【数据分析】pandas (三)
基本功能
在这里,我们将讨论pandas数据结构中常见的许多基本功能
让我们创建一些示例对象:
index = pd.date_range(“1/1/2000”, periods=8)
s = pd.Series(np.random.randn(5), index=[“a”, “b”, “c”, “d”, “e”]).
df = pd.DataFrame(np.random.randn(8, 3), index=index, columns=[“A”, “B”, “C”])
head 和 tail
要查看一个Series或DataFrame对象的部分内容,可以使用head()和tail()方法。要显示的元素的默认数量是5个,但是可以传递一个自定义的数字。
一般head为前面5行,tail为后面5行
long_series = pd.Series(np.random.randn(1000))
long_series.head()
0 -1.157892
1 -1.344312
2 0.844885
3 1.075770
4 -0.109050
dtype: float64long_series.tail(3)
997 -0.289388
998 -1.020544
999 0.589993
dtype: float64
属性和基础数据
Pandas对象具有许多属性,使您能够访问元数据
- shape给出对象的轴尺寸,与narray一致
- Axis label:
Series:索引(仅轴)
DataFrame:索引(行)和列
df
df[:2]
A B C2000-01-01 0.646715 -0.533237 0.512050
2000-01-02 0.473347 -1.401934 -0.101406
2000-01-03 -1.736713 0.793529 0.600978
2000-01-04 -0.105295 -0.154846 -0.121468
2000-01-05 0.740262 0.009942 0.508145
2000-01-06 0.152475 0.010283 0.599246
2000-01-07 1.909515 -0.662262 1.074580
2000-01-08 -2.146941 -1.081284 0.282604A B C2000-01-01 0.646715 -0.533237 0.512050
2000-01-02 0.473347 -1.401934 -0.101406
pandas的对象(index,Series,DataFrame)可以被认为是数组的容器,他保存实际数据并进行实际计算。对于许多数据类型,底层数组是numpy.ndarry。但是pandas和第三方库可能会扩展Numpy的类型系统以添加对自定义数组的支持。
要获取 Index 或 Series中的数据,使用==.arry==
s
a 0.591348
b -0.209001
c 0.632891
d -0.148446
e -0.161156
dtype: float64
s.array
PandasArray
[ 0.4691122999071863, -0.2828633443286633, -1.5090585031735124,
-1.1356323710171934, 1.2121120250208506]
Length: 5, dtype: float64
s.index,array
PandasArray
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’]
Length: 5, dtype: object
如果你需要一个Numpy数组,使用to_numpy()或者numpy.asarray()
s.to_numpy()
[out]:
array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
np.asarray(s)
[out]
array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
to_numpy()对numpy.ndarry的结果有一些控制,例如,考虑带时区的日期时间。numpy没有dtype,来表示具有时区意识的日期时间,所以有两种可能有用的表示:
- numpy.ndarray带有Timestamp对象,每一个都有正确的tz
- 一个datetime64[ns] dtype numpy.ndarray,其中的值在转化为UTC和时区是被丢弃。
时区可以使用dtype=object
In [14]: ser = pd.Series(pd.date_range(“2000”, periods=2, tz=“CET”))
In [15]: ser.to_numpy(dtype=object)
Out[15]:
array([Timestamp(‘2000-01-01 00:00:00+0100’, tz=‘CET’),
Timestamp(‘2000-01-02 00:00:00+0100’, tz=‘CET’)], dtype=object)
或者丢弃 dtype=‘datetime64[ns]’
In [16]: ser.to_numpy(dtype=“datetime64[ns]”)
Out[16]:
array([‘1999-12-31T23:00:00.000000000’, ‘2000-01-01T23:00:00.000000000’],
dtype=‘datetime64[ns]’)
Merage,join,concatenate and compare
pandas提供了各种工具,可以在连接/合并类型操作的情况下,轻松地将Series或DataFrame与用于索引和关系代数功能的各种集合逻辑组合在一起。
此外,pandas还提供了比较两个Series或DataFrame并总结其差异的实用程序
连接对象
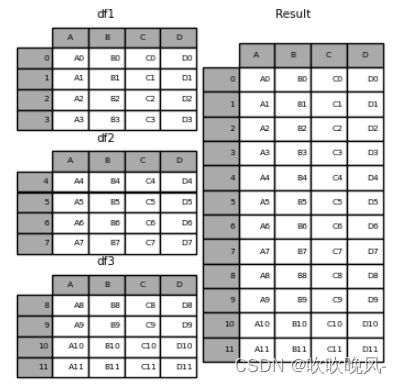
**concat()**功能(在主pandas名称空间中)完成沿一个轴执行连接操作的所有繁重工作,同时在其他轴上执行索引(如果有的话)可选集合逻辑。下面给一个简单的示例:
df1 = pd.DataFrame(
{
“A”: [“A0”, “A1”, “A2”, “A3”],
“B”: [“B0”, “B1”, “B2”, “B3”],
“C”: [“C0”, “C1”, “C2”, “C3”],
“D”: [“D0”, “D1”, “D2”, “D3”],
},
index=[0, 1, 2, 3],
)df2 = pd.DataFrame(
{
“A”: [“A4”, “A5”, “A6”, “A7”],
“B”: [“B4”, “B5”, “B6”, “B7”],
“C”: [“C4”, “C5”, “C6”, “C7”],
“D”: [“D4”, “D5”, “D6”, “D7”],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
“A”: [“A8”, “A9”, “A10”, “A11”],
“B”: [“B8”, “B9”, “B10”, “B11”],
“C”: [“C8”, “C9”, “C10”, “C11”],
“D”: [“D8”, “D9”, “D10”, “D11”],
},
index=[8, 9, 10, 11],
)
frames = [df1, df2, df3]
result = pd.concat(frames)
pd.concat(
objs,
axis=0,
join=“outer”,
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True,
)
- objs:一个Series或者一个DataFrame对象的序列或映射,如果传递了dict,则将排序后的键用作keys参数,除非传递了dict,在这种情况下将选择值(见下文)。任何None对象都将被静默丢弃,除非它们都是None,在这种情况下会引发ValueError
- axis:{0,1,…} 默认为0 表示连接的轴
- join:{’ inner ', ’ outer ‘},默认为’ outer '。如何处理其他轴上的索引。外为并,内为交
- ignore_index:boolean,默认为False。如果为True,则不要使用连接轴上的索引值。生成的轴将被标记为0,…,n - 1。如果您正在连接对象,其中连接轴没有有意义的索引信息,则这很有用。注意,在连接中仍然尊重其他轴上的索引值。
- keys:顺序,默认为None,使用传递的键作为最外层构建分层索引。如果通过了多个级别,则应该包含元组。
- levels:序列列表,默认为None。用于构造MultiIndex的特定级别(惟一值)。否则,它们将从键中推断出来。
- names:生成的层次索引中级别的名称。
- verify_integrity:boolean,默认为False。检查新连接的轴是否包含重复项。相对于实际的数据连接,这可能非常昂贵。
- copy:boolean,默认为True。如果为False,则不要复制不必要的数据。
result = pd.concat(frames, keys=[“x”, “y”, “z”])
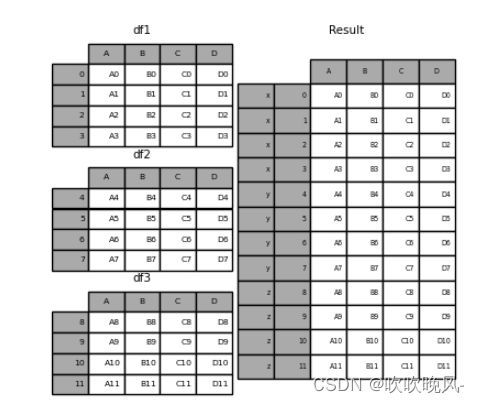
result.loc[“y”]
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
值得注意的是,concat()生成数据的完整副本,并且不断重用该函数可能会对性能造成重大影响。如果需要在多个数据集上使用操作,请使用列表推导式。
在其他轴上设置逻辑
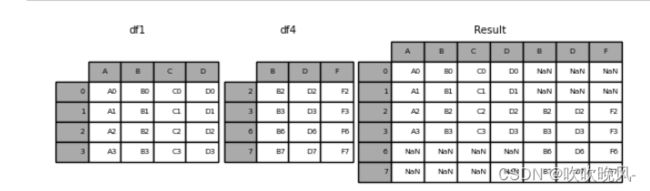
将多个 DataFrame 粘合在一起时,您可以选择如何处理其他轴(除了连接的轴之外)。这可以通过以下两种方式完成:
- 将它们全部结合起来,join=‘outer’. 这是默认选项,因为它的结果为零
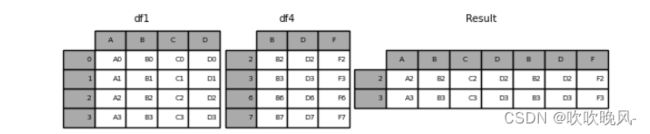
- 采取交叉路口,join=‘inner’。
以下是每种方法的示例。首先,默认join=‘outer’ 行为:
In [8]: df4 = pd.DataFrame(
…: {
…: “B”: [“B2”, “B3”, “B6”, “B7”],
…: “D”: [“D2”, “D3”, “D6”, “D7”],
…: “F”: [“F2”, “F3”, “F6”, “F7”],
…: },
…: index=[2, 3, 6, 7],
…: )
…:
In [9]: result = pd.concat([df1, df4], axis=1)
这里也是一样的join=‘inner’:
In [10]: result = pd.concat([df1, df4], axis=1, join=“inner”)
append
pd.append() 函数专门用于在 dataframe 对象后 添加新的行,如果添加的列名不在 dataframe 对象中,将会被当作新的列进行添加。
s = pd.DataFrame(np.random.randn(5,3), index=[“a”, “b”, “c”, “d”, “e”],columns=[“A”, “B”, “C”])
s2 = pd.DataFrame(np.random.randn(5,3), index=[“a”, “b”, “c”, “d”, “e”],columns=[“B”, “E”, “F”])
A B Ca 0.457078 1.023073 -0.562775
b 1.298108 -0.759387 0.524104
c -2.316800 -1.842333 -0.027894
d 1.588192 -0.024175 0.554156
e 1.881850 -0.979311 -1.519555
B E F
a 0.382541 1.595857 1.304981
b 1.924457 0.115844 0.495387
c -1.054523 0.170910 -0.299745
d 0.754534 0.392500 -0.675588
e -0.269393 1.920908 0.899837
a=s.append(s2,sort=True)
