
cmd命令进入文件夹:D:>cd elk\elasticsearch-head-master
cmd命令初始化:npm install
启动
cmd命令启动:npm run start
访问:http://127.0.0.1:9100/

Kibana
官网下载:https://www.elastic.co/cn/downloads/kibana
版本:kibana版本要与es对应
环境需求:node.js
默认端口:5601
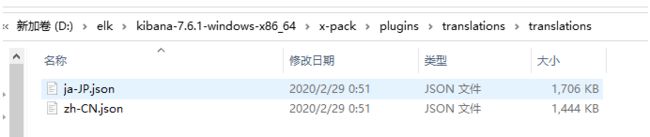
汉化
汉化文件7.x自带:D:\elk\kibana-7.6.1-windows-x86_64\x-pack\plugins\translations\translations
修改配置:D:\elk\kibana-7.6.1-windows-x86_64\config\kibana.yml

启动
bin:双击kibana.bat

访问http://127.0.0.1:5601/

ik分词器
安装
安装:在D:\elk\elasticsearch\plugins\新建文件夹ik
将ik分词器目录下所有文件移至新建文件夹中

重启elasticsearch,加载插件
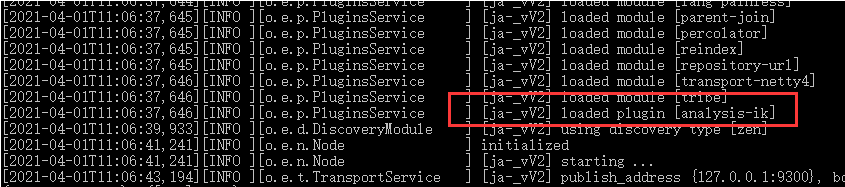
插件查看
进入elasticsearch中bin目录
执行命令:elasticsearch-plugin list

分词器测试
打开kibana开发工具
GET _analyze
{
"analyzer": "ik_smart", //最少单词切分
"text": ["无敌姐妹花"]
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["无敌姐妹花"]
}
词典配置
新建:tsdn.dic
姐妹花
无敌姐妹花
配置文件:IKAnalyzer.cfg.xml

重启es
Logstash
数据导入
csv文件导入
将数据库表导出为csv文件(不包含标题,字段内不能包含逗号,否则csv文件可能出错)

将导出的csv文件放至D:\elk\logstash-7.6.1\config
新建配置文件data.conf放至D:\elk\logstash-7.6.1\bin目录
配置内容如下:
input {
file {
#要读取的数据文件的路径
path => "D:/elk/logstash-7.6.1/config/TSI_DOC_TITLE_CONTENT_VIEW.csv"
start_position => "beginning"
}
}
filter {
csv {
#分隔符
separator => ","
#数据对应的字段名,顺序要和字段值一致
columns => ["TID","TNAME","TPARENT","DID","CONTENT"]
}
mutate{
#忽略某些字段
remove_field => ["@version","message","host","path","@timestamp"]
#类型
convert => {
"TID" => "string"
"TENAME" => "string"
"TPARENT" => "string"
"DID" => "string"
"CONTENT" => "string"
}
}
}
output {
elasticsearch {
#要写入的es地址
hosts => "http://localhost:9200"
#索引
index => "title"
#类型,6.X版本后的固定用这个
document_type => "_doc"
#定义文档id用表数据的主键,会方便核对数据
document_id =>"%{TID}"
}
stdout {}
}
cmd进入bin目录执行:logstash -f data.conf
logstash同步数据库
将jdbc连接插件(根据数据库下载对应jar包)放至D:\elk\logstash-7.6.1\lib目录下

新建sql文件夹,新建sql文件,写上查询语句

sql文件范例
select * from student
新建conf配置文件放至bin目录下
配置文件内容如下:
input {
jdbc {
jdbc_driver_library => "d:/elk/logstash-7.6.1/lib/ojdbc6-11.2.0.2.0.jar"
jdbc_driver_class => "Java::oracle.jdbc.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@192.168.212.22:7210:chestnut"
jdbc_user => "chestnut"
jdbc_password => "chestnut1111"
schedule => "* * * * *"
statement_filepath => "d:/elk/logstash-7.6.1/sql/gettitlecontent.sql"
jdbc_page_size => "100000"
use_column_value => "true"
tracking_column => "tid"
codec => plain { charset => "UTF-8"}
jdbc_paging_enabled => true
}
}
filter {
mutate{
#忽略某些字段
remove_field => ["@version","message","host","path","@timestamp"]
}
}
output {
elasticsearch {
#要写入的es地址
hosts => "http://localhost:9200"
#索引
index => "title"
#类型,6.X版本后的固定用这个
document_type => "_doc"
#定义文档id用表数据的主键,会方便核对数据
document_id => "%{tid}"
}
stdout {}
}
cd到bin目录运行:logstash -f getoracle.conf
秒级同步:2秒同步一次
schedule => " */2 * * * * "
分钟级同步:2分钟同步一次
schedule => " 0/2 * * * * "
小时级同步:晚上22:00时同步一次
schedule => " * 22 * * * "
es语法基础
基本操作(kibana控制台)
创建索引
PUT (索引)test/(文档)type/(id)1
PUT /test/type/1
{
"name":"tsdn"
}
查询
GET /test/type //查询文档为type
GET /test/type/_search?q=name:tsdn //精确查询
GET _cat //可以查看默认配置
复杂查询
//模糊查询
GET /test/type/_search
{
"query":{
"match": {
"name": "csdn"
}
},
"_source": "name", //查询结果字段过滤
"sort": [ //排序
{
"id": {
"order": "desc"
}
}
],
"from": 0, //分页
"size": 1
}
//聚合查询{must相当于数据库中的and,should相当于or,must_not相当于not}
GET /test/type/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "csdn" //查询条件1
}
},
{
"match": {
"id": 1 //查询条件2
}
}
]
}
}
}
//筛选条件{gte:大于等于 lte:小于等于 gt:大于 lt:小于}
GET /test/type/_search
{
"query":{
"bool": {
"filter": {
"range": {
"id": {
"gte": 0, //大于等于0
"lte": 1 //小于等于1
}
}
}
}
}
}
修改
PUT (索引)test/(文档)type/(id)1 直接覆盖
POST (索引)test/(文档)type/(id)1/_update 只改具体属性
POST /test/type/1/_update
{
"name":"csdn"
}
删除
DELETE (索引)test