微服务与Nacos概述-3
流量治理
在微服务架构中将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络原因或者自身的原因,服务并不能保证服务的100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时若有大量的网络涌入,会形成任务堆积,最终导致服务瘫痪。
流量是一个系统中最重要的运维参数之一,在具体的应用中,作为产品部署,必须进行压力测试jmeter,需要通过压力测试查找应用的QPS值
在高并发系统中,出于系统保护角度考虑,通常会对流量进行限流;不但在工作中要频繁使用,而且也是面试中的高频考点。注意重点在于最常用的限流算法大致有三种:令牌桶算法,漏桶算法,计数器算法
-
阿里开源的限流框架 Sentinel 中的匀速排队限流策略,就采用了漏桶算法
-
Nginx中的限流模块 limit_req_zone 也是采用了漏桶算法
总结限流算法
-
固定窗口算法实现简单,性能高,但是会有临界突发流量问题,瞬时流量最大可以达到阈值的2倍
-
为了解决临界突发流量,可以将窗口划分为多个更细粒度的单元,每次窗口向右移动一个单元,于是便有了滑动窗口算法
-
滑动窗口当流量到达阈值时会瞬间掐断流量,所以导致流量不够平滑
-
想要达到限流的目的,又不会掐断流量,使得流量更加平滑?可以考虑漏桶算法!需要注意的是,漏桶算法通常配置一个FIFO的队列使用以达到允许限流的作用
-
由于速率固定,即使在某个时刻下游处理能力过剩,也不能得到很好的利用,这是漏桶算法的一个短板。
-
限流和瞬时流量其实并不矛盾,在大多数场景中,短时间突发流量系统是完全可以接受的。令牌桶算法就是不二之选了,令牌桶以固定的速率v产生令牌放入一个固定容量为n的桶中,当请求到达时尝试从桶中获取令牌
-
当桶满时,允许最大瞬时流量为n;当桶中没有剩余流量时则限流速率最低,为令牌生成的速率v
-
如何实现更加灵活的多级限流呢?滑动日志限流算法了解一下!这里的日志则是请求的时间戳,通过计算制定时间段内请求总数来实现灵活的限流。当然,由于需要存储时间戳信息,其占用的存储空间要比其他限流算法要大得多。
限流算法并没有绝对的好劣之分,如何选择合适的限流算法呢?
-
不妨从性能,是否允许超出阈值,落地成本,流量平滑度,是否允许突发流量以及系统资源大小限制多方面考虑
-
当然市面上也有比较成熟的限流工具和框架。如Google出品的Guava中基于令牌桶实现的限流组件拿来即用;alibaba开源的面向分布式服务架构的流量控制框架Sentinel是基于滑动窗口实现的。
软件系统的可靠性或者可用性经常会使用x个9表示,其中3个9表示1年8.76小时适用于电脑或服务器,4个9表示52.6分钟适用于企业级设备,5个9表示5.26分钟适用于一般电信级设备。具体生产环境中最容易出现的是一种服务的雪崩效应问题。
RESTful接口的重试实现
1、依赖:spring-retry
2、开启Retry支持,在主类或者配置类上使用EnableRetry注解,一般使用在service层,开启retry功能
@RestController
@EnableRetr
public class TestController {
@Autowired
private RestTemplate restTemplate;
@RequestMapping("/test")
@Retryable(value = Exception.class, maxAttempts = 3, backoff =
@Backoff(delay = 2000, multiplier = 1.0) )//针对test方法提供了异常重试的支持,value
//是异常类型,maxAttempts最大重试次数,backoff重试的相关参数配置,例如延迟时间等
public String test() {
String object = restTemplate.getForObject("http://retryprovider/retry", String.class);
return object;
}
@Recover 对应的异常处理
public String recover(Exception exception){
return exception.getMessage();
}
}
Sentinel
Sentinel是阿里提供的基于滑动窗口的流量控制和熔断降级的工具,用于保证分布式系统中应用的可靠性和稳定性,主要依靠于ProcessorSlotChain处理槽链的方式实现,可以将不同功能的Slot采用责任链模式组织起来,以松耦合的方式实现限流、熔断、系统保护等功能
基本概念
-
限流
-
熔断
-
削峰填谷
在Sentinel应用种会引入一个webUI的管理控制器sentinel-dashboard,管理的默认用户名和口令为sentinel/sentinel
-
查看集群信息以及各个节点的健康状况
-
可以提供秒级的服务监控统计
-
提供GUI进行流控规则配置、熔断降级以及配置规则的推送
限流的基本使用
限流主要用于将超过阈值配置的流量在到达目标之前进行处理
常规的限流策略有2种:QPS每秒的访问次数、处理线程个数
常规的限流处理方式有3种:直接拒绝、冷系统预热、匀速排队
1、添加依赖:spring-cloud-starter-alibaba-sentinel
2、添加配置
# Sentinel 控制台地址
spring.cloud.sentinel.transport.dashboard=localhost:8092
3、在访问的控制器上添加配置
@RestController
public class TestController {
@GetMapping("/test")
//可以使用SentinelResource定义资源名称
// @SentinelResource(value = "hello")
public String sayHello(String name){
return "Hello "+name+"!";
}
}
4、可以通过sentinel-dashboard配置指定资源的流控规则。默认为QPS表示每秒钟允许访问的次数,如果在规定的时间内超过阈值则会产生一个异常FlowException,默认处理方式为快速失败
@RestController
public class TestController {
@GetMapping("/test")
//可以使用SentinelResource定义资源名称
@SentinelResource(value = "hello",blockHandler = "helloBlock")
public String sayHello(String name){
return "Hello "+name+"!";
}
public String helloBlock(String name, BlockException exception){
System.out.println(name+"-->"+exception);
if(BlockException.isBlockException(exception)){
//限流处理
return "限流降级:Block:"+exception.getMessage();
}
return exception.getMessage();
}
}
-
Value:资源名称,必需项(不能为空)
-
blockHandler:处理BlockException的函数名称(可以理解对Sentinel的配置进行方法兜底)。
-
函数要求:
-
必须是public修饰
-
返回类型与原方法一致
-
参数类型需要和原方法相匹配,并在最后加BlockException类型的参数。
-
-
-
默认需和原方法在同一个类中,若希望使用其他类的函数,可配置blockHandlerClass,并指定blockHandlerClass里面的方法。
- blockHandlerClass:存放blockHandler的类。对应的处理函数必须是public static修饰,否则无法解析,其他要求:同blockerHandler
fallback:用于在抛出异常的时候提供fallback处理逻辑(可以理解为对java异常情况方法兜底)。
fallback函数可以针对所有类型的异常(除了exceptionsToIgnore里面排除掉的异常类型)进行处理。
函数要求:
-
返回类型与原方法一致
-
参数类型需要和原方法相匹配,Sentinel 1.6开始,也可以在方法最后加Throwable类型的参数。
-
默认需和原方法在同一个类中。若希望使用其他类的函数,可配置fallbackClass,并制定fallbackClass里面的方法。
fallbackClass:存放fallback的类。对应的处理函数必须static修饰,否则无法解析,其他要求:同fallback。
Sentinal-dashboard的配置
阈值类型:阈值类型QPS或者并发线程数
- 单机QPS为5即每秒只允许5次请求,超出的请求会被拦截并报错。
流控模式:当出现流控问题,就是超过阈值的处理方法
-
流控模式有直接、关联和链路三种。在添加限流规则时,点击高级选项,可以选择三种流控模式
-
1、直接,统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
-
2、关联,统计与当前资源相关的另一个资源,触发阈值时对当前资源限流。
-
3、链路,统计从指定链路访问到本资源的请求,触发阈值时对指定链路限流
-
-
总结流控模式
-
直接模式:对当前资源限流
-
关联模式:高优先级资源触发阈值,对低优先级资源限流。
-
链路模式:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
-
流控效果有快速失败、Warm Up和排队等待三种,流控效果是指请求达到流控阈值时应该采取的措施,
-
1、快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。
-
2、warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。
-
3、排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长
流控效果:1、快速失败是QPS超过阈值时,拒绝新的请求。2、warm up是QPS超过阈值时,拒绝新的请求;QPS阈值是逐渐提升的,可以避免冷启动时高并发导致服务宕机。3、排队等待是请求会进入队列,按照阈值允许的时间间隔依次执行请求;如果请求预期等待时长大于超时时间,直接拒绝。
熔断的基本使用
断路器模式,在具体应用中断路器有Hystrix和Sentinel
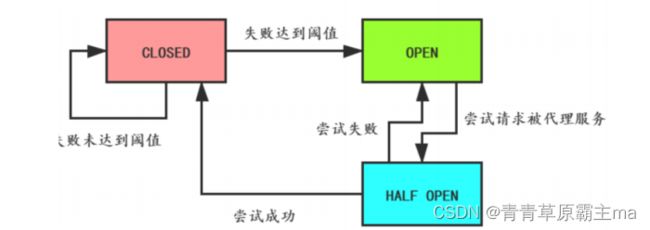
状态机包括三个状态
-
closed关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
-
open打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
-
half-open半开状态,放行一次请求,根据执行结果来判断接下来的操作。请求成功则切换到closed状态;请求失败则切换到open状态
可以使用Sentinel-dashboard配置熔断规则
Sentinel提供的熔断策略有3种:慢调用RT比例、异常比例、异常个数
@RestController
public class HelloController {
@Value("${spring.application.name}")
private String appName;
@SentinelResource(value = "hello", blockHandler = "handleError",
fallback = "handleException") //可以在控制器中,也可以在业务实现类的方法上
@RequestMapping("/hello")
public String sayHello(String name) {
if(!StringUtils.hasText(name)) throw new
IllegalArgumentException("名称不能为空!");
return String.format("[%s] said: hello %s!", appName, name);
}
public String handleError(String name, BlockException ex) { //流控降级处理
ex.printStackTrace();
return "error!"; }
public String handleException(String name,Throwable t) { //异常降级处理
return "参数错误!"; }
}
熔断降级处理
熔断降级设计理念,在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。
Hystrix 通过线程池隔离的方式,来对依赖资源进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本,过多的线程池导致线程数目过多,还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
1、通过并发线程数进行限制。和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。
当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
2、通过响应时间对资源进行降级。除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。