PyTorch深度学习图像分类--猫狗大战
PyTorch深度学习图像分类--猫狗大战
- 1.背景介绍
- 2.环境配置
-
- 2.1软硬件清单
-
- 2.1.1配置PyPorch
- 2.1.2开发软件
- 2.1.3 显卡
- 2.2 数据准备
- 3 基础理论
-
- 3.1PyTorch常用模块
- 3.2torchvision
- 3.3深度学习流程
- 3代码解析
-
- 3.1样本文件夹制作
- 3.2模型训练
- 3.3 训练结果
1.背景介绍
准备简单学习一下深度学习相关的内容,参考的书是这本《Pytorch深度学习》,刚开始接触很多概念还是不太好理解的(即使是最基础的张量和变量),这本书对这些概念的解释并不深入,它主要是通过例子增加对深度学习的理解,尤其是深度学习的整套流程和每个部分的含义,所以看书的时候需要搜索一些概念帮助理解。
这篇文章就是书中第三章的一个深度学习案例-猫狗大战,书虽然并不旧,但是由于Pytorch的更新,里面的一些代码在最新版Pytorch中已经没办法运行了。因此这篇文章在理解简单的深度学习流程之后,修改了书中的代码,然后进行运行。

2.环境配置
2.1软硬件清单
2.1.1配置PyPorch
配置PyTorch环境并不复杂,但是它占用的内存是很大的,下面两种是比较常用的方法(实际上都是Pytych虚拟环境,可以提前学习一下)

- AnaConda:需要先安装AnaConda软件,然后运行下面的命令(命令就在官网首页),篇幅限制就不详细介绍了,网上教程很多。
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
- Pip 这个就很常见了,建议建立好虚拟环境之后再安装,要不然就跟系统环境混起来了,这个用PyCharm很容易做到,下面是官网的命令
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
2.1.2开发软件
本文章用的是PyCharm(或者可以用Jupyter Notebook),相信学深度学习的都用过就不介绍了。
2.1.3 显卡
最好有个显卡吧,没有就用CPU,虽然本例可能用GPU并不多,但是如果项目比较大肯定是可以排上用场的,如果没有显卡,在配置PyPorch的时候,需要在官网选对安装命令。
2.2 数据准备
数据是开源网站下载的,这是网址:kaggle,这个网站还有很多其他的深度学习数据,下载速度也是不错的。
下载之后,把数据解压,可以得到这样的目录,本文中只用到了里面的train文件夹,里面是25000个猫啊狗啊的图片。

3 基础理论
3.1PyTorch常用模块
官网介绍:PyTorch是一个优化的张量库,用于使用 GPU 和 CPU 进行深度学习。
下面是比较常用的模块
torch.Tensor模块:张量有不同的类型和维度,可以类比Numpy类型,两者有很多相似之处,也可以相互转化,它是PyTorch数据的基础。
torch.autograd模块:提供实现任意标量值函数自动微分的类和函数。它需要对现有代码进行最少的更改计算梯度。截至目前,支持浮点Tensor类型(half、float、double 和 bfloat16)和复杂Tensor类型(cfloat、cdouble)的 autograd。
torch.cuda模块:这个包增加了对 CUDA 张量类型的支持,它们实现与 CPU 张量相同的功能,但它们利用 GPU 进行计算。它是延迟初始化的,因此可以随时导入它,并使用它 is_available()来确定系统是否支持 CUDA。
torch.nn模块:里面包含了神经网络中使用的一些常用函数
torch.optim模块:是一个实现各种优化算法的包。大多数常用的方法都已经支持,接口也足够通用,以便将来可以轻松集成更复杂的方法。
torch.utils.data模块:PyTorch 数据加载实用程序的核心是torch.utils.data.DataLoader 类。可以批量导入数据
3.2torchvision
软件包包含流行的数据集、模型架构和用于计算机视觉的常见图像转换,有以下几个功能:

本例中,该模块主要进行图像数据的加载和基本图片变换。
3.3深度学习流程
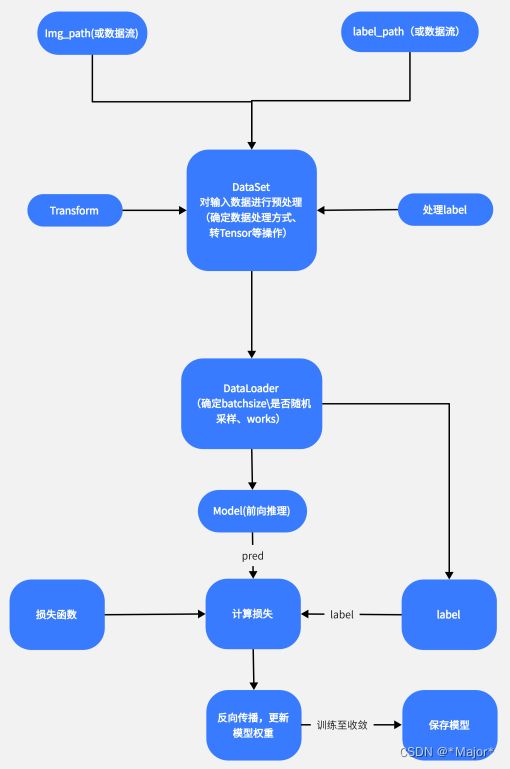
借用这篇文章的流程图:PyTorch训练模型流程图,主要分为下面几个部分
①数据加载
②模型设计
③模型训练-损失函数计算-反向传播
④继续训练,直到满足精度
3代码解析
3.1样本文件夹制作
首先把文件夹里面混在一起的猫狗图片分别放在两个文件夹,选2000个作为验证集,23000作为训练集,分别放在两个文件夹,并区分种类。
 =>
=>
import numpy as np
import os
import glob
path="data/train/"
#预处理数据,把图片按照名称分类
files=glob.glob(os.path.join(path,'*.jpg'))
print(f"一共{len(files)}")
no_of_image=len(files)
shuffle=np.random.permutation(no_of_image)
os.mkdir(os.path.join(path,'valid'))
os.mkdir(os.path.join(path,'train'))
for t in ['train','valid']:
for folder in ['dog/','cat/']:
os.mkdir(os.path.join(path,t,folder))
for i in shuffle[:2000]:
folder=files[i].split('\\')[-1].split('.')[0]
image=files[i].split('\\')[-1]
print(folder,image)
os.rename(files[i], os.path.join(path,'valid',folder,image))
for i in shuffle[2000:]:
folder=files[i].split('\\')[-1].split('.')[0]
image=files[i].split('\\')[-1]
os.rename(files[i], os.path.join(path,'train',folder,image))
3.2模型训练
相信有接触过Pytorch的对下面的代码应该很熟悉,首先导入了常用的包,然后判断是否支持显卡。
下面加载数据-设计模型-设计损失函数-设计优化器
最后开始运行函数模型。
该训练中,使用的模型是resnet18,修改了最后的线形层,因为本程序只有猫、狗两个类别
调用训练函数需要放在main,否则会因为线程问题报错
if __name__ == '__main__':
下面是沉浸版代码
import os
import torchvision.models.resnet
import numpy as np
import matplotlib.pyplot as plt
import shutil
from torchvision import transforms
from torchvision import models
import torch
from torch.autograd import Variable
import torch.nn as nn
from torch.optim import lr_scheduler
from torch import optim
from torchvision.datasets import ImageFolder
from torchvision.utils import make_grid
import time
def imshow(inp):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
is_cuda=False
if torch.cuda.is_available():
torch.cuda.empty_cache()
is_cuda = True
simple_transform = transforms.Compose([transforms.Resize((224,224))
,transforms.ToTensor()
,transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
train = ImageFolder('data/train/train/',simple_transform)
valid = ImageFolder('data/train/valid/',simple_transform)
train_data_gen = torch.utils.data.DataLoader(train,shuffle=True,batch_size=32,num_workers=2)
valid_data_gen = torch.utils.data.DataLoader(valid,batch_size=32,num_workers=2)
dataset_sizes = {'train':len(train_data_gen.dataset),'valid':len(valid_data_gen.dataset)}
dataloaders = {'train':train_data_gen,'valid':valid_data_gen}
model_ft = models.resnet18(weights=torchvision.models.resnet.ResNet18_Weights.IMAGENET1K_V1)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 2)
if torch.cuda.is_available():
model_ft = model_ft.cuda()
# Loss and Optimizer
learning_rate = 0.001
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
def train_model(model, criterion, optimizer, scheduler, num_epochs=5):
since = time.time()
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for data in dataloaders[phase]:
# get the inputs
inputs, labels = data
# wrap them in Variable
if torch.cuda.is_available():
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
if phase == 'train':
scheduler.step()
model.train(True) # Set model to training mode
else:
model.train(False) # Set model to evaluate mode
# statistics
running_loss += loss.item()
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
if __name__ == '__main__':
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=15)
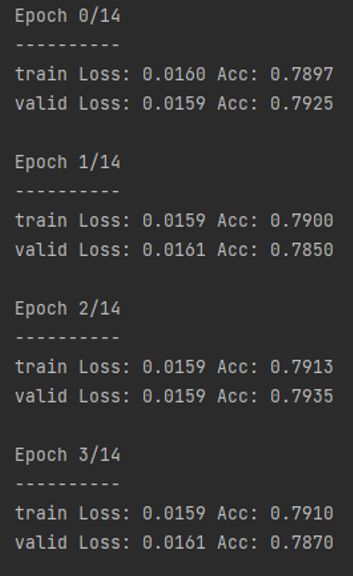
3.3 训练结果