【脚踢数据结构】链表(1)
- (꒪ꇴ꒪ ),Hello我是祐言QAQ
- 我的博客主页:C/C++语言,Linux基础,ARM开发板,软件配置等领域博主
- 快上,一起学习,让我们成为一个强大的攻城狮!
- 送给自己和读者的一句鸡汤:集中起来的意志可以击穿顽石!
- 作者水平很有限,如果发现错误,可在评论区指正,感谢
在计算机科学中,数据结构是一种组织和存储数据的方式,使我们可以有效地访问和修改它。链表是一种常见的数据结构,它是线性表的一种重要实现方式。下面,我们将详细地介绍链表及其操作。
一、线性表
线性表(Linear List)是由n(n≥0)个相同数据类型的元素a1,a2,……,an 组成的有限序列。线性表中元素的个数n定义为线性表的长度,当n=0 时,称为空表。线性表是数据结构中最基本、最简单、也是最常用的一种数据结构。
常见的两种实现方式:
-
数组实现的线性表:使用连续的内存空间存储数据元素,可以通过索引快速访问元素。数组的优点是随机访问效率高,但插入和删除元素可能涉及元素的移动,时间复杂度较高。
-
链表实现的线性表:使用一系列的节点,每个节点存储一个数据元素和指向下一个节点的指针。链表的优点是插入和删除元素效率高,不需要移动其他元素,但访问元素需要从头节点开始遍历,时间复杂度较高。
二、链表
链表是一种具体的数据结构它在逻辑上是一对一的排列的,在存储上是非连续的。
算法包含:
新建节点、插入节点、查找节点、删除节点、更新节点、遍历、清空、判断空链表等。
链表分类:

链式存储的优点
①不需要一块连续内存;
②插入和删除效率极高。
1、单向链表
单向链表(Singly linked list)是最简单的一种链表,它的每个节点包含两个域,一个数据域(元素域)和一个指正域(链接域)。头链接指向列表中的下一个节点,而最后一个节点则指向一个空值(NULL)。并且在链式存储结构中:数据元素是随机存储的,通过指针表示(控制)数据之间的逻辑关系。

单链表的节点声明:
typedef [节点数据域类型] DataType;
struct Node
{
DataType data;//数据域
struct Node *next;//指针域
};(1)单链表初始化
一般定义一个不带数据的节点,用来表示整个链表的头部。
#include
#include
#include
//数据域
typedef int Database;
//链表的节点定义
typedef struct Node
{
Database data; //数据域
struct Node *next; //指针域
}node;
//初始化链表
node *init_list()
{
node *head = malloc(sizeof(node));
if (head != NULL)//头节点不带数据,数据域不用管,但是指针域的指针需要做初始化
{
head->next = NULL;
}
return head;
} (2)新建节点
在C、C++和一些其他编程语言中,node *表示一个指向节点的指针。节点是一种数据结构,通常包含一个值(可能是任何类型的数据)和一个指向下一个节点的指针。
例如,在链表中,每个节点都有一个指向下一个节点的指针,而最后一个节点的指针通常是NULL,表示链表的结束。
//创建节点
node *create_node(Database data)
{
node *new = malloc(sizeof(node));
if (new != NULL)
{
new->data = data;
new->next = NULL;
}
return new;
}(3)尾插法
// 尾插法
void insert_tail(node *head, node *new)
{
if (head->next == NULL)
{
head->next = new;
}
else
{
//定义一个中间变量,防止头节点的地址发生改变
node *p = head;
while(p->next != NULL)//循环遍历,找到最后一个节点
{
p = p->next;
}
p->next = new;
}
}(4)头插法
//头插法
void insert_head(node *head, node *new)
{
new->next = head->next;
head->next = new;
}(5)遍历链表
//遍历打印
void display(node *head)
{
node *p = head;
while(p->next != NULL)
{
p = p->next;
printf("%d ", p->data);
}
printf("\n");
}
(6)查找节点
//查找节点
node *find_node(node *head,Database data)
{
node *p = head;
while(p->next !=NULL)
{
if (p->next->data == data)
{
return p->next;
}
p = p->next;
}
return NULL;
}(7)删除节点:这里有三种删除节点的方法,具体要因情况而选
//删除节点,链表里的数据唯一的情况,因为这种方法只会删除一个
bool delete_node(node *head,Database data)
{
node *p = head;
while(p->next != NULL)
{
if (p->next->data == data)
{
node *dele = p->next;
p->next = dele->next;
free(dele);
dele = NULL;
return true;
}
p = p->next;
}
return false;
}
//删除节点,链表里面数据不是唯一的情况
void delete_node1(node *head, Database data)
{
node *p = head;
while(p->next != NULL)
{
if (p->next->data == data)
{
node *dele = p->next;
p->next = dele->next;
free(dele);
dele = NULL;
continue;
}
p = p->next;
}
}
//删除节点,以节点的方式删除,每次一个
bool delete_node2(node *head, node *dele)
{
if(dele ==NULL)
{
return false;
}
node *p = head;
while(p->next != NULL)
{
if (p->next->data ==dele->data)
{
p->next =dele->next;
free(dele);
dele = NULL;
return true;
}
p = p->next;
}
return false;
}(8)判断空链表
#include
//判断空链表
bool isempty(node *head)
{
return head->next == NULL;
} (9)清空链表
//清空链表
void clear_list(node *head)
{
if (isempty(head))
{
return ;
}
while(head->next!=NULL)
{
node *dele = head->next;
head->next = dele->next;
free(dele);
dele = NULL;
}
}(10)更新节点
//更新节点
void update_node(node *head, Database old_data, Database new_data)
{
if (isempty(head))
{
return;
}
node *p = find_node(head, old_data);
if (p!=NULL)
{
p->data = new_data;
}
else
{
printf("链表里面没有 %d 这个元素\n", old_data);
}
}
(11)取出节点
//取出节点
node *get_node(node *head, Database data)
{
if (isempty(head))
{
return NULL;
}
node *p = head;
while(p->next != NULL)
{
if (p->next->data == data)
{
node *tmp = p->next;
p->next = tmp->next;
return tmp;
}
p = p->next;
}
return NULL;
}(12)指定位置插入节点
//指定位置插入节点
void insert_node_node(node *n1, node *n2)
{
insert_head(n1, n2);
}
//就相当于头插法,node2相当于头节点,node1相当于新节点
(12)移动节点
void move_node(node *head, Database d1, Database d2)
{
node *p1 = get_node(head, d1);
node *p2 = find_node(head, d2);
insert_node_node(p2, p1);
} 将链表中包含数据d1的节点移动到链表中包含数据d2的节点之前的操作。它通过查找数据为d1和d2的节点,并使用insert_node_node函数将节点d1插入到节点d2之前,实现了节点的移动。
单链表实例
下面我们来完成一个简单的例子,题目为:
利用头插法,实现输入一个正整数,就插入对应节点,输入小于等于0的数则把其对应的正数节点删除,输入0则显示链表的所有节点数据(遍历)。
#include
#include
#include
//数据域
typedef int Database;
//链表的节点定义
typedef struct Node
{
Database data; //数据域
struct Node *next; //指针域
}node;
//初始化链表
node *init_list()
{
node *head = malloc(sizeof(node));
if (head != NULL)//头节点不带数据,数据域不用管,但是指针域的指针需要做初始化
{
head->next = NULL;
}
return head;
}
//创建节点
node *create_node(Database data)
{
node *new = malloc(sizeof(node));
if (new != NULL)
{
new->data = data;
new->next = NULL;
}
return new;
}
void insert_head(node *head, node *new)
{
new->next = head->next;
head->next = new;
}
void insert_sort_tail(node *head, node *new)
{
if (head->next == NULL)
{
head->next = new;
}
else
{
//定义一个中间变量,防止头节点的地址发生改变
node *p = head;
while(p->next != NULL)
{
if(p->next->data > new->data)
{
insert_head(p, new);
return ;
}
p = p->next;
}
p->next = new;
}
}
//遍历
void display(node *head)
{
node *p = head;
int i = 0;
while(p->next != NULL)
{
p = p->next;
printf("%s%d", i>0?"->":"", p->data);
i++;
}
printf("\n");
}
//查找节点
node *find_node(node *head, Database data)
{
node *p = head;
while(p->next != NULL)
{
if (p->next->data == data)
{
return p->next;
}
p = p->next;
}
return NULL;
}
//删除节点,链表里面数据唯一的情况,只删除一个
bool delete_node(node *head, Database data)
{
node *p = head;
while(p->next != NULL)
{
if (p->next->data == data)//p->next是不是就是我们要删除的节点
{
node *dele = p->next;
p->next = dele->next;
free(dele);
dele = NULL;
return true;
}
p = p->next;
}
return false;
}
int main(int argc, char const *argv[])
{
node *head = init_list();
int n;
printf("自定义一个简单链表\n");
while(1)
{
scanf("%d", &n);
if (n>0)//插入链表
{
if (!find_node(head, n))
{
//插入
insert_sort_tail(head, create_node(n));
}
}
else if (n<0)//删除节点
{
if(!delete_node(head, -n))
{
printf("链表里面没有这个节点\n");
}
}
else//遍历链表
{
display(head);
}
}
return 0;
} 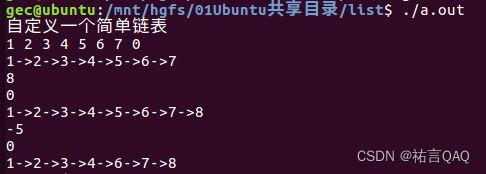
我们不难看出,当我们输入自定义的链表并在最后补上0,程序将会输出我们的链表,当我们输入一个正数8的时候,程序会把8放在位于第八位的节点上,输入0再次遍历即可得到结果。最后输入-5 将会删除位于第五位的节点。
单链表的讲解就到这里啦~
更多C语言、Linux系统、ARM板实战和数据结构相关文章,关注专栏:
手撕C语言
玩转linux
脚踢数据结构
6818(ARM)开发板实战
写在最后
- 今天的分享就到这啦~
- 觉得博主写的还不错的烦劳
一键三连喔~ - 感谢关注