引用计数法
原理篇
GC是一种释放无法被引用对象的机制。引用计数法的思想是让每个对象记录下有多少程序引用自己,我们形象的称之为"人气",并且让没有人气的对象自动消失。引用计数法诞生于1960年,由George E. Collins创造。
引用计数法在对象头中添加了一个计数器来记录对象的被引用数。
分配一个新对象的伪代码如下:
//分配内存
new_obj(size) {
//从空闲链表中寻找一个合适的分块
obj = pickup_chunk(size, $free_list)
if (obj == NULL)
allocation_fail() //分配失败
else
obj.ref_cnt = 1 //初始化引用计数为1
return obj
}
在分配过程中,也是去空闲链表中寻找一个大小合适的分块,这和GC标记清除算法是一样的。当成功找到合适的分块后,我们将它的引用计数设置为1,因为是新分配的,所以只有一个引用。
你会发现在引用计数法中,并没有显示的垃圾清除过程,那些引用为0的对象是在何时被回收的呢?
回答这个问题之前我们需要先思考另一个问题:什么时候一个对象的"人气"会发生变化?一个是在分配对象的时候会增加"人气"。另一个是在更新指针的时候,源指针指向的对象"人气"会减少,目的指针指向的对象"人气"会增加。
更新指针函数伪代码如下:
//更新指针
update_ptr(ptr, obj) {
inc_ref_cnt(obj) //增加目的对象的引用计数
dec_ref_cnt(*ptr) //减少源对象的引用计数
*ptr = obj
}
//增加对象obj的引用计数
inc_ref_cnt(obj) {
obj.ref_cnt++
}
//增加对象obj的引用计数,
//并将引用计数为0的对象回收
dec_ref_cnt(obj) {
obj.ref_cnt-- //减少对象obj的引用计数
if(obj.ref_cnt == 0) //不再被引用,表示变成了垃圾
for(child : children(obj)) //遍历obj的子对象
dec_ref_cnt(*child) //将子对象引用计数减一,因为obj被回收了
reclaim(obj) //将obj加入空闲链表
}
update_ptr的核心是*ptr=obj,inc_ref_cnt和dec_ref_cnt是为了进行内存管理,注意二者的顺序不能颠倒。因为如果ptr本来就是指向obj的,如果先执行了dec_ref_cnt,obj就会被回收掉,再执行inc_ref_cnt时就会增加一个已被回收对象的引用计数,而且obj也不能被回收。
dec_ref_cnt在减少引用计数的同时就把垃圾给回收掉了,垃圾清理和应用程序是同时运行的。GC标记清除算法需要定期运行GC或在内存耗尽时运行GC,而引用计数法则不需要,在分配失败时,就能确定一定是堆已经用完了。
举个例子,根引用A和C,A引用B,通过update_ptr让A指向C,堆的变化如下图所示。
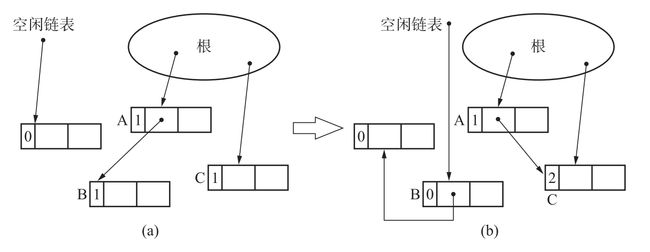
注意图中B和C的"人气"变化。
引用计数法优点如下:
- 可立即回收垃圾。从伪代码可以看出,垃圾产生的同时就被立刻回收了。
- 最大暂停时间短。只有更新指针时,才会执行垃圾回收。
- 不需要沿根节点遍历活动对象。从伪代码可以看出,引用计数法是从垃圾对象开始遍历其子对象,而不是从根节点开始,而且不需要遍历堆来寻找垃圾。
引用计数法的缺点有以下几点:
- 计数器的增减处理繁重。这一点是由频繁的指针更新引起的,特别是由根引用的指针,也就是全局变量指针。每次指针更新都要递归更新计数器的值。
- 计数器需要占据较多内存空间。为了记录对象被引用的次数,计数器需要有足够的位宽,最坏情况下要能记录下堆中所有对象数。计数器会降低内存使用效率,越小的对象,空间利用率越低。
- 实现繁琐复杂。因为我们需要将所有的
*ptr=obj重写成update_ptr(ptr,obj)。 - 无法回收循环引用的对象。因为循环引用的对象计数器值都是1,不能被判定为垃圾,也就无法一起回收。

优化篇
延迟引用计数法
延迟应用计数法主要针对的是计数器更新繁重的问题,这里的"延迟"指的是"延迟回收"。它的发明者是L. Peter Deutsch和Daniel G. Bobrow。
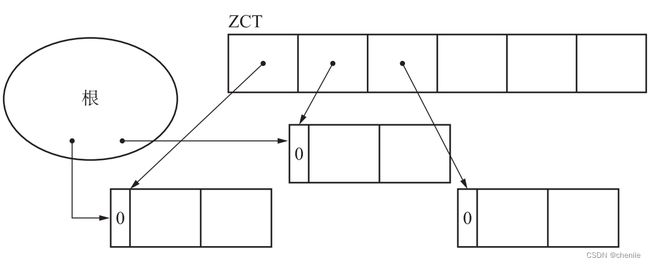
延迟引用计数法做的第一个改动是不记录根节点直接引用的对象的计数器变化。比如对于全局指针,直接使用*$ptr=obj更新,而不是用update_ptr($ptr,obj)。根节点直接引用的对象计数器始终为0,它们可能是垃圾,也可能不是。
第二个改动是增加了一个ZCT数组,全称是Zero Count Tale。在执行dec_ref_cnt时,引用数变为0的对象并不是马上被回收,而是加入ZCT数组。并且也不会递归的对子对象执行dec_ref_cnt方法。
以上两个改动如下图所示。
dec_ref_cnt函数伪代码变化如下:
dec_ref_cnt(obj) {
obj.ref_cnt-- //减少obj引用计数
if(obj.ref_cnt == 0) //引用计数为0,可能变成垃圾
if(is_full($zct) == TRUE) //ZCT数组已满
scan_zct() //扫描ZCT数组,将真正的垃圾回收,释放ZCT数组空间
push($zct, obj) //将obj加入ZCT数组
}
此时,因为垃圾并不是马上被回收,所有在分配对象时,需要多一次尝试。
new_obj(size) {
//从空闲链表寻找大小合适的分块
obj = pickup_chunk(size, $free_list)
if(obj == NULL) //没找到
scan_zct() //扫描ZCT数组,回收垃圾
obj = pickup_chunk(size, $free_list) //再次尝试分配
if(obj == NULL) //没找到
allocation_fail() //分配失败
obj.ref_cnt = 1 //分配成功,初始化引用计数
return obj
}
scan_zct函数的伪代码如下:
scan_zct() {
//将根节点直接引用对象的计数器加一,
//因为它们肯定不是垃圾
for(r : $roots)
(*r).ref_cnt++
for(obj : $zct) //遍历ZCT数组
if(obj.ref_cnt == 0) //如果引用计数为0,肯定是垃圾
remove($zct, obj) //将obj从ZCT数组删除
delete(obj) //回收垃圾
//恢复根节点直接引用对象的计数器
for(r : $roots)
(*r).ref_cnt--
}
//回收obj对象空间
delete(obj) {
for(child : children(obj) //遍历子对象
(*child).ref_cnt-- //将子对象引用数减一,因为obj被回收了
if((*child).ref_cnt == 0) //子对象也没有引用了,变成了垃圾
delete(*child) //递归回收变成垃圾的子对象
reclaim(obj) //将obj添加到空闲链表
}
为了避免根对象直接引用的对象被回收,在扫描ZCT之前,需要先将根节点直接引用对象的计数器加一,并在扫描结束后将其恢复。原本在dec_ref_cnt中更新子对象计数器的工作,现在放到了delete中执行,也就是在真正回收垃圾时,才去递归遍历子对象。
其实我一直不明白为什么根直接引用的对象的计数器会是0,难道它们不是通过
new_obj函数分配的吗?如果是,那么初始引用计数应该是1才对啊。而且,如果所有根直接引用的对象的计数器都是0,那么它们必然要被记录到ZCT数组,如果程序创建了足够多的全局对象,导致根直接引用的对象就把ZCT数组占满了,那么ZCT不就失效了吗?而且再创建全局引用的话,也应该被加入ZCT数组,但此时ZCT数组已满,又没有垃圾可以回收,那就无法加入了呀。
延迟引用计数法的优点是减轻了根引用频繁变化导致的计数器更新负担,而且通过延迟,实现了垃圾批量回收。
它的优点也带来了一个缺点,那就是垃圾不能立刻回收,会压迫堆。另外,scan_zct也增加了最大暂停时间。ZCT越大,扫描花费的时间就越长,暂停时间也就越长。而如果减小ZCT,扫描的频率就会增加,导致吞吐量降低。
Sticky引用计数法
Sticky引用计数法解决的是计数器占据较多内存空间的问题。其思路是减少计数器位宽。比如只有5比特作为计数器,最多可以记录31个引用,如果引用数超过这个上限,再想别的办法处理。
第一个办法是什么都不做。这主要是基于以下两点考虑:
- 研究表明许多对象一生成马上就死了,多数情况下引用计数都是在0-1之间变化,鲜有5位计数器溢出的情况。
- 计数器溢出则说明该对象很重要,那么其在将来称为垃圾的可能性也很低。
第二个办法是使用GC标记清除算法来管理。直接来看伪代码:
mark_sweep_for_counter_overflow() {
reset_all_ref_cnt() //将所有对象计数器清零
mark_phase() //标记
sweep_phase() //清除
}
//标记阶段
mark_phase() {
//将根节点直接引用的对象入栈
for(r : $roots)
push(*r, $mark_stack)
//遍历活动对象
while(is_empty($mark_stack) == FALSE)
obj = pop($mark_stack)
obj.ref_cnt++ //增加引用计数
//处理一个对象被多次引用的情况,真实还原它的引用数
if(obj.ref_cnt == 1) //如果obj有一个引用,
for(child : children(obj)) //那么它的子对象也应该有一个引用
push(*child, $mark_stack)
}
//清除阶段
sweep_phase() {
sweeping = $heap_top //从堆头部开始
while(sweeping < $heap_end) //遍历堆
if(sweeping.ref_cnt == 0) //引用计数为0,表示是垃圾
reclaim(sweeping) //将对象添加到空闲链表
sweeping += sweeping.size //下一个对象
}
一开始我们将所有对象的引用计数全部清零了,因此在标记阶段遍历活动对象来真实还原对象的"人气",与普通遍历算法不同的是,每个对象会被遍历多次,具体次数与该对象的实际"人气"值相同,或者说与该节点的入度相同。你可以将活动对象抽象成一张有向图,对象的"人气"就是图中节点的入度。
清除阶段还是遍历堆,将"人气"为0的对象回收掉。
结合GC标记清除算法,不仅能回收计数器溢出的对象,还可以回收循环引用的对象,可以说是一举两得。
不过这里用到的GC标记清除算法相比于标准的GC标记清除算法要消耗更多时间,吞吐量会减小。因为标准GC标记清除算法对每个活动对象只会访问一次,而在引用计数法中,为了还原活动对象的真实引用数,可能要多次访问一个活动对象。
1位引用计数法
1位引用计数法也是为了优化计数器太占空间的问题,它是比Sticky更狠的一个算法,直接将计数器减小到1个比特。
首先我们让计数器为0表示"人气"为1,计数器为1表示"人气"大于等于2,如下图所示。

我们能都这样的处理是基于这样一个事实:几乎没有对象被共有,所有对象都能马上被回收。
前面提到计数器在对象头中,现在只占一个比特,那么可以在指针中拿出一个比特来作为计数器。但是在指针中我们不叫它计数器,而是换了个名字叫"标签"。
标签位为0表示对象引用数为1,我们称这种状态为UNIQUE;标签位为1表示对象引用数多于1个,这种状态称为MULTIPLE。相应的,处于这两种状态下的指针分别称为UNIQUE指针和MULTIPLE指针。
因为计数器从对象移到了指针中,因此从理解上应该是MULTIPLE指针表示该指针指向的对象有两个及以上引用。说的是指针,但主体还是对象。
1位引用计数法依然是在更新指针时进行内存管理。在普通引用计数法中,我们是通过update_ptr(ptr,obj)来更新指针,让ptr指向obj。转换一下思路,让ptr指向obj其实也就是把原本指向obj的指针复制给ptr变量。这一步转变是1位引用计数法的关键,一定要理解清楚。考虑下图的例子:

将A→D的指针更新为指向C,等价于将B→C的指针复制给A。此时因为C有了两个引用,所以A→C和B→C的指针都变成了MULTIPLE指针。
指针复制的伪代码实现如下:
//复制指针
copy_ptr(dest_ptr, src_ptr) { //注意两个参数都是指针
delete_ptr(dest_ptr) //尝试回收dest_ptr引用的对象
*dest_ptr = *src_ptr //更新指针
set_multiple_tag(dest_ptr) //将dest_ptr设置为MULTIPLE状态
if(tag(src_ptr) == UNIQUE)
set_multiple_tag(src_ptr) //将src_ptr设置为MULTIPLE状态
}
//回收ptr指向的对象
delete_ptr(ptr) {
//如果ptr指向的对象只有一个引用,
//发生指针复制后它就没有引用了,
//表示变成垃圾,可以被回收。
//MULTIPLE表示有多个引用,因此不能回收
if(tag(ptr) == UNIQUE)
reclaim(*ptr) //将ptr指向对象添加到空闲链表
}
结合上面的图示,dest_ptr是A→D的指针,src_ptr是B→C的指针。
在指针复制过程中,如果dest_ptr是UNIQUE状态,指针更新完以后,它原本指向的对象将不再被引用,因此可以直接回收。复制结束后,src_ptr指向的对象至少有两个引用,因此需要更新指针状态。整个过程中,我们只对指针操作,完全没有访问对象。最后还要将调用update_ptr的地方全部换成copy_ptr。
1位引用计数法的一个优点是不容易出现高速缓存缺失。CPU在处理时首先访问高速缓存,如果没有再从内存读取到高速缓存。使用update_ptr更新指针时,为了更新计数器,我们需要访问源对象和目标对象,如果它们在内存中相隔很远,发生高速缓存缺失的概率就会增大。而使用copy_ptr更新指针时,我们完全没有访问对象,通过指针就完成了。其另一个优点是计数器不再占用对象空间,能节省内存消耗。
1位引用计数法的缺点也和Sticky引用计数法一样,需要额外的手段来解决引用计数溢出问题。
部分标记清除算法
部分标记清除算法针对的是引用计数法无法清除循环引用垃圾的问题。其中"部分"的含义是只在可能存在循环引用的地方使用标记清除算法,其他地方还是使用引用计数法。部分清除标记法由Rafael D. Lins在1992年提出。
部分清除标记算法定义了4种颜色:
- 黑(BLACK):绝对不是垃圾的对象,也是对象的初始颜色
- 白(WHITE):绝对是垃圾的对象
- 灰(GRAY):搜索完毕的对象
- 阴影(HATCH):可能是循环垃圾的对象
在对象头中用两个比特来表示对象颜色,分别对应值00~11。
考虑下面的例子,ABC和DE构成两个循环引用,$hatch_queue是用来存放阴影对象的全局队列。

这里我们依然使用update_ptr函数更新指针,但是执行计数器减量的dec_ref_cnt函数需要改变一下,伪代码如下。
dec_ref_cnt(obj) {
obj.ref_cnt-- //将obj计数器减一
if(obj.ref_cnt == 0) //没有引用了,表示是垃圾
delete(obj) //回收对象
else if(obj.color != HATCH) //非阴影对象
obj.color = HATCH //标记为阴影,表示可能存在循环引用
enqueue(obj, $hatch_queue) //入队
}
delete函数我们在延迟引用计数法中已经见过了,不过这里还是有一点小小的区别,就是如果obj在$hatch_queue队列中,也要将obj从队列中删除。
如果将计数器减量之后任然不能回收,说明该对象可能存在循环引用,这就是循环引用的特点,计数器值无法减到零。此时我们将对象变成阴影,并加入到全局队列$hatch_queue中。如果对象颜色已经是阴影,表示已经入过队,不再重复入队。
上图示例中,删除根到A的引用,执行完def_ref_cnt函数后,堆的状态如下。
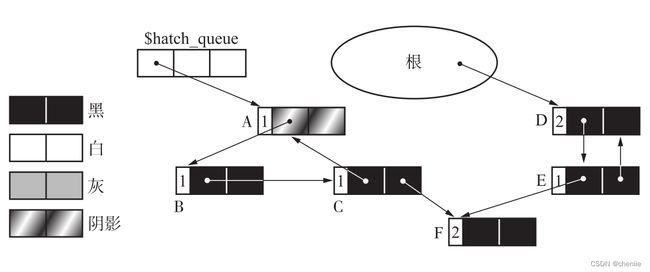
接下来GC标记清除算法就会扫描整个$hatch_queue队列,而不是从根开始扫描。从这里可以看出部分GC标记清除算法和GC标记清除算法的一点区别,部分GC标记清除算法是扫描的非活动对象,而GC标记清除算法扫描的是活动对象,二者的出发点不一样。
部分GC标记清除算法是在分配对象时触发的,新的分配算法伪代码如下。
//分配size大小的对象
new_obj(size) {
obj = pickup_chunk(size) //从空闲链表选择大小合适的分块
if(obj != NULL) //分配成功
obj.color = BLACK //新对象初始颜色为黑色
obj.ref_cnt = 1 //新对象初始引用数为1
return obj
else if(is_empty($hatch_queue) == FALSE) //分配失败且队列不为空
scan_hatch_queue() //扫描队列回收垃圾
return new_obj(size) //再次分配
else
allocation_fail() //分配失败
}
//扫描阴影对象
scan_hatch_queue() {
obj = dequeue($hatch_queue) //取队首
if(obj.color == HATCH) //阴影对象,可能是循环引用垃圾
paint_gray(obj) //染灰
scan_gray(obj) //扫描灰色对象
collect_white(obj) //回收白色对象,也就是垃圾
else if(is_empty($hatch_queue) == FALSE) //队列不为空
scan_hatch_queue() //继续扫描阴影对象
}
当无法分配内存时,就会启动部分GC标记清除算法回收垃圾,然后再次尝试分配。我们会遍历$hatch_queue队列,这里我们只处理阴影对象,因为只有阴影对象才可能存在循环引用。
部分标记清除算法的标记阶段就是在染色,对应paint_gray和scan_gray两个函数,清除阶段对应的是collect_white函数。从染色到回收共分三个步骤。
第一步 减小引用数
第一步是将对象自身以及子对象染成灰色,并将子对象引用计数减一。伪代码如下:
//将obj及其子对象染灰
paint_gray(obj) {
if(obj.color == (BLACK | HATCH)) //白色是垃圾,不用处理
obj.color = GRAY //染灰
for(child : children(obj)) //遍历子对象
(*child).ref_cnt-- //减少子对象引用计数
paint_gray(*child) //递归将子对象染灰
}
paint_gray实际上是图的深度优先遍历,这一步的真正目的是减小对象"人气",染灰只是为了防止重复访问,同时也告诉后面的流程应该处理哪些对象。因为会递归处理子对象,如果存在循环引用,最终环上的每个对象的引用数都会减一。这样就解决了循环引用对象的计数器始终不为0的问题,后面的流程也就能根据对象引用数顺利进行了。
这里有个细节,在paint_gray函数中,我们只对obj进行了染色,没有减少引用数,而对于子对象,只减少了计数器,没有染色。为什么一定要这样处理,后面会详细解释。
这一步执行完后,堆的状态如下,以A为根的对象全部染灰,并且引用数减一。
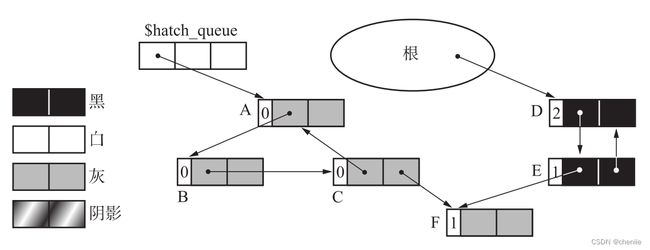
第二步 找到垃圾
第二步是从obj开始遍历,将对象染成黑色或者白色。伪代码如下。
//扫描灰色对象,将其染成黑色或白色
scan_gray(obj) {
if(obj.color == GRAY) //灰色对象
if(obj.ref_cnt > 0) //引用数大于0,肯定的不是垃圾
paint_black(obj) //染黑
else
obj.color = WHITE //染白
for(child : children(obj)) //遍历子对象
scan_gray(*child) //递归扫描灰色对象
}
//将obj染黑
paint_black(obj) {
obj.color = BLACK //染黑
for(child : children(obj)) //遍历子对象
(*child).ref_cnt++ //增加引用计数
if((*child).color != BLACK) //还没处理过
paint_black(*child) //递归染黑子对象
}
这一步染黑还是染白的依据是对象的引用计数是否大于0,如果大于0,必然不是垃圾,就将其染黑,使用paint_black是为了递归处理子对象,将误当作垃圾的对象的状态还原。否则一定是垃圾,直接染成白色。这一步执行完后,就完成了对象是垃圾还是非垃圾的分类,基本原理还是根据引用数判断是不是垃圾。完成后堆状态如下。

第三步 回收垃圾
第三步是回收白色对象,也就是垃圾。伪代码如下。
//回收垃圾
collect_white(obj) {
if(obj.color == WHITE) //白色对象,表示是垃圾
obj.color = BLACK //暂时染黑,避免循环引用导致重复回收
for(child : children(obj)) //遍历子对象
collect_white(*child) //递归处理子对象
reclaim(obj) //将obj加入空闲链表
}
这一步是针对白色对象进行递归回收,执行完后堆状态如下。

部分标记清除算法的完整过程如下。

细节问题
现在我们再来讨论上面提到的一个细节问题。问题出在不存在循环引用的情况下,考虑以下情形。
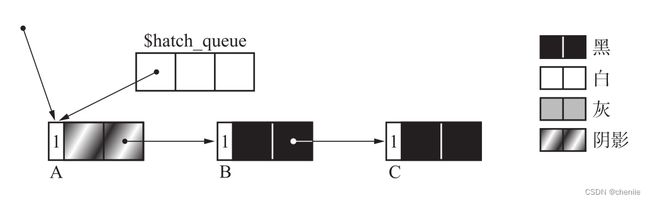
如果我们在染色的同时对计数器减一,那么paint_gray的执行过程如下:

这三个对象都被染灰,而且引用数变为0,这显然是不对的,在接下来的扫描和回收过程中,它们都会被染白并回收掉,但是显然它们还不能被回收。在dec_ref_cnt中,减小对象引用计数后仍不为0只能表示它可能是垃圾,我们无法判定仍然存在的引用究竟是真的引用,还是循环引用。因此我们不能直接直接削减它的"人气",而是利用环的特点,通过它的子对象最终把它的"人气"抹掉。
如果分开执行染色和减少引用数,整个过程如下。

由于不存在环,所以最终A的引用数还是1,在接下来的扫描过程中,它们又会被染黑,"人气"也会恢复。
总结
- 引用计数法记录了每个对象的引用数,并在更新指针时将没有"人气"的对象回收。
- 延迟引用计数法延迟了回收过程,利用ZCT数组记录下"人气"为0的对象,内存不够时再遍历ZCT数组回收垃圾。优化了频繁更新计数器问题。
- Sticky引用计数法通过减小计数器位宽优化了计数器占用较多内存的问题,但是需要额外处理计数器溢出的对象。
- 1位引用计数法将计数器减小到1比特,并且放到了指针中,彻底解决了计数器占用内存问题,同样也需要额外处理计数器溢出的情况。
- 部分标记清除法针对可能存在循环引用的对象采用了GC标记清除法,解决了循环引用无法回收的问题。
更多阅读
-
GC标记清除算法
-
GC复制算法
-
GC标记压缩算法
-
渐进式垃圾回收