Deep Tone-Mapping Operator UsingImage Quality Assessment InspiredSemi-Supervised Learning
ABSTRACT
色调映射操作符(TMO)旨在将高动态范围(HDR)内容转换为低动态范围,以便其可以在标准动态范围(SDR)设备上显示。 HDR内容的色调映射结果通常存储为SDR图像。 对于不同的HDR场景,传统的TMOS只能在人工微调参数的情况下获得令人满意的SDR图像。 本文提出了一种基于学习的深度卷积神经网络模型。 我们探索不同的CNN结构,采用多尺度、多分支的全卷积设计。 在训练深度CNN时,我们引入了图像质量评估(IQA),特别是色调映射图像质量评估,并将其实现为半监督损失项。 通过实验讨论并证明了半监督损失项、CNN结构、数据预处理等方法的有效性。 最后,我们证明了我们的方法可以在不同的HDR场景下产生有吸引力的结果。
I. INTRODUCTION
场景动态范围定义为最大亮度与最小亮度之比。 真实场景的亮度范围很广,从10^-4~10^5cd/m^2不等,因此特定场景的动态范围可达10^9,这远远超出了标准动态范围(SDR)器件的捕捉和显示能力。 高动态范围(HDR)图像可以以光度线性[1]和场景参考的方式记录真实世界的亮度,并在大多数情况下以封装在.HDR或.EXR格式的32位浮点数据存储。 然而,能够渲染HDR图像的显示设备仍然昂贵。 因此,在传统的SDR显示中,能够近似HDR内容外观的色调映射算子(TMO)成为大多数情况下的先决条件。
TMO的目标是尽可能地再现与真实世界场景匹配的感知[1],换句话说,选择性地保持原始HDR场景的某些特征,并产生一个信息减少的版本[3]。 但是由于HDR场景的多样性,大多数传统的TMO都依赖于参数来产生视觉上可信的结果。 传统的TMO在不正确的参数下产生的色调映射SDR图像中存在过度增强、过度程式化、晕圈效应和模糊等伪影。
随着深度学习技术的出现及其在图像变换任务中的成功应用,我们可以利用易于获得的HDR数据来学习基于深度卷积神经网络(CNN)的场景自适应TMO。
与分类、对象检测和风格转换等任务不同,高层语义特征在色调映射过程中几乎没有变化。 因此,对于色调映射,完全卷积层(其中张量的高度和宽度不发生变化)就足够了,U-Net[4](编码器-解码器)结构变得不合适,尤其是在处理高分辨率图像时[5]。 尽管全卷积体系结构在任意输入大小上具有独特的优势,但它也存在着有限的感受野所带来的全局理解能力不足的缺点。 为了克服这一点,一些相关的工作提出了不同的方法。 在深入研究和实验的基础上,我们的全卷积网络将输入分解为2个不同尺度的分量,并将它们发送到独立的特定任务的CNN分支中,然后分配另一个CNN对合并后的输出进行润色。
训练,即优化CNN的参数,是深度学习的另一个主要方面。 习惯于以往的图像变换工作,几乎每一个相关的工作都使用监督训练,即计算输出图像和标签图像之间的损失函数(在SDR中,在色调映射的情况下)。 当涉及到图像质量评估(IQA)时,特别是色调映射图像质量评估,即在输出和输入图像之间计算客观分数(SDR vs.HDR)时,自然会想到是否可以直接优化质量分数。 受此启发,我们的损失函数中的2项以IQA的方式计算,即输出对输入(无标签,无监督)。 我们的训练可以广义地称为半监督,因为有监督和无监督的损失项都涉及到。 由于监督损失需要成对的标签图像,我们以一种独特而精细的方式收集了一个包含高质量标签SDR图像的训练集。
在设计方法之前,我们系统地研究了所有与HDR相关的深度CNN的CNN结构、训练方法等。 在此基础上,还应用了多程[8]或多群[9]卷积和实例归一化[10]等改进方法。
简单来说,我们的作品是:
1)利用CNN提出了一种基于学习的TMO。
2)据我们所知,我们首先在HDR相关的深度CNN中引入了IQA启发的半监督训练。 我们迈出了一小步,弥合了感知质量和HDR相关CNN之间的差距。
3)在无语义任务中,我们探索了一种独特的低成本、灵活的方法来加强CNN的全局理解,即在全卷积层上进行多尺度分解和多组卷积。
本文的其余部分组织如下。 第二节回顾了相关工作。 第三节详细介绍了所提出的网络结构和训练方法。 第四节介绍了半监督损失项等的烧蚀研究,额外的实验,以及与其他方法的比较。 最后,第五节评述了目前和今后的工作。
II. RELATED WORK
A. TRADITIONAL TONE-MAPPING OPETATOR
在过去的20年里,大量的传统TMO被提出。 它们可以在数学上明确定义,并可分为4类,即全局类、局部类、频率/梯度类和分段类[2]。 全局方法,如Ward94[11]、Larson97[12]、Pattanaik00[13]、 DRAGO03[14],MANTIUK06[15]和ICAM06[16]对HDR图像中的所有像素应用相同的操作。 像Reinhard02[17]这样的局部方法基于其领域来处理像素值。 Durand02[18]采用双边滤波器将输入图像分解为基频分量和细节频分量,并分别进行处理。 梯度方法Fattal02[19]在梯度域处理像素。 分割方法KRAWCZYK05[20]对分割后的图像区域应用不同的操作。
在过去的十年里,更多样化的TMO如雨后春笋般出现。 李等人[21]将色调映射与视觉显著性结合起来。 SometMOS是为人类感知以外的应用场景设计的。 杨等人[22]是用于物体检测的,Rana等人[23]是用于图像匹配的。 尽管传统的TMOS带来了过度增强、过度程式化、光晕效应和模糊等伪影,但他们的一些思想如[18]中的分解仍然影响着基于深度CNN的TMOS。
B. DEEP CNN BASED TONE-MAPPING OPETATOR
到目前为止,有5个深CNN为基础的TMO。 帕特尔等人[24]提出了一种基于生成对抗网络[28](GAN)的TMO,其生成器是一个类似于U-Net[4]的14层编解码器。 他们用957个HDR-SDR(标签)图像对训练他们的网络。 这些标签是由传统的TMO生成的,他们给出了比其他TMQI更好的TMQI[6](TMQI是一种客观的色调映射图像质量评估方法,详见§II.D)。 这种标签生成在表1中称为“最佳TMQI”。
CNN在杨等人[25]的方法只包含完全卷积层:2个相同的5层分支来处理不同的分量,一个10层CNN来打磨合并后的输出。 将HDR图像的单通道亮度转换到对数域,然后利用拉普拉斯金字塔将其分解为不同尺度的基/细节分量。 他们的训练集由摄影师和志愿者微调、评估和选择(表1中表示为“人工微调”)。
张等人[26]应用了类似于[25]的多尺度2分支CNN。 他们的9层带扩张卷积的大规模分支[55]负责处理细节,5层小规模编码器分支负责全局信息,2层'tail'则负责合并2个分支的输出。 它们的损失函数包含L1范数的变体(在梯度幅值图/高斯滤波图像上,测量局部/全局细节)和其他为其双目视觉任务定制的术语,即产生具有各自重点的2幅色调映射图像。
拉纳等人[27]提出了一种基于条件生成对抗网络(CGAN)的DeepTMO方法。 他们尝试了4种生成器和鉴别器的组合,并应用了包含一个15层U网的小规模分支和一个包含7个全卷积层的大规模分支的最佳生成器。 除了CGAN项外,它们的损失函数还包含L1范数和从暹罗预训练的19层VGG-Net[30]中提取的知觉损失(表1中表示为“VGG”)。
张等人[34]的方法将HDR图像转换为HSV颜色空间。 S通道和V通道由CNN处理,而H通道被保留,以避免色调映射时的色调偏移。 他们的训练由包括SSIM[35]在内的损失术语监督,使用摄影师微调的标签图像。
有3个作品在他们的CNN的一部分中实现了色调映射。 谢特等人[31]在LAB颜色空间的4个通道上分别进行简单的4层卷积处理HDR图像。 侯等人[3]利用4层卷积处理HDR图像的亮度通道,注意这是唯一一个涉及无监督训练的HDR相关CNN。 杨等人[33]使用12层U-网将他们的中间阶段HDR图像转换成增强的色调映射图像。
表1列出了基于深度CNN的TMOS(简称“深度TMOS”)的比较。 这里,“conv5”表示5个全卷积层,“unet14”表示总共14个卷积层的编码器-解码器结构等。在第6列,“reg”表示防止过拟合的正则化项,“gan”是特定gan的损失项。
从第3列我们知道一些深TMOS([25]-[27])受到传统Durand02 TMO[18]的影响,因为它们分配不同的CNN分支来处理不同的频率分量。 具体来说,他们使用大接收场的CNN来处理全局/低频分量,小接收场的CNN来处理局部/高频分量。 第5列C=1表示CNN只处理亮度通道(除[31]外),用[32]中的一种方法从原始HDR图像的比值重建输出的颜色,这是传统TMOS的常见做法。
C. OTHER HDR RELATED DEEP CNN
其他与HDR相关的深度CNNs包括反向色调映射操作符(RTMO,单SDR到HDR)也在表1中列出,因为其中有值得学习的创新。 这里,“模拟曝光”是指使用模拟相机响应函数(CRFs)拍摄线性光HDR图像,以获得非线性SDR图像,“MEF堆栈中的EV0”将在§III.B.2中详细说明。
在HDR相关的CNN中,分解首先由Eilertsen等人应用[36]。 然而,它们的照度/反射率(I/R)[37]分解是在损失函数(I/R分量的权重不同,与[46]相同)中实现的,而不是在网络结构中实现的。 Marnerides et al[39]在以后的工作中首先应用了多分支结构,通过在每个分支中分配不同的核大小来集中全局/局部特征。 后来,分解和多分支变得更加流行,因为它们被[5]、[25]-[27]、[31]、[34]、[40]-[42]、[45]和[47]所使用。 而且,Wang等人[42]首先处理去噪,而徐等人[46]首先引入了考虑HDR视频时间信息的3D卷积。
最新著作[5]、[47]和[56]将HDR(RTMO)与超分辨率(SR)相结合。 在多任务探索(RTMO+SR)中,他们发现U-网结构不再合适,这一结论在§I中得到了阐述。 将计算机视觉(CV)中常用的几种机制引入到HDR相关的CNN(MEF)中。 严等人在文献[50]中首次引入空间注意(掩码),在文献[8]中引入多程卷积,使CNN更好地理解全局信息。
还有几项训练创新。 Marnerides等[39]首先在训练中考虑颜色信息,在不同的RGB通道上引入余弦相似损失项。 张等人[40]在损失函数中引入了E76色差公式,这是HDR相关CNN中第一个与人类感知相关的损失项。 桑托斯等人。 [43]首先引入了Gram矩阵[44]来度量风格损失,并引入特征掩蔽来强调全局差异。
目前,唯一的同时射击HDR-SDR对是由Zhang等人提出的[38]。 但由于其分辨率较低(64*128),仅包含全局特征,限制了其在未来工作中的应用。 注意,与通常应用于摄影、基于图像的渲染和医学的线性HDR不同,[5]、[40]、[45]-[47]和[56]中的HDR图像/视频通过用于消费级HDR电视和HDR电影的PQ[48]/HLG[49]光电传递函数(OETF)进行非线性变换。 金等人发现为线性光HDR图像设计的传统TMOS在OETF传输的非线性HDR内容上表现不佳,因此他们决定使用YouTube默认方法收集SDR对应物([5]、[45]和[47])。
D. TONE-MAPPED IMAGE QUALITYASSESSMENT
作为IQA的一个分支,色调映射图像质量评估将HDR视为原始图像,而将SDR视为失真图像。 色调映射图像的质量可以以全参考(FR)方式测量,即将HDR与SDR图像进行比较,或者以非参考(NR)方式测量,即仅评估色调映射SDR图像[51]。
为了在深度学习中实现损失函数,IQA方法需要在数学上是显式的和可微的,以适应反向传播中的链推导规则。 TMQI[6](Tone-Mapped Image Quality Index)从HDR与SDR图像的FR结构保真度和SDR图像的NR统计自然度两个方面来评价色调映射图像的质量。 后者是不可微的,因此被排除在我们的工作之外。 而前者的局部结构保真度项是在SSIM[35]的基础上改进的:
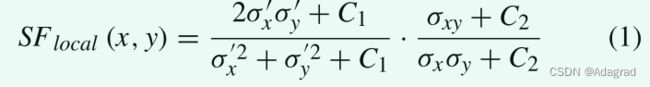


纳夫基等人提出了一种通过局部加权平均相角来度量HDR和SDR图像相位一致性的FR方法FSITM[7](色调映射图像特征相似性指数)。 除此之外,最新的NR方法如BTMQI[73]和Blique-TMI[70]等涉及更全面的特征提取和回归,取得了更好的性能(与主观得分的相关性更高),但它们要么不可微,要么过于复杂,难以在CNN中作为损失函数实现。 关于色调映射图像质量评估的更多信息可以在Survey[53]中找到。
III. PROPOSED METHOD
A. NETWORK STRUCTURE
正如图所示 1、本文方法中的CNN由3个子网络组成,即全尺度局部分支(NL)、小规模全局分支(NG)和抛光网络(NP)。 首先将3个RGB通道的HDR图像(H)分解为全尺度细节分量(HD)和小尺度基本分量(HB),然后分别发送到NL和NG,得到中间SD和SB。 然后,将SD和放大的SB(SB_F)按像素方向相加,从而重组为NP的输入。 最后,用NP给出了输出的色调映射SDR图像(S)。

全尺度局部分支(NL)由5个全卷积层(图1中的蓝框)组成,它负责处理细节信息,而不负责处理全局信息。 在此准则下,为了保持图像的结构,我们增加了2个跳过连接,并且只使用相对较小接收场的3×3卷积核来聚焦细节信息。
小尺度全局分支(NG)包含一个多组残差块(MGRB,图1中的橙盒)和前后4个卷积层。 MGRB旨在通过扩大接受领域来增强全局理解,将在§III.A.2中详细说明。
抛光网络由2个MGRB和4个卷积层(共8层)组成。 在采用滤波器分解和分支网络结构的相关工作中([5]、[25]、[31]、[42]、[45]和[47]),其中4个工作采用了抛光网络([5]、[25]、[45]和[47])。 我们采取了同样的设计,后来进行了一个实验来证明它的必要性。
在图 2、蓝框下面的数字(如24-3)表示当前层的“输入输出通道数”,如果两者相同,则简称为一个数字。 当通道数改变时,张量/图像的大小保持不变,因为我们的CNN不涉及编码器-解码器结构(没有反卷积层),并且所有完全卷积层的步幅都设置为1(带有对称填充)。
除NL、NG、NP最后一层神经元外,所有神经元均采用斜率为0.2的漏整流线性单元(LRELU)激活,以加快计算速度,避免梯度消失。 Sigmoid激活在最后3层后应用,以增加网络的非线性。 对图像尺寸较小的NG采用批处理归一化[58](BN,图1中的绿盒),因此在训练时可以采用大批处理。 由于实例规范化[10]在[27]中被证明对小批处理是有帮助的,我们将它(在灰盒中)用于批处理大小受图像大小限制的NL和NP。
1) DECOMPOSING STRATEGY
我们的分解策略是基于以下考虑而设计的。 从相关文献中可以看出,多分支策略有三种类型。 首先,调整大小,即用局部/细节/大尺度分支处理全尺寸输入图像,同时将下采样图像发送到全局/小尺度分支([26]、[27]、[39]和[41])。 二是滤波,即利用滤波器(通常是边缘保持滤波器,如双边滤波器)将图像分解为基分量和细节分量,并将其分别送入全局和局部/细节分支([5]、[31]、[42]、[45]和[47])。 第三,通过颜色通道进行“分解”([31]、[34]和[40])。 我们认为第二个想法是可行的,因为任务特定的分支可以使用定制的结构来关注不同的图像组件。

不同的是,Yang等人[25]使用拉普拉斯金字塔组合调整大小和过滤。 在这里,特定层次是高斯金字塔中对应层次与其上采样模糊下一层次之间的残差。 选择4层拉普拉斯金字塔的最低层作为全局分支的输入,其余层作为局部/细节分支的输入[54]。 在这种情况下,他们的全局分支接收到一个1/16缩比的压缩图像,因此计算成本显著降低。
因此,我们决定将图像金字塔与我们的分解思想结合起来。 首先,我们发现文献[25]中4层金字塔的最低层1/16尺度太小,因而在重组时过于模糊,因此我们使用3层金字塔{L0,L1,L2,L3},从而使基分量(HB)为1/8尺度。 其次,我们用一个保持边缘的双边滤波器代替“高斯”金字塔{G0}第一级上的高斯滤波器,并用其滤波图像直接减去“高斯”金字塔{G0,G1,G2}中的电平,使我们的“拉普拉斯”金字塔{L0}中的最高电平与双边滤波器分解的细节分量完全相同(同[31])。 我们的分解在图的右(红)部分说明 2.
我们的放大和重组方法的原型也是图像金字塔,但不同的是CNN只处理最高和最低层{L0,L3}(细节和基分量)并用于金字塔重建。 我们绕过这些中间层{L1,L2},因为[54]发现,与网络复杂度的降低相比,它们的丢失所造成的性能下降是可以忽略的。
2) MULTI-GROUP RESIDUAL BLOCK
如图红框所示 1.我们的多组残差块(MGRB)首先将输入图像/张量分成3个通道数相同的组(24 3*8),然后分别用1×1、3×3和5×5核进行卷积。 在卷积过程中,每个组的信道数保持不变,这样它们就可以按照原来的顺序进行级联。 然后,级联图像/张量之后是与MGRB外卷积相同的3×3卷积。 最后,输出按像素方向与输入残差相加。
MGRB的设计基于以下考虑。 与其他方法类似,我们的多分支结构中的全局分支负责理解全局亮度分布,因此被认为具有全局理解。 [26]、[39]、[41]和[42]的全局或小规模分支包含用于提取全局特征的编码器结构。 文献[26]和[39]进一步使用扩张卷积[55]扩大了他们的感受野,从而加强了对全局分支以外分支的全局理解。 虽然上述方法认为编码器结构能够捕捉全局特征,但它有几个固有的缺点。 首先,编码器-解码器(U-NET)结构严重依赖跳过连接来保持结构一致性和避免棋盘式伪影。 其次,编码器-解码器结构需要一个固定大小的输入,这通常是通过额外的调整大小操作获得的。
为了克服第二个缺点,我们的整个网络包括MGRB只包含完全卷积层,对输入大小没有限制。 为了克服第一个缺点,我们决定不使用U-NET结构。 因此,一个额外的任务是加强全面的局部分支NL的全局理解。 其它方法通过引入多组卷积(见[56])或多程卷积(见[8]),其中每个程分配不同的核大小,使用空间注意机制(见[43]、[50]和[5]),使用一维和二维动态卷积(见[47]),以及改进编码器-解码器结构(U-Net)[57]来解决这个问题。
与上面的方法不同,我们决定在性能和复杂性之间进行权衡。 多组Conv[9]将张量沿通道维数进行拆分,并将它们分成不同的组,同时对张量进行多重传递。 [8]只需将张量复制到不同的道次中。 为了减少内存开销和参数数,我们采用多组卷积作为MGRB的原型。 另外,为了扩大感受野,我们将多程卷积不同核大小的特性移植到MGRB上。
图 3揭示了MGRB的直接效果,即有效地消除了边缘的波纹/晕影伪影,这些伪影是由有限的接收场带来的。 MGRB的影响将在§IV.B.2中进一步定量评估。
B. TRAINING
我们的CNN可以表述为:
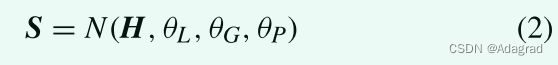
其中N是整个网络,θL,θG和θP分别表示NL,NG和NP中的模型参数。 然后,训练就是寻找使损失函数最小的θL、θG和θP。
我们采用了两步训练策略。 第一步是NL和NG的预训练,即首先优化θL和θG,冻结θP。 如图所示 4、在步骤1中,将标签SDR图像(SL)分解为细节分量(SLD)和基本分量(SLB),并将其应用于输入HDR图像。 然后,分别计算标签与输出的监督损失项,即SLB与SB,SLD与SD。 同时,无监督损失项分别计算输入与输出,即HB与SB,HD与SD。 第二步是整个网络端到端的同步训练,即对θL、θG和θP都进行了优化。 在这里,有监督的损失项是在SL和S上计算的,而无监督的损失项是在H和S上计算的。
与[5]、[25]、[42]、[45]和[47]中也应用了分解、多分支和多步训练相似,我们的2步训练具有相同的意图,即简化训练并使网络更具可解释性。 下面介绍有监督和无监督损失条款的动机和实施细节。

1) SEMI-SUPERVISED LOSS FUNCTION
这里的半监督训练不是同时使用有标记和无标记的数据,而是在有标记的数据上同时应用有监督和无监督的损失项。 有2个IQA启发的无监督术语(LTMQI和LH),2个IQA启发的监督术语(LC和LSSIM)和2个常规损失(LP和LMAE):
TMQI loss (unsupervised).

Hue shift loss (unsupervised).
对于大多数不涉及色域映射的TMOS来说,颜色外观管理长期以来一直是一个未解决的问题。 Mantiuk等人[32]探索了几种用于色调映射的颜色校正方法,发现色度变化比色调偏移更容易被接受。 我们没有采用他们的方法,因为它是为处理单亮度通道的TMO而设计的,而我们的方法直接处理3通道的RGB图像。 但受他们发现的启发,我们开始通过最小化色相移动损失(LH)来限制色相移动。
由于CIE1976 L*a*b*颜色空间及其导数L*c*h*在蓝色周围存在交叉污染[62],即在色调映射(L*递减)过程中,即使色调(H*)受到限制,蓝色周围的色度(C*)也会发生变化,因此我们转向在IPT颜色空间中定义LH。 要转换到IPT颜色空间,需要将RGB值中的像素转换为基于其色域的色品坐标的XYZ三刺激值。 我们假定所有输出SDR图像的目的色域为sRGB,同时训练集[59]和[60](参见§III.B.2)中输入HDR图像的源色域也为sRGB。 对于sRGB色域中的单个像素p:

对于Fairchild[1]HDR数据集,测量了Source HDR捕获设计的色域:

然后将XYZ三刺激转换到中间LMS颜色空间:

IPT由非线性L'M'S'值导出:


Color difference loss (supervised).
根据人类视觉系统(HVS)理论,人的颜色感知随着亮度的变化而变化,这意味着相应的HDR图像与色调映射后的SDR图像之间肯定会存在一定的色差。 因此,无监督地最小化HDR和SDR图像之间的色差是没有意义的,也是不可能的。 因此,我们转向在监督的方式下最小化输出和标签SDR图像之间的色差损失(LC)。

SSIM loss (supervised).
无监督LTMQI在保证色调映射后的SDR图像保持原始HDR图像丰富的细节和结构的同时,也要注意SDR输出图像和标签图像的结构一致性。 因此,我们决定使用损失术语SSIM[35],该术语在“知觉动机”(其定义见§V)CNN中已被证明(由[64])有效。 SSIM损失(LSSIM)采用与EQN相同的单尺度计算方法。 (4),但其局部结构保真度不同于EQN。 (1):


Perceptual loss (supervised).
另一个预先训练的网络的损失被称为“知觉”损失在20个相关的工作中的6个([3],[25],[27],[42],[43]和[46]),我们决定遵循同样的实践。
将S、SD或SB和SL、SLD或SLB分别输入到预训练的19层VGG网络[30]中,利用不同输入的VGG层间的平均绝对误差计算知觉损失(LP)。 以步骤2为例:
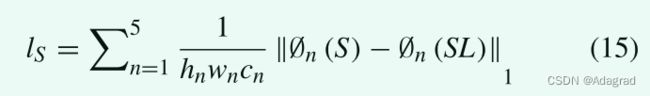

MAE loss (supervised).
平均绝对误差(MAE)损失是图像变换任务中最广泛使用的像素损失项之一:
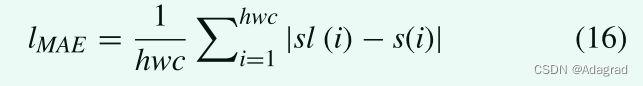
其中HWC表示张量的总元素数。 我们选择MAE(L1范数)而不是MSE(平方L2范数)损失,因为[38]发现即使HDR图像转换成非线性域,L2损失也会高估过曝光区域。
共计算出6个损失项,其中4个是受IQA启发(LTMQI、LH、LC和LSSIM),其中3个是首次在HDR相关的CNN中引入的(LTMQI、LH和LC)。 最后,所有损失项线性相加为总损失,其系数按经验设置,如表2所示。
2) TRAINING SET
一个包含HDR-SDR(输入-标签)对的训练集对于有监督的损失项仍然是不可缺少的。 我们的训练集是从Fairchild[1]、Funt et al[59]和Waterloo IVC MEFI[60]的数据集中获得的,这些数据集总共包含234个高分辨率多样化的真实世界HDR场景,以及它们的源包围曝光SDR序列。 其中200个作为训练集,其余34个作为测试集的一部分。 对于每个HDR-SDR对,得到16个大小为512×512的斑块:15个来自随机裁剪,最后一个来自大小调整。 最后,我们得到了3200对补丁。 值得注意的是,我们训练集中的目标(标签)SDR图像是基于以下见解以独特的方式获得的。
获取训练对的通常做法是使用传统的TMOS从其HDR对应体生成目标SDR图像。 由于HDR内容的广泛可访问性,几乎所有深度TMO都采用了这一方法。 然而,我们发现,即使目标SDR图像来自参数微调TMO(见[25]和[34])或根据最佳客观得分选择(见[31]、[24]、[26]和[27]),它们仍然包含传统TMO带来的伪影,如过度增强或过度程式化。 因此,为了避免这些伪影,我们首先转向使用同时拍摄的真实HDR-SDR对。
由于§II.C中提到的原因,排除了唯一可公开获得的真实HDR-SDR对[38],我们转向从括号曝光SDR序列中获得同时拍摄的SDR对应物(可在[1]、[59]和[60]中获得)。 我们开始将曝光值为0(EV0)的图像作为SDR的对应物,但我们发现它最终得到了不令人满意的结果,特别是在亮区和暗区都缺乏细节。 这是由目标SDR图像本身造成的:EV0SDR图像((a)在图5)在亮区和暗区包含缺陷细节,对RTMO显示了良好的结果,因为它们教会CNN恢复丢失的细节,然而,它们教会CNN在谈到TMO时消失这些细节。
因此,我们转向利用所有的原始信息在包围曝光序列中生成更好的目标SDR图像。 一些是通过专业摄影师使用Adobe Photoshop在校准的sRGB色域监视器上进行微调来完成的,其余的是通过调整预先训练的多曝光图像增强器SICE[61]来完成的。 正如(b)在图所示 5、这样获得的目标SDR图像在亮区和暗区都有更多的细节。
3) DATA PRE-PROCESSING
4) INPLEMENTATION DETAILS
IV. EXPERIMENTS
V. CONCLUSION AND FUTURE WORK
本文提出了一种基于学习的、场景自适应和尺寸自适应的深度CNN TMO。 在设计过程中,我们探讨了网络结构、训练和数据预处理的效果。 最重要的是,我们将IQA引入了“感知驱动”的深度CNN(即其输出由人类感知评估的CNN)。 由于IQA的机制,特别是色调映射图像质量评估,它是通过半监督损失函数来实现的。
我们的工作只是在现代知觉质量模型和知觉驱动的CNN之间的一小步。 虽然我们的IQA损失是由数学定义的,但最近有几个“知觉动机”的深度CNN,他们的IQA得分来自定制的损失网络。 这些损失网络被训练来模拟各种质量分数,以用于损失函数。 例如,陈等人[69]训练他们的损失网络输出目标VAMF之间的标签和输出,Talebi等人[74]和Yang等人[75]应用NIMA[76]作为损失网络,对输出图像进行审美主观评分。 由于质量分数的复杂性或不可微性(客观分数)和不可量化性(主观分数),使得质量分数无法直接实现为损失函数。
回想一下,由于上述原因,一些客观分数(如TMQI的自然性项、BTMQI[73]和Blique-TMI[70])被排除在我们的损失函数之外。 因此,在进一步的工作中,我们期待着使用损失网络来学习这些分数,并充当损失函数。 我们认为,与20个HDR相关CNN中的6个所使用的基于VGG-Net的损失网络相比,具有可解释输出的损失网络更能代表“感知损失”这一术语。