NLP语言模型概览
语言模型结构分类
- Encoder-Decoder(Transformer): Encoder 部分是 Masked Multi-Head Self-Attention,Decoder 部分是 Casual Multi-Head Cross-Attention 和 Casual Multi-Head Self-Attention 兼具。比如T5,BART,MASS
- 因果语言模型(Causal Language Model, CLM): 即Transformer的Decoder,比如GPT。也叫自回归语言模型(Auto-Regressive Language Models)
- 掩蔽语言模型(Masked Language Model, MLM): 即Transformer的Encoder,相比自回归模型,自编码模型的学习过程,能看到待预测词的前后内容,所以对文本的理解是更深入的,在同等成本的情况下理论上自编码模型对文本的分类、回归方面的 NLU 问题会有更好性能表现。典型的自编码模型有 BERT、ERNIE、ALBERT、RoBERTa、DistilBERT、ConvBERT、XLM、XLM-RoBERTa、FlauBERT、ELECTRA、Funnel Transformer。
- 前缀语言模型(Prefix language model):如UniLM。与自回归语言模型相比,前缀语言模型在抽取输入文本特征时用了 Fully-Visible Mask(Encoder 用的掩码,能看到「过去」和「未来」)而不是 Future Mask(Decoder 用的掩码,只能看到「过去」),而生成本文部分则与自回归语言模型一样,只看到左侧
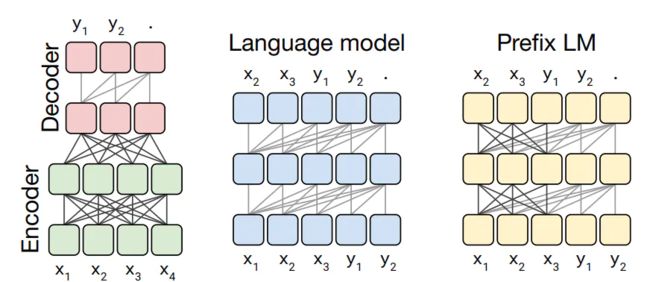

Pre-trained Language Model(PLM)模型
- BERT−Tokenizer
- Flan-T5:instruction-finetuned
- Falcon 7B:
- RoBERTa
- DeBERTa
- AlBERT
- ELECTRA
1. BERT(2018)
Bidirectional Encoder Representations from Transformers
BERT 具有两种输出,一个是pooler output,对应的[CLS]的输出,以及sequence output,对应的是序列中的所有字的最后一层hidden输出。所以BERT主要可以处理两种,一种任务是分类/回归任务(使用的是pooler output),一种是序列任务(sequence output)
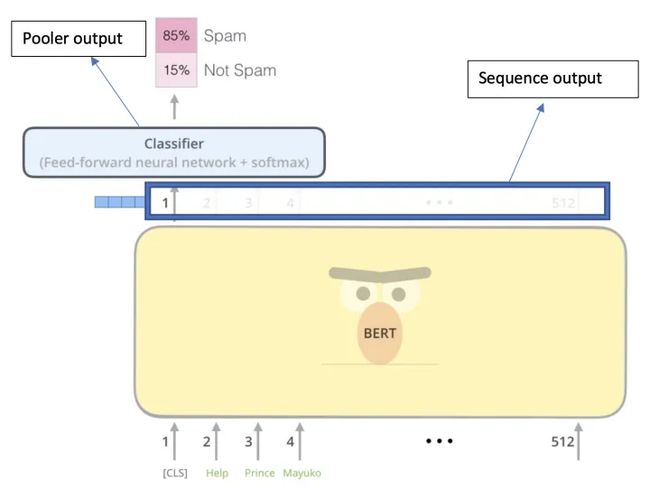
输入层

为了使得BERT模型适应下游的任务(比如说分类任务,以及句子关系QA的任务),输入将被改造成[CLS]+句子A(+[SEP]+句子B+[SEP]) 其中
- [CLS]:代表的是分类任务的特殊token,它的输出就是模型的pooler output
- [SEP]:分隔符
- 句子A以及句子B是模型的输入文本,其中句子B可以为空,则输入变为[CLS]+句子A
BERT预训练和微调
1. Mask Language Model(MLM):类似于完形填空(Cloze task)
具体的做法: 我们会随机mask输入的几个词,然后预测这个词。但是这样子做的坏处是因为fine-tuning阶段中并没有[MASK] token,所以导致了pre-training 和 fine-tuning的不匹配的情况。所以为了减轻这个问题,文章中采用的做法是:对于要MASK 15%的tokens,
- (1) 80%的情况是替换成[MASK]
- (2) 10%的情况是替换为随机的token
- (3) 10%的情况是保持不变
for index in cand_indexes:
if len(masked_lms) >= num_to_predict: # 15% of total tokens
break
...
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token注意,这边的token的level是采用Byte Pair Encoding (BPE)生成word piece级别的,什么是word piece呢,就是一个subword的编码方式,经过WordpieceTokenizer 之后,将词变为了word piece, 例如:
# input = "unaffable"
# output = ["un", "##aff", "##able"]这样子的好处是,可以有效的解决OOV(Out-Of-Vocabulary)的问题,但是mask wordpiece的做法也被后来(ERNIE以及SpanBERT等)证明是不合理的,没有将字的知识考虑进去,会降低精度,于是google在此版的基础上,进行Whole Word Masking(WWM)的模型。需要注意的是,中文的每个字都是一个word piece,所以WWM的方法在中文中,就是MASK一个词组
2. Next sentence order(NSP) 预测两个句子是不是下一句的关系
具体来说:50%的概率,句子A和句子B是来自同一个文档的上下句,标记为is_random_next=False, 50%的概率,句子A和句子B不是同一个文档的上下句,具体的做法就是,采用从其他的文档(document)中,加入新的连续句子(segments)作为句子B。具体参考create_instances_from_document函数
首先我们会有一个all_documents存储所有的documents,每个documents是由句子segemnts组成的,每个segment是由单个token组成的。我们首先初始化一个chunk数组,每次都往chunk中添加同一个document中的一个句子,当chunk的长度大于target的长度(此处target的长度一般是max_seq_length,但是为了匹配下游任务,target的长度可以设置一定比例short_seq_prob的长度少于max_seq_length)的时候,随机选择一个某个句子作为分割点,前面的作为句子A,后面的作为句子B。 chunk = [Sentence1, Sentence2,..., SentenceN], 我们随机选择选择一个句子作为句子A的结尾,例如2作为句子结尾,则句子A为=[Sentence1, Sentence2]。我们有50%的几率选择剩下的句子[Sentence3,...SentenceN]作为句子B,或者50%的几率时的句子B是从其他文档中的另外多个句子。
这时候可能会导致我们的训练样本的总长度len(input_ids)大于或者小于我们的需要的训练样本长度max_seq_length。
- 如果
len(input_ids) > max_seq_length, 具体的做法是分别删除比较长的一个句子中的头(50%)或尾(50%)的token - 如果
len(input_ids) < max_seq_length, 采用的做法是补0。
根据我们的两个任务,我们预训练模型的输入主要由以下7个特征组成。
input_ids: 输入的token对应的idinput_mask: 输入的mask,1代表是正常输入,0代表的是padding的输入segment_ids: 输入的0:代表句子A或者padding句子,1代表句子Bmasked_lm_positions:我们mask的token的位置masked_lm_ids:我们mask的token的对应idmasked_lm_weights:我们mask的token的权重,1代表是真实mask的,0代表的是padding的masknext_sentence_labels:句子A和B是否是上下句
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])3. fine-tuning
在Fine-Tuning阶段的时候,我们可以简单的plugin任务特定的输入和输出,作为训练。 例如:
- 2句子 pairs: 相似度任务,
- 假设-前提 pairs: 推理任务,
- 问题-文章 pairs : QA任务
- text−∅ pair: 文本分类 or 序列标注.
在这个任务中,就不需要MLM任务以及NSP任务所需要的输入了,所以就只有固定输入features(input_ids, input_mask, segment_ids)以及任务特定features
例如分类任务的输入特征:
input_ids: 输入的token对应的idinput_mask: 输入的mask,1代表是正常输入,0代表的是padding的输入segment_ids: 输入的0:代表句子A或者padding句子,1代表句子Blabel_ids:输入的样本的label
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])2. XLNet
BERT的缺点很明显。从建模本身来看,随机选取15%的字符mask忽视了被mask字符之间可能存在语义关联的现象,从而丢失了部分上下文信息。同时,微调阶段没有mask标记,导致预训练与微调的不一致
 XLNet原理浅析 - 知乎
XLNet原理浅析 - 知乎
XLNet是一种广义的自回归预训练方法。XLNet本质上是用自回归语言模型来同时编码双向语义信息的思路,可以克服BERT存在的依赖缺失和训练/微调不一致的问题。同时为了弥补自回归模型训练时无法同时看到上下文的缺陷,XLNet曲线救国地提出了PLM排列语言模型的训练方式。

Permutation Language Model 排列语言模型
为了在不改变AR模型基本结构的条件下引入下文信息,XLNet使用了对输入序列“排列组合”的方法,把下文信息排到前面,赋予了单向模型感知下文的能力。例如,现有序列 [1→2→3→4] ,只需改变其顺序,变换出[2→4→3→1] 、[1→4→2→3] 、[4→3→1→2] 等序列,即可让3看到4,2看到3和4,1看到2、3、4。下图为不同排列方式下,位置"3"所能关注的位置示意图(只能关注序列中在它之前的部分):
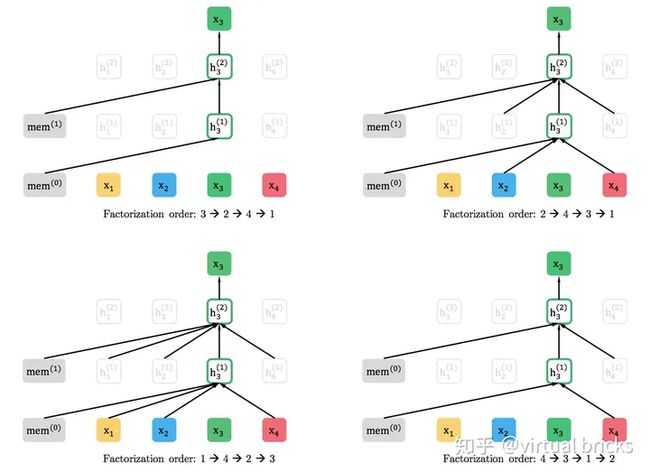

注意,排列组合并不是真的使用原始序列生成新的排列组合序列,并抽样产生新的增强数据集来完成的,因为这种做法仍然会造成Pre-train和Fine-tune的语料分布不一致。XLNet的做法是在计算attention时mask掉对应位置,不同的mask对应不同的序列。
Two-Stream Self-Attention 双流注意力
为了实现 Permutation 加上 AR 预测过程,首先我们会发现,打乱顺序后位置信息非常重要,同时对每个位置来说,需要预测的是内容信息(对应位置的词),于是输入就不能包含内容信息,不然模型学不到东西,只需要直接从输入复制到输出就好了。
于是这里就造成了位置信息与内容信息的割裂,因此在 BERT 这样的位置信息加内容信息输入 Self-Attention (自注意力) 的流(Stream)之外,作者还增加了另一个只有位置信息作为 Self-Attention 中 query 输入的流。文中将前者称为 Content Stream,而后者称为 Query Stream。Query流中当前token只能关注到前面的token和自身的位置信息,Content流中当前token可以关注到自身。
这样就能利用 Query Stream 在对需要预测位置进行预测的同时,又不会泄露当前位置的内容信息。具体操作就是用两组隐状态(hidden states) g 和 ℎ 。其中 g 只有位置信息,作为 Self-Attention 里的 Q。 ℎ 包含内容信息,则作为 K 和 V。具体表示如下图所示
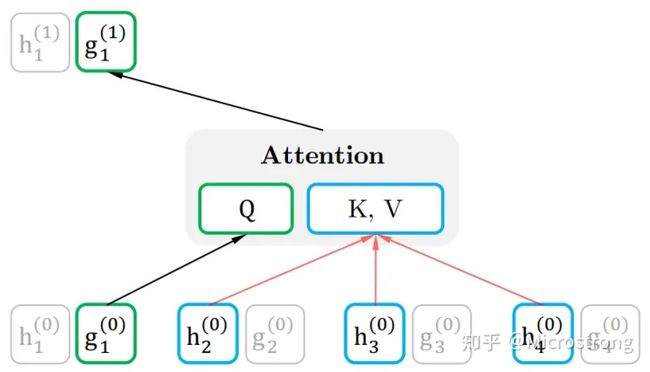 query stream
query stream
假如,模型只有一层的话,其实这样只有 Query Stream 就已经够了。但如果将层数加上去的话,为了取得更高层的 h,于是就需要 Content Stream 了。h 同时作为 Q K V。所有组合起来:
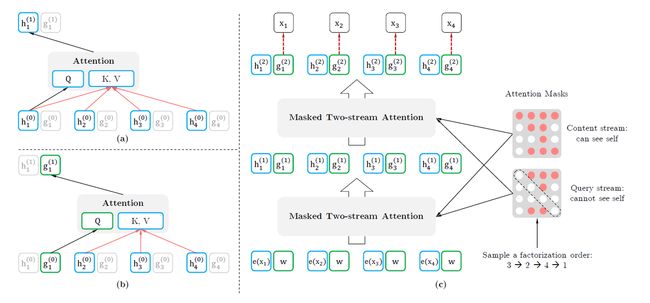
上图中我们需要理解两点:
- 第一点,最下面一层蓝色的 Content Stream 的输入是 e(xi) ,这个很好懂就是 x 对应的词向量 (Embedding),不同词对应不同向量,但看旁边绿色的 Query Stream,就会觉得很奇怪,为什么都是一样的 w ?这个和Relative Positional Encoding 有关。
- 第二点,Query stream attention图中为了便于说明,只将当前位置之外的 h 作为 K 和 V,但实际上实现中应该是所有时序上的 h 都作为 K 和 V,最后再交给上图中的 Query stream 的 Attention Mask 来完成位置的遮盖。
Partial Prediction
XLNet还使用了部分预测(Partial Prediction)的方法。因为LM是从第一个Token预测到最后一个Token,在预测的起始阶段,上文信息很少而不足以支持Token的预测,这样可能会对分布产生误导,从而使得模型收敛变慢。为此,XLNet只预测后面一部分的Token,而把前面的所有Token都当作上下文。具体来说,对长度为 T 的句子,我们选取一个超参数 K ,使得后面 1/K 的Token用来预测,前面的 1−1/K 的Token用作上下文。注意, K 越大,上下文越多,模型预测得就越精确。
例如[1→2→3→4]只预测3和4,把1和2当作上下文信息。
3. RoBERTa
A Robustly Optimized BERT Pretraining Approach
此方法属于BERT的强化版本,也是BERT模型更为精细的调优版本。在模型规模、算力和数据上,与BERT相比主要有以下几点改进:
- 更大的模型参数量(论文提供的训练时间来看,模型使用 1024 块 V100 GPU 训练了 1 天的时间)
- 更大bacth size。RoBERTa 在训练过程中使用了更大的bacth size。尝试过从 256 到 8000 不等的bacth size。
- 更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本。而最初的BERT使用16GB BookCorpus数据集和英语维基百科进行训练)
另外,RoBERTa在训练方法上有以下改进:
- 去掉下一句预测(NSP)任务
- 动态掩码。BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。 而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
- 文本编码。Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
Static vs. Dynamic Masking 动态掩码与静态掩码
○ BERT依赖于随机mask和预测标记。原始的BERT实现在数据预处理期间执行一次mask,从而产生一个静态mask。为了避免对每个epoch中的每个训练实例使用相同的mask,训练数据被复制了10次,以便在40个epoch中,每个序列以10种不同的方式被mask训练。因此,在训练过程中,每个训练序列都被用同一个mask观看四次。
我们将这种策略与动态mask进行比较,在动态mask中,我们每次向模型提供一个序列时都会生成mask模式。当进行更多步骤的预训练或使用更大的数据集时,这一点变得至关重要。
○ 动态mask:对每个序列进行mask的操作是在喂给模型该序列时执行的。这在预训练更多步骤或更大数据集时,至关重要。
对NSP训练策略的探索
为了探索NSP训练策略对模型结果的影响,将一下4种训练方式及进行对比:
- SEGMENT-PAIR + NSP:这是原始 BERT 的做法。输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。
- SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
- FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。
- DOC-SENTENCES:输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务。
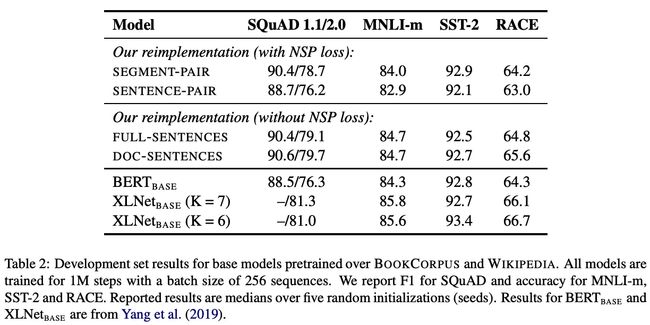
- (1)作者发现使用单个句子会损害下游任务的性能,作者推测这是因为该模型无法学习远程依赖关系。
- (2)去掉NSP任务会有略微的提升。
- (3)DOC-SENTENCES比FULL-SENTENCES表现好。
文本编码 - Text Encoding
字节对编码(Byte-Pair Encoding, BPE) 是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在 1万到 10万之间。当对海量多样语料建模时,unicode characters占据了该词表的大部分。Radford et al.(2019)的工作中介绍了一个简单但高效的BPE, 该BPE使用字节对而非unicode characters作为子词单元。
总结下两种BPE实现方式:
- 基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
- 基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。
当采用 bytes-level 的 BPE 之后,词表大小从3万(原始 BERT 的 char-level )增加到5万。这分别为 BERT-base和 BERT-large增加了1500万和2000万额外的参数。之前有研究表明,这样的做法在有些下游任务上会导致轻微的性能下降。但是作者相信:这种统一编码的优势会超过性能的轻微下降。且作者在未来工作中将进一步对比不同的encoding方案。
- 字节对编码(BPE)是字符级和单词级表示形式的混合体,可以处理自然语言语料库中常见的大词汇。
- Radford在GPT2里提出了一种更巧妙的BPE实现版本byte-level text encoding,该方法使用bytes作为基础的子词单元,这样便把词汇表的大小控制到了5w。它可以在不需要引入任何未知字符前提下对任意文本进行编码。
- BERT原始版本使用字符级(character-level)的BPE词汇表,大小是3w,是用启发式分词规则对输入进行预处理学习得到的。
- 之前的一些实验结果表明,这两种文本编码的实验性能区别不大,可能Radford BPE Encoding在某些任务上的终端性能略微差点,但是RoBerta作者坚信通用的编码模式比性能上的轻微损失更重要,所以在实验中采用了byte-level text encoding。
4. DeBERTa(2021)
Decoding-enhanced BERT with Disentangled Attention
- 解耦注意力(disentangled attention)机制:将内容和位置的注意力分开来,由4部分组成,内容到内容(C2C),内容到位置(C2P),位置到内容(P2C)和位置到位置(P2P);
- 增强型掩码解码器(EMD):在所有Transformer层之后,各种最后输出头之前,将绝对位置合并。BERT模型在输入层中合并了绝对位置。;
- 一种用于微调的虚拟对抗训练方法(Scale-invariant-Fine-Tuning,规模不变微调SiFT):SiFT首先将单词嵌入向量归一化为随机向量,然后将扰动应用于归一化的嵌入向量。 归一化大大改善了微调模型的性能。
解耦注意力(disentangled attention)
对于序列中位置i处的token,我们使用两个向量, {H_i} 和 {P_i|j} 表示它,它们分别表示其内容和与位置j处的token的相对位置。 token i和j之间的交叉注意力得分的计算可以分解为四个部分:
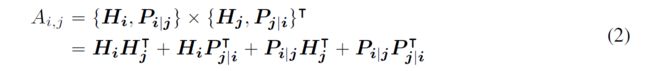
也就是说,一个单词对的注意力权重可以使用其内容和位置的解耦的矩阵计算为四个注意力(内容到内容,内容到位置,位置到内容和位置到位置)的得分的总和。
这和把两个向量级联,然后相乘的区别在哪里?
举例子,假设都是2维行向量:
Hi = [hi1, hi2], Pi|j = [pi1, pi2];
Hj = [hj1, hj2], Pj|i = [pj1, pj2];
那么按照上面的计算公式,我们得到的是:
hi1 * hj1 + hi2 * hj2 + (content to content)
hi1 * pj1 + hi2 * pj2 + (我是新的; content to position)
pi1 * hj1 + pi2 * hj2 + (我也是!position to content)
pi1 * pj1 + pi2 * pj2 (position to position)
而如果级联之后呢,得到的是:
[hi1, hi2, pi1, pi2] * [hj1, hj2, pj1, pj2]
= hi1 * hj1 +
hi2 * hj2 +
pi1 * pj1 +
pi2 * pj2
可以看到多出来了内容向量和位置向量的“交互”

SiFT规模不变微调
Scale-invariant-Fine-Tuning 不变微调(SiFT) 是Miyato等人(Jiang et al2020)中描述的算法的一种变体,用于微调。
虚拟对抗训练是一种改进模型泛化的正则化方法。 它通过对抗性样本提高模型的鲁棒性,对抗性样本是通过对输入进行细微扰动而创建的。 对模型进行正则化,以便在给出特定于任务的样本时,该模型产生的输出分布与该样本的对抗性扰动所产生的输出分布相同。
对于NLP任务,扰动将应用于单词嵌入,而不是原始单词序列。 但是,嵌入向量的value范围(范数)在不同的单词和模型之间有所不同。 对于具有数十亿个参数的较大模型,方差会变大,从而导致对抗训练有些不稳定。
受层归一化的启发(Ba et al.,2016),我们提出了SiFT算法,该算法通过应用扰动的归一化的词嵌入来提高训练稳定性。 具体来说,在我们的实验中将DeBERTa微调到下游NLP任务时,SiFT首先将单词嵌入向量(word embedding vectors)归一化为随机向量,然后将随机扰动应用于归一化的嵌入向量。 我们发现,归一化大大改善了微调模型的性能。 对于较大的DeBERTa模型,此改进更为突出。 我们将SiFT的全面研究留给未来的工作。
5. ALBERT(2020)
A Lite BERT for Self-supervised Learning of Language Representations
ALBERT 结合了两种技术同时解决了内存和训练时长的问题:
- 分解 Embedding 的参数
- 跨层参数共享
还有个增益是可以充当正则化的形式,从而稳定训练并有助于泛化。对 Bert 模型进行了三个方面调整:
- 分解 Embedding 参数:WordPiece Embedding 学习的是 context-independent 表示;hidden-layer Embedding 学习的是 context-dependent 表示。前者 Size 取小点就可以缩小参数规模,因此本文将 Embedding 的参数分解为两个较小的矩阵。即首先将 One-hot 投影到尺寸为 E(128) 的较低维嵌入空间中,然后再将其投影到隐藏空间中。参数规模从 O(V × H) 减小到 O(V × E + E × H)。
- 跨层共享:共享了层间的所有参数。这里作者对比了 Bert 和 ALBERT 层输入和输出的相似度,发现 ALBERT 的结果更加平滑,说明权重共享对稳定网络参数有影响。另外相似度的结果是振荡的,不是像 DQEs(见《相关工作》)所说的达到了平衡点(对于该平衡点,特定层的输入和输出嵌入保持不变)。
- 句子连贯性损失函数:Bert 的 NSP(Next Sentence Prediction) 被发现不可靠,本文作者猜测任务难度相比 MLM 来说太小,其实它可以看作一个任务做了主题预测和连贯性预测,但主题预测很容易,而且和 MLM 有重叠。因此本文提出了 SOP(Sentence-order Prediction),聚焦在句子连贯的建模上,具体做法是:Positive 和 Bert 一样,来自同一个文档的两个连续片段;Negative 用的还是这两个片段,只不过交换了一下顺序。事实证明 NSP 根本无法解决 SOP 任务(即,它最终学习了更容易的主题预测信号,并在 SOP 任务上以随机基线水平执行),而 SOP 可以将 NSP 任务解决为合理的程度。
6. T5
Transfer Text-to-Text Transformer
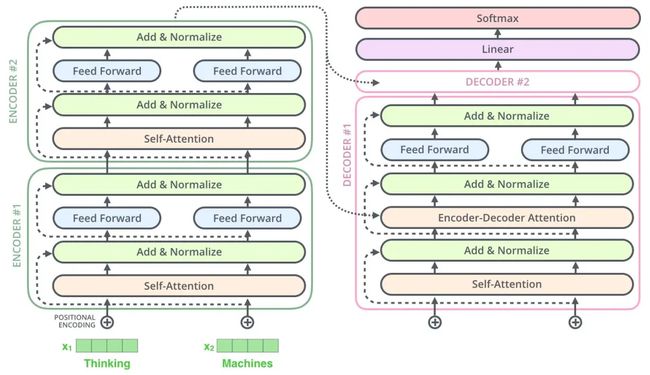
T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型。
对预训练目标的大范围探索实验
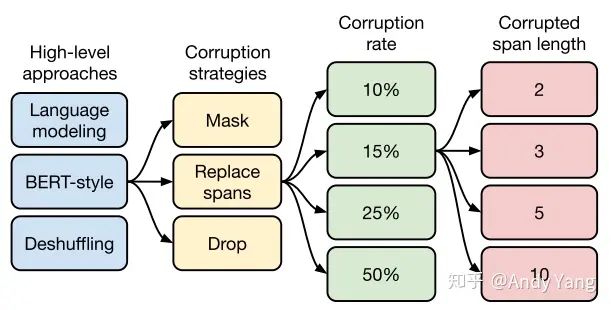
总共从四方面来进行比较。
第一个方面,高层次方法(自监督的预训练方法)对比,总共三种方式。
- 语言模型式,就是 GPT-2 那种方式,从左到右预测;
- BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来;
- Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来。
![]()
其中发现 Bert-style 最好,进入下一轮。
第二方面,对文本一部分进行破坏时的策略,也分三种方法。
- Mask 法,如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
- replace span(小段替换)法,可以把它当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率;
- Drop 法,没有替换操作,直接随机丢弃一些字符。
![]()
此轮获胜的是 Replace Span 法,类似做法如 SpanBERT 也证明了有效性。
第三方面,到底该对文本百分之多少进行破坏呢,挑了 4 个值,10%,15%,25%,50%,最后发现 BERT 的 15% 就很 ok了。这时不得不感叹 BERT 作者 Devlin 这个技术老司机直觉的厉害。
接着进入更细节,第四方面,因为 Replace Span 需要决定对大概多长的小段进行破坏,于是对不同长度进行探索,2,3,5,10 这四个值,最后发现 3 结果最好。
终于获得了完整的 T5 模型,还有它的训练方法。
- Transformer Encoder-Decoder 模型;
- BERT-style 式的破坏方法;
- Replace Span 的破坏策略;
- 15 %的破坏比;
- 3 的破坏时小段长度。
7. Flan-T5
Scaling Instruction-Finetuned Language Models:One Model for ALL Tasks
这里的Flan指的是(Instruction finetuning),即"基于指令的微调";T5是2019年Google发布的一个语言模型了。注意这里的语言模型可以进行任意的替换(需要有Decoder部分,所以「不包括BERT这类纯Encoder语言模型」),论文的核心贡献是提出一套多任务的微调方案(Flan),来极大提升语言模型的泛化性。
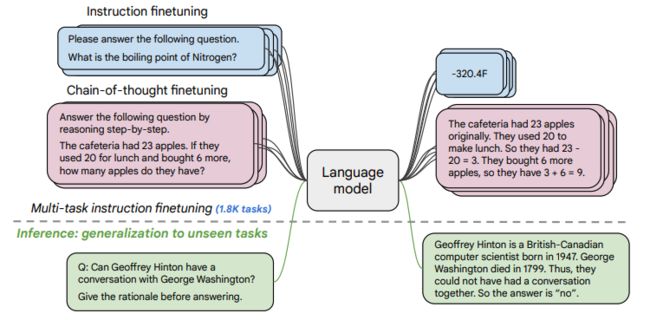
微调任务

(1) 「任务收集」:工作的第一步是收集一系列监督的数据,这里一个任务可以被定义成<数据集,任务类型的形式>,比如“基于SQuAD数据集的问题生成任务”。需要注意的是这里有9个任务是需要进行推理的任务,即Chain-of-thought (CoT)任务。
(2) 「形式改写」:因为需要用单个语言模型来完成超过1800+种不同的任务,所以需要将任务都转换成相同的“输入格式”喂给模型训练,同时这些任务的输出也需要是统一的“输出格式”。输入输出格式如图所示,根据 “是否需要进行推理 (CoT)” 以及 “是否需要提供示例(Few-shot)” 可将输入输出划分成四种类型:

(3) 「训练过程」:采用恒定的学习率以及Adafactor优化器进行训练;同时会将多个训练样本“打包”成一个训练样本,这些训练样本直接会通过一个特殊的“结束token”进行分割。训练时候在每个指定的步数会在“保留任务”上进行模型评估,保存最佳的checkpoint。

评测数据集
- SQuAD(Standford Question Answering Dataset) :提供了一段上下文和一个问题。任务是回答这个问题通过从上下文中提取相关span
- RACE (ReAding Comprehension from Examinations):大规模的阅读理解数据集。该数据集收集自中国为中学生设计的英语考试。在比赛中,每篇文章都有多个问题。对于每个问题的任务是从四个选项中选择一个正确答案
- GLUE (General Language Understanding Evaluation):评估自然语言理解系统的9个数据集的集合。6项任务分为单句分类任务和句子对分类任务
References
文本生成系列之前缀语言模型 - 知乎
人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状
BERT 详解 - 知乎
XLNet原理浅析 - 知乎
RoBERTa - 论文解读 - 简书
DEBERTA:解耦注意力的解码增强型BERT - 知乎
[细读经典]DeBERTa-使用解绑注意力的解码增强BERT - 知乎